搞懂分散式技術11:分散式session解決方案與一致性hash
- 2019 年 12 月 2 日
- 筆記
本文內容參考網路,侵刪
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫
https://github.com/h2pl/Java-Tutorial
文章將同步到我的個人部落格:
www.how2playlife.com
該系列博文會告訴你什麼是分散式系統,這對後端工程師來說是很重要的一門學問,我們會逐步了解常見的分散式技術、以及一些較為常見的分散式系統概念,同時也需要進一步了解zookeeper、分散式事務、分散式鎖、負載均衡等技術,以便讓你更完整地了解分散式技術的具體實戰方法,為真正應用分散式技術做好準備。
如果對本系列文章有什麼建議,或者是有什麼疑問的話,也可以關注公眾號【Java技術江湖】聯繫作者,歡迎你參與本系列博文的創作和修訂。
一、問題的提出
1. 什麼是Session?
用戶使用網站的服務,需要使用瀏覽器與Web伺服器進行多次交互。HTTP協議本身是無狀態的,需要基於HTTP協議支援會話狀態(Session State)的機制。具體的實現方式是:在會話開始時,分配一個 唯一的會話標識(SessionID),並通過Cookie將這個標識告訴瀏覽器,以後每次請求的時候,瀏覽器都會帶上這個會話標識SessionID來告訴Web伺服器這個請求是屬於哪個會話的。在Web伺服器上,各個會話都有獨立的存儲,保存不同會話的資訊。如果遇到禁用Cookie的情況,一般的做法就是把這個會話標識放到URL的參數中。
2. 什麼是Session一致性問題?
當Web伺服器從一台變為多台時,就會出現Session一致性問題。
如上圖所示,當一個帶有會話標識的HTTP請求到了Web伺服器後,需要在HTTP請求的處理過程中找到對應的會話數據(Session)。但是,現在存在的問題就是:如果我第一次訪問網站時請求落到了左邊的伺服器,那麼我的Session就創建在左邊的伺服器上了,如果我們不做處理,就不能保證接下來的請求每次都落在同一邊的伺服器上了。這就是Session一致性問題。
二、Session一致性解決方案
1. Session Stiky
在單機的情況下,會話保存在單機上,請求也是由這個機器處理,因此不會有問題。當Web伺服器變為多台以後,如果保證同一個會話的請求都在同一個Web伺服器上處理,則對該會話來說,與之前單機的情況是一樣的。
如果要做到這樣,就需要負載均衡器能夠根據每次請求的會話標識SessionID來進行請求轉發,如下圖所示。這種方式稱之為Session Stiky方式。
該方案本身非常簡單,對於Web伺服器來說,該方案和單機的情況是一樣的,只是我們在負載均衡器上做了手腳。這個方案可以讓同樣Session的請求每次都發送到同一個Web伺服器來處理,非常利於針對Session進行服務端本地的快取。
其所存在的問題包括:
- 如果有一台Web伺服器宕機或者重啟,則該機器上的會話數據就會丟失。如果會話中有登錄狀態數據,則用戶需要重新登陸。
- 會話標識是應用層的資訊,則負載均衡器要將同一個會話的請求都保存到同一個Web伺服器上的話,就需要進行應用層(七層)的解析,這個開銷比第四層的交換要大。
- 負載均衡器變為了一個有狀態的節點,要將會話保存到具體Web伺服器的映射,因此記憶體消耗會更大,容災會更麻煩。
打個比方來說,對於Session Stiky,如果說Web伺服器是我們每次吃飯的飯店,會話數據就是我們吃飯用的碗筷。要保證每次吃飯都用自己的碗筷,我就把餐具存在某一家,並且每次都去這家店吃,這是個不錯的主意。
2. Session Replication
如果我們繼續以去飯店吃飯類比,那麼除了前面的方式之外,如果我在每個店都存放一套自己的餐具,就可以更加自由地選擇飯店。Session Replication就是這樣一種方式,如下圖所示。
可以看到,在Session Replication方中,不再要求負載均衡器來保證同一個會話地多次請求必須到同一個Web伺服器上了。而我們的Web伺服器之間則增加了會話數據的同步。通過同步就保證了不同Web伺服器之間的Session數據的一致。
但是,Session Replication方案也存在一些問題,包括:
- 同步Session數據造成了網路頻寬的開銷。只要Session數據有變化,就需要將數據同步到其他所有機器上,機器數越多,同步帶來的網路頻寬開銷就越大。
