阿里雲DataWorks實踐:數據集成+數據開發
簡介
-
什麼是DataWorks:
- DataWorks(數據工場,原大數據開發套件)是阿里雲重要的PaaS(Platform-as-a-Service)平台產品,為您提供數據集成、數據開發、數據地圖、數據品質和數據服務等全方位的產品服務,一站式開發管理的介面,幫助企業專註於數據價值的挖掘和探索。
- DataWorks支援多種計算和存儲引擎服務,包括離線計算MaxCompute、開源大數據引擎E-MapReduce、實時計算(基於Flink)、機器學習PAI、圖計算服務Graph Compute和互動式分析服務等,並且支援用戶自定義接入計算和存儲服務。DataWorks為您提供全鏈路智慧大數據及AI開發和治理服務。
-
學習路徑:
-
實踐案例目標:將MongoDB資料庫中的目標日誌集合約步至阿里雲DataWorks中,在DataWorks中進行日誌解析處理後,將處理後的新數據同步到MongoDB資料庫的新集合中,整個業務流程的執行間隔盡量縮短。
-
實踐案例步驟:
- 準備阿里雲帳號並登錄
- 創建並配置工作空間
- 購買獨享數據集成資源組並綁定
- 創建並配置數據源
- 配置並創建MaxCompute表
- 創建業務流程
- 創建並配置離線數據增量同步節點
- 下載IntelliJ IDEA的MaxCompute Studio插件並配置
- 使用MaxCompute Studio開發MapReduce功能的Java程式
- 將MapReduce功能程式打包上傳為資源
- 創建並配置ODPS MR節點
- 關聯各個節點
- 提交業務流程並查看運行結果
步驟
一、準備阿里雲帳號並登錄
Ⅰ、註冊阿里雲帳號
-
官方文檔:準備阿里雲帳號
-
步驟圖示:
-
官網首頁點擊右上角”立即註冊”。
-
選擇註冊方式進行註冊。
-
註冊完成後,官網首頁右上角可登錄帳號。
-
登錄成功後,點擊右上角”我的阿里雲”圖標,會出現賬戶資訊邊欄。

-
在邊欄中點擊”帳號管理”,進入帳號管理頁面。
-
在帳號管理頁面完成實名認證。

-
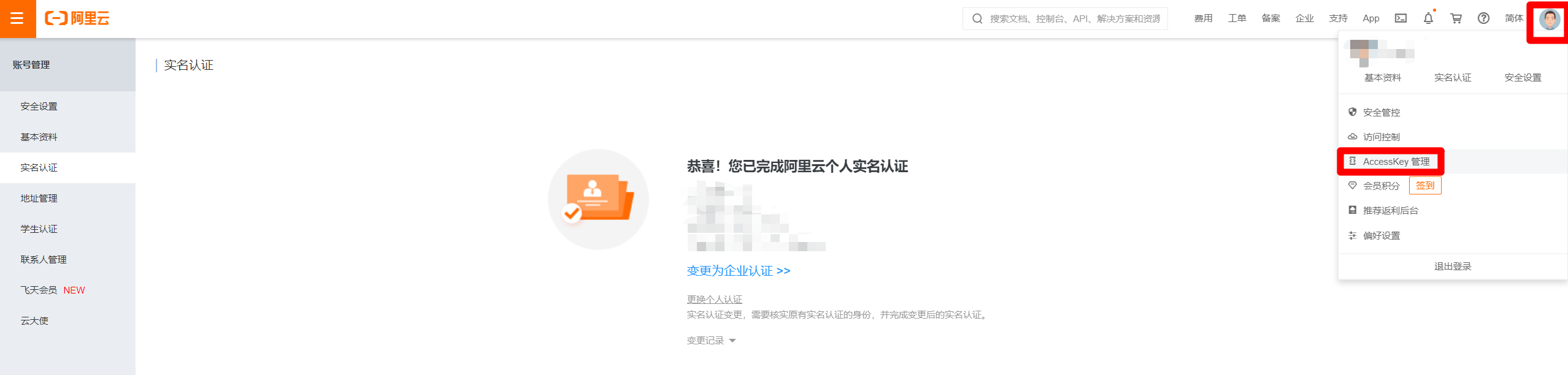
完成實名認證後,滑鼠箭頭懸停在頁面右上角的頭像上,在出現的懸浮框中點擊”AccessKey管理”,進入AccessKey管理頁面。
-
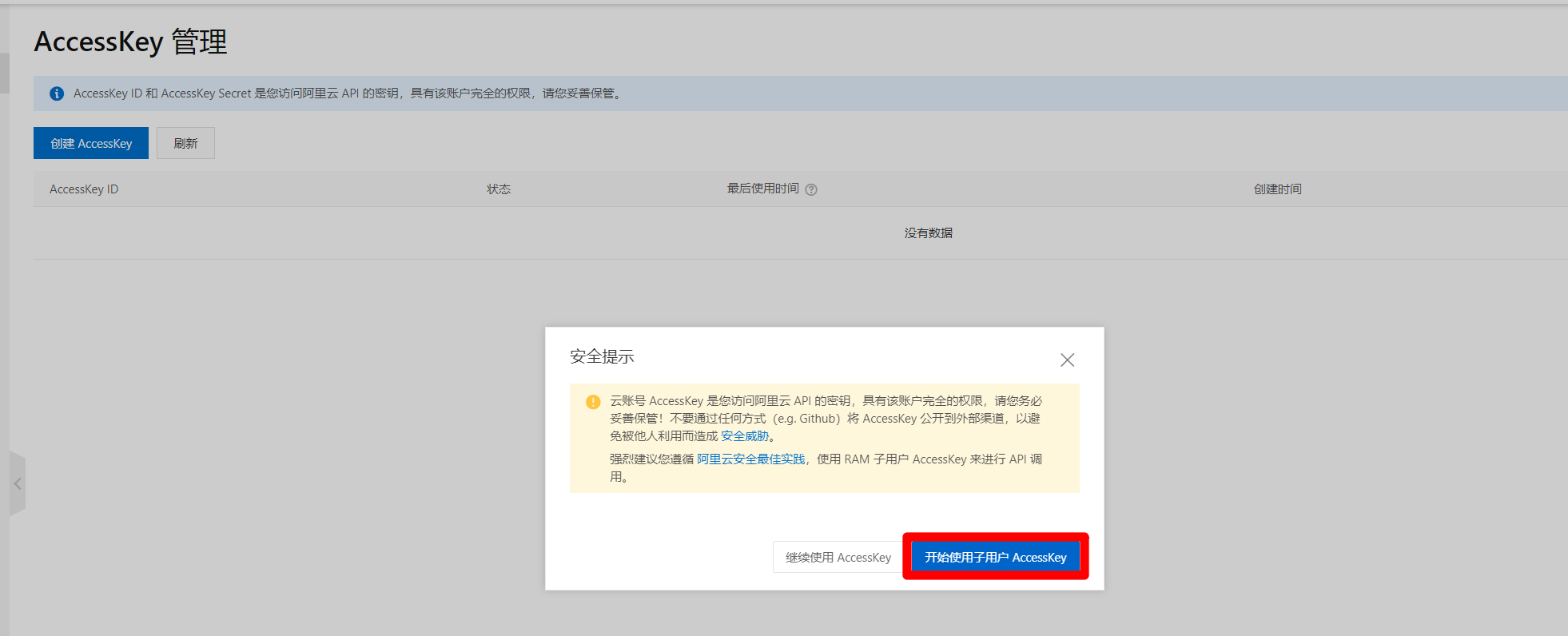
目前阿里雲官方建議禁用主帳號的AccessKey,使用RAM子用戶AccessKey來進行API調用,因此點擊”開始使用子用戶AccesssKey”,進入RAM訪問控制頁面,進行下一步:創建RAM子帳號。
-








Ⅱ、創建RAM子帳號
-
官方文檔:準備RAM用戶
-
步驟圖示:
-
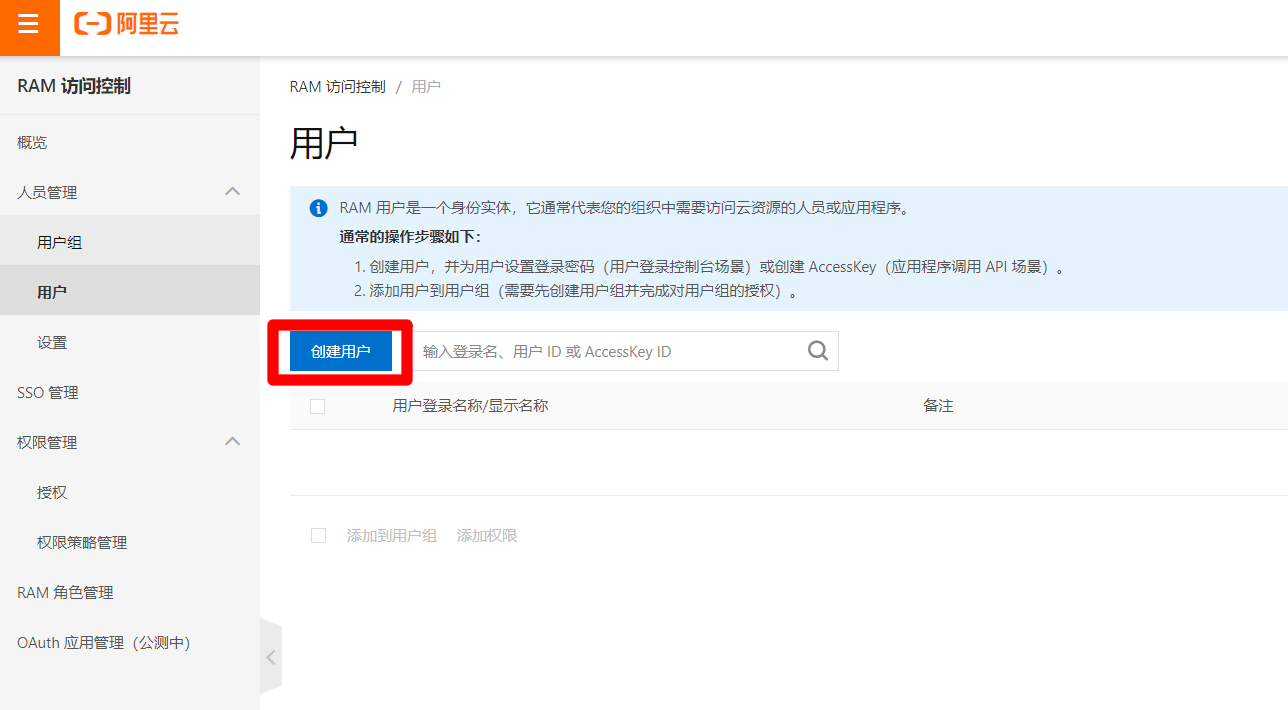
在RAM訪問控制頁面,點擊”創建用戶”按鈕,進入創建用戶頁面。
-
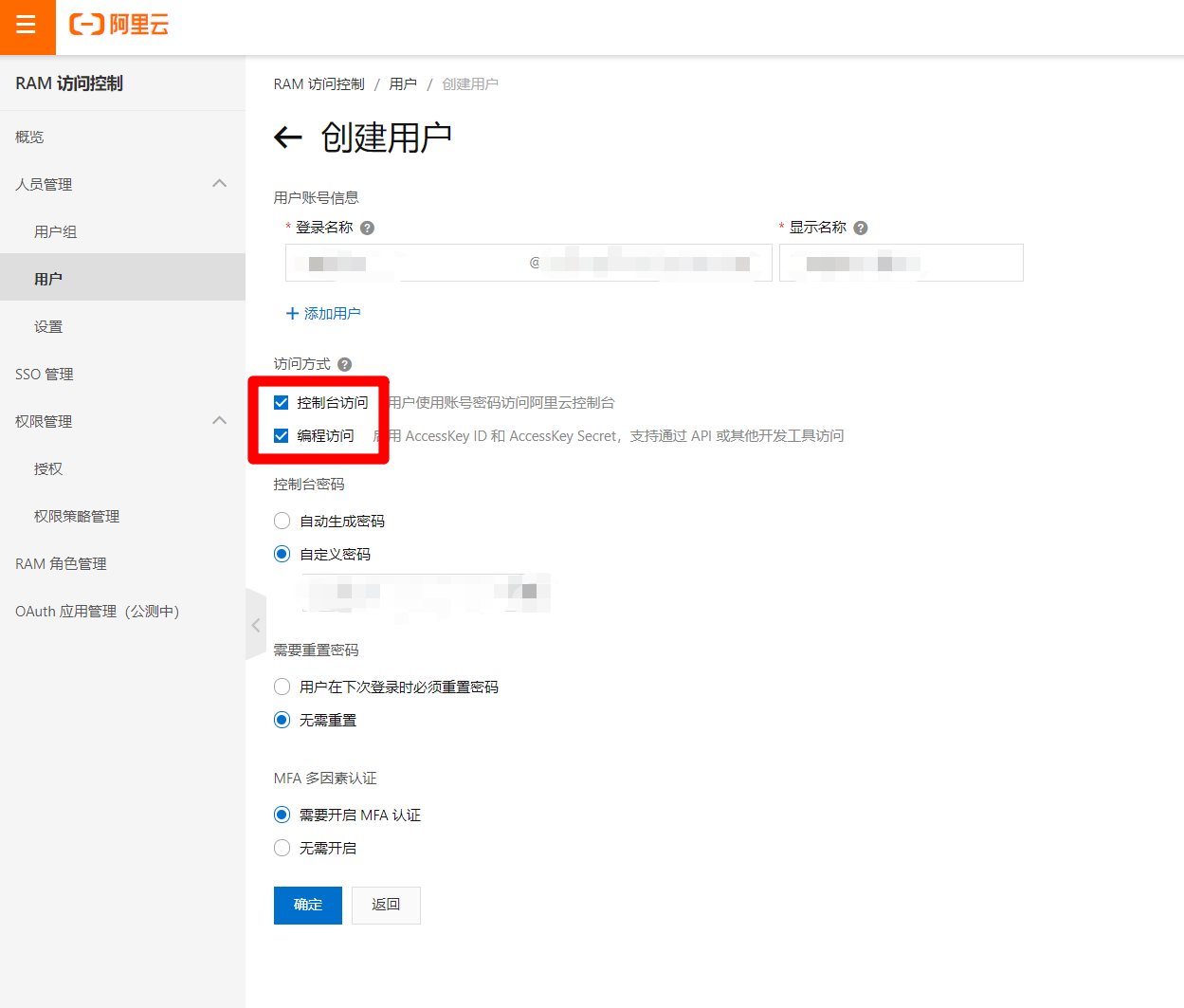
在創建用戶頁面,填寫賬戶資訊,勾選”控制台訪問”與”編程訪問”,下面的密碼選項根據需求自主選擇,完成後點擊”確定”,創建成功後,及時保存AccessKey相關資訊(下載CSV文件)。
-
選擇RAM訪問控制頁面左側菜單欄的”人員管理”中的”用戶組”標籤,在切換後的頁面中點擊”創建用戶組”,完善用戶組資訊後,點擊”確定”按鈕,完成用戶組的創建。
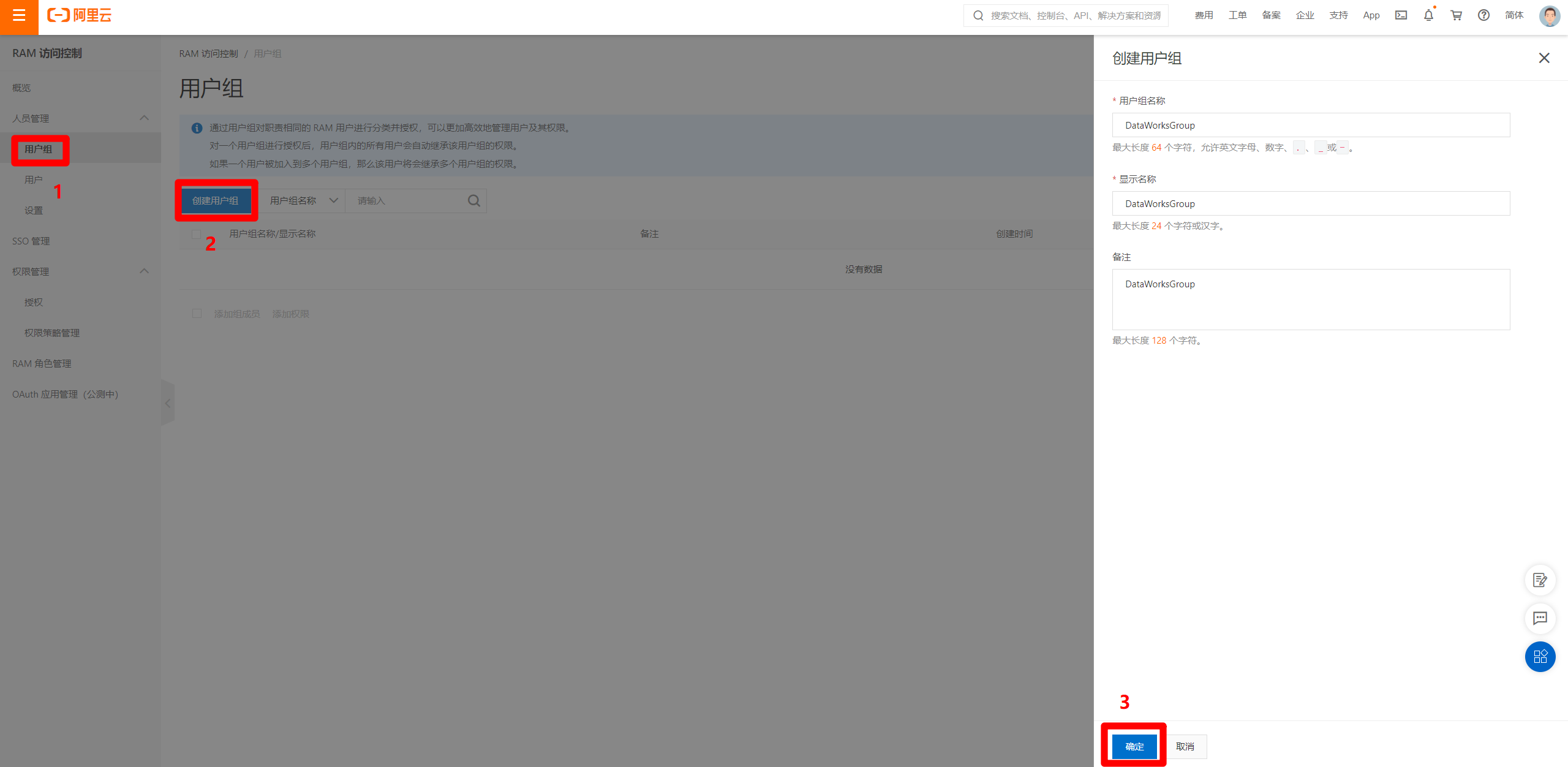
-
選中創建好的用戶組,點擊”添加組成員”,在彈出的邊欄中,選中剛才創建好的RAM用戶,點擊”確定”,將RAM用戶綁定到用戶組。
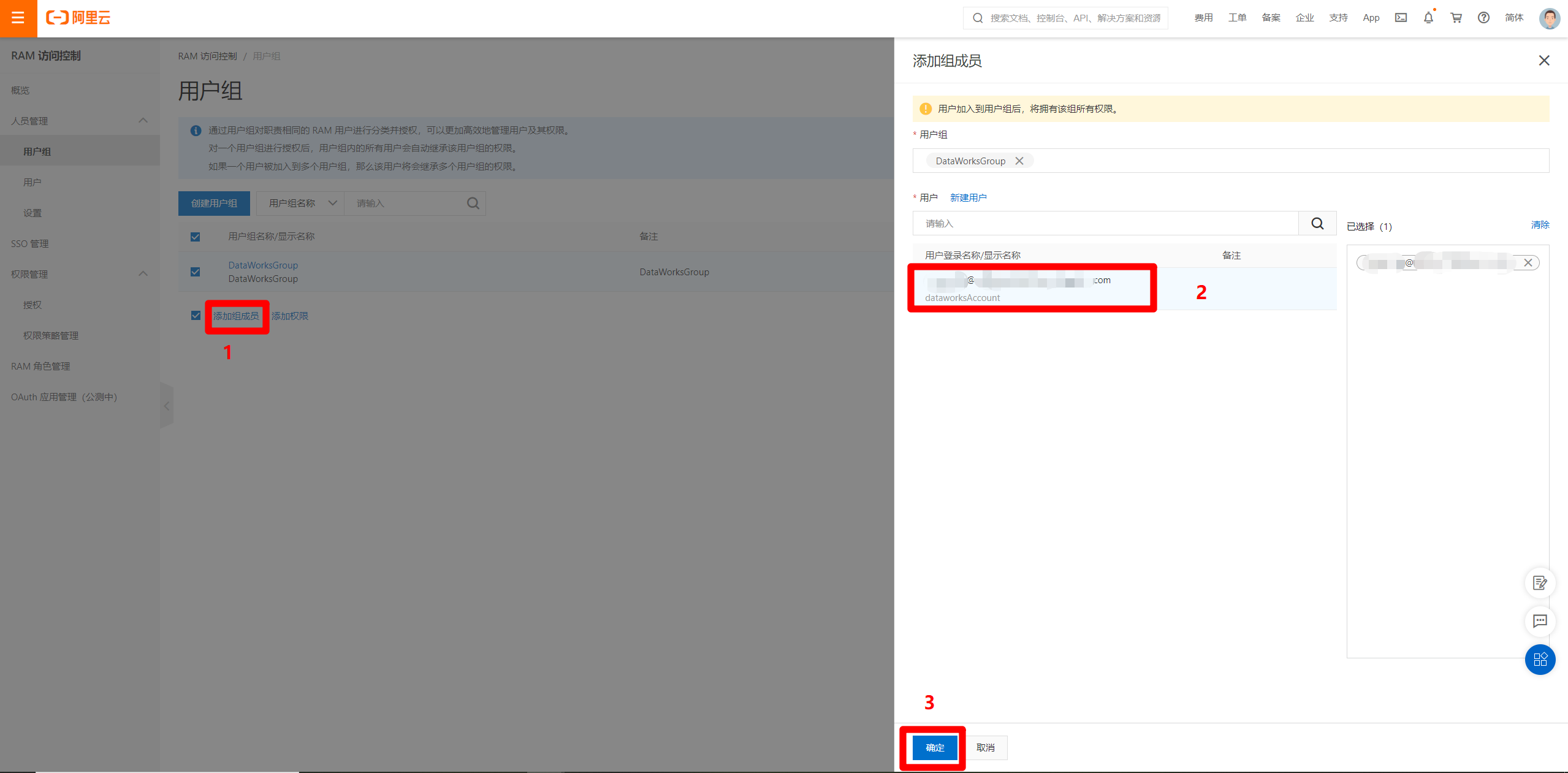
-
選中剛才的用戶組,點擊”添加許可權”,在彈出的邊欄中,根據需求選擇授權範圍,然後選擇許可權添加。根據需求盡量選擇小許可權添加,當前先添加DataWorks使用許可權,之後有別的許可權需求再進行添加。選擇好許可權後,點擊”確定”完成。
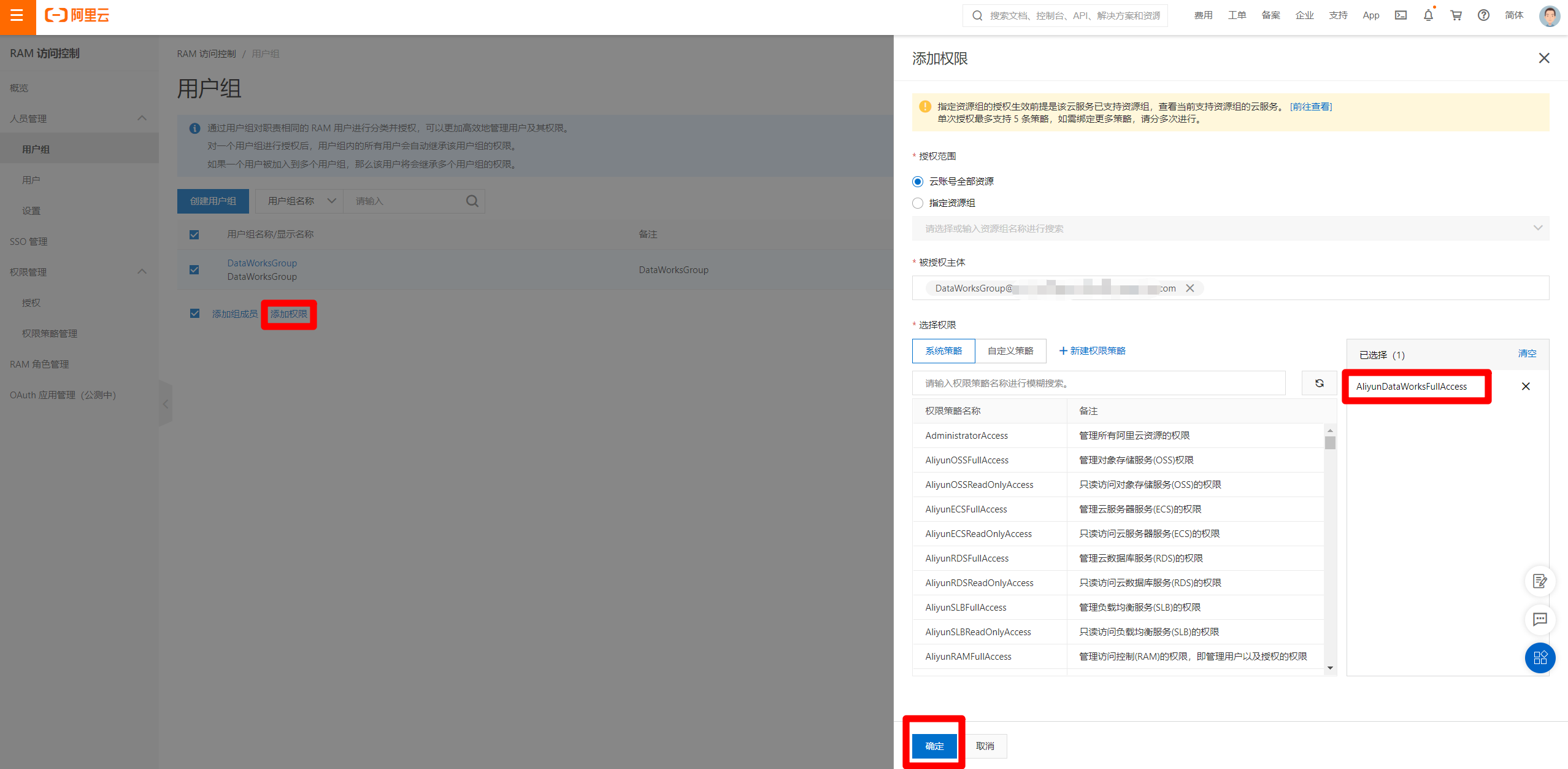
-
完成許可權添加後,點擊右上角”我的阿里雲”圖標,在出現賬戶資訊邊欄下方,點擊退出登錄,退出當前阿里雲帳號。
-
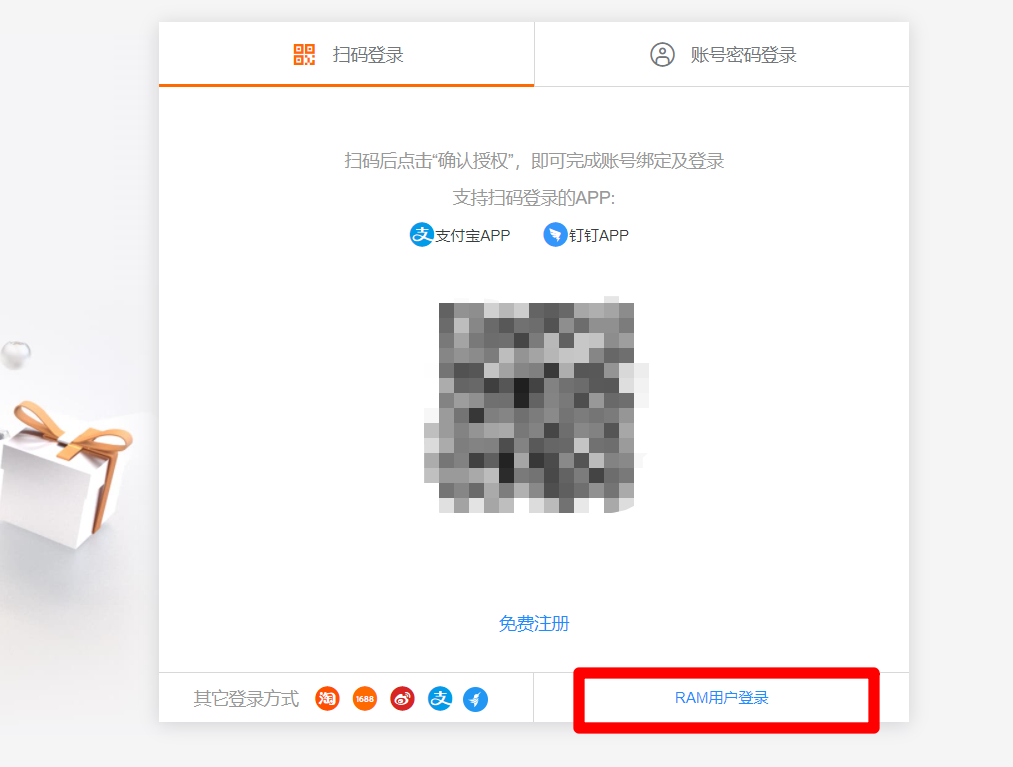
退出登錄後,點擊阿里雲首頁右上方”登錄”,在登錄頁面中點擊”RAM用戶登錄”,使用RAM帳號進行登錄。遵循阿里雲安全最佳實踐,之後均使用RAM帳號進行DataWorks開發操作,在需要添加許可權、購買阿里雲產品等特殊情況時,再使用阿里雲主賬戶進行操作(不同的瀏覽器可以分別登錄不同帳號)。
-







