金三銀四助力面試-手把手輕鬆讀懂HashMap源碼
前言
HashMap 對每一個學習 Java 的人來說熟悉的不能再熟悉了,然而就是這麼一個熟悉的東西,真正深入到源碼層面卻有許多值的學習和思考的地方,現在就讓我們一起來探索一下 HashMap 的源碼。
HashMap 源碼分析
HashMap 基於哈希表,且實現了 Map 介面的一種 key-value 鍵值對存儲數據結構,其中的 key 和 value 均允許 null 值,在 HashMap 中,不保證順序,執行緒也不安全。
HashMap 中的數據存儲
在 HashMap 中,每次 put 操作都會對 key 進行哈希運算,根據哈希運算的結果然後再經過位運算得到一個指定範圍內的下標,這個下標就是當前 key 值存放的位置,既然是哈希運算,那麼肯定就會有哈希衝突,對此在 jdk1.7 及其之前的版本,每個下標存放的是一個鏈表,而在 jdk1.8 版本及其之後的版本,則對此進行了優化,當鏈表長度大於 8 時,會轉化為紅黑樹存儲,當紅黑樹中元素從大於等於 8 降低為 小於等於 6 時,又會從紅黑樹重新退化為鏈表進行存儲。
下圖就是 jdk1.8 中一個 HashMap 的存儲結構示意圖(每一個下標的位置稱之為 桶):
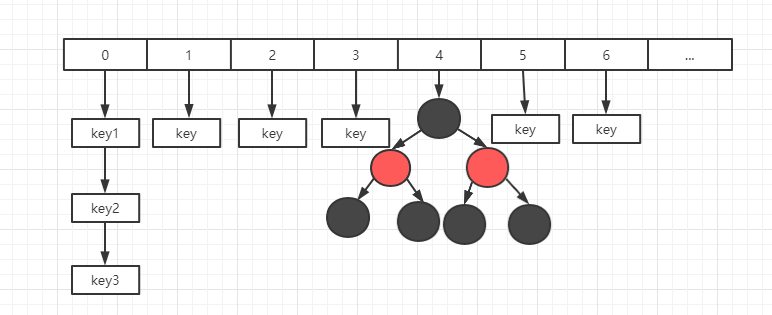
在 HashMap 中是通過數組 + 鏈表 + 紅黑樹來實現數據的存儲(jdk1.8),而在更早的版本中則僅僅採用了數組 + 鏈表的方式來進行存儲。
為什麼建議初始化 HashMap 時指定大小
HashMap 初始化的時候,我們通常都會建議預估一下可能大小,然後在構造 HashMap 對象的時候指定容量,這是為什麼呢?要回答這個問題就讓我們看一下 HashMap 是如何初始化的。
下圖就是當我們不指定任何參數時創建的 HashMap 對象:

負載因子
可以看到有一個默認的 DEFAULT_LOAD_FACTOR(負載因子),這個值默認是 0.75。負載因子的作用就是當 HashMap 中使用的容量達到總容量大小的 0.75 時,就會進行自動擴容。然後從上面的源碼可以看到,當我們不指定大小時,HashMap 並不會初始化一個容量,那麼我們就可以大膽的猜測當我們調用 put 方法時肯定會有判斷當前 HashMap 是否被初始化,如果沒有初始化,就會先進行初始化。
HashMap 默認容量
put 方法中會判斷當前 HashMap 是否被初始化,如果沒有被初始化,則會調用 resize 方法進行初始化,resize 方法不僅僅用於初始化,也用於擴容,其中初始化部分主要是下圖中紅框部分:
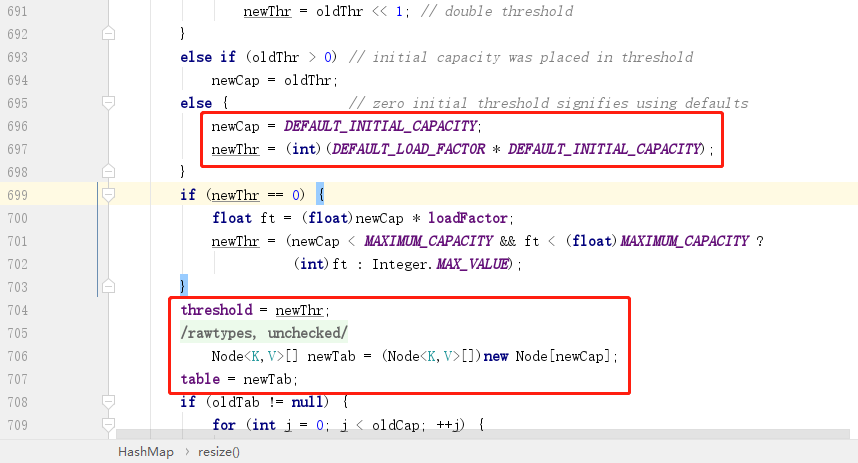
可以看到,初始化 HashMap 時,主要是初始化了 2 個變數:一個是 newCap,表示當前 HashMap 中有多少個桶,數組的一個下標表示一個桶;一個是 newThr,主要是用於表示擴容的閾值,因為任何時候我們都不可能等到桶全部用完了才去擴容,所以要設置一個閾值,達到閾值後就開始擴容,這個閾值就是總容量乘以負載因子得到。
上面我們知道了默認的負載因子是 0.75,而默認的桶大小是 16,所以也就是當我們初始化 HashMap 而不指定大小時,當桶使用了 12 時就會自動擴容(如何擴容我們在後面分析)。擴容就會涉及到舊數據遷移,比較消耗性能,所以在能預估出 HashMap 需要存儲的總元素時,我們建議是提前指定 HashMap 的容量大小,以避免擴容操作。
PS:需要注意的是,一般我們說 HashMap 中的容量都是指的有多少個桶,而每個桶能放多少個元素取決於記憶體,所以並不是說容量為 16 就只能存放 16 個 key 值。
HashMap 最大容量是多少
當我們手動指定容量初始化 HashMap 時,總是會調用下面的方法進行初始化:

看到 453 行,當我們指定的容量大於 MAXIMUM_CAPACITY 時,會被賦值為 MAXIMUM_CAPACITY,而這個 MAXIMUM_CAPACITY 又是多少呢?

上圖中我們看到,MAXIMUM_CAPACITY 是 2 的 30 次方,而 int 的範圍是 2 的 31 次方減 1,這豈不是把範圍給縮小了嗎?看上面的注釋可以知道,這裡要保證 HashMap 的容量是 2 的 N 次冪,而 int 類型的最大正數範圍是達不到 2 的 31 次冪的,所以就取了2 的 30 次冪。
我們再回到前面的帶有參數的構造器,最後調用了一個 tableSizeFor 方法,這個方法的作用就是調整 HashMap 的容量大小:

這個方法如果大家不了解位運算,可能就會看不太明白這個到底是做什麼操作,其實這個裡面就做了一件事,那就是把我們傳進來的指定容量大小調整為 2 的 N 次冪,所以在最開始要把我們傳進去的容量減 1,就是為了統一調整。
我們來舉一個簡單的例子來解釋一下上面的方法,位運算就涉及到二進位,所以假如我們傳進來的容量是一個 5,那麼轉化為二進位就是 0000 0000 0000 0000 0000 0000 0000 0101,這時候我們要保證這個數是 2 的 N 次冪,那麼最簡單的辦法就是把我們當前二進位數的最左邊的 1 開始,一直到最右邊,所有的位都是 1,那麼得到的結果就是得到對應的 2 的 N 次冪減 1,比如我們傳的 5 進來,要確保是 2 的 N 次冪,那麼肯定是需要調整為 2 的 3 次 冪,即:8,這時候我么需要做的就是把後面的 3 位 101 調整為 111 ,就可以得到 2 的 3 次冪減 1,最後的總容量再加上 1 就可以調整成為 2 的 N 次冪。
還是以 5 為例,無符號右移 1 位,得到 0000 0000 0000 0000 0000 0000 0000 0010,然後再與原值 0000 0000 0000 0000 0000 0000 0000 0101 執行 | 操作(只有兩邊同時為 0,結果才會為 0),就可以得到結果 0000 0000 0000 0000 0000 0000 0000 0111,也就是把第二位變成了 1,這時候不論再右移多少位,右移多少次,結果都不會變,保證了後三位為 1,而後面還要依次右移,是為了確保當一個數的第 31 位為 1 時,可以保證除了最高位之外的 31 位全部為 1 。
到這裡,大家應該就會有疑問了,為什麼要如此大費周章的來保證 HashMap 的容量,即桶的個數為 2 的 N 次冪呢?
為什麼 HashMap 容量大小要為 2 的 N 次冪
之所以要確保 HashMap 的容量為 2 的 N 次冪的原因其實很簡單,就是為了儘可能避免哈希分布不均勻而導致每個桶中分布的數據不均勻,從而出現某些桶中元素過多,影響到查詢效率。
我們繼續看一下 put 方法,下圖中紅框部分就是計算下標位置的演算法,就是通過當前數組(HashMap 底層是採用了一個 Node 數組來存儲元素)的長度 - 1 再和 hash 值進行 & 運算得到的:
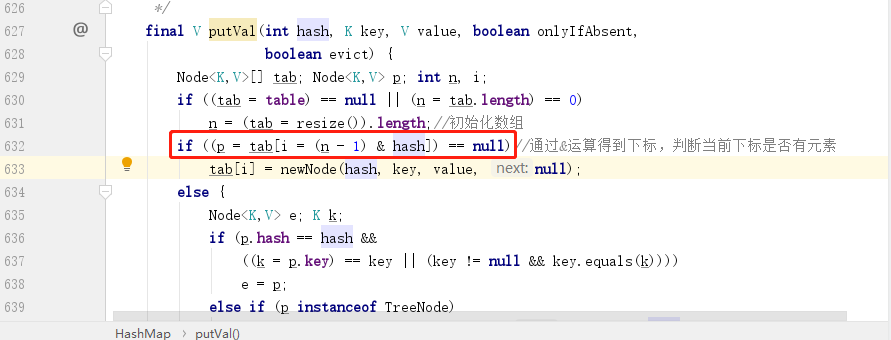
& 運算的特點就是只有兩個數都是 1 得到的結果才是 1,那麼假如 n-1 轉化為二進位中含有大量的 0,如 1000,那麼這時候再和 hash 值去進行 & 運算,最多只有 1 這個位置是有效的,其餘位置全部是 0,相當於無效,這時候發生哈希碰撞的概率會大大提升。而假如換成一個 1111 再和 hash 值進行 & 運算,那麼這四位都有效參與了運算,大大降低了發生哈希碰撞的概率,這就是為什麼最開始初始化的時候,會通過一系列的 | 運算來將其第一個 1 的位置之後所有元素全部修改為 1 的原因。
談談 HashMap 中的哈希運算
上面談到了計算一個 key 值最終落在哪個位置時用到了一個 hash 值,那麼這個 hash 值是如何得到的呢?
下圖就是 HashMap 中計算 hash 值的方法:

我們可以看到這個計算方法很特別,它並不僅僅只是簡單通過一個 hashCode 方法來得到,而是還同時將 hashCode 得到的結果無符號右移 16 位之後再進行異或運算,得到最終結果。
這麼做的目的就是為了將高 16 位也參與運算,進一步避免哈希碰撞的發生。因為在 HashMap 中容量總是 2 的 N 次冪,所以如果僅僅只有低 16 位參與運算,那麼有很大一部分情況其低 16 位都是 1,所以將高 16 位也參與運算可以一定程度避免哈希碰撞發生。而後面之所以會採用異或運算而不採用 & 和 | 的原因是如果採用 & 運算會使結果偏向 1,採用 | 運算會使結果偏向 0,^ 運算會使得結果能更好的保留原有特性。
put 元素流程
put 方法前面的流程上面已經提到,如果 HashMap 沒有初始化,則會進行初始化,然後再判斷當前 key 值的位置是否有元素,如果沒有元素,則直接存進去,如果有元素,則會走下面這個分支:

這個 else 分支主要有 4 個邏輯:
- 判斷當前
key和原有key是否相同,如果相同,直接返回。 - 如果當前
key和原有key不相等,則判斷當前桶存儲的元素是否是TreeNode節點,如果是則表示當前是紅黑樹,則按照紅黑樹演算法進行存儲。 - 如果當前
key和原有key不相等,且當前桶存放的是一個鏈表,則依次遍歷每個節點的next節點是否為空,為空則直接將當前元素放進鏈表,不為空則先判斷兩個key是否相等,相等則直接返回,不相等則繼續判斷next節點,直到key相等,或者next節點為空。 - 插入鏈表之後,如果當前鏈表長度大於
TREEIFY_THRESHOLD,默認是8,則會將鏈表進行切換到紅黑樹存儲。
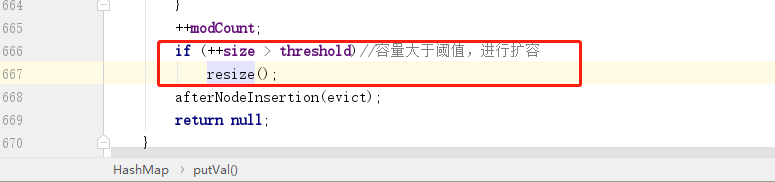
處理完之後,最後還有一個判斷就是判斷是否覆蓋舊元素,如果 e != null,則說明當前 key 值已經存在,則繼續判斷 onlyIfAbsent 變數,這個變數默認就是 false,表示覆蓋舊值,所以接下來會進行覆蓋操作,然後再把舊值返回。

擴容
當 HashMap 中存儲的數據量大於閾值(負載因子 * 當前桶數量)之後,會觸發擴容操作:
所以接下來讓我們看看 resize 方法:

第一個紅框就是判斷當前容量是否已經達到了 MAXIMUM_CAPACITY,這個值前面提到了是 2 的 30 次冪,如果達到了這個值,就會將擴容閾值修改為 int 類型存儲的最大值,也就是不會再出發擴容了。
第二個紅框就是擴容,擴容的大小就是將舊容量左移 1 位,也就是擴大為原來的 2 倍。當然,擴大之後的容量如果不滿足第二個紅框中的條件,則會在第三個紅框中被設置。
擴容之後原有數據怎麼處理
擴容很簡單,關鍵是原有的數據應該如何處理呢?不看程式碼,我們可以大致梳理出遷移數據的場景,沒有數據的場景不做考慮:
- 當前桶位置只有自己,也就是下面沒有其他元素。
- 當前桶位置下面有元素,且是鏈表結構。
- 當前桶位置下面有元素,且是紅黑樹。
接下來讓我們看看源碼中的 resize 方法中的數據遷移部分:
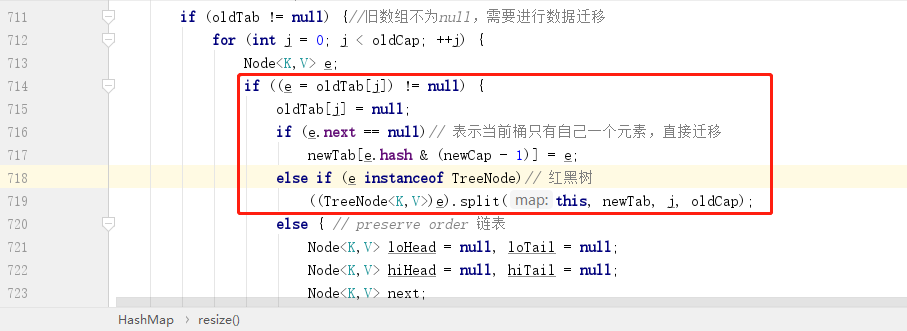
紅框部分比較好理解,首先就是看當前桶內元素是否是孤家寡人,如果是,直接重新計算下標然後賦值到新數據即可,如果是紅黑樹,則打散了重組,這部分暫且略過,最後一個 else 部分就是處理鏈表部分,接下來就讓我們重點看一下鏈表的處理。
鏈表數據處理
鏈表的處理有一個核心思想:鏈表中元素的下標要麼保持不變,要麼在原先的基礎上在加上一個 oldCap 大小。
鏈表的數據處理完整部分源碼如下圖所示:

關鍵條件就是 e.hash & oldCap,為什麼這個結果等於 0 就表示元素的位置沒有發生改變呢?
在解釋這個問題之前,需要先回憶一下 tableSizeFor 方法,這個方法會將 n-1 調整為類似 00001111 的數據結構,舉個例子:比如初始化容量為 16,長度 n-1 就是 01111,而 n 就是 10000,所以如果 e.hash & oldCap ==0 就說明 hash 值的第 5 位是 0,10000 擴容之後得到的就是 100000,對應的 n-1 就是 011111,和原先舊的 n-1 的差異之處就是第 5 位(第 6 位是 0 不影響計算結果),所以當 e.hash & oldCap==0 就說明第 5 位對結果也沒有影響,那麼就說明位置不會變,而如果 e.hash & oldCap !=0,就說明第 5 位數影響到了結果,而第 5 位如果計算結果為 1,則得到下標的位置恰好多出了一個 oldCap 的大小,即 16。其他位置擴容也是同樣的道理,所以只要 e.hash & oldCap==0,說明下標位置不變,而如果不等於 0,則下標位置應該再加上一個 oldCap。
最後的循環完節點之後,處理源碼如下所示:
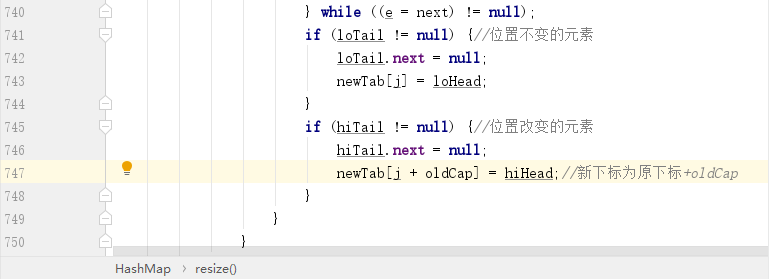
同理的 32 就是 100000,這就說明了一件事,那就是只需要關注最高位的 1 即可,因為只有這一位數和 e.hash 參與 & 運算時可能得到 1,
總結
本文主要分析了 HashMap 中是如何進行初始化,以及 put 方法是如何進行設置,同時也介紹了為了防止哈希衝突,將 HashMap 的容量設置為 2 的 N 次冪,最後介紹了 HashMap 中的擴容。