- 每台Web伺服器都要保存所有的Session數據,如果整個集群的Session數很多的話,每台機器用於保存Session數據的內容佔用會很嚴重。
這就是Session Replication方案。這個方案是靠應用容器來完成Session的複製從而使得應用解決Session問題的,應用本身並不關心這個事情。不過,這個方案並不適合集群機器數多的場景。如果只有幾台機器,用該方案是可以的。
3. Session數據集中存儲
同樣是希望同一個會話的請求可以發到不同的Web伺服器上,前面的Session Replication是一種方案,還有一種方案就是把Session數據集中存儲起來,然後不同Web伺服器從同樣的地方來獲取Session。其大概的結構如下圖所示:
可以看到,與Session Replication方案一樣的部分是,會話請求經過負載均衡器後,不會被固定在同樣的Web伺服器上。不同的地方是,Web伺服器之間沒有Session數據複製,並且Session數據也不是保存在本機了,而是放在了另一個集中存儲的地方。這樣,無論是哪台Web伺服器,也無論修改的是哪個Session的數據,最終的修改都發生在這個集中存儲的地方,而Web伺服器使用Session數據時,也是從這個集中存儲Session數據的地方來讀取。對於Session數據存儲的具體方式,可以使用資料庫,也可以使用其他分散式存儲系統。這個方案解決了Session Replication方案中記憶體的問題,而對於網路頻寬,該方案也比Session Replication要好。
不過,該方案仍存在一些問題,包括:
- 讀寫Session數據引入了網路操作,這相對於本機的數據讀取來說,問題就在於存在時延和不穩定性,不過由於通訊基本發生在內網,問題不大。
- 如果集中存儲Session的機器或者集群存在問題,這就會影響我們的應用。
相對於Session Replication,當Web伺服器數量比較大時、Session數比較多的時候,集中存儲方案的優勢是非常明顯的。
4. Cookie Based
對於Cookie Based方案,它對同一個會話的不同請求也是不限制具體處理機器的。與Session Replication和Session數據集中管理的方案不同,這個方案是通過Cookie來傳遞Session數據的。具體如下圖所示。
可以看出,我們的Session數據存放在Cookie中,然後在Web伺服器上從Cookie中生成對應的Session數據。這就好比我每次都把自己的碗筷帶在身上,這樣我去哪家飯店吃飯就可以隨意選擇了。相對於前面的集中存儲,這個方案不會依賴外部的一個存儲系統,也就不存在從外部系統獲取、寫入Session數據的網路時延和不穩定性了。
不過,該方案依然存在不足,包括:
- Cookie長度限制。由於Cookie是有長度限制的,這也會限制Session數據的長度。
- 安全性。Session數據本來都是伺服器端數據,而這個方案是讓這些服務端數據到了外部外部網路及客戶端,因此存在安全性的問題。
- 頻寬消耗。這裡指的不是內部Web伺服器之間的頻寬的消耗,而是我們數據中心的整體外部貸款的消耗。
- 性能消耗。每次HTTP請求和響應都帶有Session數據,對Web伺服器來說,在同樣的處理情況下,響應的結果輸出越少,支援的並發請求就會越多。
三、總結
綜合而言,上述所有方案都是解決session問題的方案,對於大型網站來說,Session Sticky和Session集中管理是比較好的方案。
一、前言
在解決分散式系統中負載均衡的問題時候可以使用Hash演算法讓固定的一部分請求落到同一台伺服器上,這樣每台伺服器固定處理一部分請求(並維護這些請求的資訊),起到負載均衡的作用。
但是普通的餘數hash(hash(比如用戶id)%伺服器機器數)演算法伸縮性很差,當新增或者下線伺服器機器時候,用戶id與伺服器的映射關係會大量失效。一致性hash則利用hash環對其進行了改進。
二、一致性Hash概述
為了能直觀的理解一致性hash原理,這裡結合一個簡單的例子來講解,假設有4台伺服器,地址為ip1,ip2,ip3,ip4。
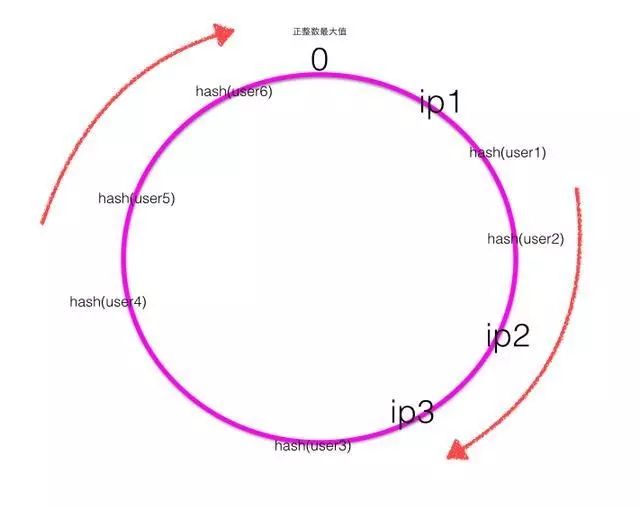
一致性hash是首先計算四個ip地址對應的hash值hash(ip1),hash(ip2),hash(ip3),hash(ip3),計算出來的hash值是0~最大正整數直接的一個值,這四個值在一致性hash環上呈現如下圖:

hash環上順時針從整數0開始,一直到最大正整數,我們根據四個ip計算的hash值肯定會落到這個hash環上的某一個點,至此我們把伺服器的四個ip映射到了一致性hash環當用戶在客戶端進行請求時候,首先根據hash(用戶id)計算路由規則(hash值),然後看hash值落到了hash環的那個地方,根據hash值在hash環上的位置順時針找距離最近的ip作為路由ip.

如上圖可知user1,user2的請求會落到伺服器ip2進行處理,User3的請求會落到伺服器ip3進行處理,user4的請求會落到伺服器ip4進行處理,user5,user6的請求會落到伺服器ip1進行處理。
下面考慮當ip2的伺服器掛了的時候會出現什麼情況?
當ip2的伺服器掛了的時候,一致性hash環大致如下圖:

根據順時針規則可知user1,user2的請求會被伺服器ip3進行處理,而其它用戶的請求對應的處理伺服器不變,也就是只有之前被ip2處理的一部分用戶的映射關係被破壞了,並且其負責處理的請求被順時針下一個節點委託處理。
下面考慮當新增機器的時候會出現什麼情況?
當新增一個ip5的伺服器後,一致性hash環大致如下圖:

根據順時針規則可知之前user1的請求應該被ip1伺服器處理,現在被新增的ip5伺服器處理,其他用戶的請求處理伺服器不變,也就是新增的伺服器順時針最近的伺服器的一部分請求會被新增的伺服器所替代。
三、一致性hash的特性
單調性(Monotonicity),單調性是指如果已經有一些請求通過哈希分派到了相應的伺服器進行處理,又有新的伺服器加入到系統中時候,應保證原有的請求可以被映射到原有的或者新的伺服器中去,而不會被映射到原來的其它伺服器上去。這個通過上面新增伺服器ip5可以證明,新增ip5後,原來被ip1處理的user6現在還是被ip1處理,原來被ip1處理的user5現在被新增的ip5處理。分散性(Spread):分散式環境中,客戶端請求時候可能不知道所有伺服器的存在,可能只知道其中一部分伺服器,在客戶端看來他看到的部分伺服器會形成一個完整的hash環。如果多個客戶端都把部分伺服器作為一個完整hash環,那麼可能會導致,同一個用戶的請求被路由到不同的伺服器進行處理。這種情況顯然是應該避免的,因為它不能保證同一個用戶的請求落到同一個伺服器。所謂分散性是指上述情況發生的嚴重程度。平衡性(Balance):平衡性也就是說負載均衡,是指客戶端hash後的請求應該能夠分散到不同的伺服器上去。一致性hash可以做到每個伺服器都進行處理請求,但是不能保證每個伺服器處理的請求的數量大致相同,如下圖
伺服器ip1,ip2,ip3經過hash後落到了一致性hash環上,從圖中hash值分布可知ip1會負責處理大概80%的請求,而ip2和ip3則只會負責處理大概20%的請求,雖然三個機器都在處理請求,但是明顯每個機器的負載不均衡,這樣稱為一致性hash的傾斜,虛擬節點的出現就是為了解決這個問題。
五、虛擬節點
當伺服器節點比較少的時候會出現上節所說的一致性hash傾斜的問題,一個解決方法是多加機器,但是加機器是有成本的,那麼就加虛擬節點,比如上面三個機器,每個機器引入1個虛擬節點後的一致性hash環的圖如下:

其中ip1-1是ip1的虛擬節點,ip2-1是ip2的虛擬節點,ip3-1是ip3的虛擬節點。
可知當物理機器數目為M,虛擬節點為N的時候,實際hash環上節點個數為M*(N+1)。比如當客戶端計算的hash值處於ip2和ip3或者處於ip2-1和ip3-1之間時候使用ip3伺服器進行處理。
六、均勻一致性hash
上節我們使用虛擬節點後的圖看起來比較均衡,但是如果生成虛擬節點的演算法不夠好很可能會得到下面的環:

可知每個服務節點引入1個虛擬節點後,情況相比沒有引入前均衡性有所改善,但是並不均衡。
均衡的一致性hash應該是如下圖:

均勻一致性hash的目標是如果伺服器有N台,客戶端的hash值有M個,那麼每個伺服器應該處理大概M/N個用戶的。也就是每台伺服器負載盡量均衡。dubbo提供的一致性hash負載均衡演算法就是不均勻的,我們自己實現了dubbo的spi擴展實現了均勻一致性hash.
七、總結
在分散式系統中一致性hash起著不可忽略的地位,無論是分散式快取,還是分散式Rpc框架的負載均衡策略都有所使用。


