python-卷積神經網路全面理解-tensorflow實現手寫數字識別
- 2019 年 10 月 3 日
- 筆記
首先,關於神經網路,其實是一個結合很多知識點的一個演算法,關於cnn(卷積神經網路)大家需要了解:
下面給出我之前總結的這兩個知識點(基於吳恩達的機器學習)
代價函數:
代價函數
代價函數(Cost Function )是定義在整個訓練集上的,是所有樣本誤差的平均,也就是損失函數的平均。
具體的了解請看我的部落格:
https://blog.csdn.net/qq_40594554/article/details/97389489
梯度下降:
梯度下降一般講解採用單變數梯度下降,但是一般在程式中常用多變數梯度下降
單變數梯度下降大家可以了解最小二乘法,多變數梯度下降也是基於上述知識點演化而來,具體講解可以看我的部落格:
https://blog.csdn.net/qq_40594554/article/details/97391667
在這裡,我們以上述知識點為基礎,了解深度神經網路裡面的卷積神經網路:
大家可以看我這兩篇了解神經網路相關知識點
神經網路:https://blog.csdn.net/qq_40594554/article/details/97399935
神經網路入門:https://blog.csdn.net/qq_40594554/article/details/97617154
神經網路的一個大致流程如下:

例如:我們有三個數據:x1,x2,x3,我們將其輸入到我們的這個神經網路中,我們稱L1為輸入層,L2為隱藏層,L3為輸出層
我們用通俗的話來描述:即為我們的輸入層L1輸入3個數據,通過3個神經單元a1,a2,a3,其中x1,x2,x3在a1中佔有不同的權值,x1,x2,x3在a2中又佔有不同的權值,x1,x2,x3在a3中佔有不同的權值
通過代價函數求出最優解,即為最優權值,最後得出a1,a2,a3的值,然後a1,a2,a3再通過L3的這個神經單元,通過權值計算得出輸出,這就是一個最簡單的神經網路,如果不是很理解,大家可以看我上面的部落格。
下面我用tensorflow實現普通的神經網路:即為通過幾層隱藏層來進行權值確定。
上述中的相關神經元計算,類似於一個黒夾子,計算過程是不顯示的我們最後知道的是結果,在傳統神經網路計算中,一般計算的神經元是非常多的,所以傳統神經網路無法滿足,容易出現計算量大,但是準確率低的可能性,於是出現了卷積神經網路!
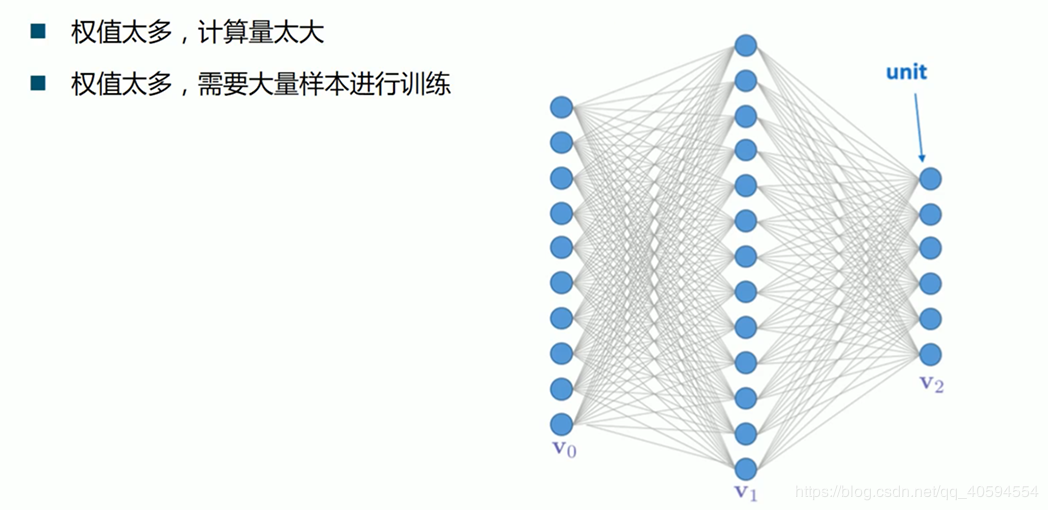
上圖中,我們需要計算的權值非常多,就需要大量的樣本訓練,我們模型的構建,需要根據數據的大小來建立,防止過擬合,以及欠擬合。
因此,cnn演算法通過感受野和權值共享減少了神經網路需要訓練的參數個數,如圖(大家可以百度了解這是什麼意思):

其實卷積神經網路很容易理解:
他的最簡單相關步驟為:積卷層-池化層-積卷層-池化層-….-全連接層
卷積層:數據通過卷積核,按照卷積核的步長,一步一步掃描,得出一個新的特徵圖
池化層:通過卷積核掃描後得出的特徵圖,進行池化,實際上池化層也是加強特徵圖的一個手段
卷積層(建議大家可以百度卷積核是什麼):

