理解深度學習:神經網路的雙胞胎兄弟-自編碼器(上)
前言
本篇文章可作為<利用變分自編碼器實現深度換臉(DeepFake)>的知識鋪墊。
自編碼器是什麼,自編碼器是個神奇的東西,可以提取數據中的深層次的特徵。
例如我們輸入影像,自編碼器可以將這個影像上「人臉」的特徵進行提取(編碼過程),這個特徵就保存為自編碼器的潛變數,例如這張人臉的膚色以及頭髮顏色,自編碼器在提取出這些特徵之後還可以通過這些特徵還原我們的原始數據。這個過程稱作「解碼」。
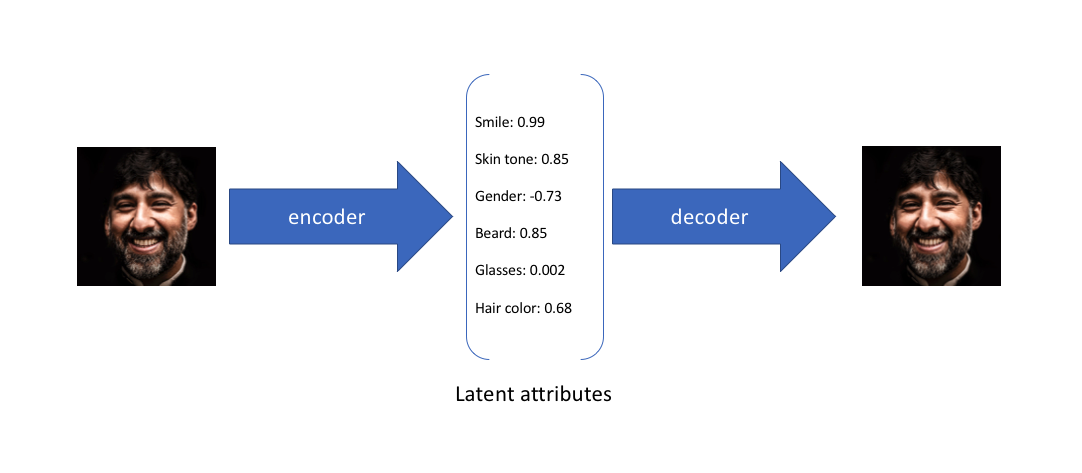
(以下相關圖來自於jeremy)
自編碼器其實也是神經網路的一種,神經網路我們都知道,我們設計好網路層,輸入我們的數據,通過訓練提供的數據進行前向操作提取特徵,然後與準備好的標記進行比較,通過特定的損失函數來得到損失,然後進行反向操作實現對目標的分類和標定。
那麼自編碼器為什麼說和神經網路很像呢?
什麼是自編碼器
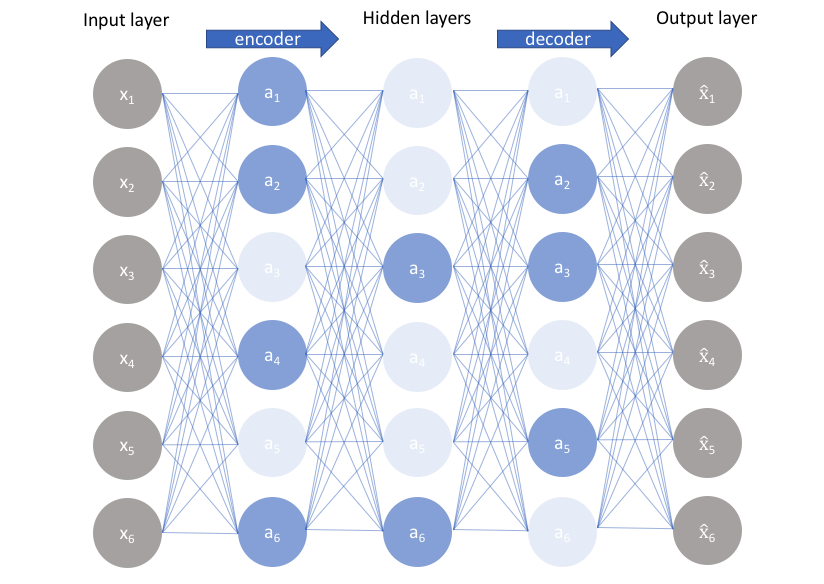
自編碼器也有自己的網路層,在自編碼器中通常稱之為隱藏層$h$,一個自編碼器通常包含兩個部分,一個為$h=f(x)$表示的編碼器,另一個是$s=g(h)$表示的解碼器。也就是$s=g(f(x))$。
當然編碼器不可能輸入$x$輸出$x$,那樣就太沒意思了,編碼器的主要特點是吸收輸入數據的「特點」,然後再釋放出來,可以理解為隨機映射$p_{encoder}(h|x)$和$p_{decoder}(x|h)$。
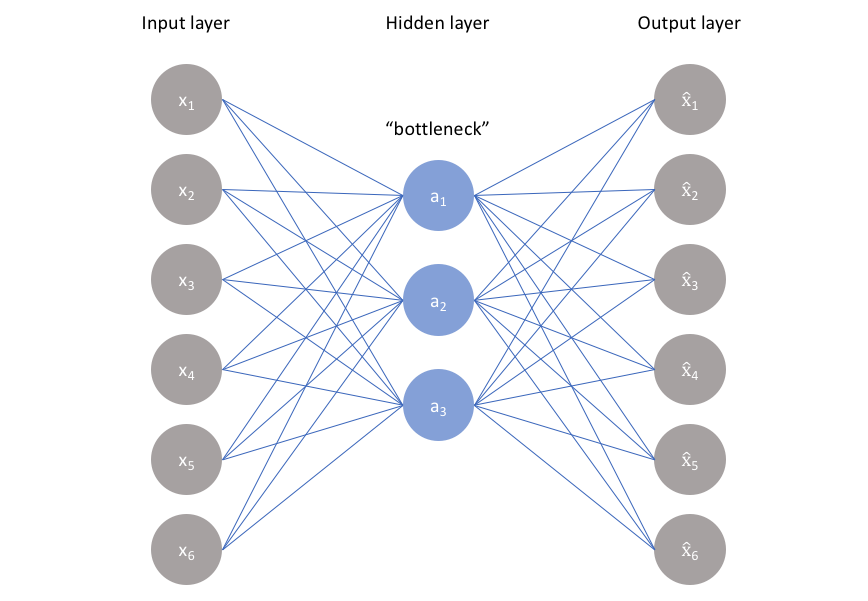
如上圖(來自Jeremyjordan),我們可以看到輸入input layer和output layer的維數是一樣的,而隱含層的維數較小,所以我們也將自編碼器理解為降維的過程。
但是要注意,自編碼器屬於無監督學習,也就是說,不同於神經網路,自編碼器不需要任何其他的數據,只需要對輸入的特徵進行提取即可,當然我們要添加一些額外的限制條件來「強迫」自編碼器提取我們想要的東西。