二、創建並配置工作空間
-
官方文檔:創建工作空間
-
步驟圖示:
-
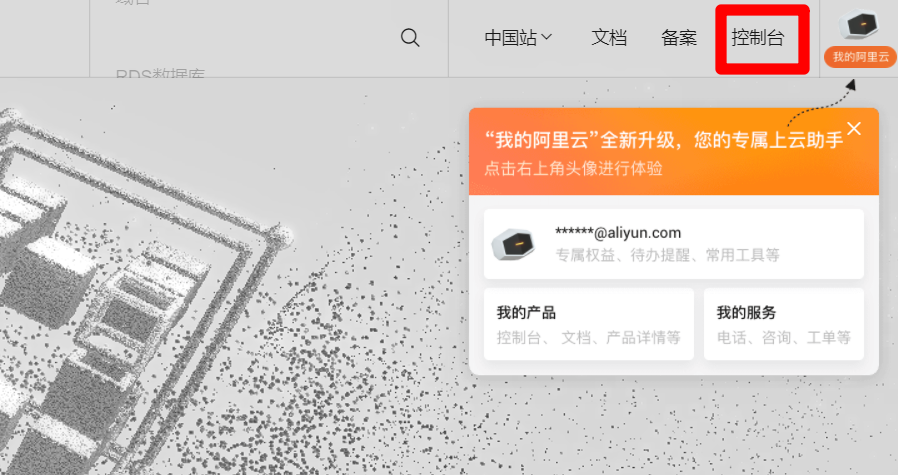
RAM帳號登錄成功後,在阿里雲首頁右上方點擊”控制台”,進入管理控制台頁面。
-
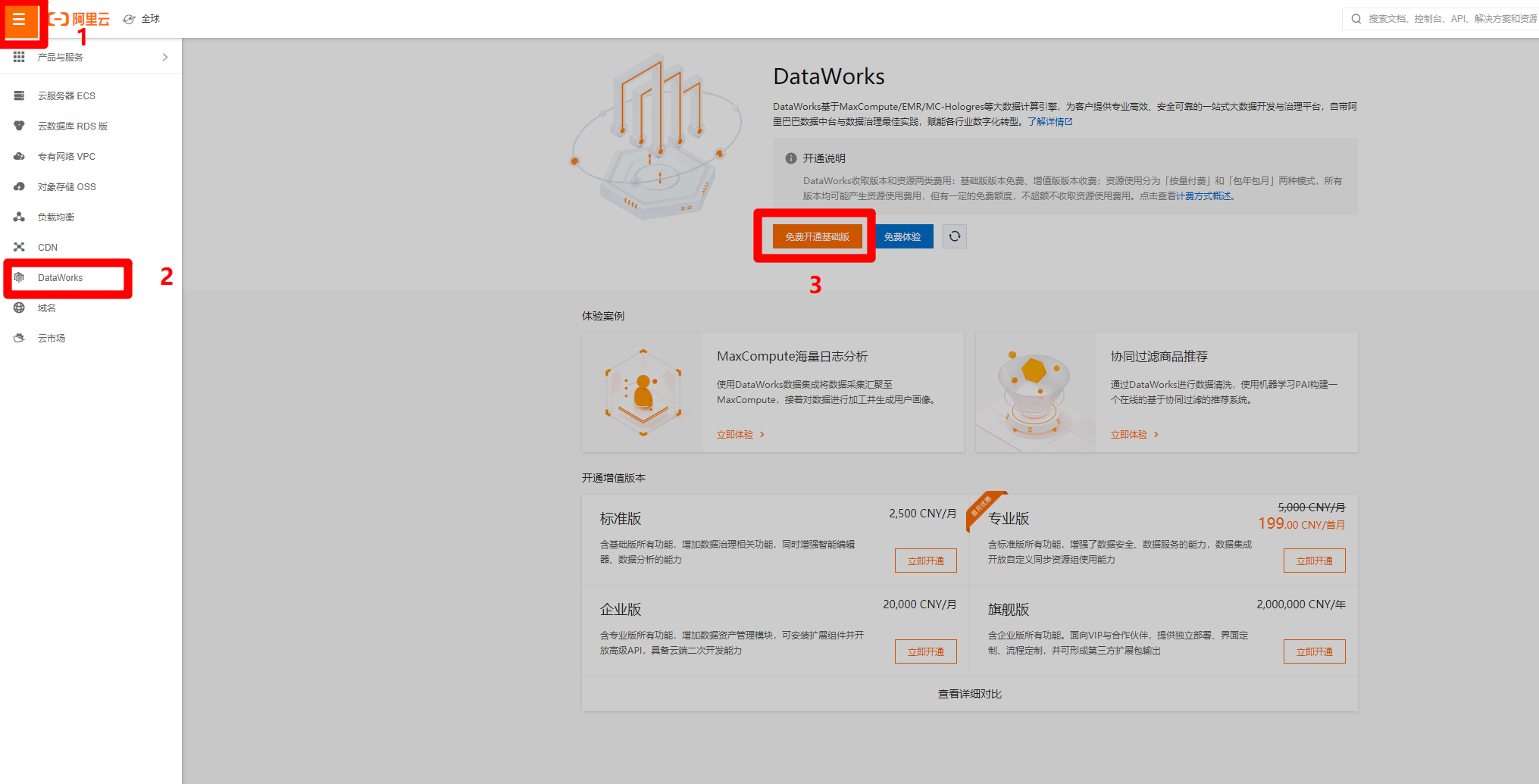
在管理控制台頁面,點擊左上角的菜單按鈕,會出現側邊菜單欄,點擊”DataWorks”標籤,頁面會切換到對應的DataWorks頁面,點擊”免費開通基礎版”,進入DataWorks購買頁面,購買完成後要回到此頁面。
-
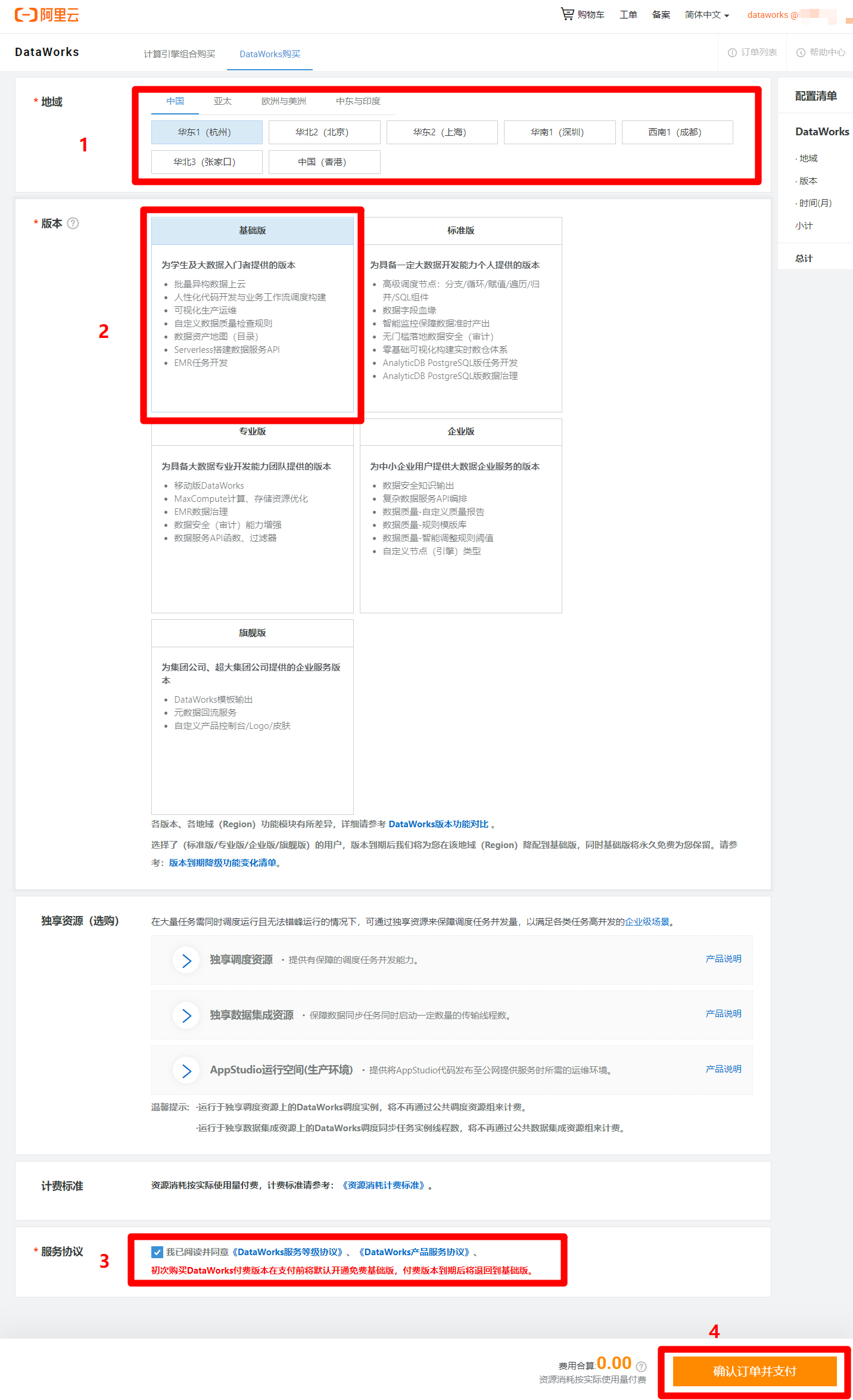
在DataWorks購買頁面,根據自己需求選擇地域(可以選擇離自己最近的地域),版本選擇基礎版(其他版本需要付費)即可滿足本次實踐需求,然後勾選同意服務協議,點擊”確認訂單並支付”,完成DataWorks基礎版的開通。
-
完成DataWorks基礎版的開通後,回到剛才的管理控制台頁,重新點擊”DataWorks”標籤,可以進入新的DataWorks控制台頁,點擊左側菜單欄的”工作空間列表”,切換到工作空間列表頁,點擊”創建工作空間”按鈕,準備創建一個新的工作空間。
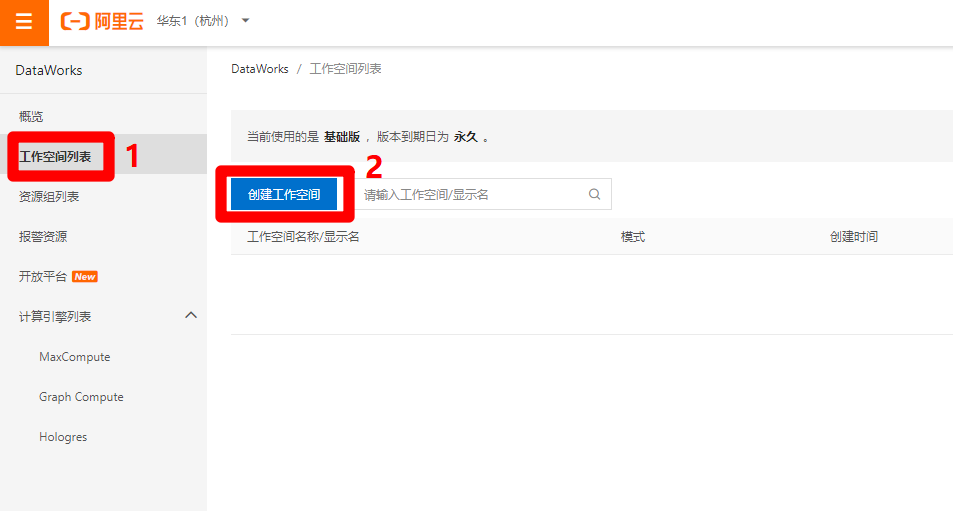
-
點擊”創建工作空間”按鈕後,頁面右側會彈出邊欄,填寫工作空間名稱等資訊,為簡化操作流程,本次實踐選擇”簡單模式”進行演示,完成後點擊”下一步”,將選擇工作空間引擎。
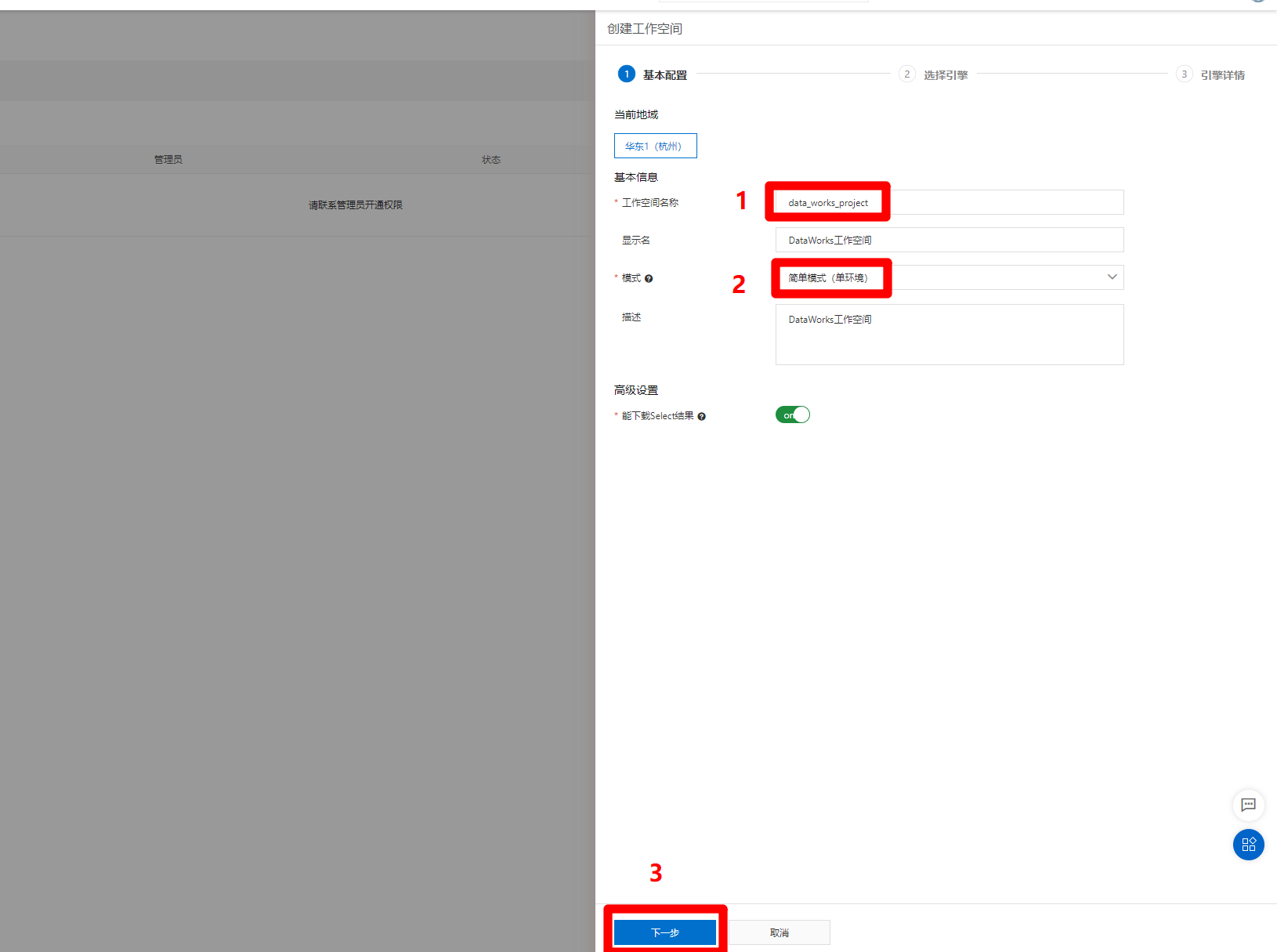
-
進入選擇引擎頁面,需要選擇計算引擎服務為MaxCompute,此時還未開通MaxCompute服務,點擊”MaxCompute”標籤里的”按量付費”選項後的”去購買”鏈接,跳轉到MaxCompute購買頁面,購買完成後要回到此頁面。
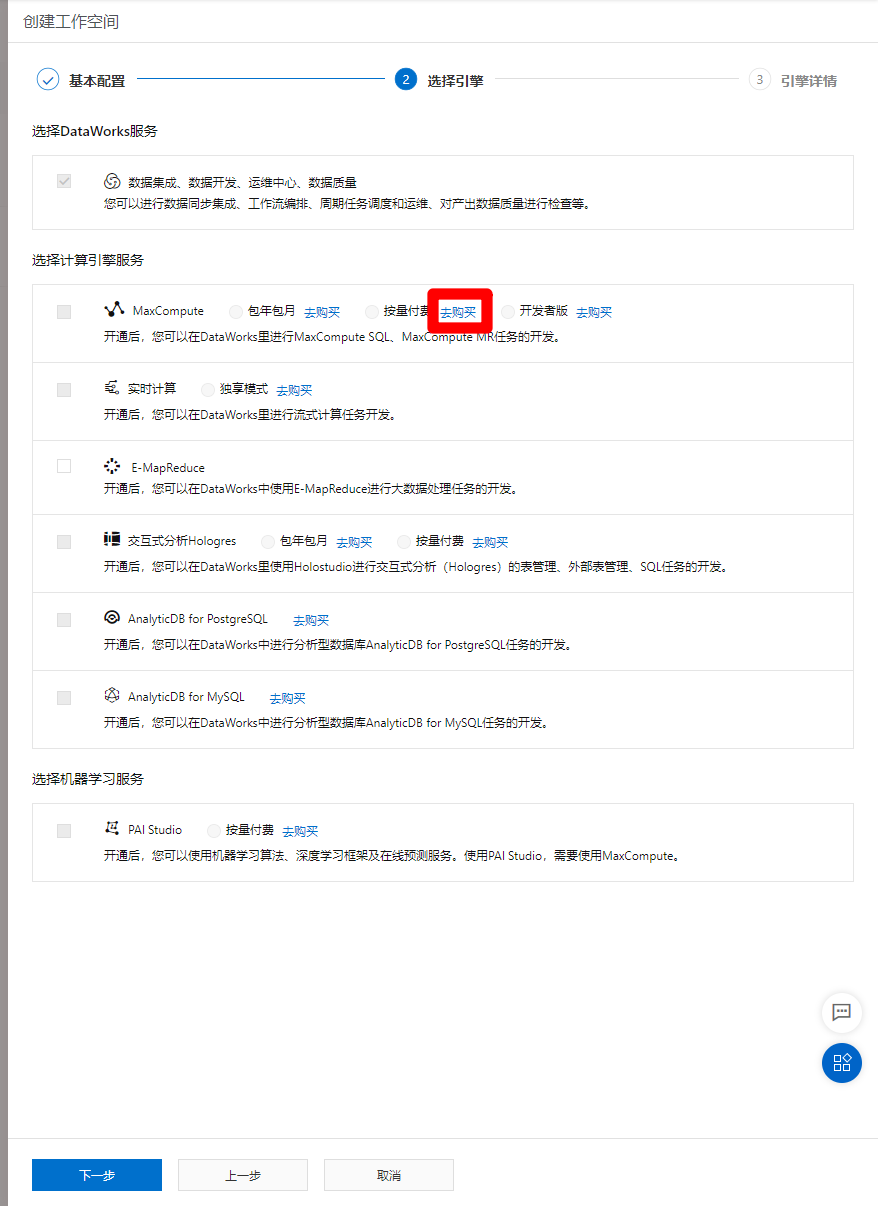
-
進入MaxCompute購買頁面,商品類型選擇”按量計費”,區域根據自己的需求選擇,規格類型選擇”標準版”,然後點擊”立即購買”,完成MaxCompute服務的激活。
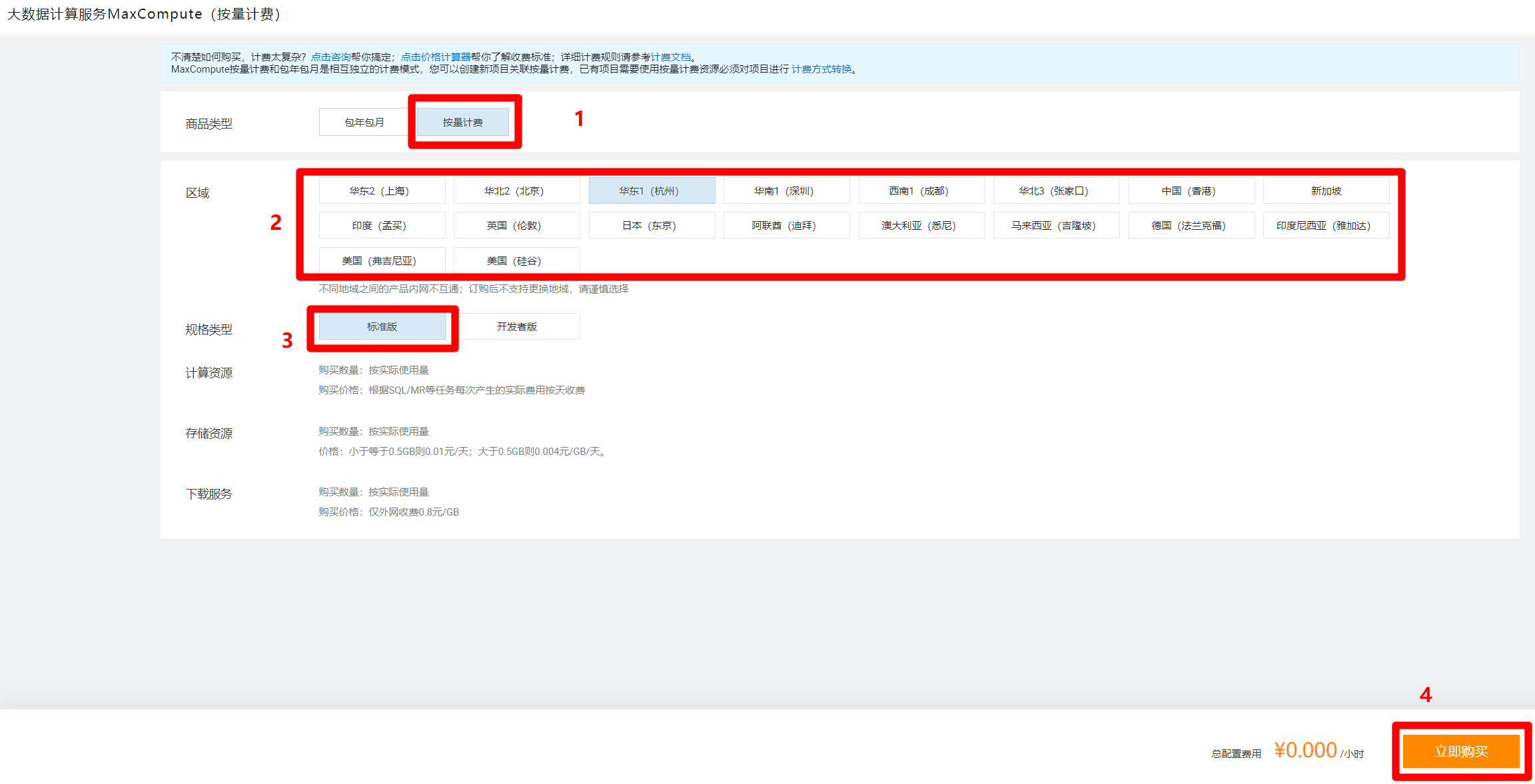
-
MaxCompute服務激活後,回到創建工作空間的選擇引擎頁面,選中”MaxCompute”標籤里的”按量付費”選項(若頁面沒有刷新,無法選中,點一下”上一步”,再點一下”下一步”來刷新頁面),然後點擊”下一步”,準備配置引擎詳情。
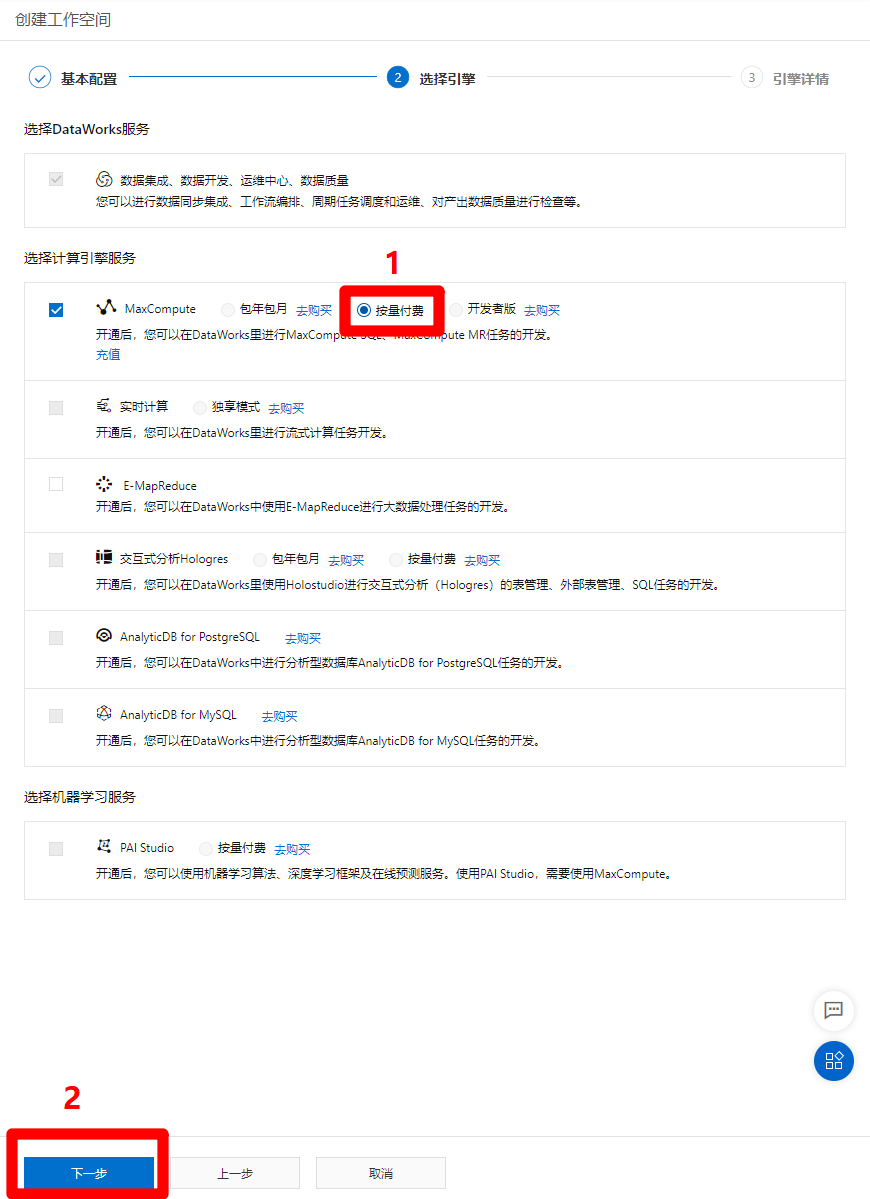
-
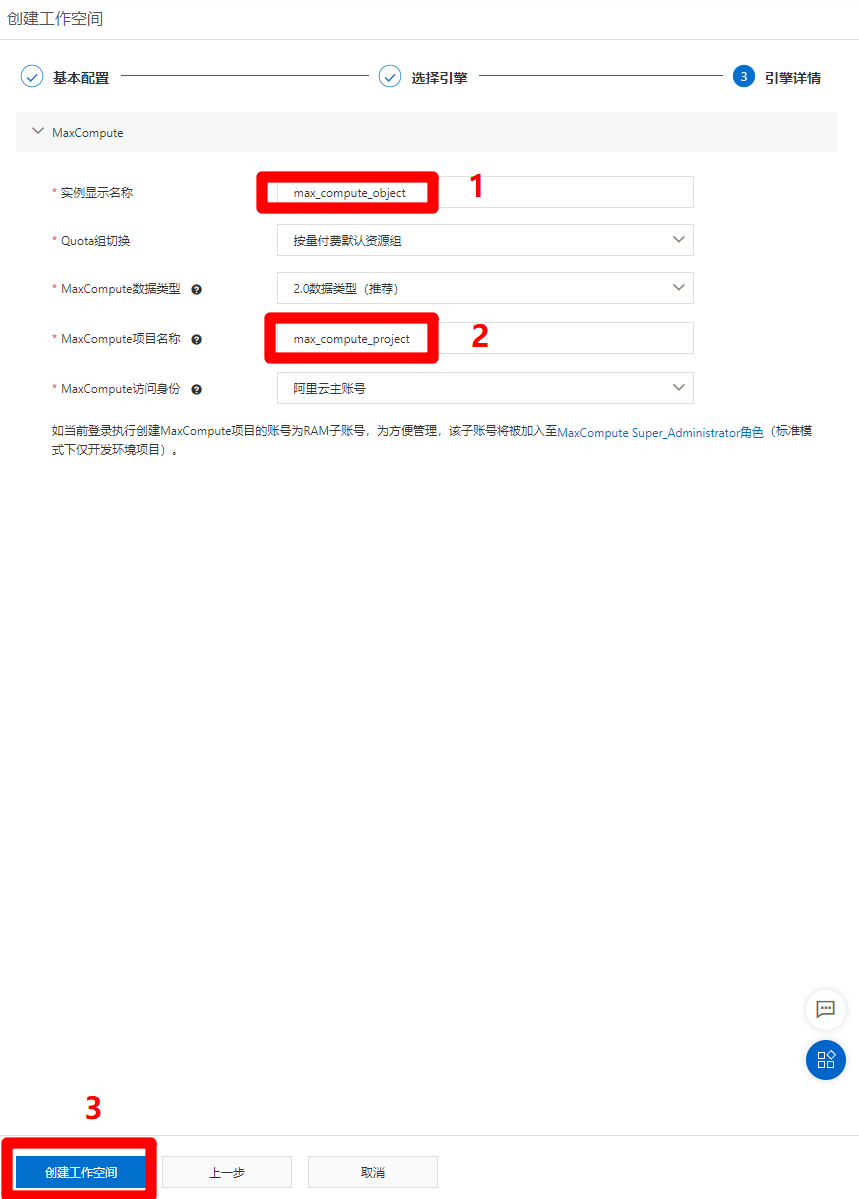
進入引擎詳情頁面,自主填寫實例顯示名稱和MaxCompute項目名稱,其他配置選項保持默認即可,然後點擊”創建工作空間”,完成工作空間的創建。
-









