07 Scrapy框架在爬蟲中的詳細使用
- 2019 年 10 月 3 日
- 筆記
一.Scrapy框架簡介
何為框架,就相當於一個封裝了很多功能的結構體,它幫我們把主要的結構給搭建好了,我們只需往骨架里添加內容就行。scrapy框架是一個為了爬取網站數據,提取數據的框架,我們熟知爬蟲總共有四大部分,請求、響應、解析、存儲,scrapy框架都已經搭建好了。scrapy是基於twisted框架開發而來,twisted是一個流行的事件驅動的python網路框架,scrapy使用了一種非阻塞(又名非同步)的程式碼實現並發的,Scrapy之所以能實現非同步,得益於twisted框架。twisted有事件隊列,哪一個事件有活動,就會執行!Scrapy它集成高性能非同步下載,隊列,分散式,解析,持久化等。
1.五大核心組件
引擎(Scrapy)
框架核心,用來處理整個系統的數據流的流動, 觸發事務(判斷是何種數據流,然後再調用相應的方法)。也就是負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、數據傳遞等,所以被稱為框架的核心。
調度器(Scheduler)
用來接受引擎發過來的請求,並按照一定的方式進行整理排列,放到隊列中,當引擎需要時,交還給引擎。可以想像成一個URL(抓取網頁的網址或者說是鏈接)的優先隊列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址。
下載器(Downloader)
負責下載引擎發送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理。Scrapy下載器是建立在twisted這個高效的非同步模型上的。
爬蟲(Spiders)
用戶根據自己的需求,編寫程式,用於從特定的網頁中提取自己需要的資訊,即所謂的實體(Item)。用戶也可以從中提取出鏈接,讓Scrapy繼續抓取下一個頁面。跟進的URL提交給引擎,再次進入Scheduler(調度器)。
項目管道(Pipeline)
負責處理爬蟲提取出來的item,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。
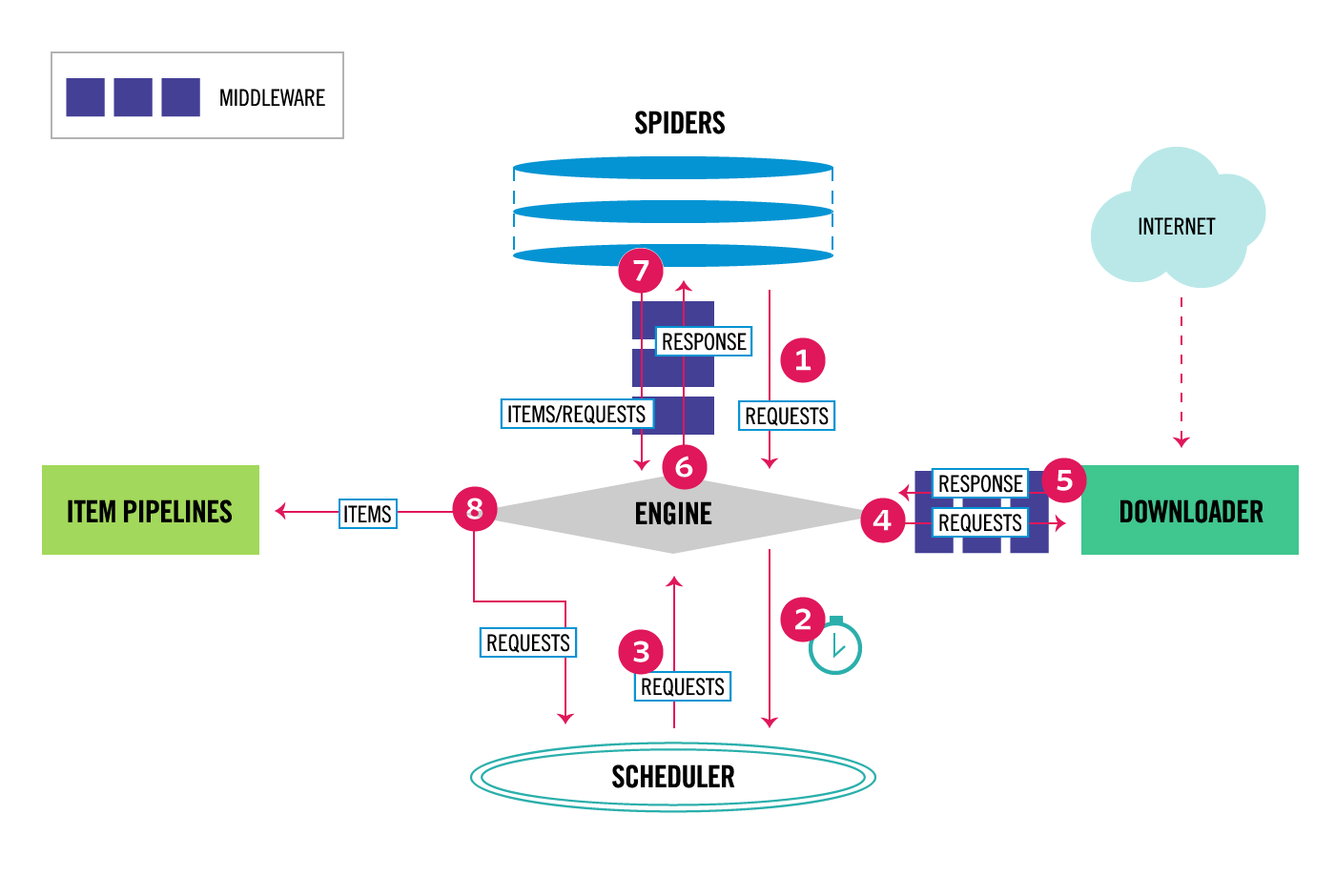
2.工作流程
Scrapy中的數據流由引擎控制,其過程如下:
(1)用戶編寫爬蟲主程式將需要下載的頁面請求requests遞交給引擎,引擎將請求轉發給調度器;
(2)調度實現了優先順序、去重等策略,調度從隊列中取出一個請求,交給引擎轉發給下載器(引擎和下載器中間有中間件,作用是對請求加工如:對requests添加代理、ua、cookie,response進行過濾等);
(3)下載器下載頁面,將生成的響應通過下載器中間件發送到引擎;
(4) 爬蟲主程式進行解析,這個時候解析函數將產生兩類數據,一種是items、一種是鏈接(URL),其中requests按上面步驟交給調度器;items交給數據管道(數據管道實現數據的最終處理);
官方文檔
英文版:https://docs.scrapy.org/en/latest/
http://doc.scrapy.org/en/master/
中文版:https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://www.osgeo.cn/scrapy/topics/architecture.html
二、安裝及常用命令介紹
1. 安裝
Linux:pip3 install scrapy
Windows:
a. pip3 install wheel
b. 下載twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. shift右擊進入下載目錄,執行 pip3 install typed_ast-1.4.0-cp36-cp36m-win32.whl
d. pip3 install pywin32
e. pip3 install scrapy
2.scrapy基本命令行