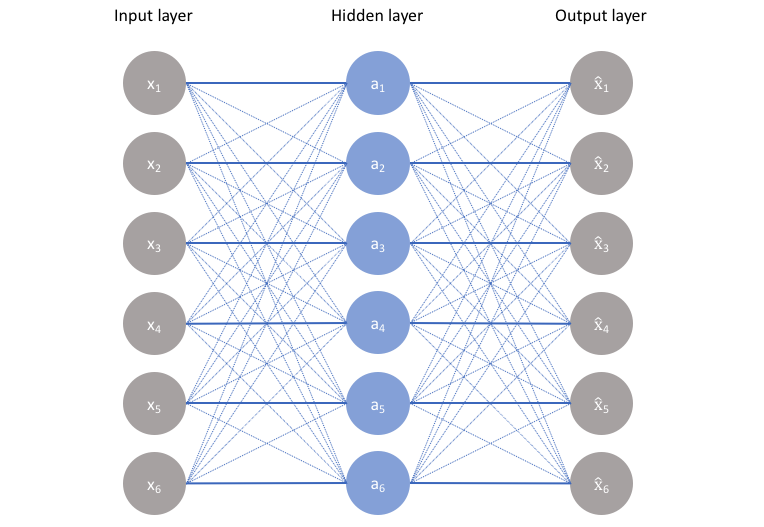
如果是上面這種網路的話,全是線性激活層,激活層可以記憶我們的輸入,但也僅僅是記住了而已。在實際應用中,我們需要的隱含層應該可以很好地構建我們輸入數據的資訊,學習到我們的輸入數據的一些分布和特點。
欠完備自編碼器
自編碼器我們想要它能夠對輸入的數據進行分析獲取一些特性,而不是簡單的輸入輸出,所以我們通過限制h的維度來實現,強迫自編碼器去尋找訓練數據中最顯著的特徵。
為什麼叫欠完備,那是因為$h$的維度比輸入$x$小。
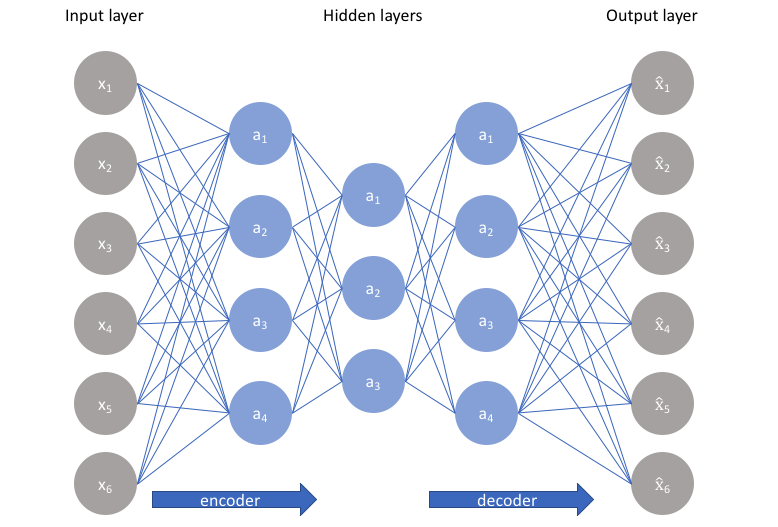
我們通過對輸出設置一個損失函數(和神經網路中的損失函數相似):
$$L(x,g(f(x)))$$
然後通過減少損失(這個損失可以是均方誤差等)來使$h$隱含層學習數據中最重要的資訊。也就是學習數據中的潛在特性(Latent attributes)。
說白了這個自編碼器和PCA(PCA是一個簡單的機器學習演算法,通過尋找矩陣中最大的特徵向量來尋找輸入數據的「特點」)很像。都是通過編碼和解碼來得到訓練數據的隱含資訊,但是如果這個隱含層是線性層(上圖提到的)或者隱含層的容量很大,那麼自編碼器就無法學習到我們輸入數據的有用資訊。僅僅起一個複製的作用。
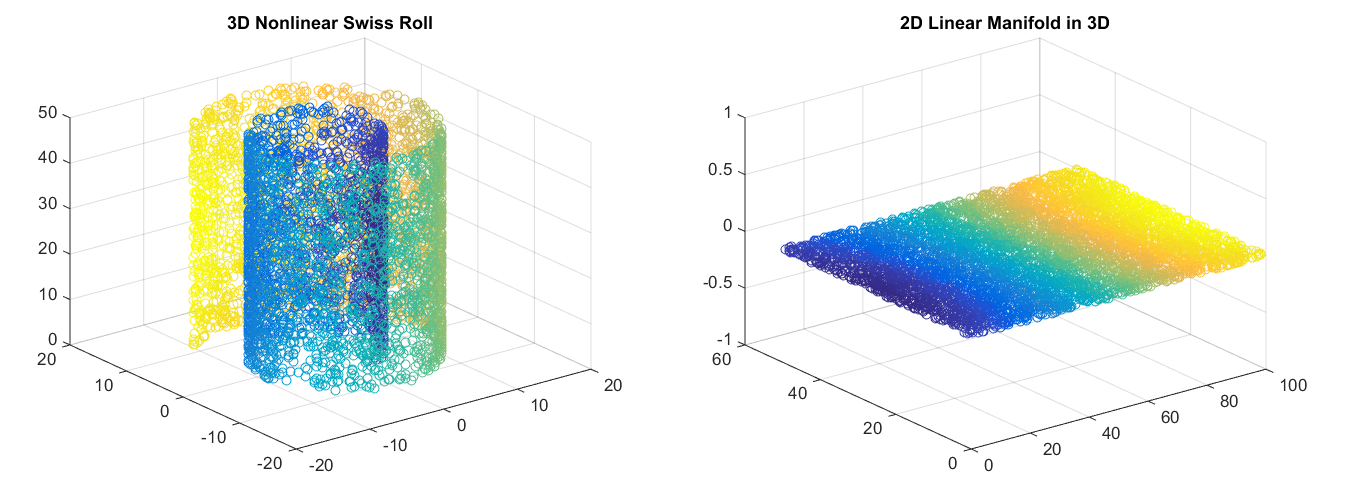
自編碼器和PCA的不同在於自編碼器可以學習到非線性特徵,也就是通過非線性編碼和非線性解碼自編碼器可以實現對數據的理解還原操作。對於高維的數據,自編碼器就可以學習到一個複雜的數據表示(流形,manifold)。這些數據表示可以是二維的或者三維的形態(取決於我們自己的設置)。
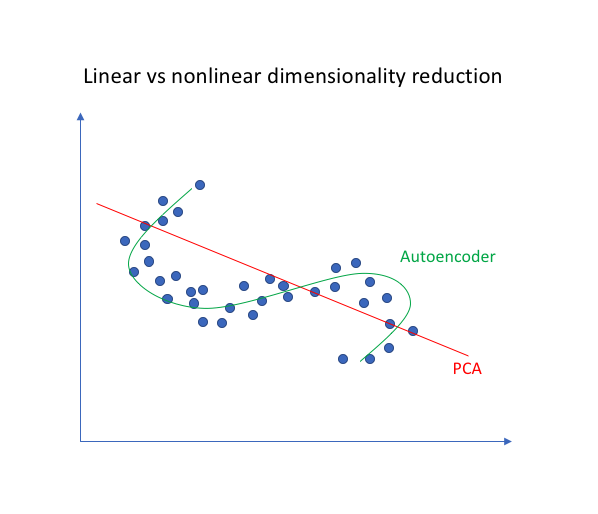
為什麼非線性的映射能夠學到更多的東西,當然是因為非線性的表示能力更強,學習到的東西越多,從下圖可以看出,對於二維空間中的一系列點,直線擬合(PCA)遠遠不如曲線擬合(自編碼器)。
我們利用Pytorch(v0.4.0)簡單編寫一個程式來觀察一下欠完備自編碼器的效果:
首先我們設計一個基本的網路層(自編碼器層),這裡我們輸入的數據是MNIST手寫數據集,數據集的影像大小是28*28=784,所以我們設計的欠完備自編碼器將我們的輸入特徵進行降維操作(我們輸入的是$28 *28=784$維的數據),然後我們進行三次降維,將784維降到3維這樣我們就可以將其進行可視化了。
下面自編碼器層的設計:
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 自編碼器的編碼器構造
self.encoder = nn.Sequential(
nn.Linear(28*28, 128), # 784 => 128
nn.LeakyReLU(0.1, inplace=True), # 激活層
nn.Linear(128, 64), # 128 => 64
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(64, 12), # 64 => 12
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(12, 3), # 最後我們得到3維的特徵,之後我們在3維坐標中進行展示
)
# 自編碼器的解碼器構造
self.decoder = nn.Sequential(
nn.Linear(3, 12), # 3 => 12
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(12, 64), # 12 => 64
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(64, 128), # 64 -> 128
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(128, 28*28), # 128 => 784
nn.Sigmoid(), # 壓縮值的範圍到0-1便於顯示
)
def forward(self, x):
hidden = self.encoder(x) # 編碼操作,得到hidden隱含特徵
output = self.decoder(hidden) # 解碼操作,通過隱含特徵還原我們的原始圖
return hidden, output
我們的優化器為:
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=configure['lr'])
然後建立損失函數就可以進行訓練了。
我們首先讀取我們需要的數字影像集MNIST,然後將其投入我們設計的自編碼器中進行訓練,我們分別用原始輸入影像和重構後的影像進行損失訓練,通過降低損失我們就可以提取到數字數據集中的特徵。最後,我們將我們提取的三維特徵用三維坐標表示出來:
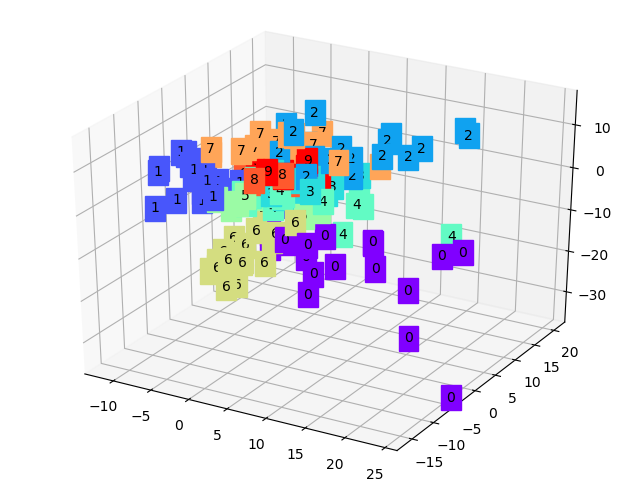
顯然可以看到,每種數字(0-9)都有各自的特徵簇,它們通常都聚在一起,換個角度再看一下:
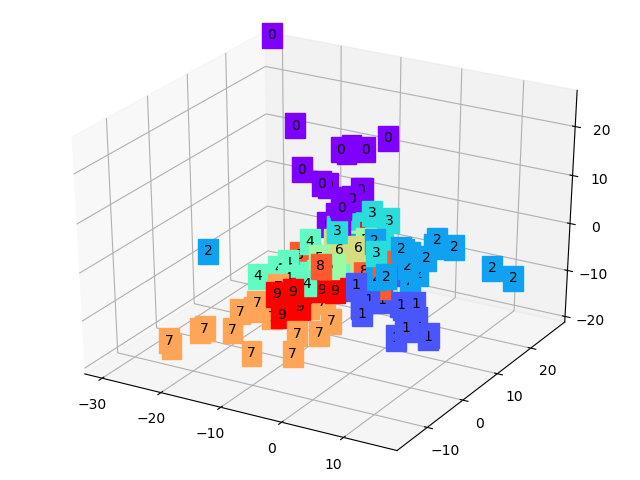
這樣我們就把一些數字圖從784維降到3維,將其提取到的特徵通過三維坐標展示出來了。
我們也可以還原我們的輸入數據(上一行是輸入的影像,下一行是通過3維特徵還原出來的),雖然還原的比較模糊,但是也可以看出我們正確提取了這些數字的特徵。
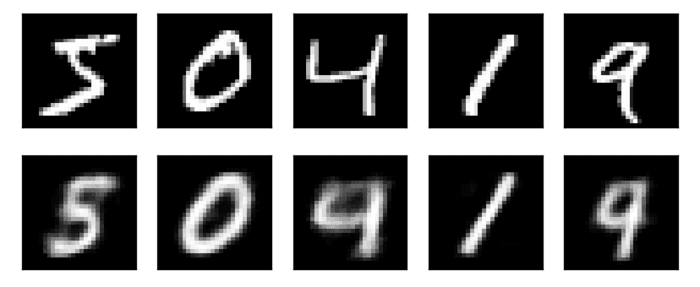
稀疏自編碼器
稀疏自編碼器是正則編碼器的一種,正則即代表正則化,在之前的自編碼器中我們的隱藏層的維數是小於輸入層的,因此我們可以強迫自編碼器學習數據的「特徵」。但是,如果隱含層的維數和輸入層的維數相同或者大於輸入層的維數(也可以說是容量)。那麼我們的自編碼器可能就學不到什麼有用的東西了。
這個時候應該怎麼辦,我們可以學習神經網路中經常用到的東西,那就是正則化。
稀疏編碼器可以簡單表示為:
$$L(x,g(f(x))) + \Omega(h)$$
其中$g(h)$表示解碼器的輸出,$h$是編碼器的輸出$h=f(x)$。
很簡單,我們在損失函數的後面加了一項正則項,也可以稱作懲罰項。結合一些神經網路的概念,我們可以將其理解為自編碼器前饋網路中的正則項。