三、購買獨享數據集成資源組並綁定
-
注意:由於本人在其他業務流程中使用了數據集成中”一鍵實時同步至MaxCompute的功能”(不支援MongoDB數據源),而實時同步功能僅支援運行在獨享數據集成資源組上,因此購買了獨享數據集成資源組。而本次實踐中也就使用了之前購買的獨享數據集成資源組(不用白不用)。而本次實踐由於只使用了離線同步功能,也可使用公共資源組(免費)進行數據集成,如要使用公共資源組,可跳過此步驟。
-
官方文檔:新增和使用獨享數據集成資源組
-
步驟圖示:
-
進入DataWorks控制台頁面,在左側菜單欄切換到”工作空間列表”頁面,點擊頁面右上角的”購買獨享資源組”,打開DataWorks獨享資源購買頁面。
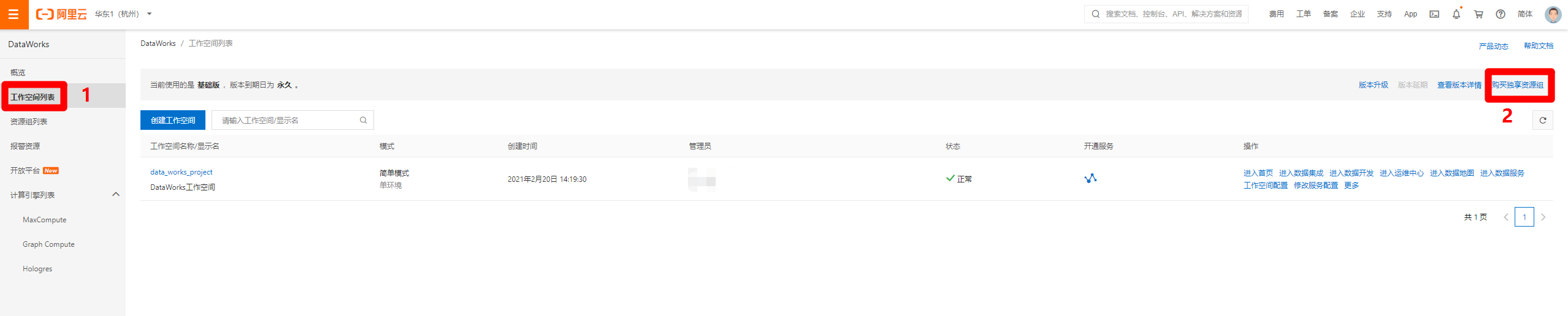
-
進入DataWorks獨享資源購買頁面,根據自己的需求選擇地域和可用區(要與工作空間所在的地域相同),獨享資源類型選擇”獨享數據集成資源”,本次實踐只需購買最低限度的獨享集成資源,因此下面選項依次選擇”4 vCPU 8 GiB”、”1″、”1個月”,然後點擊”立即購買”,完成獨享數據集成資源的購買。
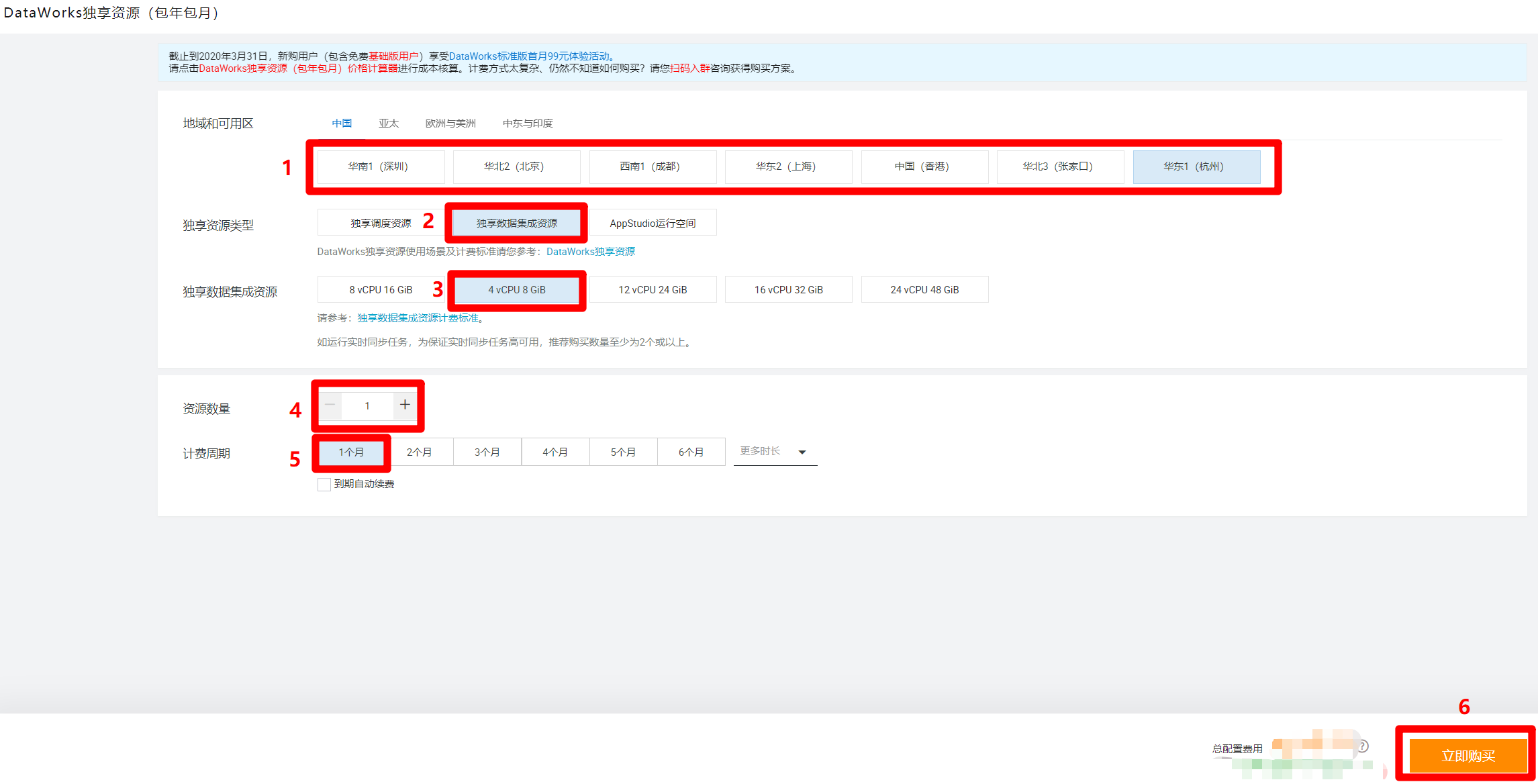
-
完成獨享數據集成資源組的購買後,進入DataWorks控制台頁面,在左側菜單欄切換到”資源組列表”頁面,然後點擊”創建獨享資源組”,會出現右側邊欄。資源組類型選擇”獨享數據集成資源組”,資源組名稱自主填寫,資源組備註自主填寫,訂單號選擇剛才購買的獨享數據集成資源的訂單號,然後點擊”確定”,完成獨享數據集成資源組的創建。
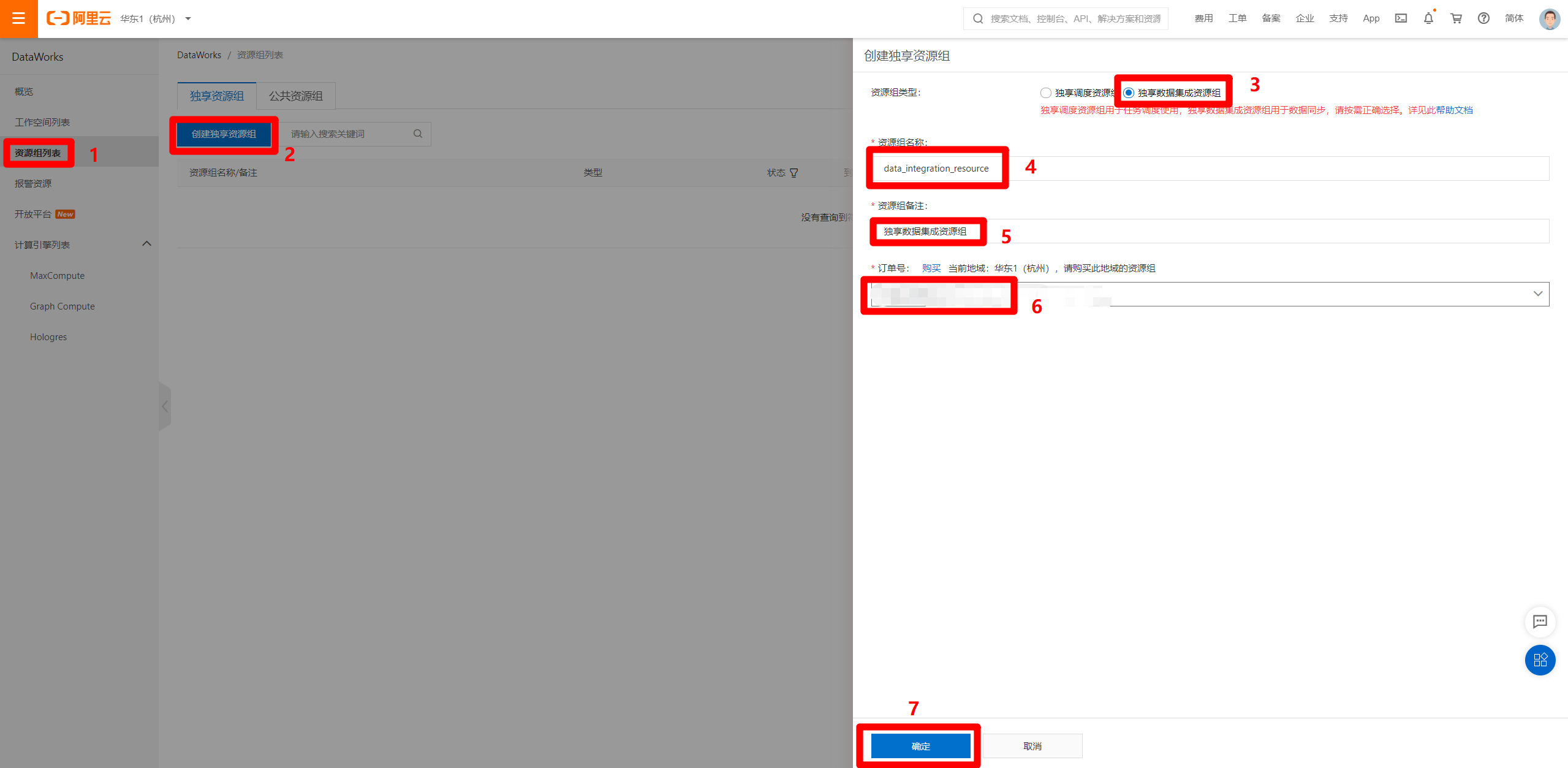
-
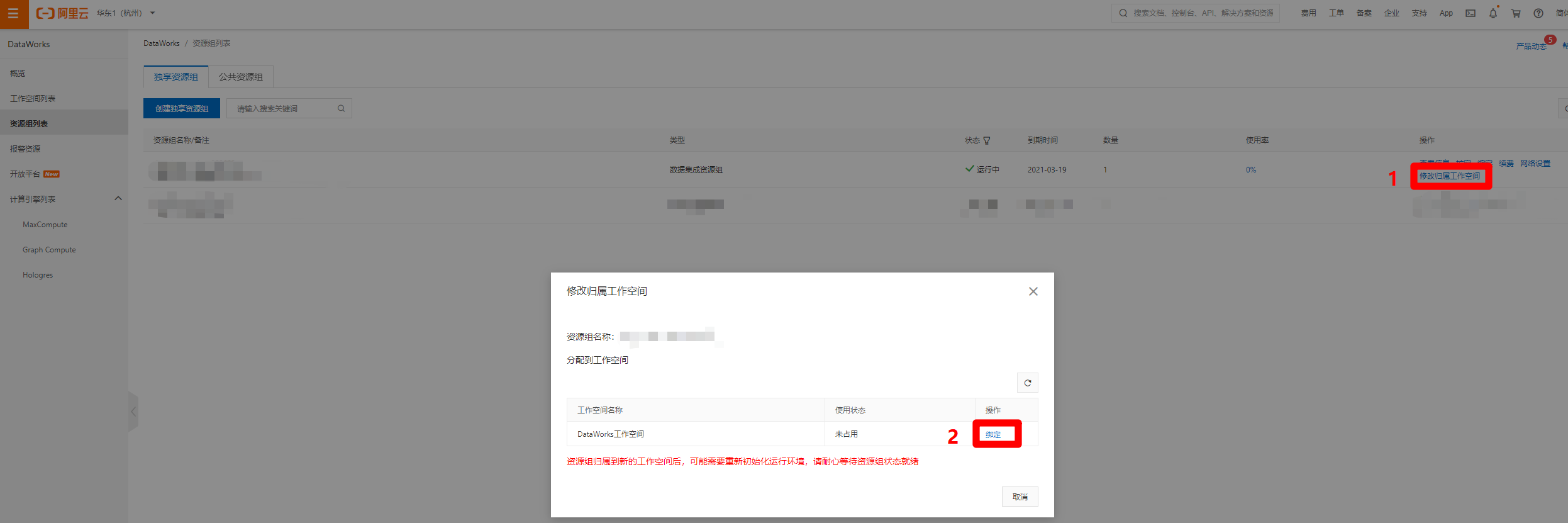
創建好獨享數據集成資源組後,在資源組列表頁面中,點擊剛創建完成的資源組右端的”修改歸屬工作空間”鏈接,會出現修改歸屬工作空間的彈出框,選擇剛才創建的工作空間,點擊右端對應的”綁定”,完成獨享數據集成資源組與工作空間的綁定。
-




四、創建並配置數據源
-
官方文檔:配置數據源
-
步驟圖示:
-
在DataWorks控制台的工作空間列表頁面中,點擊目標工作空間右端”操作”列中的”進入數據集成”鏈接,打開數據集成頁面。