(1)創建一個新的項目 scrapy startproject ProjectName (2)生成爬蟲 scrapy genspider +SpiderName+website (3)運行(crawl) # -o output scrapy crawl +SpiderName scrapy crawl SpiderName -o file.json scrapy crawl SpiderName-o file.csv (4)check檢查錯誤 scrapy check (5)list返回項目所有spider名稱 scrapy list (6)view 存儲、打開網頁 scrapy view https://www.baidu.com (7)scrapy shell,進入終端 scrapy shell https://www.baidu.com (8)scrapy runspider scrapy runspider zufang_spider.py
三、簡單實例
以麥田租房資訊爬取為例,網站http://bj.maitian.cn/zfall/PG1
1.創建項目
scrapy startproject houseinfo
生成項目結構:
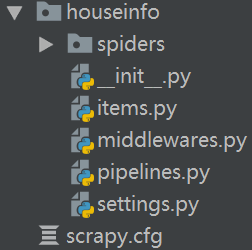
scrapy.cfg 項目的主配置資訊。(真正爬蟲相關的配置資訊在settings.py文件中)
items.py 設置數據存儲模板,用於結構化數據,如:Django的Model
pipelines 數據持久化處理
settings.py 配置文件
spiders 爬蟲目錄
2.創建爬蟲應用程式
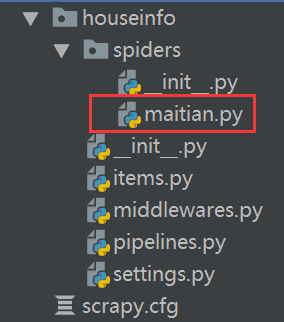
cd houseinfo scrapy genspider maitian maitian.com
然後就可以在spiders目錄下看到我們的爬蟲主程式
3.編寫爬蟲文件
步驟2執行完畢後,會在項目的spiders中生成一個應用名的py爬蟲文件,文件源碼如下:
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class MaitianSpider(scrapy.Spider): 6 name = 'maitian' # 應用名稱 7 allowed_domains = ['maitian.com'] #一般注釋掉,允許爬取的域名(如果遇到非該域名的url則爬取不到數據) 8 start_urls = ['http://maitian.com/'] #起始爬取的url列表,該列表中存在的url,都會被parse進行請求的發送 9 10 #解析函數 11 def parse(self, response): 12 pass
我們可以在此基礎上,根據需求進行編寫
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 class MaitianSpider(scrapy.Spider): 5 name = 'maitian' 6 start_urls = ['http://bj.maitian.cn/zfall/PG100'] 7 8 9 #解析函數 10 def parse(self, response): 11 12 li_list = response.xpath('//div[@class="list_wrap"]/ul/li') 13 results = [] 14 for li in li_list: 15 title = li.xpath('./div[2]/h1/a/text()').extract_first().strip() 16 price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip() 17 square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡','') # 將面積的單位去掉 18 area = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[0] # 以空格分隔 19 adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[2] 20 21 dict = { 22 "標題":title, 23 "月租金":price, 24 "面積":square, 25 "區域":area, 26 "地址":adress 27 } 28 results.append(dict) 29 30 print(title,price,square,area,adress) 31 return results
