阿里面試這樣問:redis 為什麼把簡單的字元串設計成 SDS?
2021開工第一天,就有小夥伴私信我,還給我分享了一道他面阿里的redis題(這傢伙絕比已經拿到年終獎了),我看了以後覺得挺有意思,題目很簡單,是那種典型的似懂非懂,常常容易被大家忽略的問題。這裡整理出來分享一下,順便自己鞏固一下基礎,希望對正在面試和想要面試的兄弟有點幫助。
題目大致是這樣的
面試官:了解redis的String數據結構底層實現嘛?
鐵子:當然知道,是基於SDS實現的
面試官:redis是用C語言開發的,那為啥不直接用C的字元串,還單獨設計SDS這樣的結構呢?
鐵子:·····

其實看得出面試官是想看看,鐵子是只停留在redis的使用層面,還是對底層數據結構有過更深入的研究,面試嘛都愛這樣問大家都懂得。
我們知道redis是用C寫的,但它卻沒有完全直接使用C的字元串,而是自己又重新構建了一個叫簡單動態字元串SDS(simple dynamic string)的抽象類型。
redis也支援使用C語言的傳統字元串,只不過會用在一些不需要對字元串修改的地方,比如靜態的字元輸出。
而我們開發中使用redis,往往會經常性的修改字元串的值,這個時候就會用SDS來表示字元串的值了。有一點值得注意:在redis資料庫中,key-value鍵值對含有字元串值的,都是由SDS來實現的。
比如:在redis執行一個最簡單的set命令,這時redis會新建一個鍵值對。
127.0.0.1:6379> set xiaofu "程式設計師內點事"
此時鍵值對的key和value都是一個字元串對象,而對象的底層實現分別是兩個保存著字元串xiaofu和程式設計師內點事的SDS結構。
再比如:我向一個列表中壓入數據,redis 又會新建一個鍵值對。
127.0.0.1:6379> lpush xiaofu "程式設計師內點事" "程式設計師小富"
這時候鍵值對的鍵和上邊一樣,還是一個由SDS實現的字元串對象,鍵值對的值是一個包含兩個字元串對象的列表對象了,而這兩個對象的底層也是由SDS實現。
SDS結構
一個SDS值的數據結構,主要由len、free、buf[]這三個屬性組成。
struct sdshdr{
int free; // buf[]數組未使用位元組的數量
int len; // buf[]數組所保存的字元串的長度
char buf[]; // 保存字元串的數組
}
其中buf[]為實際保存字元串的char類型數組;free表示buf[]數組未使用位元組的數量;len表示buf[]數組所保存的字元串的長度。
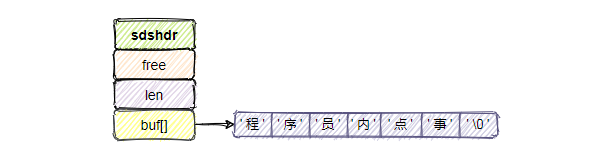
例如上圖表示的是buf[]保存長度為6個位元組的字元串,未使用的位元組數free為0,但是眼尖的同學會發現這明明是7個字元,還有一個"\0"啊?
上邊提到過SDS沒有完全直接使用C的字元串,還是沿用了一些C特性的,比如遵循C的字元串以空格符結尾的規則,這樣還可以使用一部分C字元串的函數。而對於SDS來說,空字元串佔用的一位元組是不計算在len屬性里的,會為他分配額外的空間。
簡單了解SDS結構後,下邊我們來看看SDS相比於C字元串有哪些優點。
效率高
舉個例子:工作中使用redis,經常會通過STRLEN命令得到一個字元串的長度,在SDS結構中len屬性記錄了字元串的長度,所以我們獲取一個字元串長度直接取len的值,複雜度是O(1)。
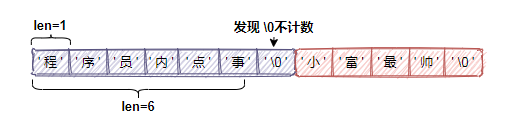
而如果用C字元串,在獲取一個字元串長度時,需對整個字元串進行遍歷,直至遍歷到空格符結束(C中遇到空格符代表一個完整字元串),此時的複雜度是O(N)。
在高並發場景下頻繁遍歷字元串,獲取字元串的長度很有可能成為redis的性能瓶頸,所以SDS性能更好一些。
數據溢出
上邊提到C字元串是不記錄自身長度的,相鄰的兩個字元串存儲的方式可能如下圖,為字元串分配了合適的記憶體空間。