-
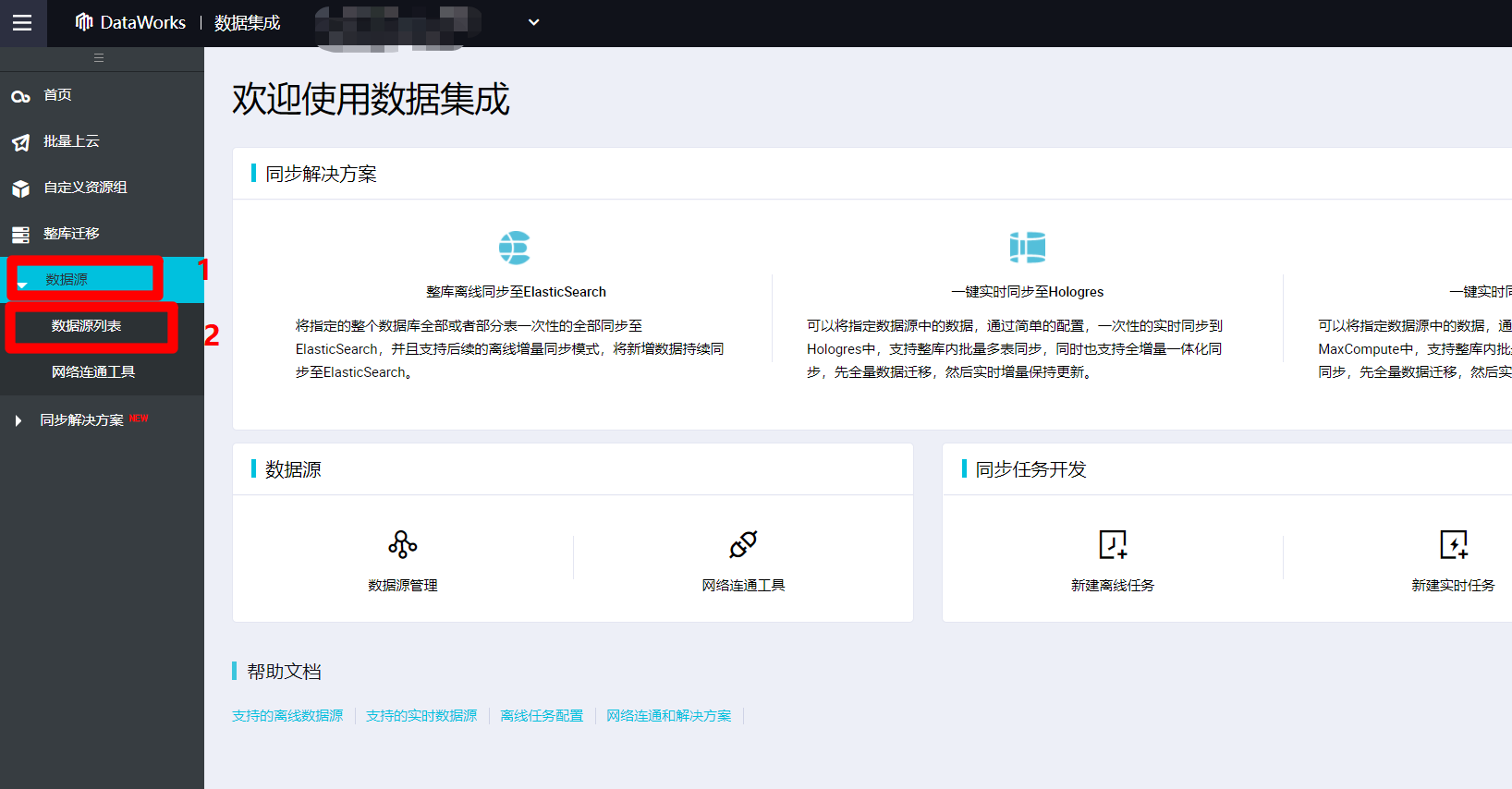
進入數據集成頁面中,點擊展開左側菜單欄中的”數據源”項,在其展開的子菜單中,點擊”數據源列表”,打開數據源管理頁面。
-
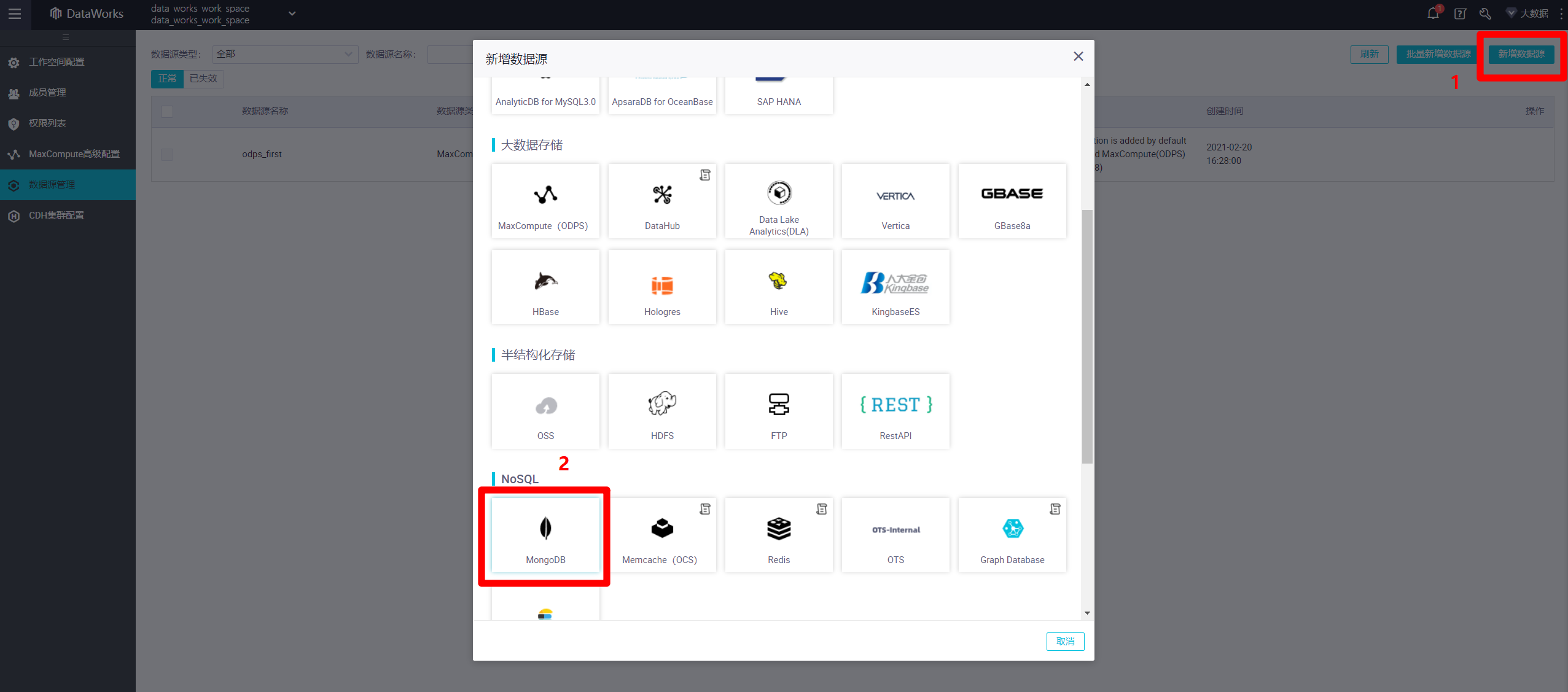
進入數據源管理頁面中,點擊頁面右上角的”新增數據源”,會出現新增數據源的彈出框。本次實踐的目標數據源為MongoDB資料庫,因此在彈出框中找到”NoSQL”標籤下”MongoDB”圖標,點擊該圖標,會出現新的”新增MongoDB數據源”彈出框。
-
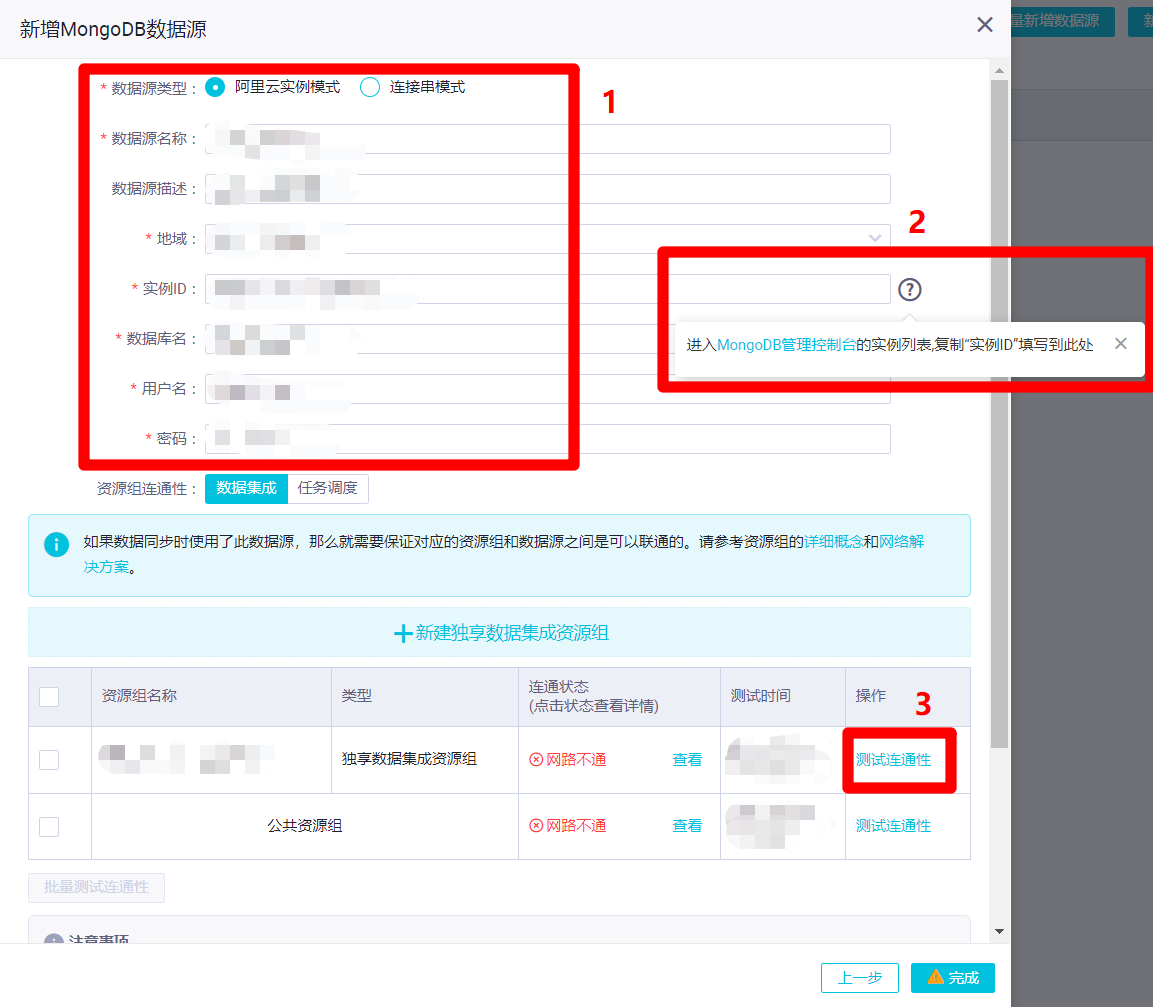
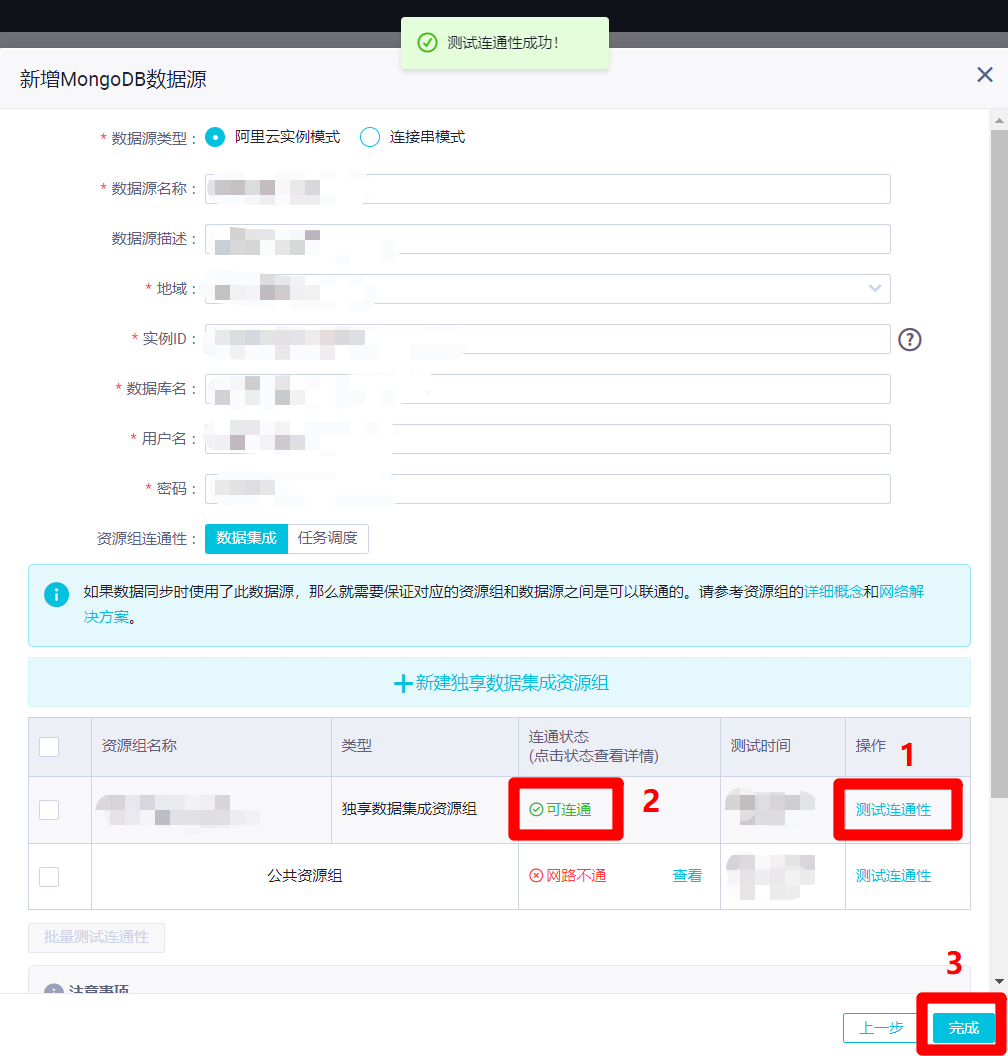
在新增MongoDB數據源的彈出框中,需要填寫數據源相關資訊。本次實踐的MongoDB數據源為阿里云云資料庫MongoDB版,所以數據源類型選擇”阿里雲實例模式”,自主填寫數據源名稱和數據源描述,地域選擇數據源所在地域,實例ID填寫數據源的實例ID(通過後面的問號圖標,可進入MongoDB管理控制台的實例列表,複製”實例ID”填寫),自主填寫正確的資料庫名、用戶名、密碼。然後點擊下面表格中”獨享數據集成資源組”這一行的”測試連通性”,此時會連通失敗,需要添加獨享數據集成資源綁定的交換機網段至資料庫的白名單內(若使用的是公共資源組,則需要添加DataWorks工作空間所在區域的白名單IP至資料庫的白名單內)。因此下一步要打開DataWorks控制台的”資源組列表”頁面去找到相關資訊。
-
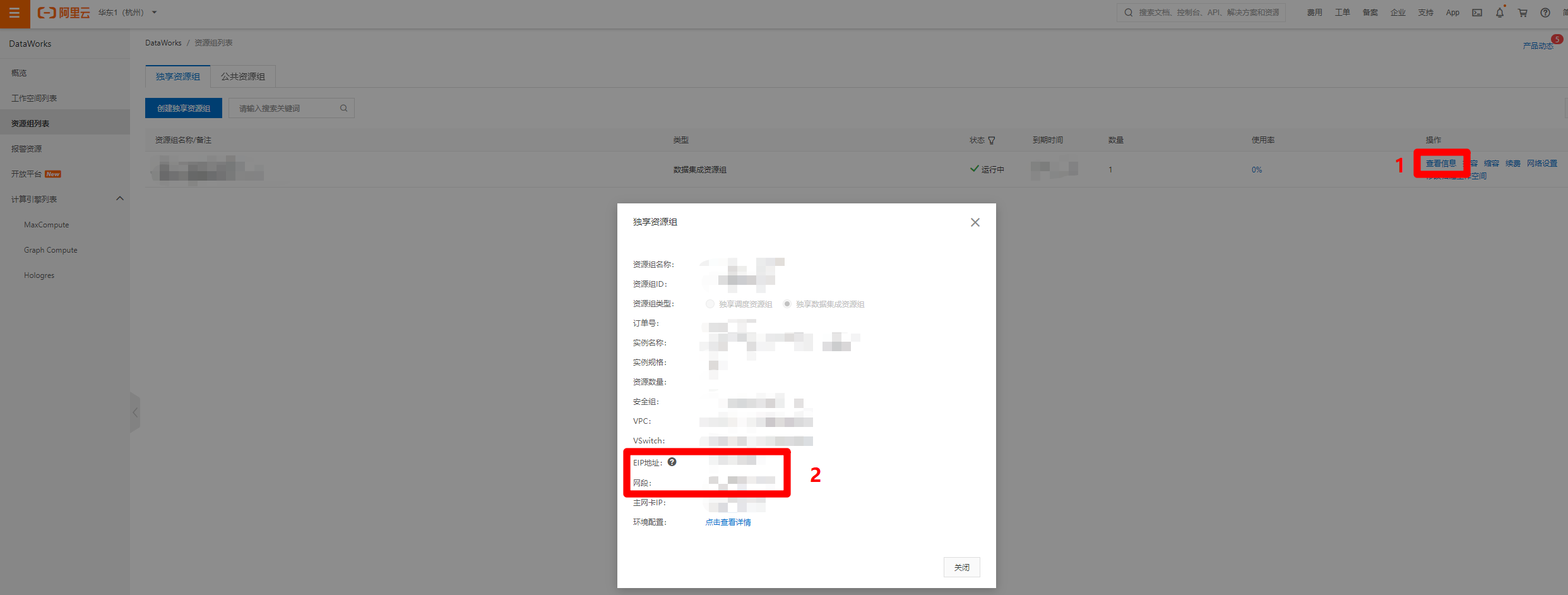
進入”資源組列表”頁面中,點擊目標獨享數據集成資源組的”操作”列中的”查看資訊”鏈接,會出現”獨享資源組”的彈出框,複製”EIP地址”和”網段”的內容,下一步打開MongoDB管理控制台,準備添加資料庫的IP白名單。
-
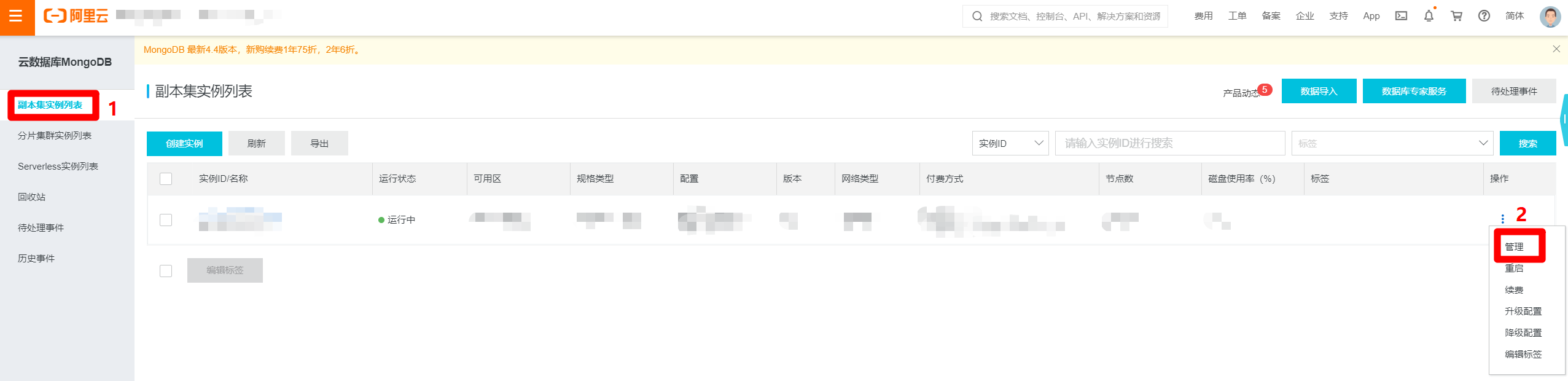
進入MongoDB管理控制台,選擇”副本集實例列表”,找到目標MongoDB實例的行,展開後面的”操作”列,點擊”管理”選項,打開目標MongoDB實例的管理頁面。
-
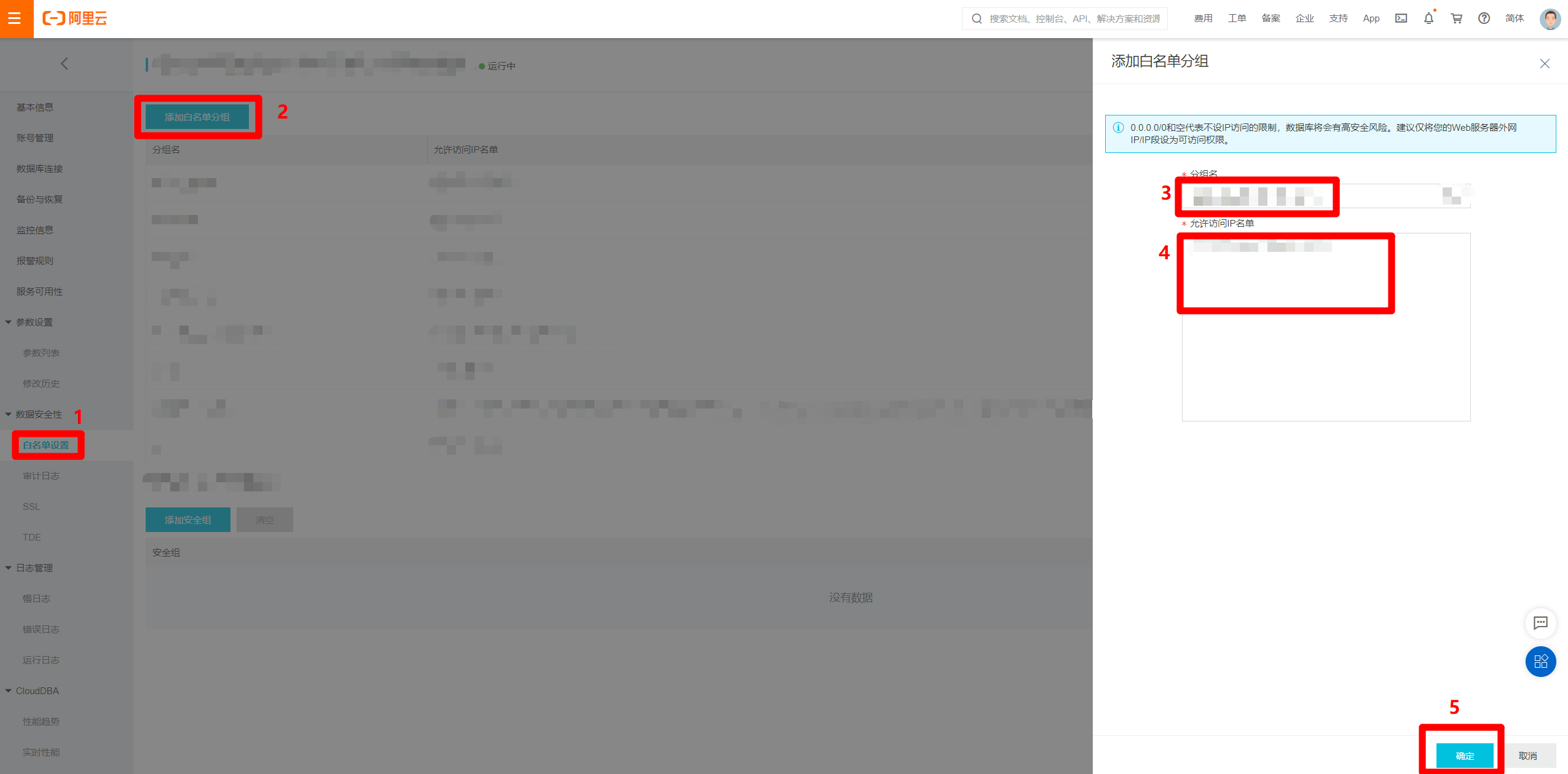
進入MongoDB實例的管理頁面中,在左側菜單欄點擊”白名單設置”切換到對應頁面。點擊頁面中的”添加白名單分組”按鈕,會出現右側”添加白名單分組”邊欄。在邊欄中自主填寫分組名,並將剛才獨享資源組的”EIP地址”和”網段”的內容填寫到”允許訪問IP名單”文本框中,用英文逗號分隔,然後點擊”確定”,完成將獨享資源組網段添加到數據源白名單的操作,下一步回到新增MongoDB數據源的頁面。
-
在新增MongoDB數據源的頁面中,再次點擊”測試連通性”,此時連通狀態變為”可連通”,然後點擊”完成”,完成MongoDB數據源的創建。
-
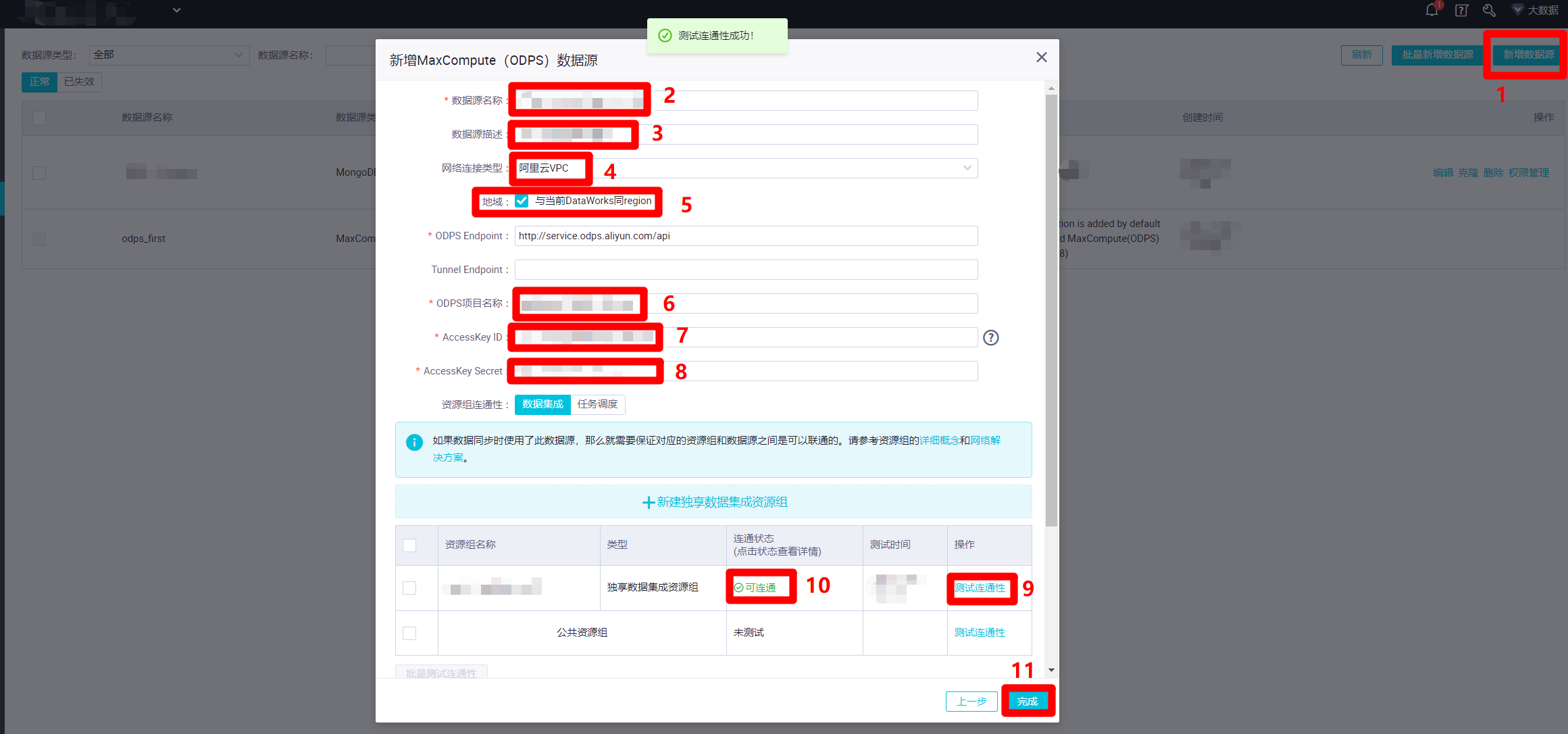
同理,也創建一個新的MaxCompute數據源(默認的MaxCompute數據源”odps_first”直接用來運行任務會出問題)。在數據源管理頁面中,點擊”新增數據源”,會出現”新增MaxCompute(ODPS)數據源”彈出框。在彈出框中,自主填寫”數據源名稱”、”數據源描述”,”網路連接類型”選擇”阿里雲VPC”,”地域”勾選”與當前DataWorks同region”,”ODPS項目名稱”填寫當前的DataWorks工作空間名稱,”AccessKey ID”填寫當前登錄的RAM帳號的AccessKey ID,”AccessKey Secret”填寫當前登錄的RAM帳號的AccessKey Secret。然後同樣點擊下面表格中”獨享數據集成資源組”這一行的”測試連通性”,確認”連通狀態”為”可連通”。點擊”完成”,完成MaxCompute數據源的創建。
-









五、配置並創建MaxCompute表
-
官方文檔:創建MaxCompute表
-
步驟圖示:
-
在DataWorks控制台的工作空間列表頁面中,點擊目標工作空間所在行的”操作”列中的”進入數據開發”鏈接,打開”DataStudio(數據開發)”頁面。

-
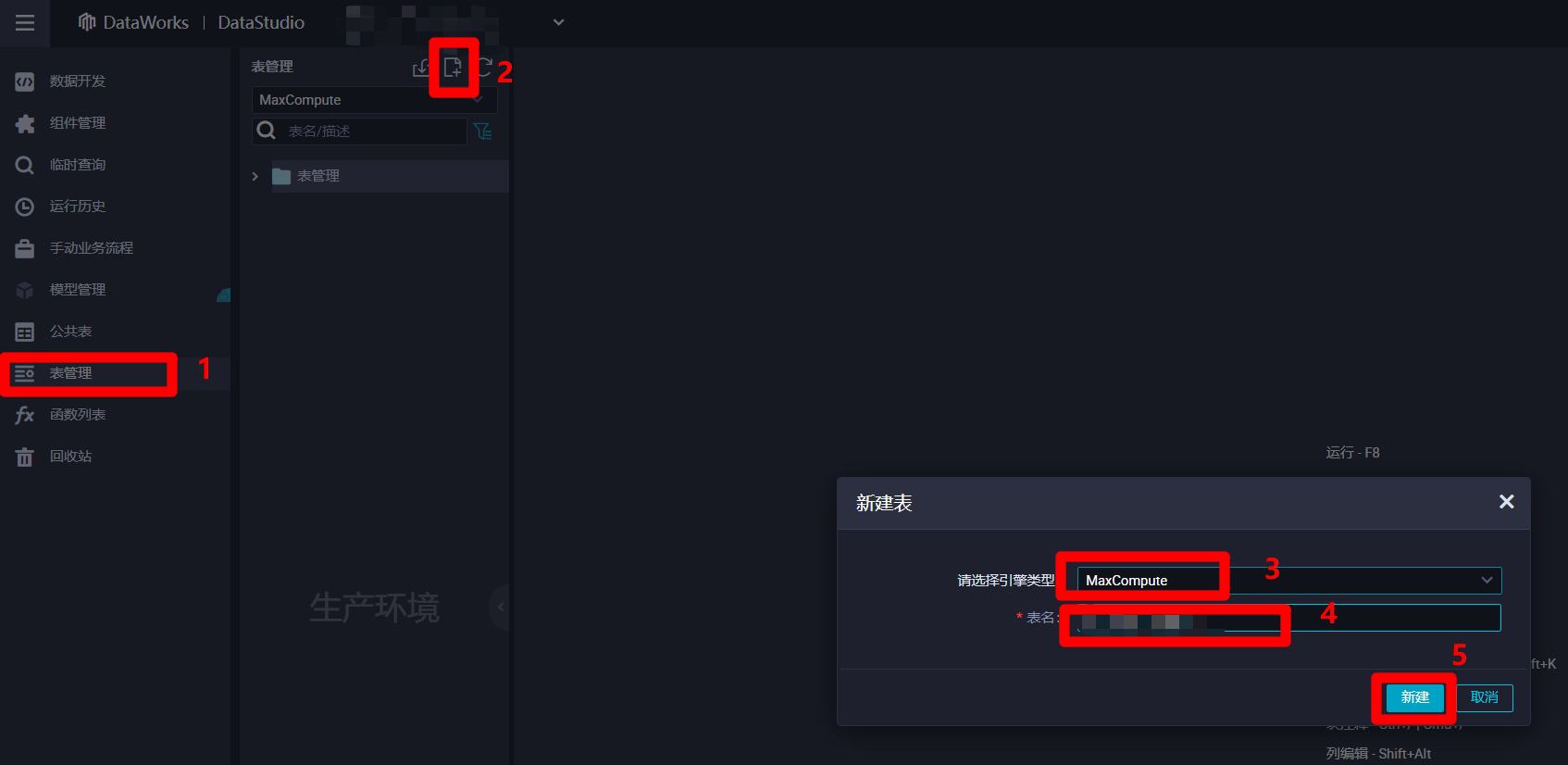
進入”DataStudio(數據開發)”頁面中,點擊左側菜單欄中的”表管理”項,切換到表管理頁面。然後點擊表管理菜單中的新建按鈕,會出現”新建表”彈出框,準備新建一張輸入表用於保存來自數據源的離線同步日誌數據。在彈出框中選擇引擎類型為”MaxCompute”,自主填寫表名,然後點擊新建,會出現MaxCompute表的編輯頁面。
-
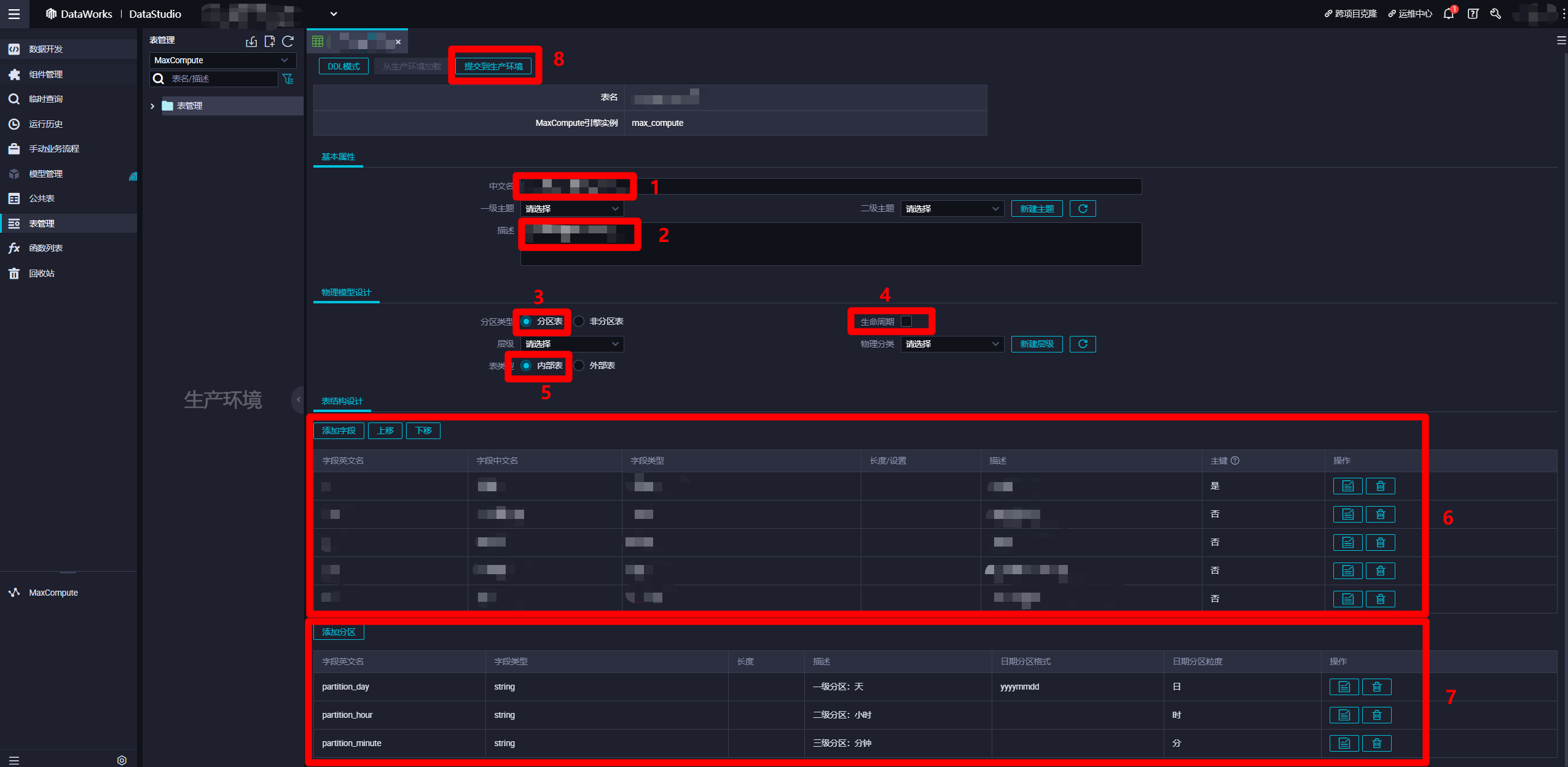
在MaxCompute表的編輯頁面,”基本屬性”模組中,自主填寫”中文名”與”描述”。”物理模型設計”模組中,”分區類型”選擇”分區表”,”生命周期”自主勾選(超過生命周期的未更新數據會被清除),”表類型”選擇”內部表”。”表結構設計”模組中,自主添加欄位,分區添加日、時、分三種粒度的分區,其中日級分區的”日期分區格式”可以填寫日期格式(例如:yyyymmdd)。也可以使用DDL模式設置表結構。設置完表結構後,點擊”提交到生產環境”,完成”輸入表”的創建。同理,自主創建一張類似的”輸出表”,用於保存此次實踐中日誌解析完成後產生的數據。至此完成兩張MaxCompute表的創建。
-



