Real-time Personalization using Embeddings for Search Ranking at Airbnb(休息)
- 2021 年 2 月 26 日
- AI
最近要做feed 流推薦,找了一些很不錯的課程。
我不太喜歡看影片,因為太慢,極客時間還是非常不錯的,課程有錄音版和文字版(非廣告。。。),看起來很快,不過目前專門講推薦的就兩門課,但都是精品:

王喆大佬的課講解了非常多的精品論文和系統架構,

無刀大佬的課講了Netflix的推薦系統架構,不過找來找去沒有看到airbnb的embedding推薦的內容,所以這裡補上。
考慮到這篇論文網上已經有非常多經典的解讀,這裡的工作就是把整個論文面向的業務場景,解決思路,技巧等做一個總結;
Ning Lee:推薦系統從零單排系列(七)–Airbnb實時個性化推薦之Embedding真的好用嗎?
Airbnb的業務場景:
作為全球最大的短租平台,每天都有上百萬的用戶通過Airbnb找到自己心儀的短租屋。一個典型的用戶操作流程如下:

用戶輸入地點、日期、人數進行搜索,系統會根據你的需求推薦你可能會感興趣的房源,這就是Airbnb的第一大業務:搜索推薦。如下圖所示:

瀏覽滑動選擇一個你感興趣的,點擊查看,新頁面中除了該短租屋具體資訊,在頁面底部會有一個更多房源,這就是Airbnb的第二大推薦業務場景:相似房源推薦。

與其他公司業務不同的地方在於,host可以拒絕user的預定。論文就是從這兩大類業務場景出發,通過Embedding技術來提高推薦品質。具體包括:
問題1、 使用Embedding來建模用戶long-term偏好,提高搜索推薦的品質 ;
問題2、 使用Embedding來學習listing的低維表達,提高相似房源推薦的品質;
王喆:從KDD 2018 Best Paper看Airbnb實時搜索排序中的Embedding技巧
針對於問題1,通過booking session生成user-type和listing-type的embedding,目的是捕捉不同user-type的long term喜好。由於booking signal過於稀疏,Airbnb對同屬性的user和listing進行了聚合,形成了user-type和listing-type這兩個embedding的對象。(就是你去了一個新地方,打開airbnb搜索的時候給你推薦的功能)
針對於問題2,airbnb地工程團隊 通過click session數據生成listing的embedding,(翻譯過來就是通過用戶在選擇短租屋的時候的點擊序列數據來生成listing——也就是短租屋的embedding向量)生成這個embedding的目的是為了進行listing(短租屋)的相似推薦,以及對用戶進行session內的實時個性化推薦。(就是你點擊了某個房源之後,airbnb底下的給你其它相似房源的那個功能)
listing embedding
首先來看相對簡單的listing embedding的部分,
數據預處理:
Airbnb使用了click session數據對listing進行embedding,其中click session指的是一個用戶在一次搜索過程中,點擊的listing的序列,這個序列需要滿足兩個條件,一個是只有停留時間超過30s的listing page才被算作序列中的一個數據點,二是如果用戶超過30分鐘沒有動作,那麼這個序列會斷掉,不再是一個序列。

(比較好奇,這些閾值是怎麼確定下來的)
這麼做的目的無可厚非,一是清洗雜訊點和負回饋訊號,二是避免非相關序列的產生。
模型:
魔改了目標函數的skip-gram版的word2vec

word2vec的skip-gram model的目標函數如下:

使用nce之後得到:

對應到airbnb中的論文公式:
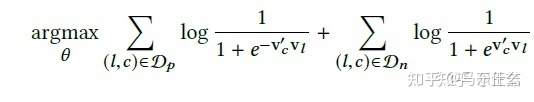
(sigmoid自帶負號,這裡沒有問題的)
這裡做的改進也不複雜,airbnb的工程師認為,用戶booking成功的listing意義重大,這個其實不難理解,比如我今天比較喜歡 裝修性冷淡風+價格便宜+有投影的listing,我肯定是在相似風格的listing裡面找,那麼我最終booking的listing大概率也是這種風格的,但是如果我選完了但是女朋友不同意,她想住現代風格的listing,那麼我們可能會爭論一段時間,大概爭論個半小時,我妥協,重新booking,此時我重新點擊的listing序列可能就完全不同了(不過說實話這個半小時airbnb到底是怎麼統計出來的。。。論文也沒寫)
因此,最終的目標函數成為這樣:

其中Db代表了所有booked session中所有滑動窗口中central listing和booked listing的pair集合。
下面這一項就比較容易理解了,為了更好的發現同一市場(marketplace)內部listing的差異性,Airbnb加入了另一組negative sample,就是在central listing同一地區的listing集合中進行隨機抽樣,獲得一組新的negative samples。同理,我們可以用跟之前negative sample同樣的形式加入到objective中。

其中Dmn就是新的同一地區的negative samples的集合。
至此,lisitng embedding的objective就定義完成了,embedding的訓練過程就是word2vec negative sampling模型的標準訓練過程,這裡不再詳述
從這裡看來有兩個需要注意的地方:
1、

根據原文的描述,這裡應該是把booked listing也強製作為windows中的一部分了,也就是實際上上面公式的第一項

其實可以和
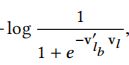
直接進行合併了。
2、關於目標函數的修改,我一開始以為這裡的魔改是目標函數公式層面的修改,就類似於app2vec:

中引入app之間的使用時間作為權重,但是其實上面所描述的目標函數的修改其實是在樣本層面進行的,換句話說,我們其實可以通過樣本構造方式的實現上述的目標函數的改變,而模型本身仍舊是使用原本的skip-gram+nce版的word2vec的方法即可。
所以整體上實現起來難度就會低一些,我們可以使用tf版的word2vec的api,然後樣本構造的時候按照上文的邏輯進行樣本改在,這篇論文的價值倒不是這裡的對booked listing的處理或者是同地區的負取樣樣本的擴充,而是提供了一個很好地將業務目標融合到模型訓練過程中的思路;
為了對embedding的效果進行檢驗,Airbnb還實現了一個tool,我們簡單貼一個相似embedding listing的結果。

從中可以看到,embedding不僅encode了price,listing-type等資訊,甚至連listing的風格資訊都能抓住,說明即使我們不利用圖片資訊,也能從用戶的click session中挖掘出相似風格的listing。
這裡的描述很有意思,這也是一種很好的解決問題的思路,就是遇到難以解決的問題換一個角度切入也許有意想不到的效果,graph algorithms之所以橫空出世一炮而紅,很大程度上其實是因為給我們解決問題的思路提供了一個全新的角度,例如反欺詐的應用,我們以往可能會從用戶的交易序列數據層面入手去做時間序列異常檢測,或者是從直接根據欺詐用戶的標籤,使用有監督學習,特徵工程+lgb一把梭的方式,或者是根據用戶的一些關鍵特徵做一些無監督異常檢測的工作,而圖演算法提供給了我們一種全新的視角,從社交網路關係的層面出發去嘗試解決問題,這是一種非常好的思考問題的方式。這也是為什麼要在知識方面有一定廣度的原因,更廣泛的知識能夠提供更多的可能的問題的解決方案。