池化層(常用的有最大值池化,平均池化):
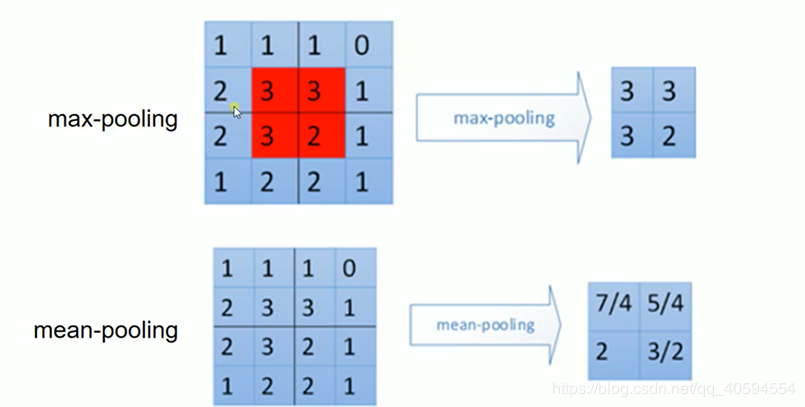
實際上通過上述手段主要是來獲取和增強特徵
至於全連接層,即為通過池化後的結果,通過激勵函數後,排除不需要的特徵圖,然後輸出:
我這裡給出一個關於手寫數字識別的源碼:
import tensorflow as tf#9.50 from tensorflow.examples.tutorials.mnist import input_data #載入數據集 mnist=input_data.read_data_sets("MNNIST_data",one_hot=True)#下載網上的數據集 #print(mnist) #每個批次的大小,每次放入100張圖片放入神經網路訓練。 batch_size=100 #計算一共有多少批次 n_bach=mnist.train.num_examples//batch_size#//整除 #初始化權值 def weight_variable(shape): inital=tf.truncated_normal(shape,stddev=0.1) return tf.Variable(inital) #初始化偏置值 def bias_variable(shape): initial=tf.constant(0.1,shape=shape) return tf.Variable(initial) #卷積層 def conv2d(x,W): return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') #使用了這個庫,tf.nn.conv2d #池化層 def max_pool_2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') #定義兩個placeholder x=tf.placeholder(tf.float32,[None,784])#784列 y=tf.placeholder(tf.float32,[None,10])#0-9,10個數字 #改變x的格式轉為4d向量[batch,in_height,in_width,in_channels] x_image=tf.reshape(x,[-1,28,28,1]) #初始化第一個卷積層的權值和偏置值 W_conv1=weight_variable([5,5,1,32])#採用5*5的取樣窗口,32個卷積核從1個平面抽取特徵 b_conv1=bias_variable([32])#每個卷積核一個偏置值 #把x_image和權值向量進行卷積,再加上偏置值,然後應用於relu激活函數 h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1) h_pool1=max_pool_2(h_conv1)#進行max-pooling #初始化第二個卷積層的權值和偏置值 W_conv2=weight_variable([5,5,32,64])#採用5*5的取樣窗口,32個卷積核從1個平面抽取特徵 b_conv2=bias_variable([64])#每個卷積核一個偏置值 #把x_image和權值向量進行卷積,再加上偏置值,然後應用於relu激活函數 h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) h_pool2=max_pool_2(h_conv2)#進行max-pooling #初始化第一個全連接的權值 W_fcl=weight_variable([7*7*64,1024])#上一場有7*7*64個神經元,全連接層有1024個神經元 b_fcl=bias_variable([1024])#1024個節點 #把池化層2的輸出扁平化維一維 h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) #求第一個全連接的輸出 h_fcl=tf.nn.relu(tf.matmul(h_pool2_flat,W_fcl)+b_fcl) #keep_prob表示神經元的輸出概率 keep_prob=tf.placeholder(tf.float32) h_fcl_drop=tf.nn.dropout(h_fcl,keep_prob) #初始化第二個全連接層 W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10]) #計算輸出 prediction=tf.nn.softmax(tf.matmul(h_fcl_drop,W_fc2)+b_fc2) #交叉熵代價函數 cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction)) #使用Adamoptimizer進行優化 train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #結果存放在一個布爾列表中 correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))#argmax返回一維張量中最大值所在位置 #求準確率 accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session()as sess: sess.run(tf.global_variables_initializer()) #把所有圖片訓練21次 for epoch in range(21): # 執行一次,即為把訓練集的所有圖片循環一次 for batch in range(n_bach): #獲取100張圖片,圖片數據保存在_xs,標籤保存在ys batch_xs,batchys=mnist.train.next_batch(batch_size) sess.run(train_step,feed_dict={x:batch_xs,y:batchys,keep_prob:0.7}) #傳進測試集,數據集的數據 acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0}) print("第"+str(epoch)+"準確率:"+str(acc))
很容易第一次就可以得出很高的準確率:
希望大家能夠看懂cnn演算法的流程(講的比較多,當然CNN演算法不可能一篇文章就學會了,我這裡僅僅給大家講了CNN演算法的一個流程)。我之前的相關博文也在上面,可能對大家的理解有幫助,大家可以查看。
個人水平有限,目前還不能實現手寫CNN演算法以及數學公式,後面會繼續學習,當然,對於機器學習,神經網路推薦大家先從影片學習開始,例如:吳恩達的機器學習。
最後希望大家學有所成!