六、創建業務流程
-
官方文檔:創建業務流程
-
步驟圖示:
-
在DataStudio(數據開發)頁面,點擊左側菜單欄中的”數據開發”項,切換到數據開發頁面。然後點擊數據開發菜單中的新建按鈕展開子菜單,點擊子菜單中的”業務流程”,會出現”新建業務流程”彈出框。
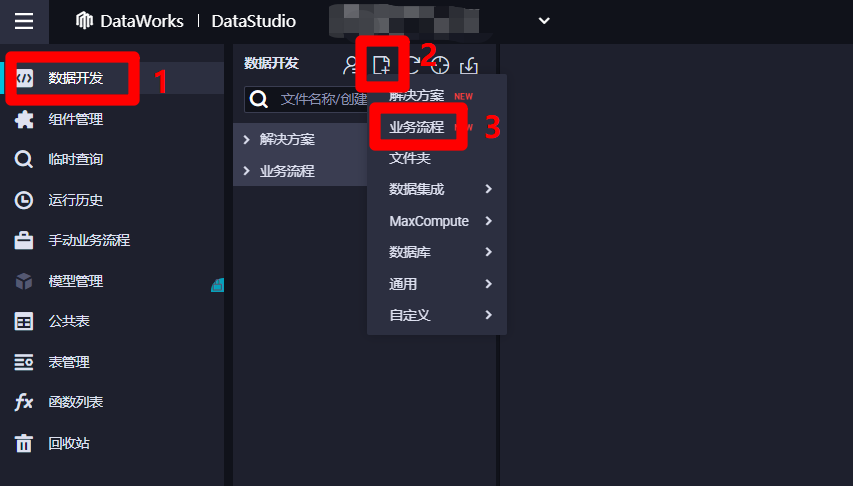
-
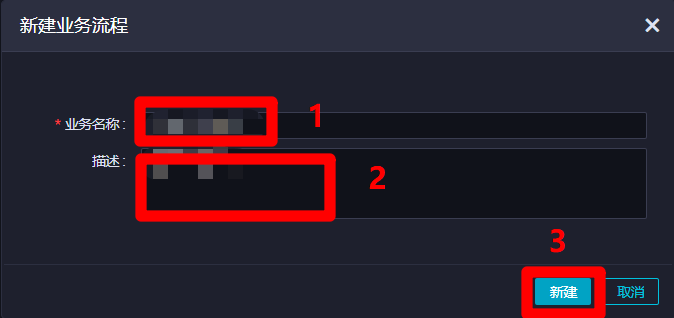
在”新建業務流程”彈出框中,自主填寫”業務名稱”與”描述”,然後點擊”新建”,新建業務流程成功,自動進入該業務流程管理頁面。
-


七、創建並配置離線數據增量同步節點
-
官方文檔:配置離線同步任務
-
步驟圖示:
-
在業務流程管理頁面中,點擊左側節點列表中”數據集成”下的”離線同步”項,會出現”新建節點”彈出框。在彈出框中自主填寫”節點名稱”,然後點擊”提交”,完成離線同步節點的新建。
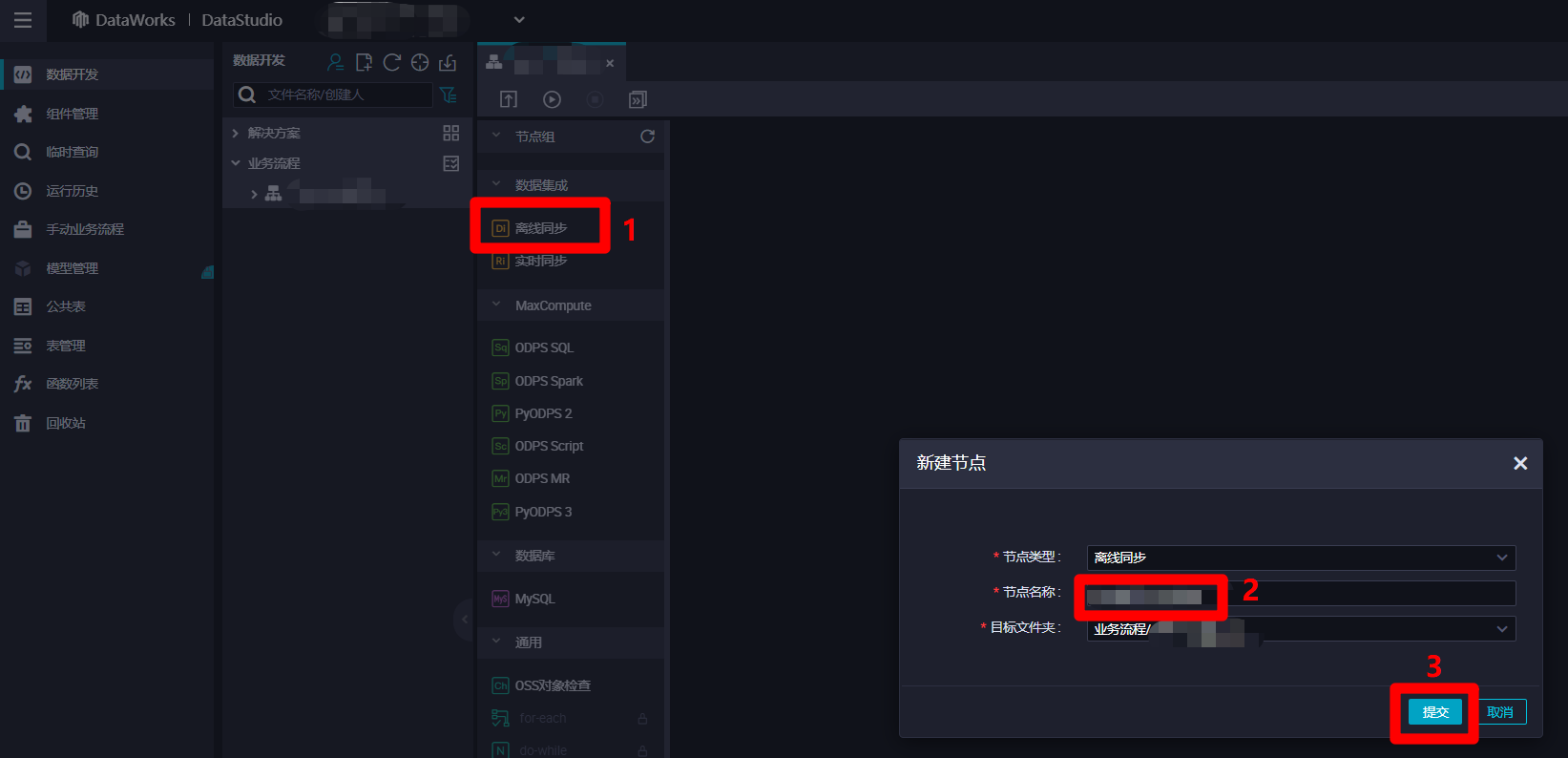
-
離線同步節點新建完成後,業務流程管理頁面中會出現此節點,雙擊該節點圖標,會進入該離線同步節點的配置頁面。
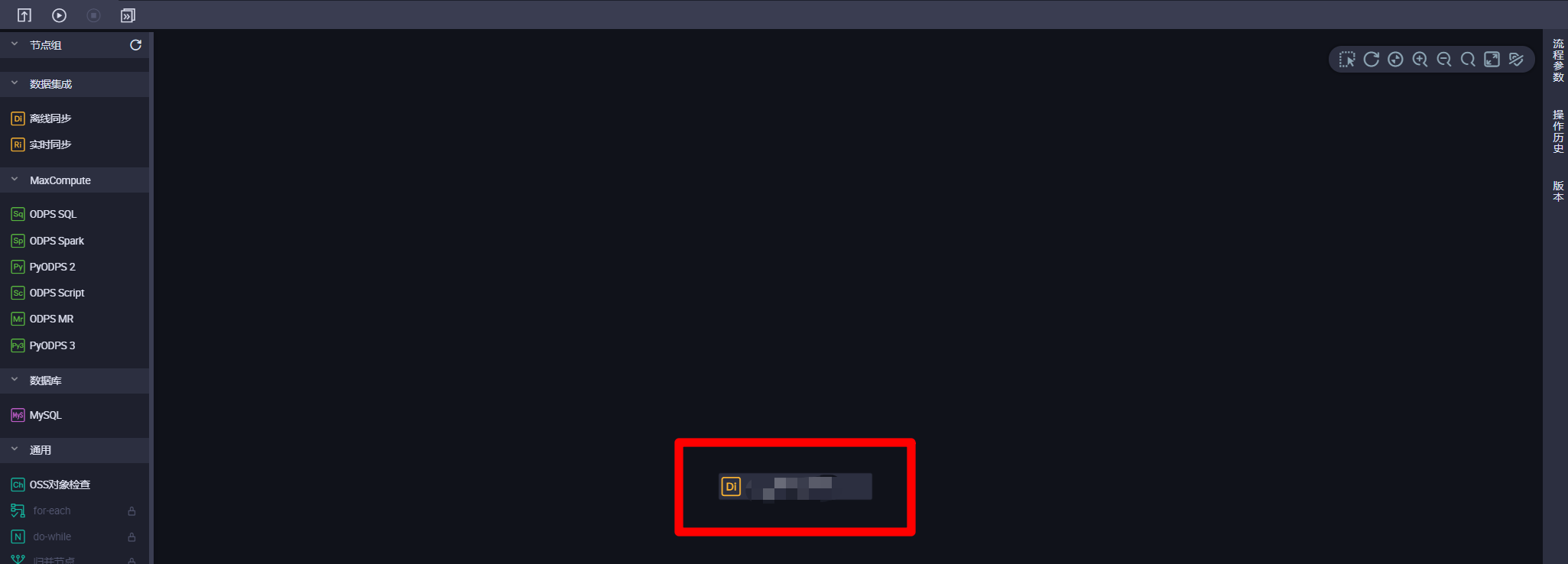
-
進入離線同步節點配置頁面中,展開”01選擇數據源”模組中”數據來源”下”數據源”的下拉菜單,找到並選中”MongoDB”項,選中後會看到提示:此數據源不支援嚮導模式,需要使用腳本模式配置同步任務,點擊轉換為腳本。由於離線同步節點配置嚮導還不支援MongoDB數據源的同步,因此點擊”點擊轉換為腳本”鏈接,節點配置頁面會從嚮導模式轉換為腳本模式。
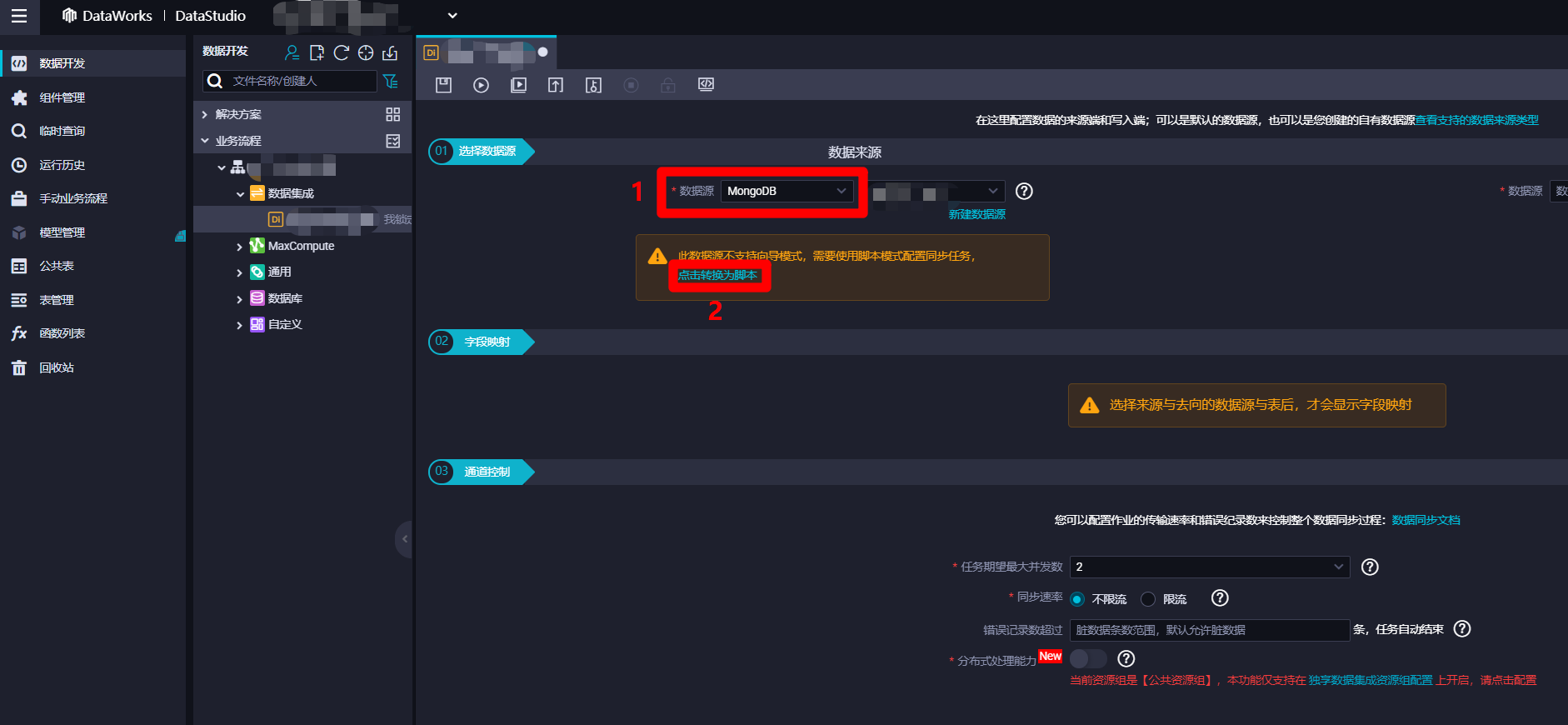
-
在離線同步節點腳本模式配置頁面中,點擊上方菜單欄中的導入模板按鈕,會出現”導入模板”彈出框。在彈出框中,選擇”來源類型”為”MongoDB”,自主選擇目標MongoDB的”數據源”;選擇”目標類型”為”ODPS”,自主選擇目標ODPS的”數據源”。然後點擊”確認”,配置頁面中會自動生成腳本的程式碼模板,下一步在程式碼模板的基礎上進行腳本的完善。
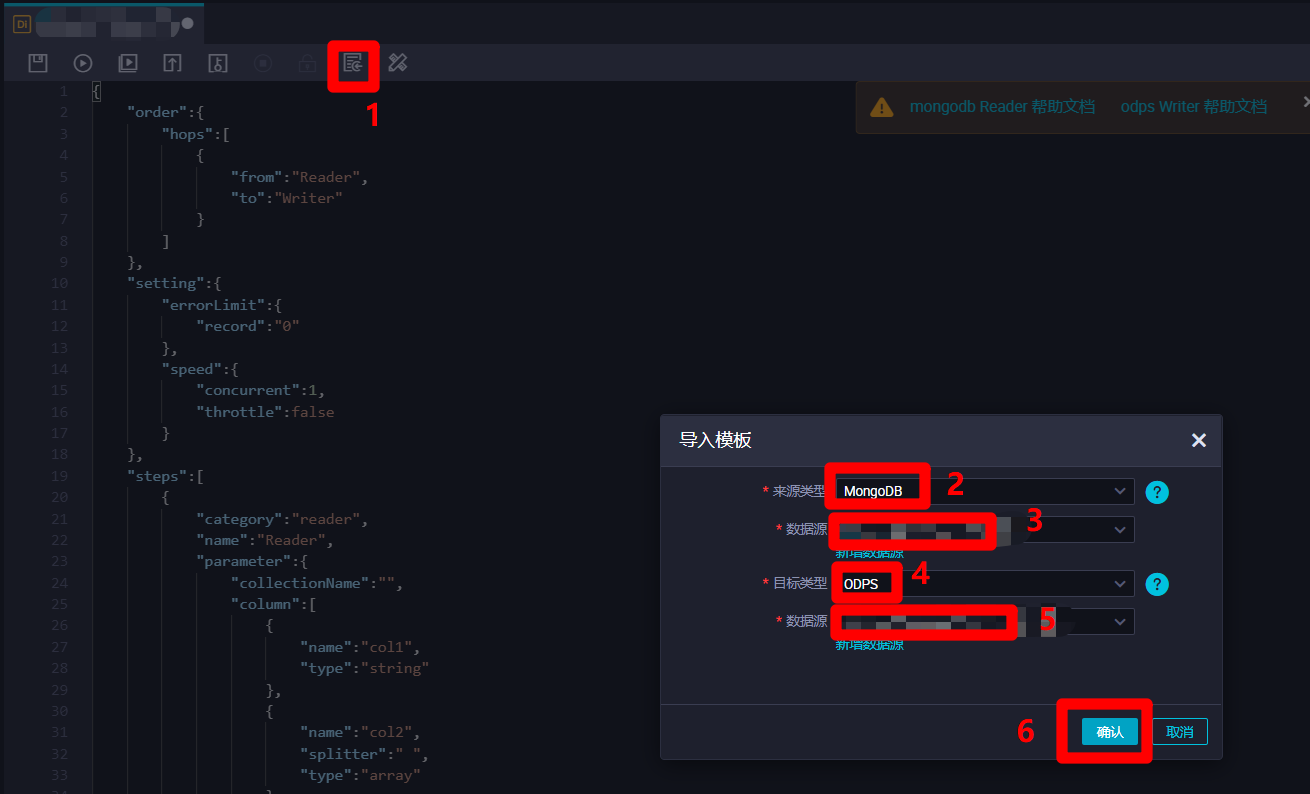
-
在離線同步節點腳本模式配置頁面中,由於要從MongoDB同步到MaxCompute,根據MongoDB Reader和MaxCompute Writer的官方文檔,自主修改完善腳本。在編寫腳本時要注意,由於離線同步任務的最小執行間隔為5分鐘一次,所以此次實踐要在每次離線同步任務定時運行時,獲取MongoDB中,定時任務執行時間往前五分鐘內的數據,塞入MaxCompute輸入表對應的分區中。因此參考DataWorks調度參數的官方文檔,在頁面右端展開”調度配置”邊欄,然後在調度配置邊欄的”基礎屬性”模組下的”參數”文本框中輸入:
yyyy_mm_dd_min=$[yyyy-mm-dd-5/24/60] yyyy_mm_dd_max=$[yyyy-mm-dd] yyyymmdd_min=$[yyyymmdd-5/24/60] hh_mi_min=$[hh24:mi-5/24/60] hh_mi_max=$[hh24:mi] hh_min=$[hh24-5/24/60] mi_min=$[mi-5/24/60]。接下來在腳本程式碼中,在”Reader”部分的”query”項(用於對MongoDB數據進行時間範圍篩選)中填寫內容:{'date':{'$gte':ISODate('${yyyy_mm_dd_min}T${hh_mi_min}:00.000+0800'),'$lt':ISODate('${yyyy_mm_dd_max}T${hh_mi_max}:00.000+0800')}}。此處”${yyyymmdd_min}”等是引用剛才設置的DataWorks調度參數,而”$gte”、”$lt”、”ISODate()”是MongoDB支援的條件操作符號和函數,將獲取數據的時間範圍限制為執行時間往前五分鐘內。下一步,要在腳本程式碼中的”Writer”部分的”partition”項(分區)中填寫內容:partition_day=${yyyymmdd_min},partition_hour=${hh_min},partition_minute=${mi_min}。此處也是引用剛才設置的DataWorks調度參數,設置數據塞入MaxCompute表的分區為執行時間往前五分鐘的時間分區。另外,”Writer”部分的”datasource”項注意要設置為自己新建的MaxCompute數據源。完成腳本的編輯後,下一步進行此離線同步節點的調度配置。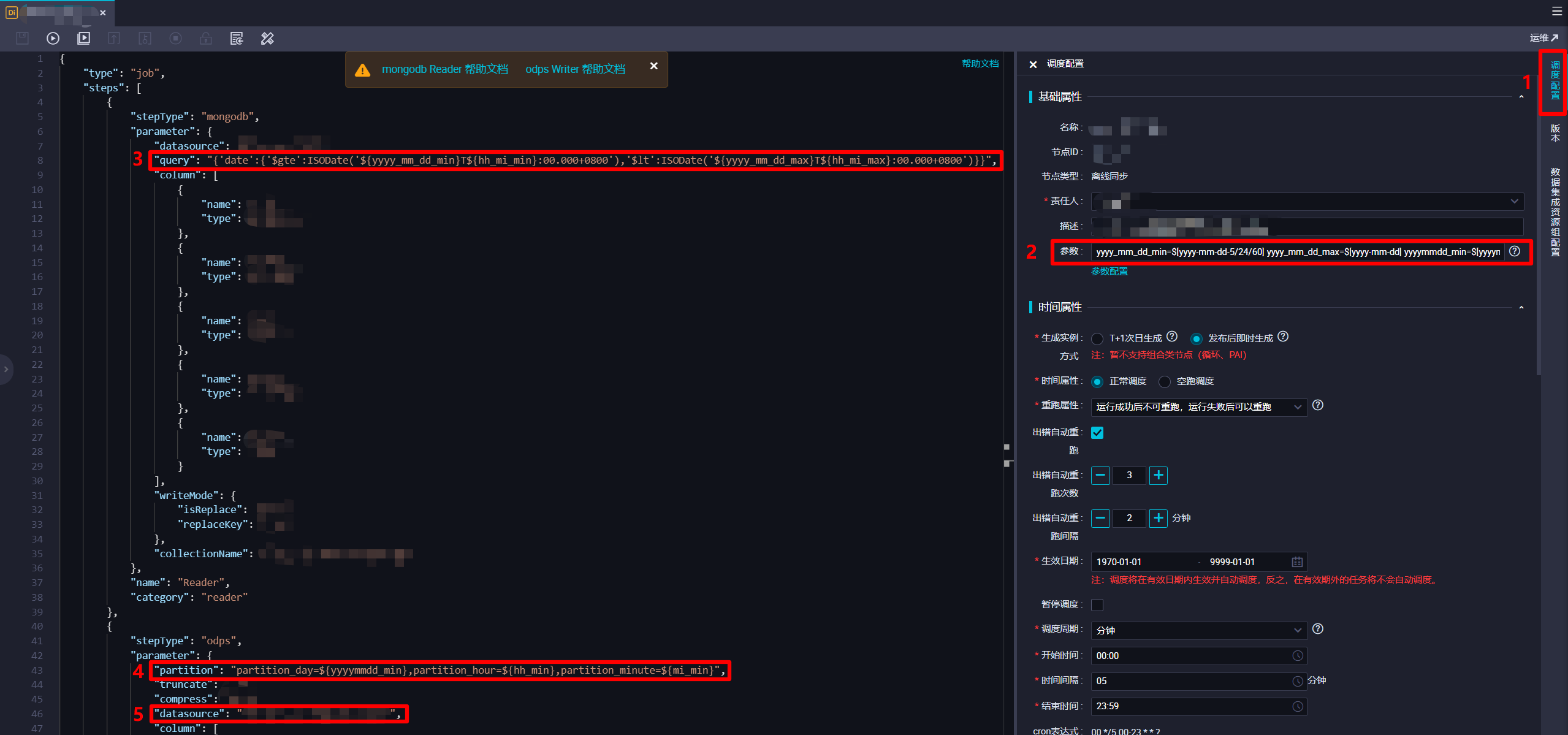
-
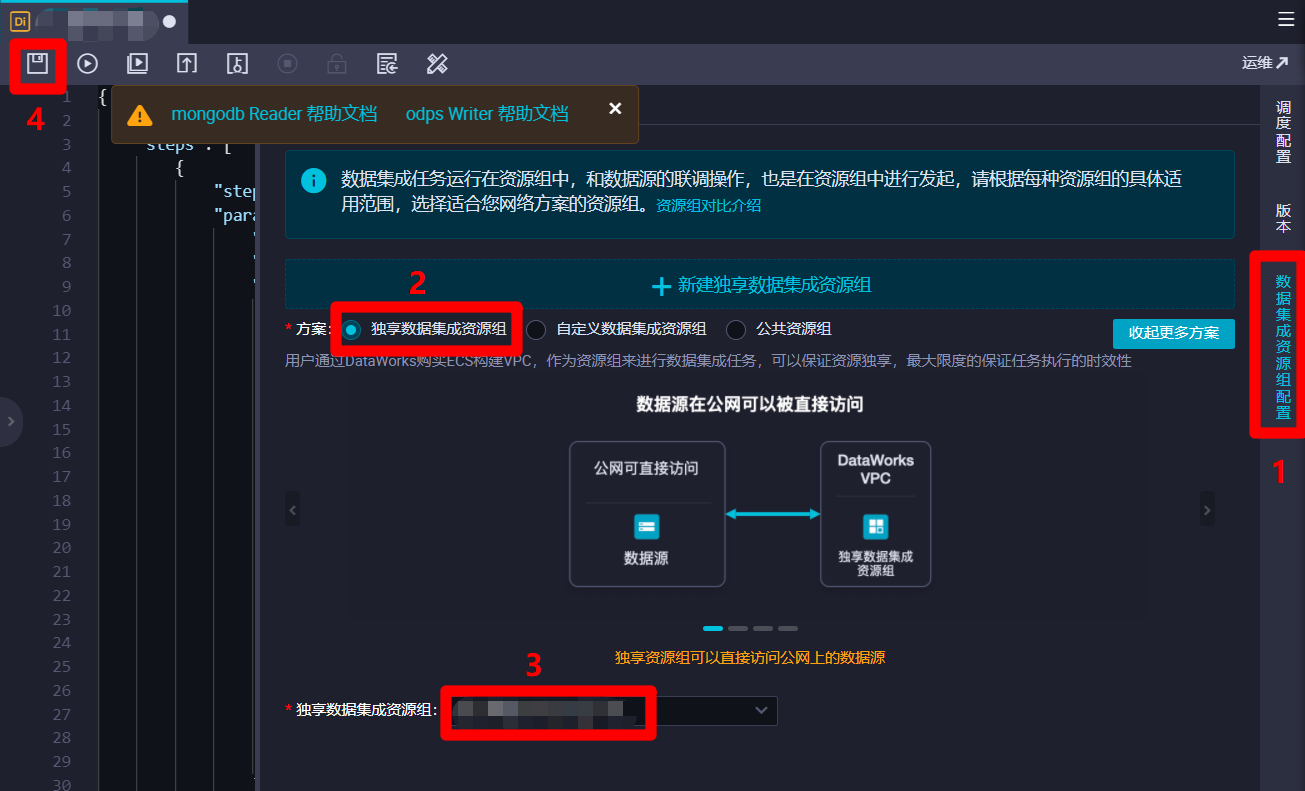
在調度配置邊欄中,對該離線同步節點的調度配置進行完善。在”基礎屬性”模組中,”責任人”選擇當前登錄的RAM帳號;自主填寫”描述”;”參數”的填寫內容上一步中已完成,不再贅述。在”時間屬性”模組中,自主選擇”生成實例方式”,為方便後面快速測試,此次實踐選擇”發布後即時生成”;”時間屬性”選擇”正常調度”;自主選擇”重跑屬性”,通常選擇”運行成功後不可重跑,運行失敗後可以重跑”;勾選”出錯自動重跑”,自主選擇”出錯自動重跑次數”、”出錯自動重跑間隔”,此次實踐使用其默認配置的次數與間隔;自主選擇”生效日期”,此次實踐使用其默認配置,讓同步任務一直保持生效狀態;由於此次實踐希望整個業務流程的運行周期間隔盡量短一些,所以設置”調度周期”為”分鐘”,”開始時間”設置為”00:00″(被限制只能設置整時),”時間間隔”設置為最短的”05″,”結束時間”設置為”23:59″(被限制只能設置小時),以確保該節點跨天也會每五分鐘運行一次;自主選擇”超時時間”,此次實踐選擇”系統默認”;不勾選”依賴上一周期”,這樣某一周期運行出錯不會影響之後的運行周期。”資源屬性”模組的”調度資源組”選擇默認的”公共調度資源組”即可。”調度依賴”模組暫時不進行配置。”節點上下文”模組在此次實踐中不需要配置。完成以上調度配置後,下一步對該節點進行數據集成資源組配置。
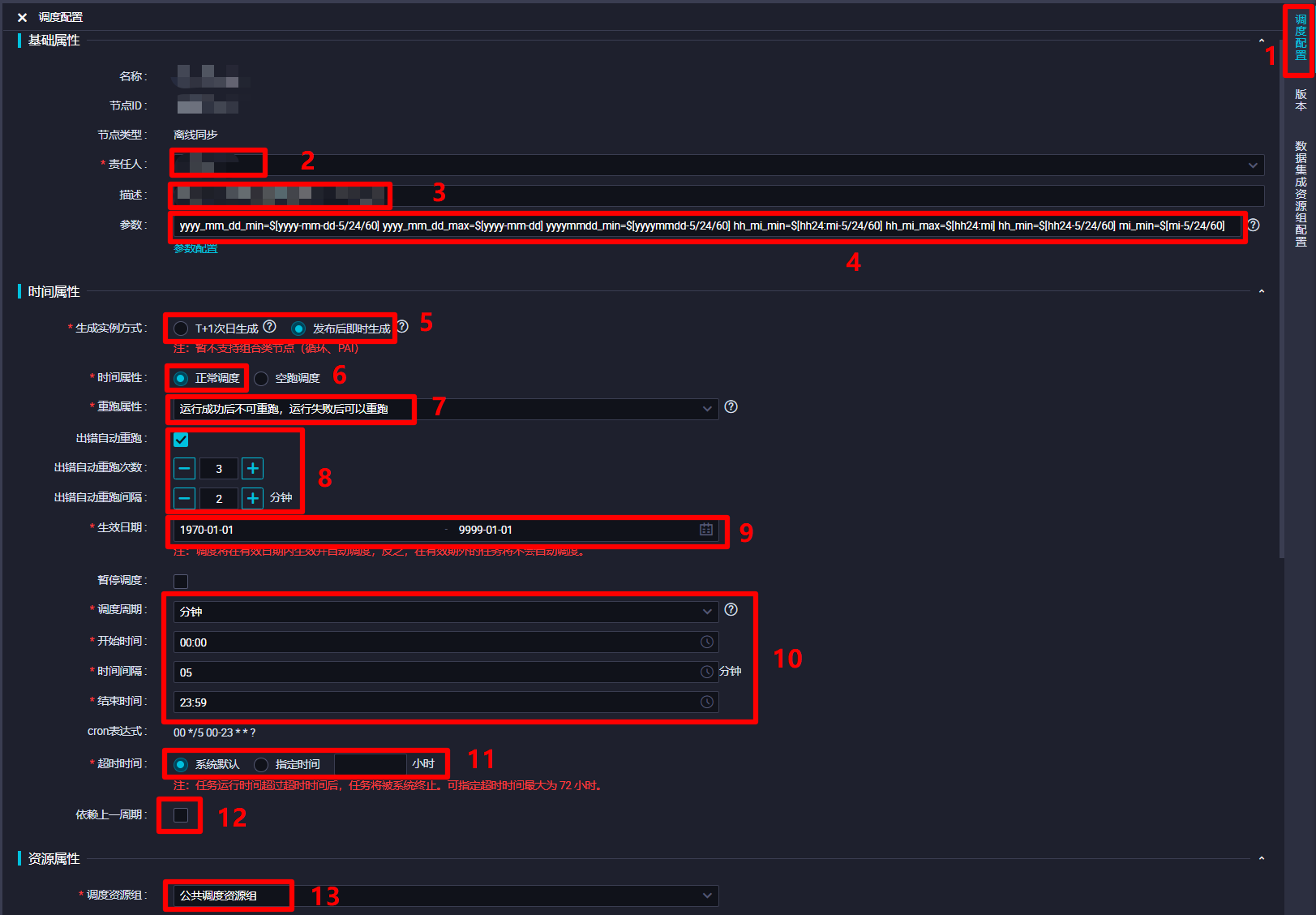
-
點擊頁面右端菜單欄的”數據集成資源組配置”項,將右邊邊欄切換到”數據集成資源組配置”頁面。在邊欄中,”方案”項選擇”獨享數據集成資源組”,然後”獨享數據集成資源組”項自主選擇獨享數據集成資源組。若要使用公共數據集成資源組,”方案”項選擇”公共資源組”即可。數據集成資源組配置完成後,點擊頁面上方菜單欄的保存按鈕,完成對離線同步節點的創建與配置。
-
同理,再創建一個類似的離線同步節點,用於將MaxCompute輸出表的數據同步到MongoDB的集合中。在編寫此腳本時同樣有幾點要注意,在調度配置邊欄的”基礎屬性”模組下的”參數”文本框中輸入:
p_yyyymmdd=$[yyyymmdd-15/24/60] p_hh=$[hh24-15/24/60] p_mi=$[mi-15/24/60]。在腳本的”Reader”部分的”partition”項中填寫內容:partition_day=${p_yyyymmdd}/partition_hour=${p_hh}/partition_minute=${p_mi}。在調度配置邊欄的”時間屬性”模組下,”調度周期”設置”分鐘”,”開始時間”設置”00:00″,”時間間隔”設置”05″,”結束時間”設置”23:59″。這樣該離線同步節點每次運行時會去同步MaxCompute輸出表中十五分鐘前的時間分區的數據。至此完成兩個離線同步節點的創建與配置,下一步準備開發DataWorks的MapReduce功能的JAR包,用於對日誌數據進行解析。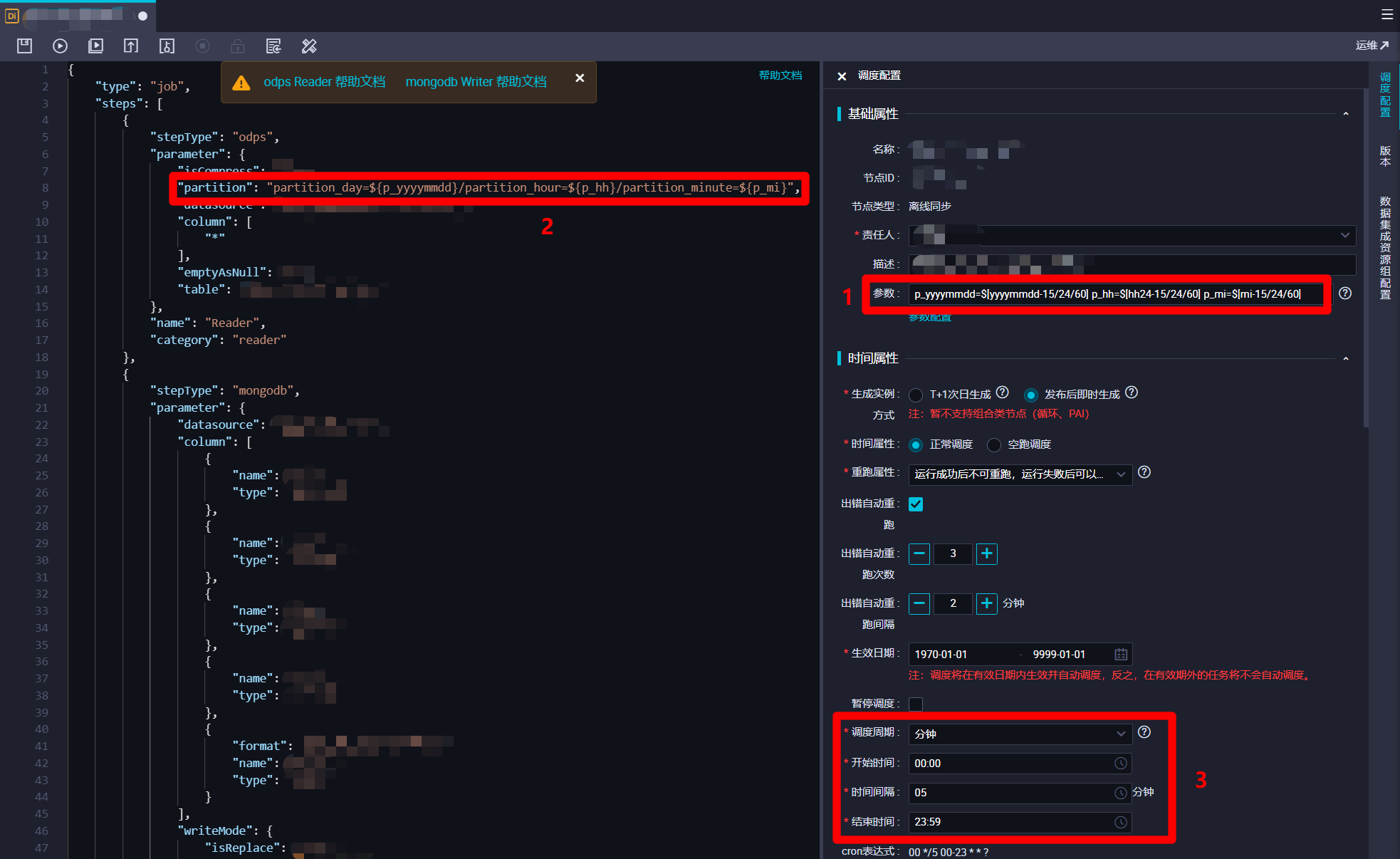
-