我們一般使用的正則項是L1正則損失,懲罰權重的絕對值,然後使用正則$\lambda$係數來調整。
$$ L(x,\hat x)+ \lambda\sum\limits_i|a_i^{(h)}|$$
另外一個常用的是$KL$散度,KL散度通常用來評價兩個分布的關係,選擇一個分布(通常是Bernoulli分布)然後將我們權重係數的分布與之進行比較,將其作為損失函數的一部分:
$$L(x,\hat x)+\sum\limits_{j}KL(\rho||\hat \rho_j)$$
其中$\rho$是我們選擇要比較的分布,而$\hat \rho$表示我們權重係數的分布。
另外在《深度學習》中,有對稀疏編碼器通過最大似然進行解釋:


通過解釋我們可以知道為什麼通過加入正則項可以使隱含層學習到我們想要讓學習到的東西。
還有個小問題,為什麼叫稀疏自編碼器,看下面的圖就可以知道,隱含層中有些結點消失了,自然就變稀疏了。稀疏的隱含層與我們之前介紹的欠完備隱含層的區別是:稀疏自編碼器可以使我們的隱含層中相對獨立的結點對特定的輸入特徵或者屬性變得更加敏感。 也就是說欠完備的自編碼器的隱含層對輸入數據所有的資訊進行觀測利用,而稀疏則不同,它是有選擇性的,只對感興趣的區域進行探測。
通過上面的稀疏策略我們可以保證在不犧牲網路對特徵提取能力的同時,減少網路的容量,這樣我們就可以挑輸入資訊中的特定資訊去提取。
我們再通過Pytorch編程式來演示一下,我們修改自編碼器的隱含層,將隱含層改成為與輸入數據相同的維數(784),這樣如果進行訓練的話…損失函數的損失值是不會下降的,我們根據稀疏自編碼器的特點加上一個正則項(懲罰項),怎麼加呢,其實對權重進行懲罰那就是權重衰減,我們在設計優化器的時候加上一句話就可以了:
# weight_decay為權重衰減係數,我們這裡設置為1e-4
# 但這裡的懲罰函數為L2
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=configure['lr'], weight_decay=1e-4)
