數據湖的概念以及解決方案
- 2019 年 10 月 3 日
- 筆記
今天這篇文章主要介紹數據湖(data lake)的定義,其次介紹各大雲廠商的解決方案以及目前的開源解決方案。
定義
看下維基百科的定義:數據湖是一個以原始格式(通常是對象塊或文件)存儲數據的系統或存儲庫。數據湖通常是所有企業數據的單一存儲。用於報告、可視化、高級分析和機器學習等任務。數據湖可以包括來自關係資料庫的結構化數據(行和列)、半結構化數據(CSV、日誌、XML、JSON)、非結構化數據(電子郵件、文檔、pdf)和二進位數據(影像、音頻、影片)。定義中的重點內容我用紅色字體標註出來,簡單說明一下這幾點。
- 原始格式:數據不做預處理,保存數據的原始狀態
- 單一存儲:存儲庫中會匯總多種數據源,是一個單一庫
- 用於機器學習:除了 BI 、報表分析,數據湖更適用於機器學習
數據湖並不是新概念,最早 2015 年就被提出來了,可以看到數據湖經常被拿來跟目前的數據倉庫作比較。下面是Google搜到的一篇比較早的數據湖和數據倉庫對比的文章

至於為什麼數據湖慢慢走近大家的視野,並且越來越多的跟倉庫作比較。我認為主要是跟機器學習的廣泛應用有很大關係。
數據湖和數據倉庫的對比
大數據剛興起的時候,數據主要用途是 BI 、報表、可視化。因此數據需要是結構化的,並且需要 ETL 對數據進行預處理。這個階段數據倉庫更適合完成這樣的需求,所以企業大部分需要分析的數據都集中到數據倉庫中。而機器學習的興起對數據的需求更加靈活,如果從數據倉庫中提數會有一些問題。比如:數據都是結構化的;數據是經過處理的可能並不是演算法想要的結果;演算法同學與數倉開發同學溝通成本較大等。我在工作中就遇到這種情況,做演算法的同學需要經常理解我們的數倉模型,甚至要深入到做了什麼業務處理,並且我們的處理可能並不是他們的想要的。基於上面遇到的各種問題,數據湖的概念應運而生。下面的表格對比一下數據湖和數據倉庫的區別,主要來自 AWS 。

從以上表格的區別上我們可以看到數據湖的應用場景主要在於機器學習,並且在用的時候再建 Schema 更加靈活。雖然數據湖能夠解決企業中機器學習應用方面的數據訴求,可以與數據倉庫團隊解耦。但並不意味著數據湖可以取代數據倉庫,數據倉庫在高效的報表和可視化分析中仍有優勢。
雲廠商的解決方案
近幾年雲計算的概念也是非常火,各大雲廠商自然不會錯失數據湖的解決方案。下面簡單介紹阿里雲、AWS 和 Azure 分別的數據產品。
- 阿里云:Data Lake Analytics,通過標準JDBC直接對阿里雲OSS,TableStore,RDS,MongoDB等不同數據源中存儲的數據進行查詢和分析。DLA 無縫集成各類商業分析工具,提供便捷的數據可視化。阿里雲OSS 可以存儲各種結構化、半結構化、非結構化的數據,可以當做一個數據湖的存儲庫。DLA 使用前需要創建 Schema 、定義表,再進行後續分析。
- AWS:Lake Formation,可以識別 S3 或關係資料庫和 NoSQL 資料庫中存儲的現有數據,並將數據移動到 S3 數據湖中。使用 EMR for Apache Spark(測試版)、Redshift 或 Athena 進行分析。支援的數據源跟阿里雲差不多。
- Azure:Azure Data Lake Storage,基於 Azure Blob 存儲構建的高度可縮放的安全 Data Lake 功能,通過 Azure Databricks 對數據湖中的數據進行處理、分析。但文檔中並沒有看到支援其他數據源的說明
開源解決方案
除了雲廠商提供的方案外, 還有一個開源解決方案——kylo 。這個框架的關注度並不高,社區不是很活躍。大概看了下官網的介紹影片,基本上與雲廠商的解決方案一致。支援多種數據源,分析時創建 Schema。另外,Databricks 團隊(開源 Spark 框架)年初開源了 Delta lake 框架, Delta lake 是存儲層,為數據湖帶來了可靠性。Delta Lake 提供 ACID 事務、可伸縮的元數據處理,並統一流和批數據處理。Delta Lake運行在現有數據湖之上,與Apache Spark api完全兼容。架構圖如下:
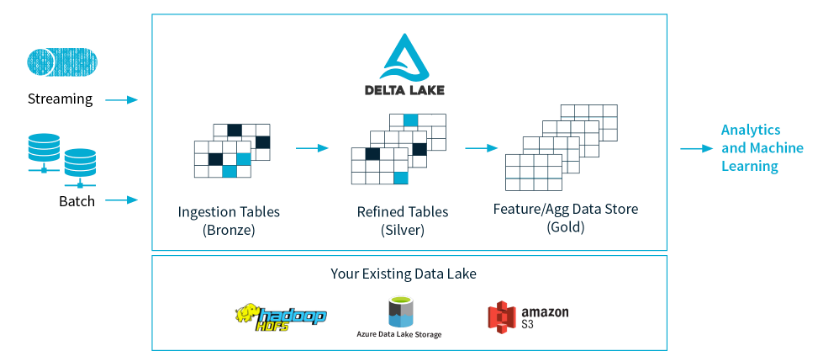
小結
今天這篇文章主要介紹了數據湖的概念,以及數據湖與數據倉庫的區別,然後簡單了解了目前數據湖在雲廠商和開源軟體中的解決方案。作為數倉建設和數據開發人員要密切關注這種新的概念,如果我們的工作中遇到這種問題我們也可以思考是否可以推動數據湖的建設。另外,作為中小企業上雲的方案可能是一個比較好的選擇,畢竟開源解決方案目前不是很成熟,社區還不是很強大。
公眾號「渡碼」,分享更多高品質內容