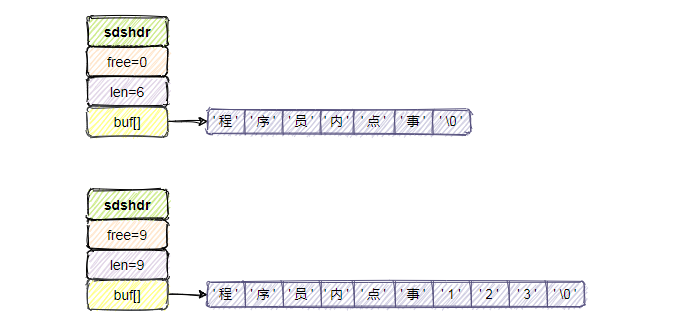
如果此時我想把「程式設計師內點事」改成「程式設計師內點事123」,可之前分配的記憶體只有6個位元組,修改後的字元串需要9個位元組才能放下啊,怎麼搞?

沒辦法只能侵佔相鄰字元串的空間,自身數據溢出導致其他字元串的內容被修改。
而SDS很好的規避了這點,當我們需要修改數據時,首先會檢查當前SDS空間len是否滿足,不滿足則自動擴容空間至修改所需的大小,然後再執行修改,如下圖所示。

不過有個特殊的地方,在把「程式設計師內點事」的6個位元組擴容到「程式設計師內點事123」9個位元組後,發現free屬性的值變成了擴容後字元串的總長度,這就涉及到下邊要說的記憶體重分配策略了。
記憶體重分配策略
C字元串長度是一定的,所以每次在增長或者縮短字元串時,都要做記憶體的重分配,而記憶體重分配演算法通常又是一個比較耗時的操作,如果程式不經常修改字元串還是可以接受的。
但很不幸,redis作為一個資料庫,數據肯定會被頻繁修改,如果每次修改都要執行一次記憶體重分配,那麼就會嚴重影響性能。
SDS通過兩種記憶體重分配策略,很好的解決了字元串在增長和縮短時的記憶體分配問題。
1.空間預分配
空間預分配策略用於優化SDS字元串增長操作,當修改字元串並需對SDS的空間進行擴展時,不僅會為SDS分配修改所必要的空間,還會為SDS分配額外的未使用空間free,下次再修改就先檢查未使用空間free是否滿足,滿足則不用在擴展空間。
通過空間預分配策略,redis可以有效的減少字元串連續增長操作,所產生的記憶體重分配次數。
額外分配未使用空間free的規則:
- 如果對 SDS 字元串修改後,
len值小於1M,那麼此時額外分配未使用空間free的大小與len相等。 - 如果對 SDS 字元串修改後,
len值大於等於1M,那麼此時額外分配未使用空間free的大小為1M。
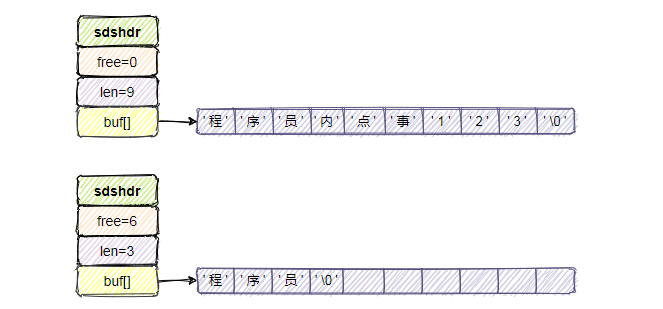
2.惰性空間釋放
惰性空間釋放策略則用於優化SDS字元串縮短操作,當縮短SDS字元串後,並不會立即執行記憶體重分配來回收多餘的空間,而是用free屬性將這些空間記錄下來,如果後續有增長操作,則可直接使用。
數據格式多樣性
C字元串中的字元必須符合某些特定的編碼格式,而且上邊我們也提到,C字元串以\0空字元結尾標識一個字元串結束,所以字元串裡邊是不能包含\0的,不然就會被誤認是多個。
由於這種限制,使得C字元串只能保存文本數據,像音影片、圖片等二進位格式的數據是無法存儲的。
redis 會以處理二進位的方式操作Buf數組中的數據,所以對存入其中的數據做任何的限制、過濾,只要存進來什麼樣,取出來還是什麼樣。
總結
上邊只是 redis 數據結構的一點基礎知識,沒什麼難度,但以我的面試經驗,如果被問這類問題,不要只含糊其辭的說出底層是SDS,有理有據的把為什麼這樣實現也說出來。
一來可以顯得自己基本功紮實,如果表達的在條理清晰,是個很不錯的加分項;在一個主動打消面試官問下去的念頭,當然就怕不按套路出牌的人!
整理了幾百本各類技術電子書,有需要的同學可以,在我同名公眾號回復[ 666 ]自取。技術群快滿了,想進的同學可以加我好友,和大佬們一起吹吹技術,期待你的加入。