這樣就相當於算上了對權重的正則項,然後是我們的自編碼層,可以看到所有維數都是一樣的。
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 28*28), # 現在所有隱含層的維數是一樣的,沒有縮小也沒有放大
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(28*28, 28*28),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(28*28, 28*28),
)
self.decoder = nn.Sequential(
nn.Linear(28*28, 28*28),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(28*28, 28*28),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(28*28, 28*28),
nn.Sigmoid(),
)
def forward(self, x):
hidden = self.encoder(x)
output = self.decoder(hidden)
return hidden, output
當然我們也可以通過dropout來實現對權重的懲罰,這裡就不演示了,我們對上面的自編碼器進行訓練得到的結果,然後對數字5的影像進行重構:
好吧,效果沒有之前那個好,可能是正則化係數(權重衰減係數)需要調一下,但這個簡單的例子也足以說明我們可以通過正則化來使隱含層學習我們想要學習的東西。
未完待續。
參考資料:
撩我吧
- 如果你與我志同道合於此,老潘很願意與你交流;
- 如果你喜歡老潘的內容,歡迎關注和支援。
- 如果你喜歡我的文章,希望點贊👍 收藏 📁 評論 💬 三連一下~
想知道老潘是如何學習踩坑的,想與我交流問題~請關注公眾號「oldpan部落格」。
老潘也會整理一些自己的私藏,希望能幫助到大家,點擊神秘傳送門獲取。