八、下載IntelliJ IDEA的MaxCompute Studio插件並配置
-
官方文檔:安裝MaxCompute Studio
-
步驟圖示:
-
打開IntelliJ IDEA的主介面,展開上方菜單欄的”File”項,點擊展開的子菜單中的”Settings…”,會出現Settings彈出框。
-
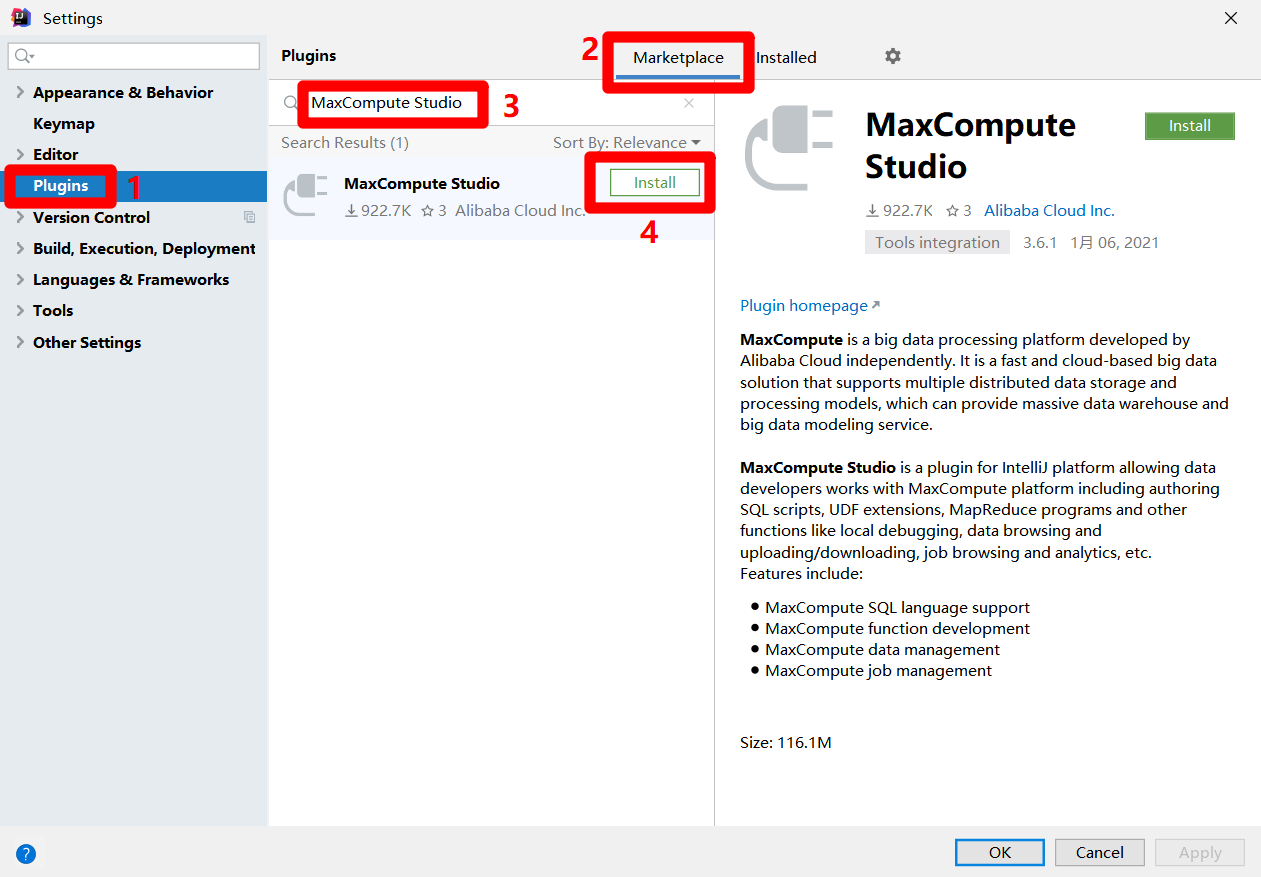
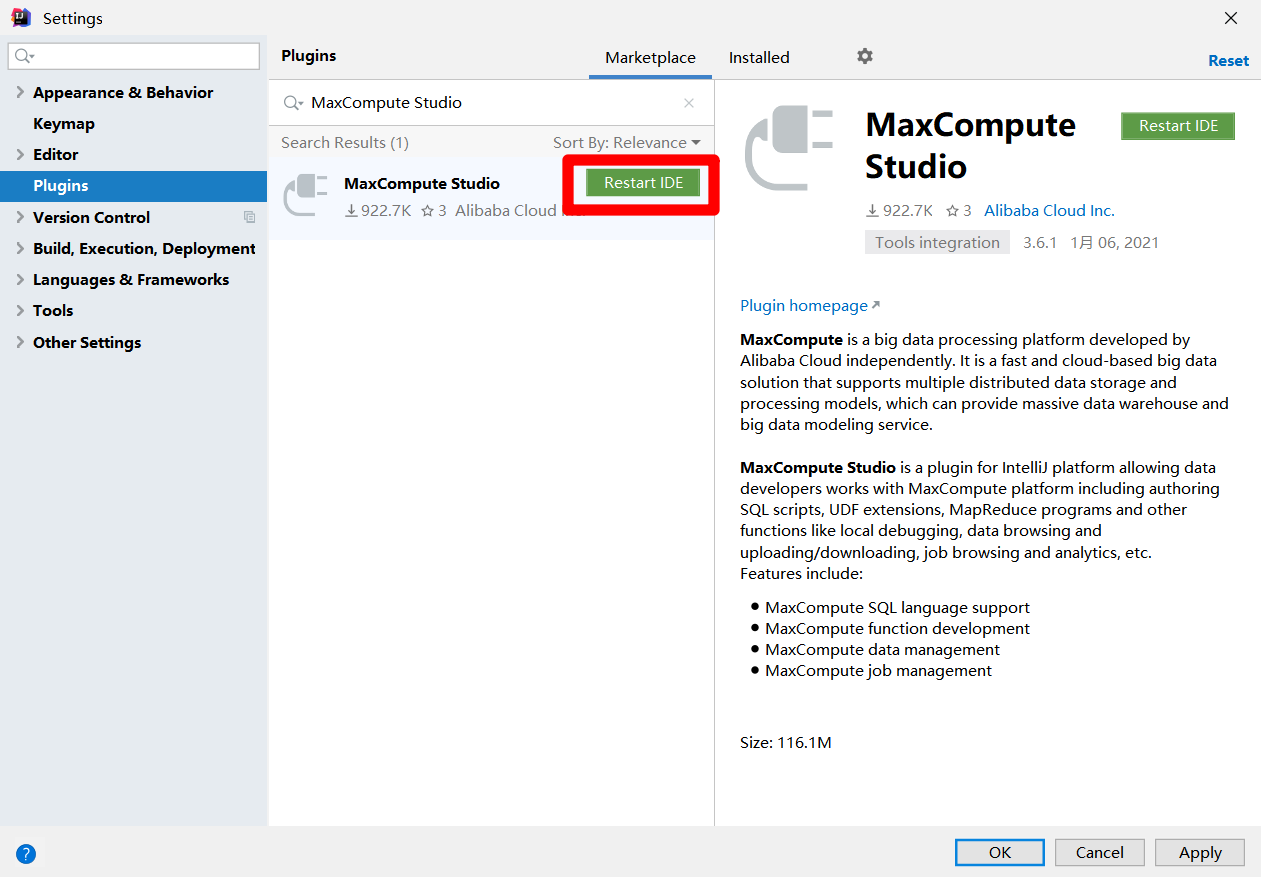
在Settings彈出框中,點擊左側菜單欄中的”Plugins”,使彈出框切換到插件頁面。在插件頁面中,點擊上方的”Marketplace”標籤,然後再搜索框中輸入”MaxCompute Studio”,搜索框下方會出現搜索結果。點擊MaxCompute Studio阿里雲官方插件的”Install”按鈕,開始插件的安裝。
-
插件安裝完成後,會出現”Restart IDE”按鈕,點擊該按鈕重啟IDEA,即可使用MaxCompute Studio插件。下一步準備在IDEA中創建MaxCompute Studio項目,並連接到DataWorks中的MaxCompute項目。
-
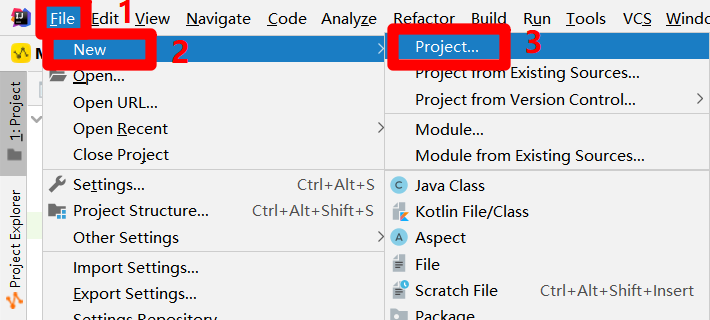
重啟IDEA後,展開上方菜單欄的”File”項,在”File”項的子菜單中再次展開”New”項,點擊”New”項的子菜單中的”Project…”項,會出現”New Project”彈出框。
-
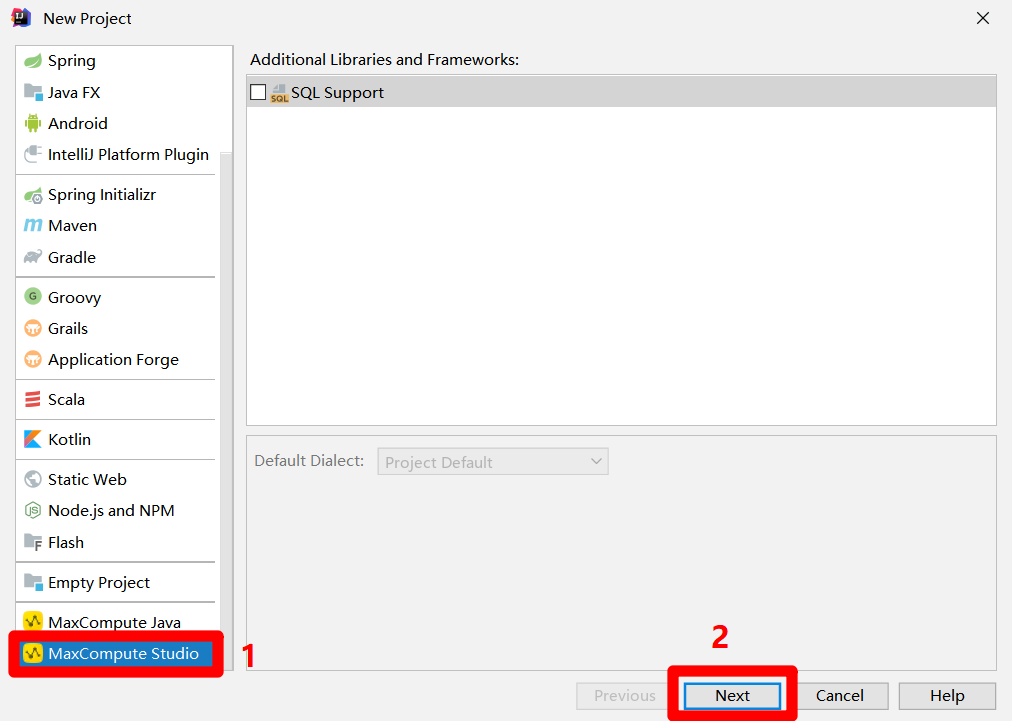
在”New Project”彈出框的左側菜單欄中點擊”MaxCompute Studio”,然後點擊”Next”按鈕,下一步設置項目名稱和路徑。
-
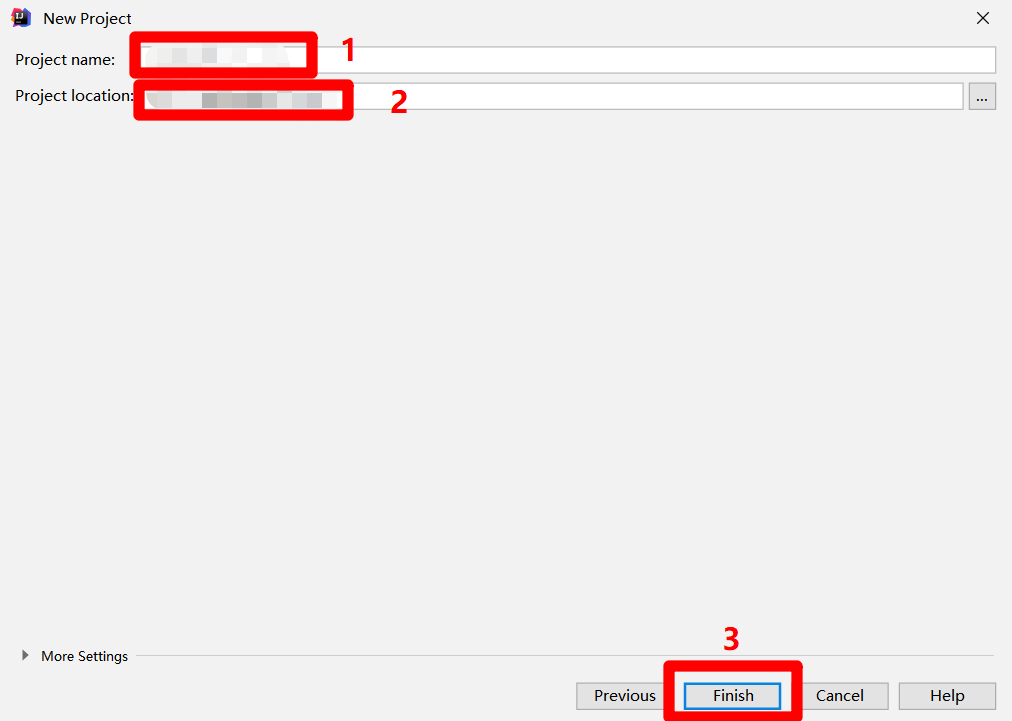
自主填寫項目名稱到”Project name”中,自主選擇項目保存路徑到”Project location”中,然後點擊”Finish”按鈕,完成創建MaxCompute Studio項目,下一步將此項目連接到DataWorks中的MaxCompute項目。
-
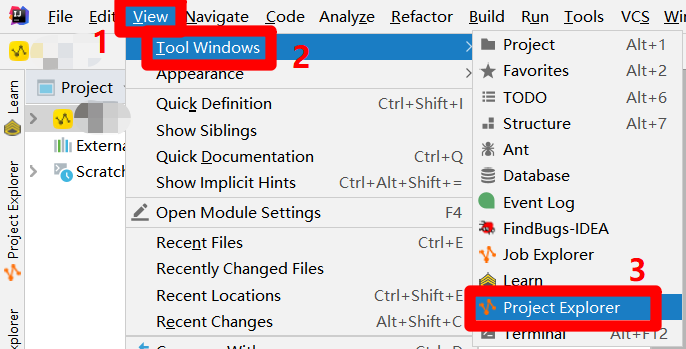
在IntelliJ IDEA的主介面,展開上方菜單欄的”View”項,在”View”項的子菜單中再次展開”Tool Windows”項,點擊”Tool Windows”項的子菜單中的”Project Explorer”項,會出現”Project Explorer”左側邊欄。
-
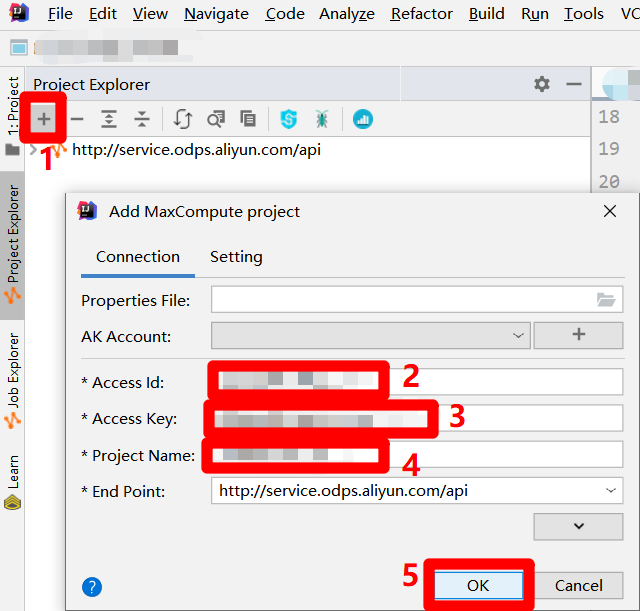
在側邊欄中,點擊左上角的”+”圖標,會出現”Add MaxCompute project”彈出框。在彈出框中,將正在使用的RAM帳號的AccessKey ID填入”Access Id”中,將正在使用的RAM帳號的AccessKey Secret填入”Access Key”中,將DataWorks工作空間名稱填入”Project Name”中,然後點擊”OK”,完成MaxCompute項目的連接。成功連接後,便可以在IDEA介面左側的”Project Explorer”邊欄中查看連接到的MaxCompute項目的詳情。
-
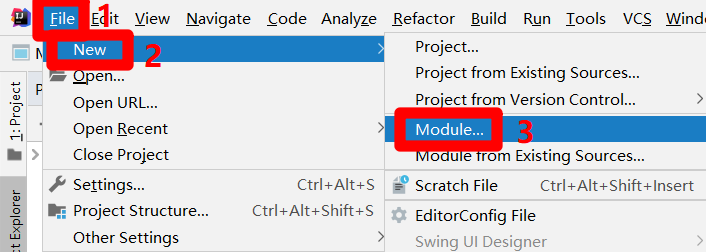
在IntelliJ IDEA的主介面,展開上方菜單欄的”File”項,在”File”項的子菜單中再次展開”New”項,點擊”New”項的子菜單中的”Module…”項,會出現”New Module”彈出框。
-
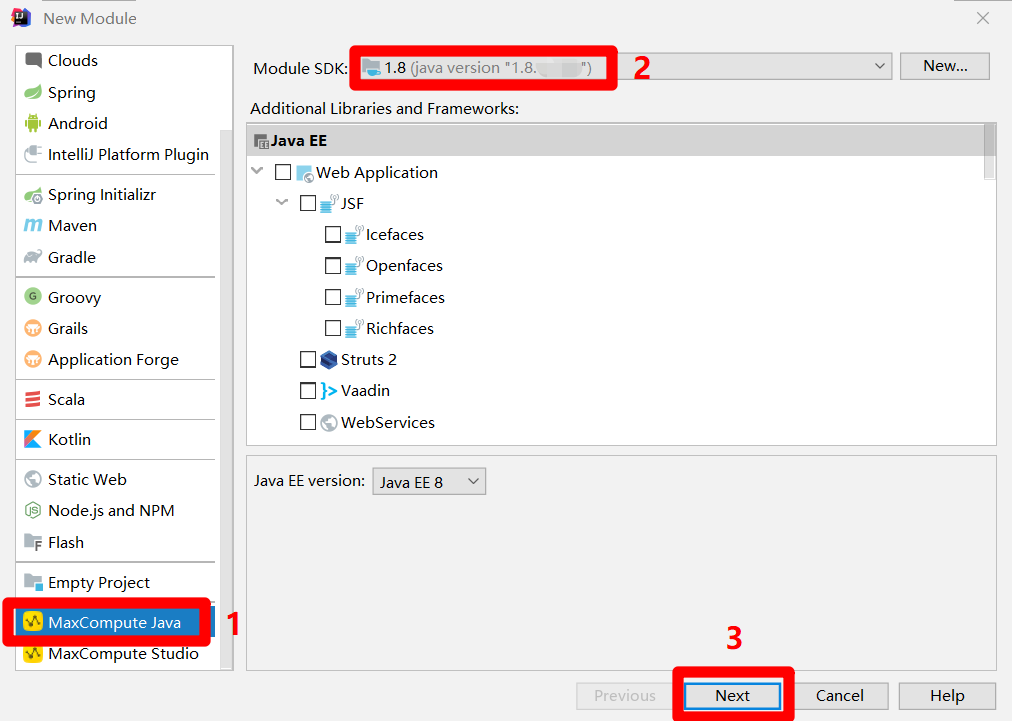
在”New Module”彈出框的左側菜單中,點擊”MaxCompute Java”,在彈出框主頁面中自主設置”Module SDK”為1.8版本的JDK,然後點擊”Next”,下一步設置Module名稱。
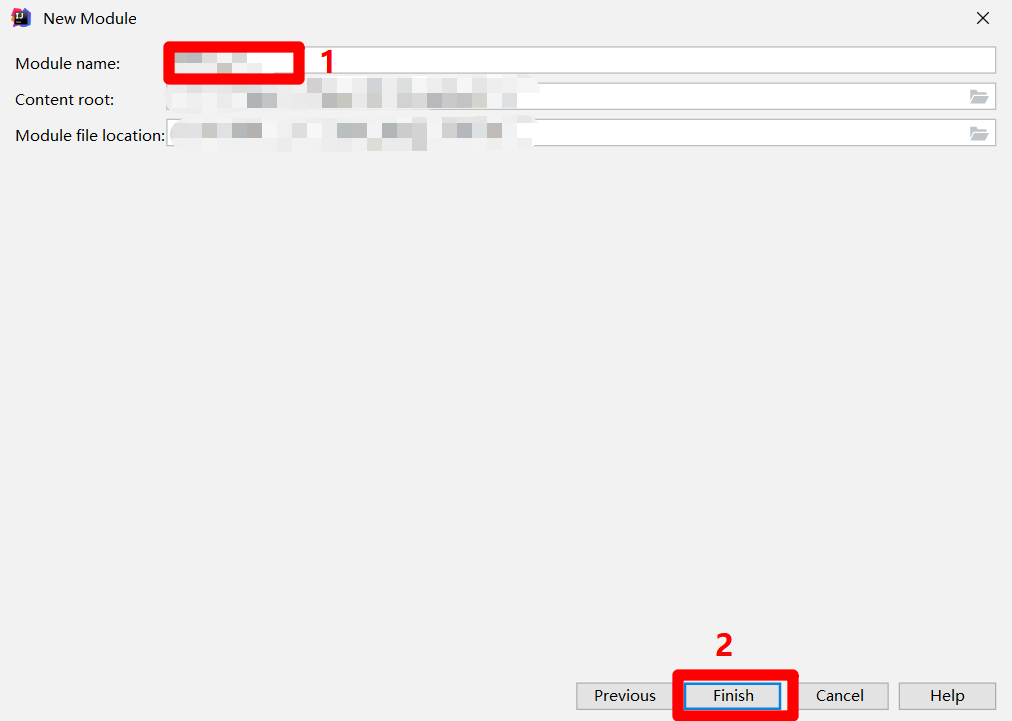
-
在”Module name”中自主填寫模組名稱,然後點擊”Finish”,完成MaxCompute Java模組的創建,在IDEA的”Project”側邊欄中會出現對應的目錄結構。至此完成MaxCompute Studio插件的下載與配置。
-











九、使用MaxCompute Studio開發MapReduce功能的Java程式
-
官方文檔:開發MapReduce功能的Java程式
-
步驟圖示:
-
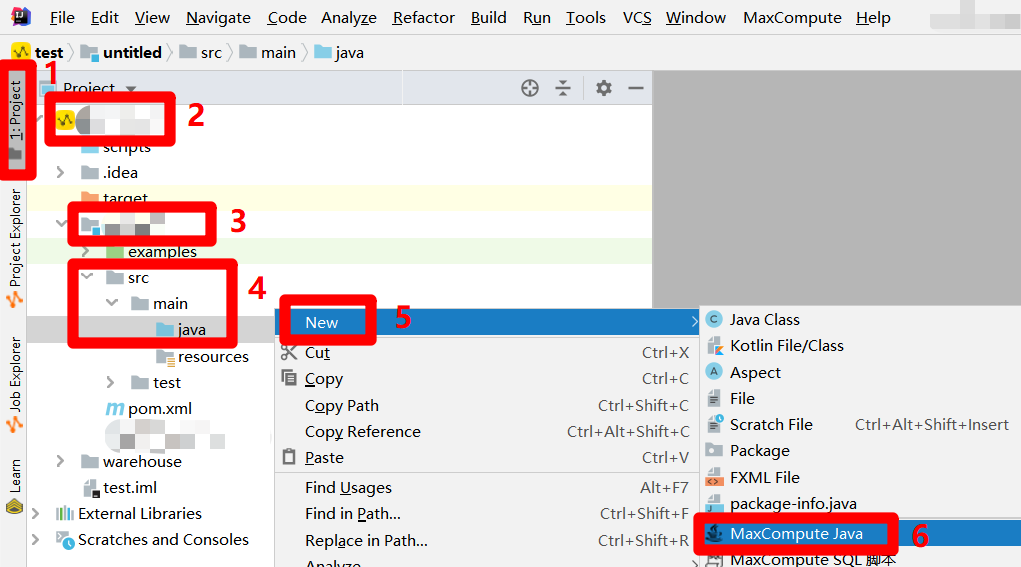
在IntelliJ IDEA主介面左側菜單欄中點擊”Project”,展開”Project”側邊欄。在側邊欄中展開MaxCompute Studio項目的目錄結構,找到MaxCompute Java模組的目錄項,依次展開其下的”src”、”main”目錄項,選中”main”目錄結構下的”java”目錄項,滑鼠右擊調出右鍵菜單。在右鍵菜單中展開”New”項,點擊”New”項的子菜單中的”MaxCompute Java”項,會出現”Create new MaxCompute java class”彈出框。
-
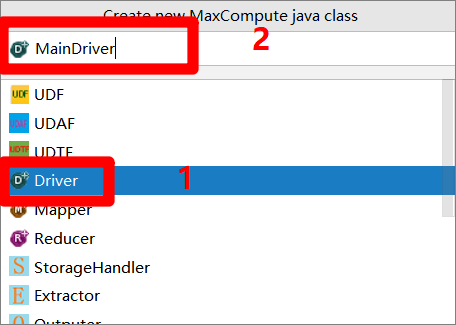
在”Create new MaxCompute java class”彈出框下方的菜單中點選”Driver”項,然後在彈出框的”Name”文本框中自主輸入Driver名稱(例如:MainDriver),按”Enter”鍵完成Driver文件的創建。
-
Driver創建完成後,在”Project”側邊欄中找到Driver文件,雙擊打開其編輯頁面。在編輯頁面中,可以看到自動生成了一些Java程式碼模板,而該Driver類中只有一個main方法,表明此Driver類是整個MapReduce功能的Java程式的入口。我們用與創建Driver類同樣的方式,創建Mapper類與Reducer類,然後根據MapReduce示常式序的官方文檔,自主完成Driver類、Mapper類、Reducer類的開發,實現所需的功能(例如本次實踐中進行了日誌解析功能的實現),這裡不深入展開詳細的過程。開發結束前,請自主進行本地測試,使程式通過本地編譯和測試,確保功能可用。

-



十、將MapReduce功能程式打包上傳為資源
-
官方文檔:打包、上傳Java程式
-
步驟圖示:
-
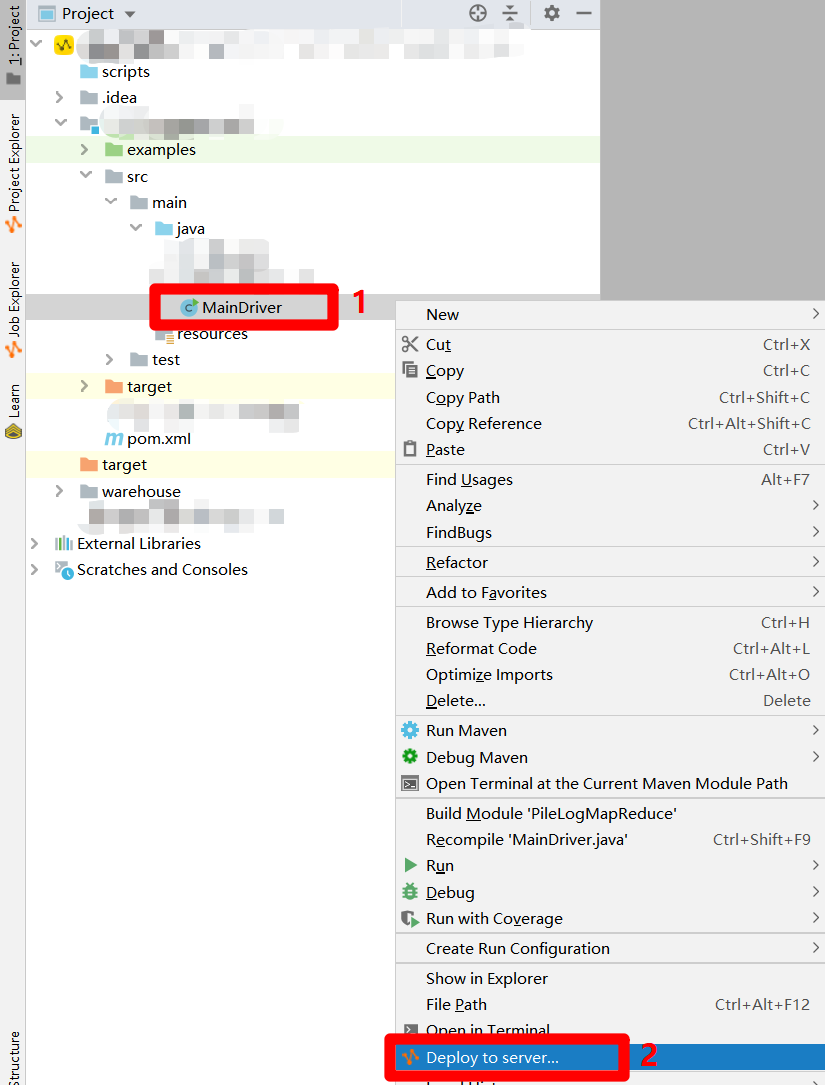
完成MapReduce功能的Java程式開發後,要對程式進行打包獲得JAR包。在IntelliJ IDEA主介面的”Project”側邊欄中選中Driver文件,滑鼠右擊調出右鍵菜單。在右鍵菜單中點擊”Deploy to server…”,會出現”Package a jar and submit resource”彈出框。
-
在”Package a jar and submit resource”彈出框中,由於之前已經配置過MaxCompute項目的連接,此時會自動填寫各項參數,只需點擊”OK”按鈕,即可完成打包,下一步要將JAR包上傳為資源。

-
在”Project”側邊欄中展開MaxCompute Java模組下的”target”目錄項,在”target”目錄結構中選中上一步生成的JAR包。然後展開主介面上方菜單欄中的”MaxCompute”項,點擊展開的子菜單中的”添加資源”,會出現”Add Resource”彈出框。
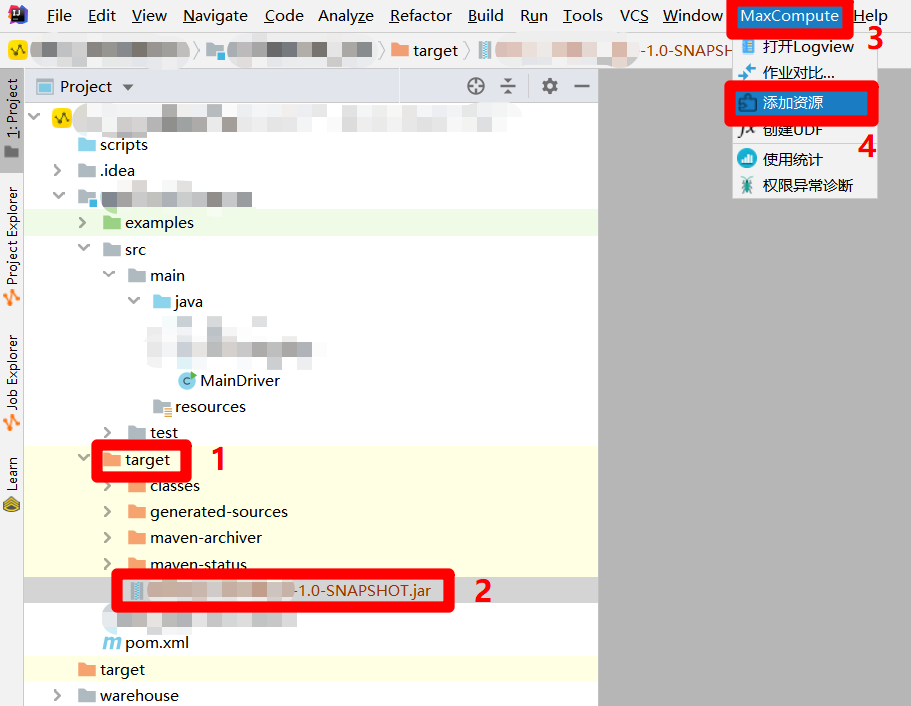
-
在”Add Resource”彈出框中,因為剛才選中了生成的JAR包,此時會自動填寫各項參數,只需點擊”OK”按鈕,即可將JAR包添加為阿里雲MaxCompute項目中的資源,下一步要將此資源添加到業務流程的資源文件夾中。
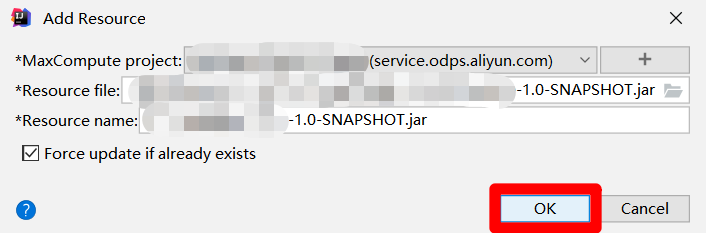
-
打開阿里雲的”DataStudio(數據開發)”頁面,展開頁面左側菜單欄中的”MaxCompute”項,點擊”MaxCompute”菜單下的”MaxCompute資源”,菜單欄右邊的頁面會切換到”MaxCompute資源”編輯頁面。在”MaxCompute資源”編輯頁面中選中剛才上傳的JAR包資源,然後點擊頁面下方的”添加到數據開發”按鈕,會出現”新建資源”彈出框。在”新建資源”彈出框中,參數”目標文件夾”里自主選擇之前創建的業務流程,然後點擊”新建”按鈕,成功將Jar包添加到業務流程的資源中,下一步將資源進行提交。
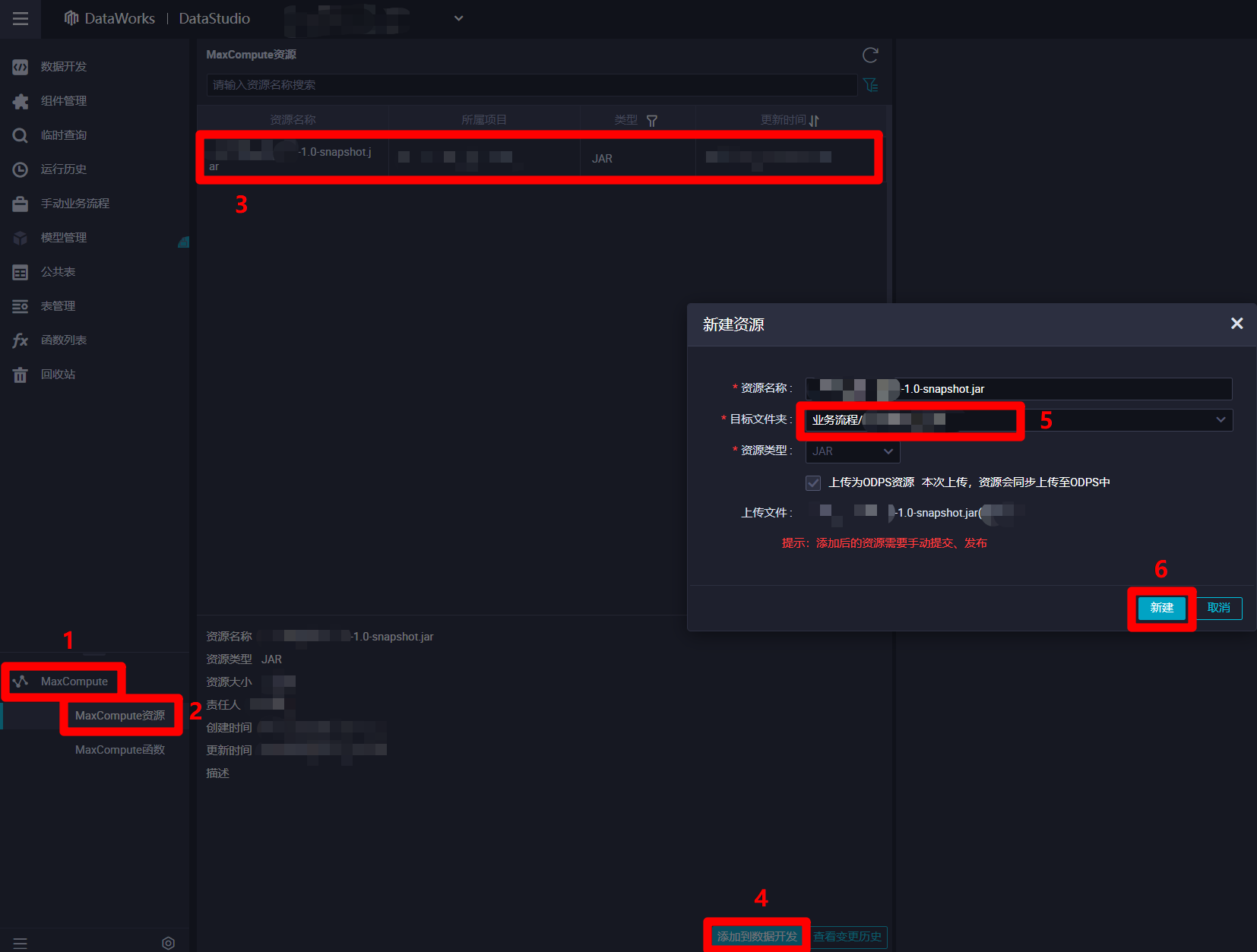
-
在DataWorks的”數據開發”頁面中,展開當前業務流程的列表,在列表中依次展開”MaxCompute”、”資源”項,雙擊剛添加的JAR包資源,進入該資源的編輯頁面,然後點擊頁面上方菜單欄中的提交按鈕,會出現”提交新版本”彈出框。
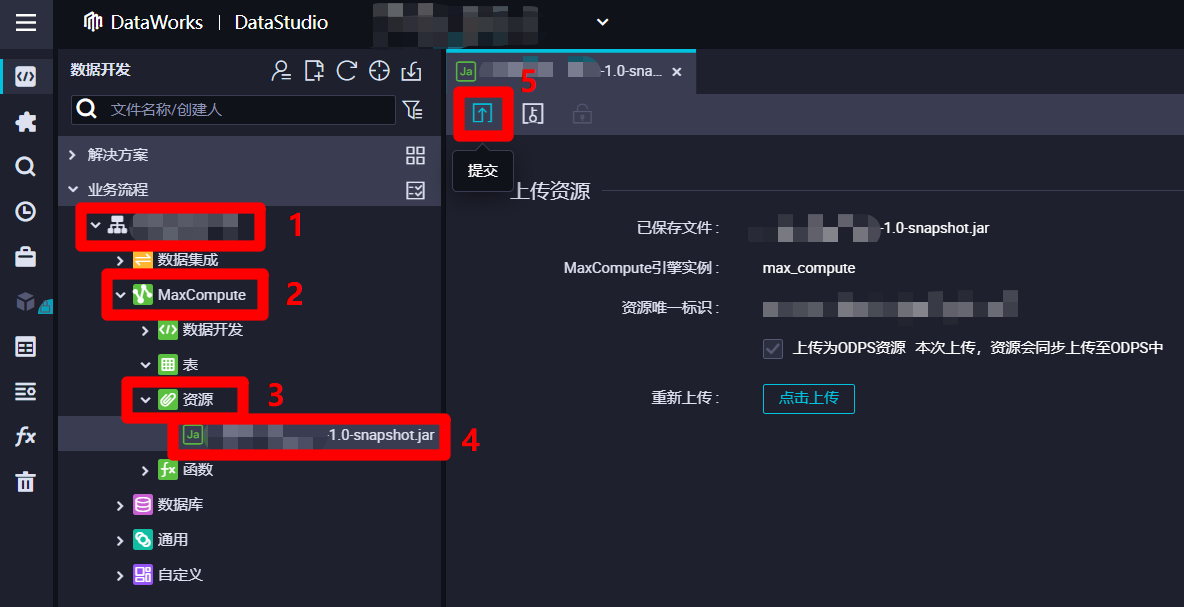
-
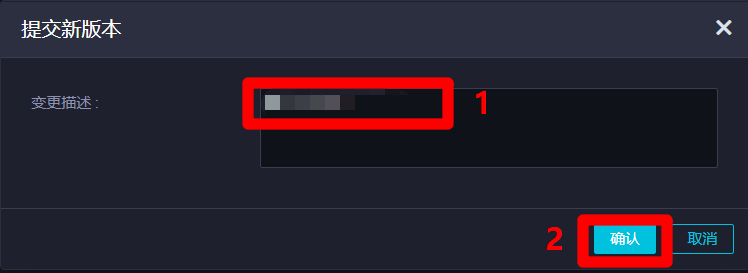
在”提交新版本”彈出框中,自主填寫”變更描述”,然後點擊”確認”,完成資源的提交。資源提交成功後,在業務流程正式運行的時候,節點才能找到此資源。
-







十一、創建並配置ODPS MR節點
-
官方文檔:創建ODPS MR節點
-
步驟圖示:
-
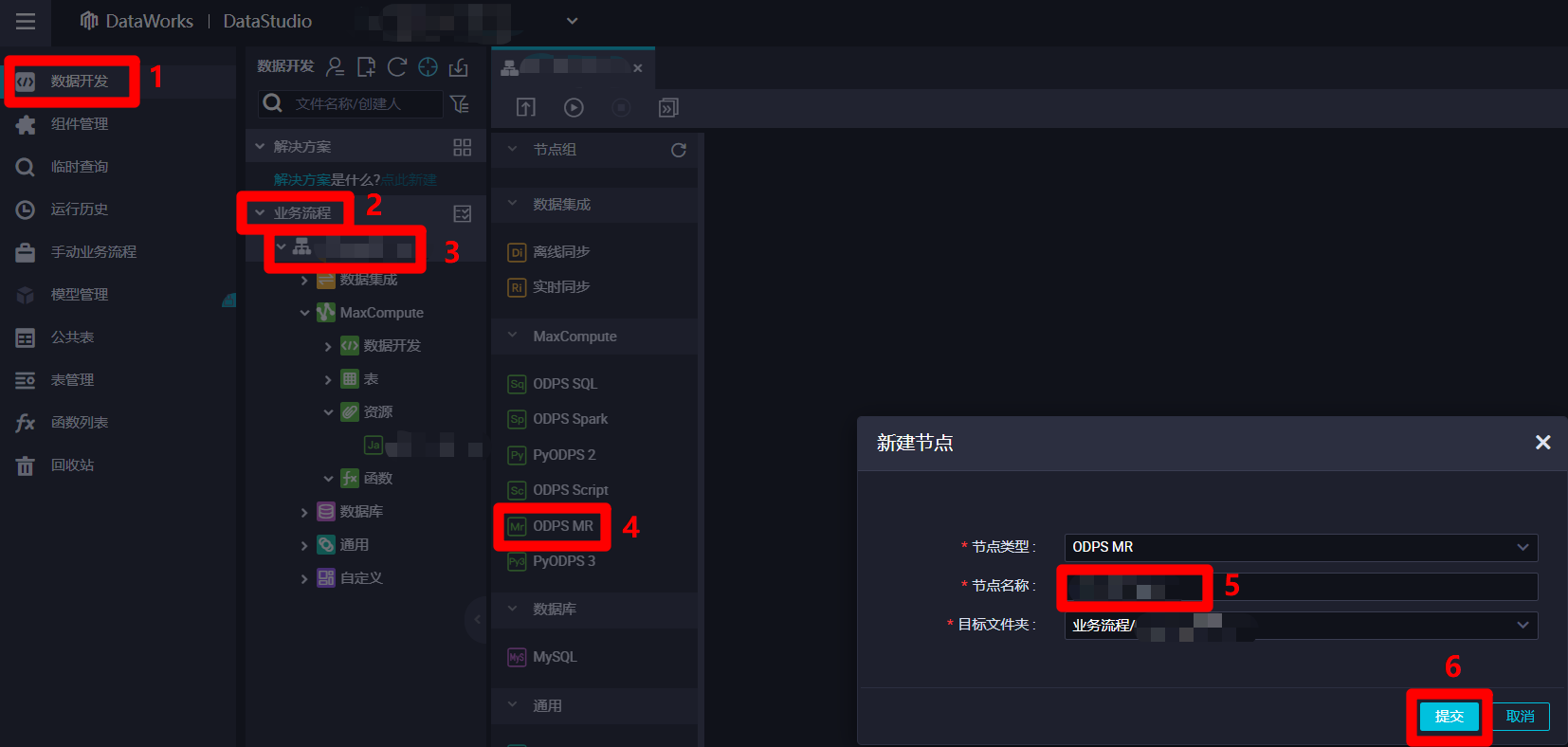
在阿里雲的”DataStudio(數據開發)”頁面中,點擊左側菜單欄中的”數據開發”項,菜單欄右邊的頁面會切換到”數據開發”頁面。在”數據開發”頁面中,展開”業務流程”列表,在”業務流程”列表中,雙擊目標業務流程,打開目標業務流程的編輯頁面。在業務流程編輯頁面的左側菜單欄中雙擊”ODPS MR”項,會出現”新建節點”彈出框。在”新建節點”彈出框中,自主填寫”節點名稱”,然後點擊”提交”按鈕,完成ODPS MR節點的創建。
-
完成ODPS MR節點的創建後,在業務流程的編輯頁面中,雙擊剛創建的ODPS MR節點,進入ODPS MR節點的編輯頁面。
-
在ODPS MR節點的編輯頁面中,編輯區域的末尾添加一行程式碼:
--@resource_reference{""}。並將游標放到兩個雙引號之間,下一步準備引入剛添加的資源。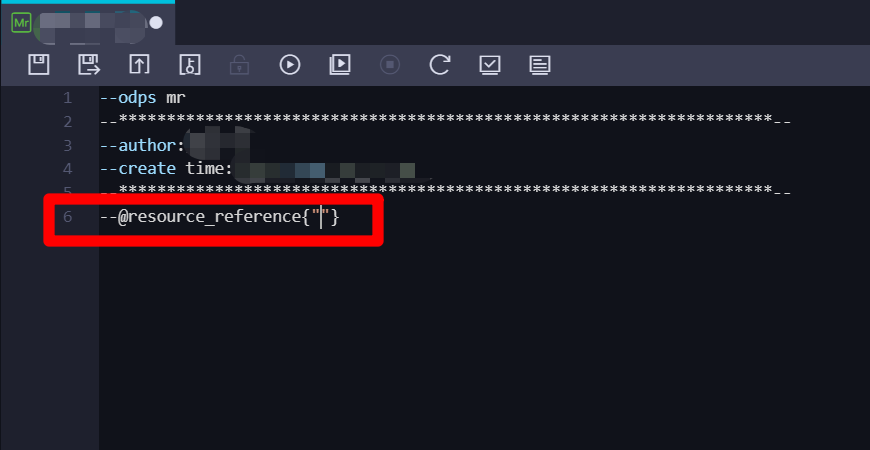
-
在ODPS MR節點編輯頁面左邊的”數據開發”頁面中,展開當前業務流程的列表,在列表中依次展開”MaxCompute”、”資源”項,選中剛添加的JAR包資源,滑鼠右擊調出右鍵菜單。在右鍵菜單中點擊”引用資源”,剛才ODPS MR節點編輯區域的游標所在位置就會自動添加引用資源的名稱,並在編輯區域的開頭自動生成一行程式碼,下一步準備添加一行調用JAR包資源運行的程式碼。
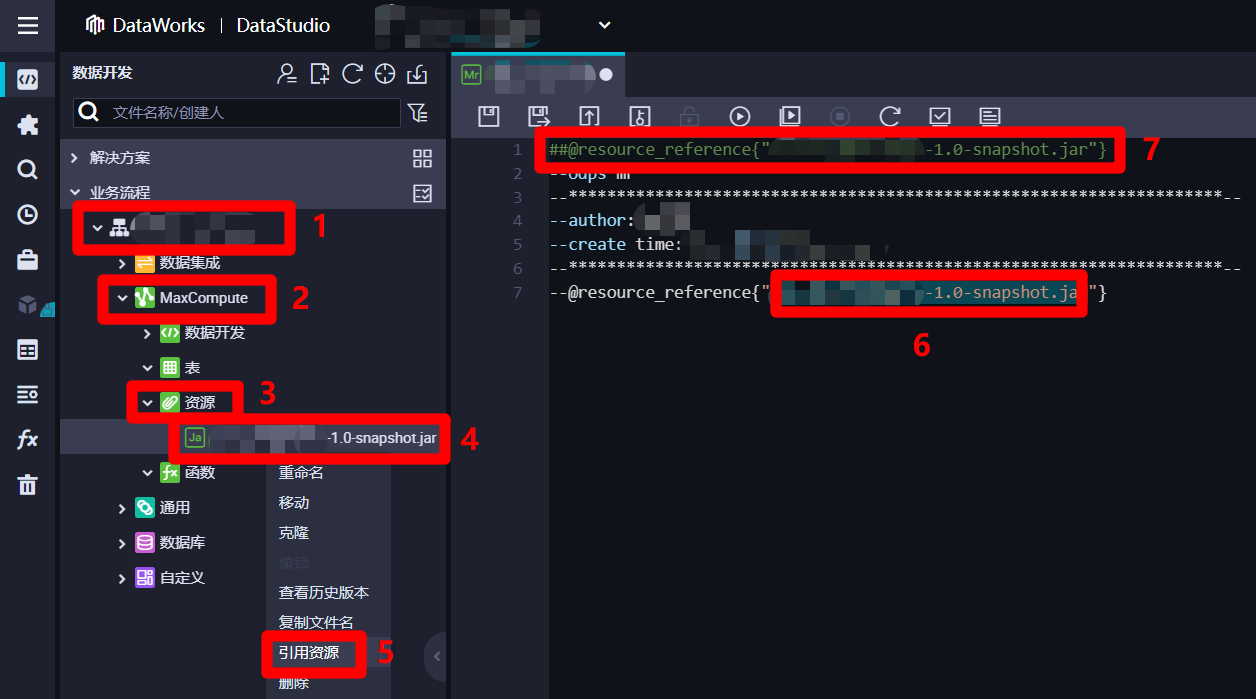
-
在編輯區域末尾,再添加一行調用JAR包資源的Driver類的main方法的程式碼,格式類似於
jar -resources *-*.*-SNAPSHOT.jar -classpath ./*-*.*-SNAPSHOT.jar *.*Driver <in_table>[|<partition_key>=<val>[/<partition_key>=<val>...]] <out_table>[|<partition_key>=<val>[/<partition_key>=<val>...]]。此行程式碼的前半部分(”in_table”之前的部分),用於指定調用的JAR包資源的名稱和位置,以及其中的Driver類的全類名;程式碼的後半部分(”in_table”以後的部分),是Driver類中main方法的入參(對應形參String[] args),因此後半部分MaxCompute輸入表與輸出表的程式碼格式,是根據之前自主編寫Driver類時main方法中的解析方式來填寫的,上面的示例程式碼僅供參考,請自主完善。本次實踐中,MaxCompute輸入表或輸出表需要指定時間分區,也跟之前一樣使用調度參數動態指定,因此在調度配置邊欄的”基礎屬性”模組下的”參數”文本框中輸入:p_yyyymmdd=$[yyyymmdd-10/24/60] p_hh=$[hh24-10/24/60] p_mi=$[mi-10/24/60],在MaxCompute輸入表與輸出表指定分區的程式碼部分填寫內容:partition_day=${p_yyyymmdd}/partition_hour=${p_hh}/partition_minute=${p_mi}。完成ODPS MR節點的程式碼編輯後,下一步準備進行其調度配置。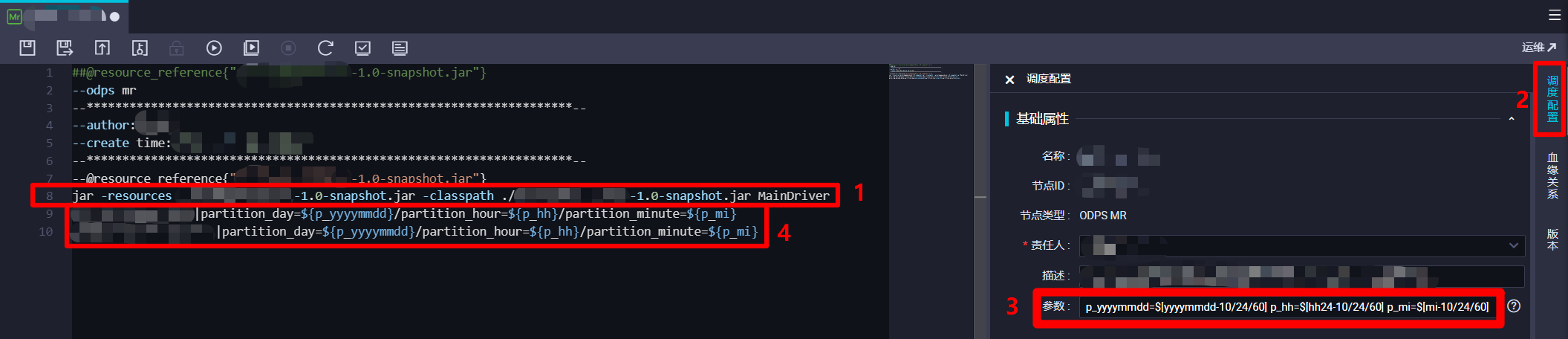
-
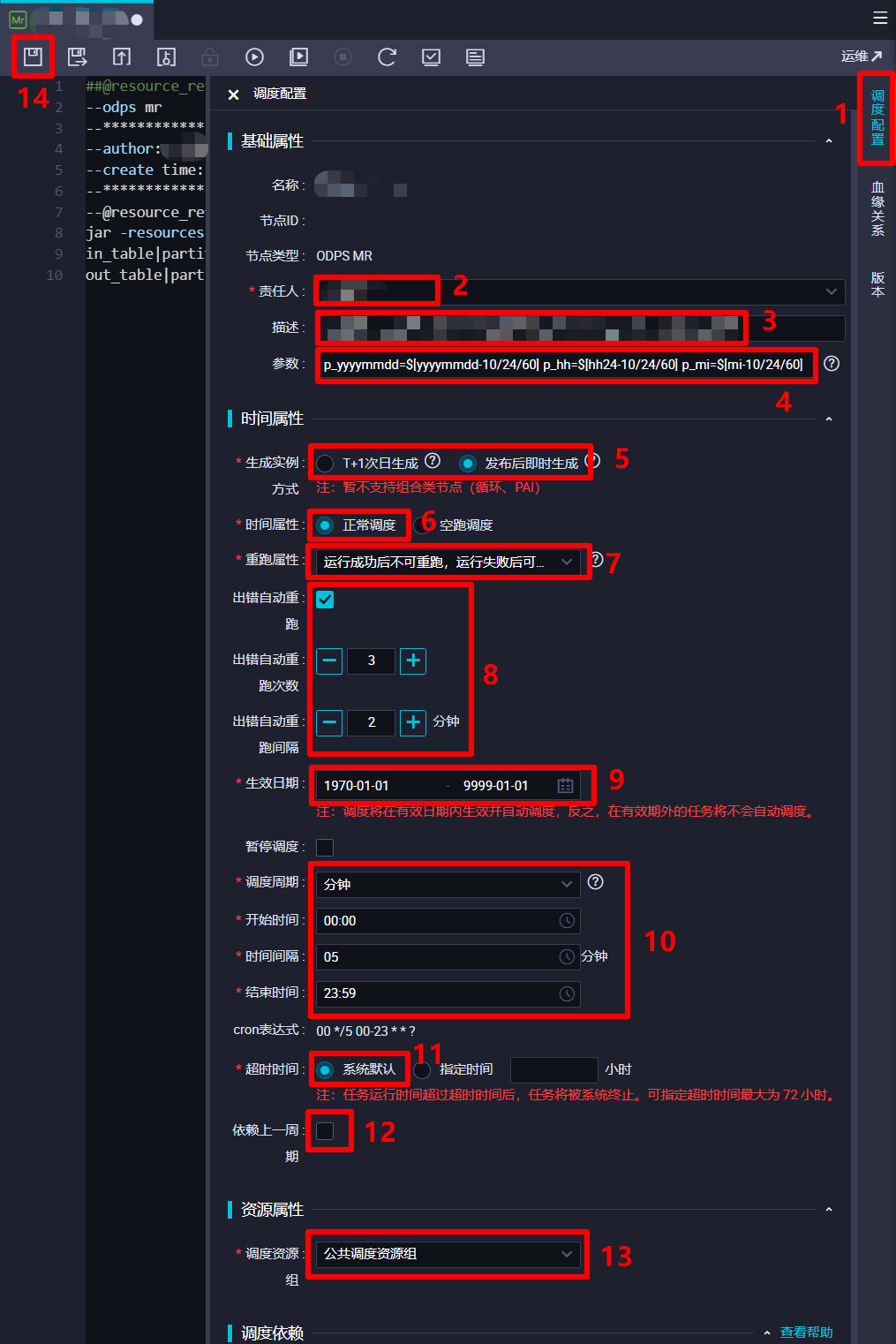
在調度配置邊欄中,對該ODPS MR節點的調度配置進行完善。在”基礎屬性”模組中,”責任人”選擇當前登錄的RAM帳號;自主填寫”描述”;”參數”的填寫內容上一步中已完成,不再贅述。在”時間屬性”模組中,自主選擇”生成實例方式”,為方便後面快速測試,此次實踐選擇”發布後即時生成”;”時間屬性”選擇”正常調度”;自主選擇”重跑屬性”,通常選擇”運行成功後不可重跑,運行失敗後可以重跑”;勾選”出錯自動重跑”,自主選擇”出錯自動重跑次數”、”出錯自動重跑間隔”,此次實踐使用其默認配置的次數與間隔;自主選擇”生效日期”,此次實踐使用其默認配置,讓同步任務一直保持生效狀態;由於此次實踐希望整個業務流程的運行周期間隔盡量短一些,所以設置”調度周期”為”分鐘”,”開始時間”設置為”00:00″(被限制只能設置整時),”時間間隔”設置為最短的”05″,”結束時間”設置為”23:59″(被限制只能設置小時),以確保該節點跨天也會每五分鐘運行一次;自主選擇”超時時間”,此次實踐選擇”系統默認”;不勾選”依賴上一周期”,這樣某一周期運行出錯不會影響之後的運行周期。”資源屬性”模組的”調度資源組”選擇默認的”公共調度資源組”即可。”調度依賴”模組暫時不進行配置。”節點上下文”模組在此次實踐中不需要配置。完成以上調度配置後,點擊頁面上方菜單欄的保存按鈕,完成對ODPS MR節點的創建與配置。
-






十二、關聯各個節點
-
官方文檔:配置節點的調度和依賴屬性
-
步驟圖示:
-
目前業務流程里總共創建並配置了三個節點:一個從MongoDB表到MaxCompute表的離線同步節點,用於獲取日誌數據,每次同步執行時間往前五分鐘到執行時間的數據;一個從MaxCompute表到MaxCompute表的ODPS MR節點節點,用於解析日誌數據,每次同步執行時間往前十分鐘到執行時間往前五分鐘的數據;一個從MaxCompute表到MongoDB表的離線同步節點,用於輸出日誌數據,每次同步執行時間往前十五分鐘到執行時間往前十分鐘的數據。本次實踐中,這三個節點在業務流程中並行運行,互相之間不存在上下游關係,因此將這三個節點的父節點均設置為工作空間根節點即可。下面進行步驟演示,對三個節點執行同樣的操作即可。首先選中一個節點雙擊,進入節點編輯頁面。
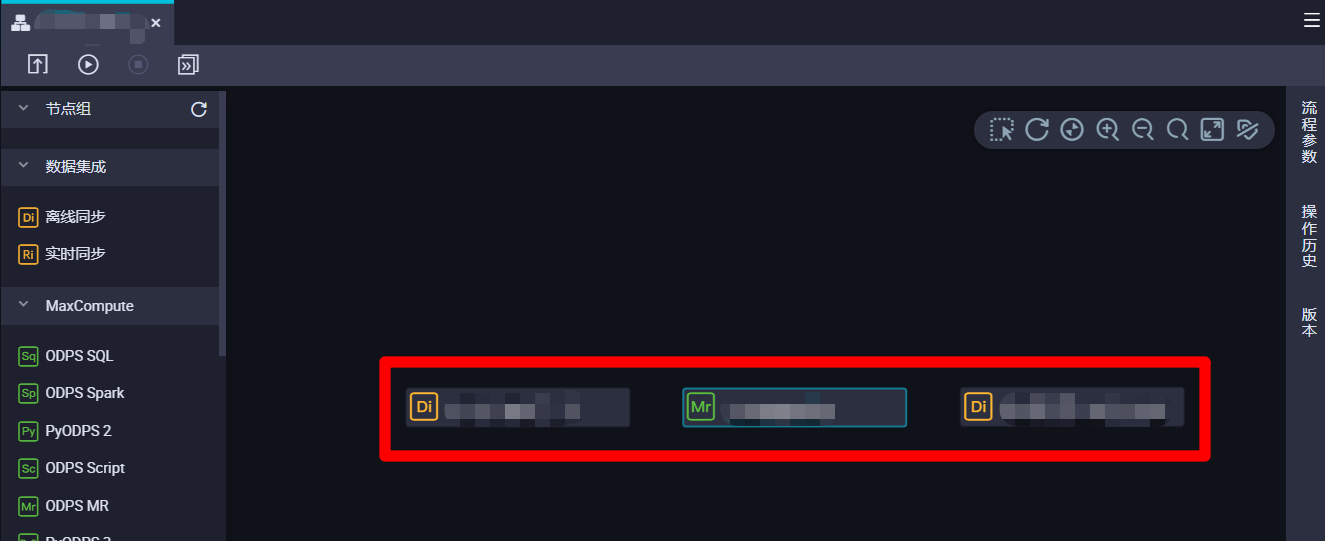
-
在節點編輯頁面右端展開”調度配置”邊欄,然後在調度配置邊欄的”調度依賴”模組下的參數項”依賴的上游節點”後面點擊”使用工作空間根節點”按鈕,下面的父節點列表中會自動添加一條工作空間根節點數據。然後點擊頁面上方菜單欄的提交按鈕,會出現”請注意”彈出框。
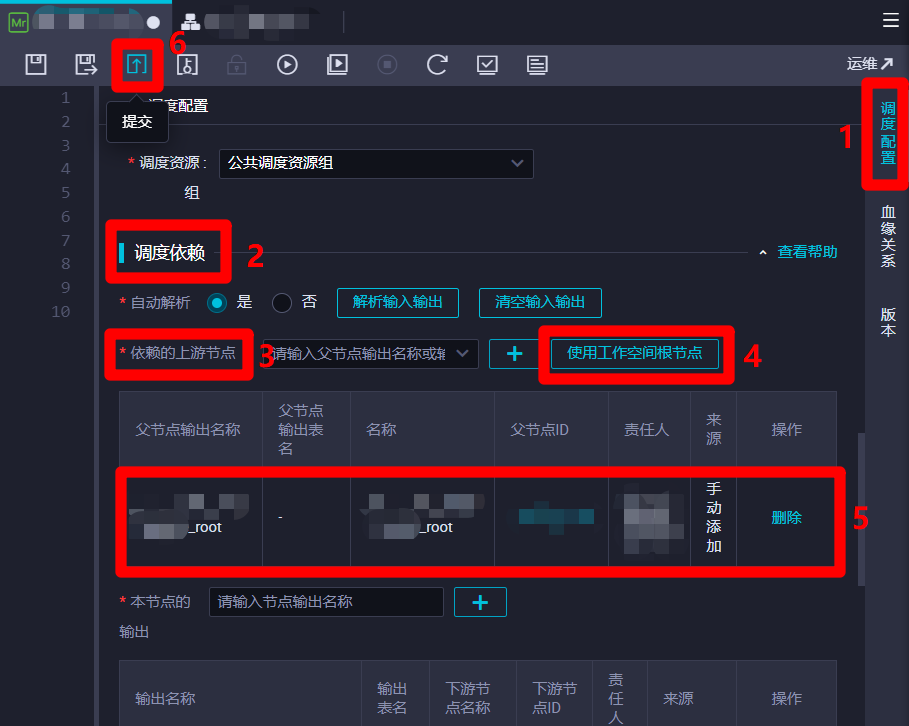
-
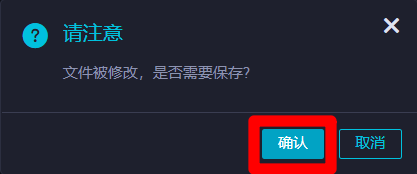
在”請注意”彈出框中,點擊”確認”保存修改。保存成功後,會出現”提交新版本”彈出框。
-
在”提交新版本”彈出框中,自主填寫”變更描述”,然後點擊”確認”,完成節點的提交。節點提交後,該節點就會正式運行,開始進行周期調度。至此完成將三個節點綁定到工作空間根節點下的操作,並將三個節點成功進行了提交。
-




十三、提交業務流程並查看運行結果
-
官方文檔:節點運行及排錯
-
步驟圖示:
-
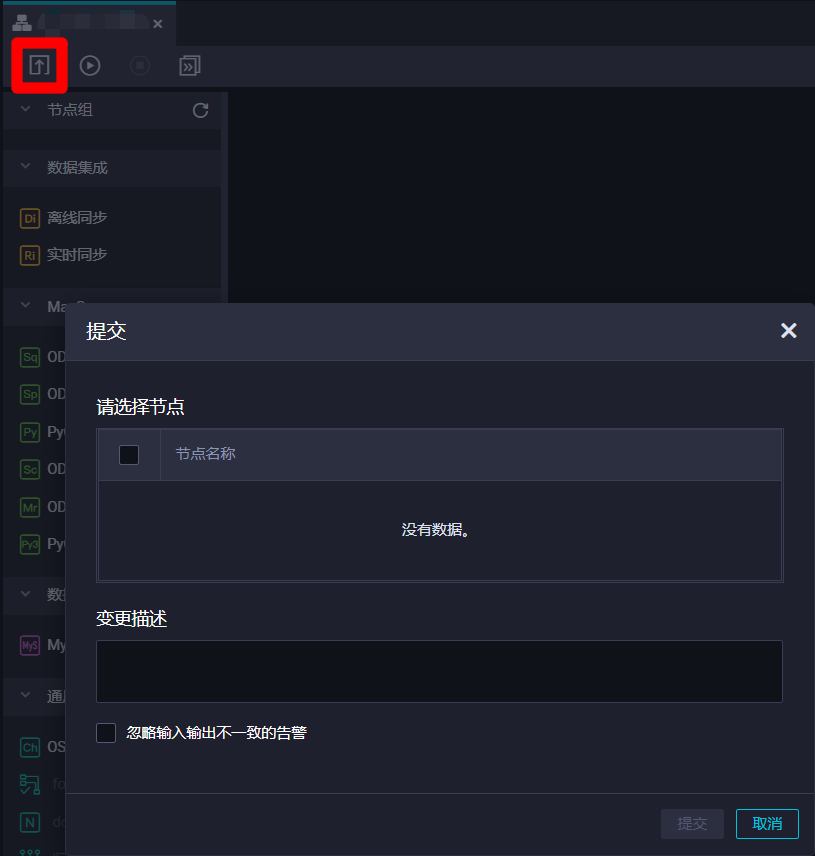
上一步中,業務流程中的三個節點已經成功進行了提交並開始運行,而在業務流程編輯頁面中,點擊上方菜單欄的提交按鈕,也可以對節點進行統一提交。
-
業務流程提交並運行後,我們可以點擊頁面上方菜單欄中的前往運維按鈕,或者頁面右上角的”運維中心”鏈接,打開DataWorks的”運維中心(工作流)”頁面,準備查看各個節點周期任務的運行結果。

-
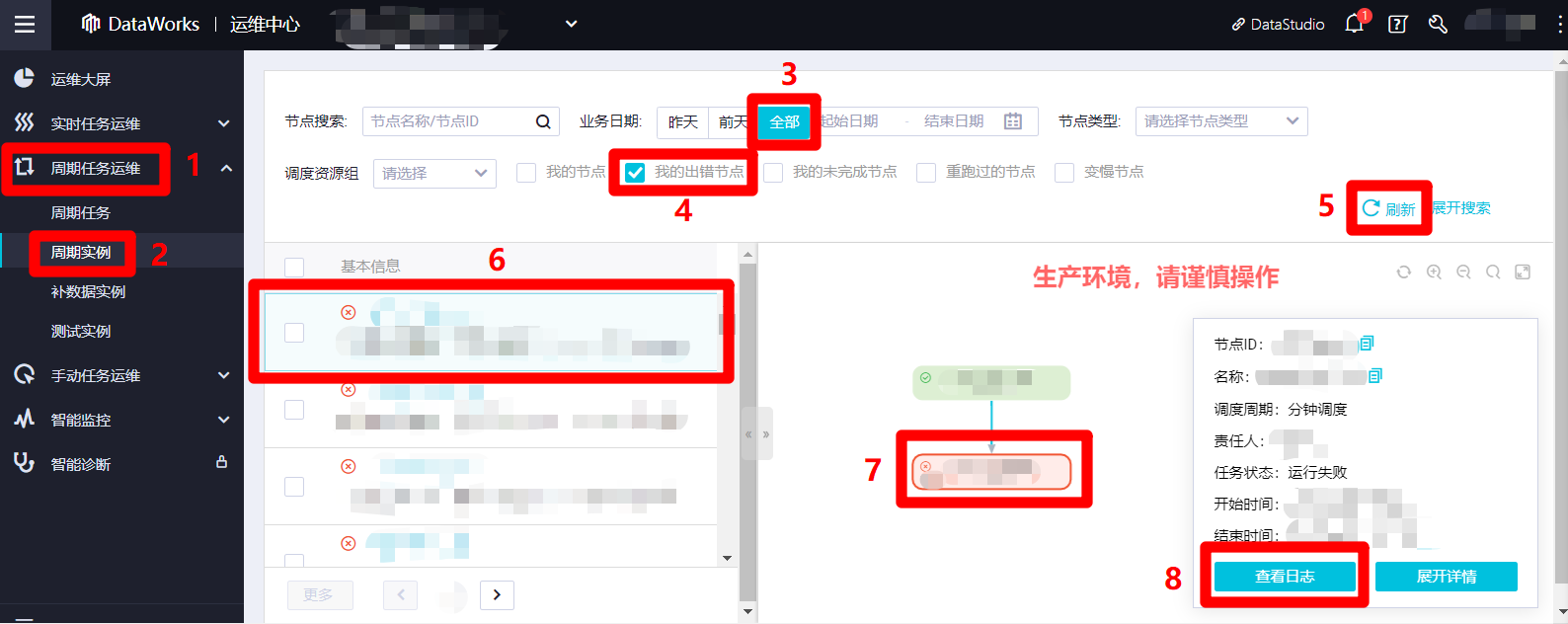
在”運維中心(工作流)”頁面左側菜單欄中展開”周期任務運維”項,在子菜單中點擊”周期實例”,切換到周期實例列表頁面。在周期實例列表頁面上方搜索欄中,搜索條件的”業務日期”(業務日期為實際運行日期的前一天)選擇”全部”,勾選”我的出錯節點”,自主調整其他搜索選項,點擊搜索欄右下角的”刷新”可以更新搜索結果。在下方周期實例列表中點選一個出錯實例,列表右側會出現該出錯實例的詳情頁面。在詳情頁面中,點選目標出錯節點,頁面右下角會出現該節點資訊的彈出框。在彈出框中點擊查看日誌,可以打開該出錯節點運行時的日誌詳情頁面。根據異常日誌內容,我們就可以找到出錯原因,進行對應的調整,確保整個業務流程的正常運行。
-



結語
- 本次實踐中,雖然購買使用了獨享數據集成資源組,實際上使用公共數據集成資源組也可實現本實踐的功能需求。若沒有購買獨享數據集成資源組,能將整個業務流程的成本降到最低,只需支付MaxCompute服務的流量費用。
- 本次實踐僅使用了阿里雲的離線同步、離線計算功能,如果要使用實時同步、實時計算功能,通常需要購買開通相應的服務。
- 使用RAM帳號操作過程中,經常會出現許可權不足的情況,這時候用另一種瀏覽器登錄主賬戶,即可較為方便地在一台電腦上進行授權或購買阿里雲服務,避免在一個瀏覽器上來回登錄。
- 在實踐過程中經常會出現陌生的術語,或者找不到某一個需求對應的模組在哪裡,或者操作過程中出現了錯誤進行不下去,可以多在阿里雲關鍵字搜索頁面中思考關鍵字查詢對應的文檔,實在解決不了,就提交工單諮詢阿里雲的技術人員即可。