須知:
- xpath為scrapy中的解析方式
- xpath函數返回的為列表,列表中存放的數據為Selector類型數據。解析到的內容被封裝在Selector對象中,需要調用extract()函數將解析的內容從Selector中取出。
- 如果可以保證xpath返回的列表中只有一個列表元素,則可以使用extract_first(), 否則必須使用extract()
兩者等同,都是將列表中的內容提取出來
title = li.xpath(‘./div[2]/h1/a/text()’).extract_first().strip()
title = li.xpath(‘./div[2]/h1/a/text()’)[0].extract().strip()
4. 設置修改settings.py配置文件相關配置:
1 #偽裝請求載體身份 2 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 3 4 #可以忽略或者不遵守robots協議 5 ROBOTSTXT_OBEY = False
5.執行爬蟲程式:scrapy crawl maitain

爬取全站數據,也就是全部頁碼數據。本例中,總共100頁,觀察頁面之間的共性,構造通用url
方式一:通過佔位符,構造通用url
1 import scrapy 2 3 class MaitianSpider(scrapy.Spider): 4 name = 'maitian' 5 start_urls = ['http://bj.maitian.cn/zfall/PG{}'.format(page) for page in range(1,4)] #注意寫法 6 7 8 #解析函數 9 def parse(self, response): 10 11 li_list = response.xpath('//div[@class="list_wrap"]/ul/li') 12 results = [] 13 for li in li_list: 14 title = li.xpath('./div[2]/h1/a/text()').extract_first().strip() 15 price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip() 16 square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡','') 17 # 也可以通過正則匹配提取出來 18 area = li.xpath('./div[2]/p[2]/span/text()[2]')..re(r'昌平|朝陽|東城|大興|丰台|海淀|石景山|順義|通州|西城')[0] 19 adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[2] 20 21 dict = { 22 "標題":title, 23 "月租金":price, 24 "面積":square, 25 "區域":area, 26 "地址":adress 27 } 28 results.append(dict) 29 30 return results
如果碰到一個表達式不能包含所有情況的項目,解決方式是先分別寫表達式,最後通過列表相加,將所有url合併成一個url列表,例如
start_urls = ['http://www.guokr.com/ask/hottest/?page={}'.format(n) for n in range(1, 8)] + [ 'http://www.guokr.com/ask/highlight/?page={}'.format(m) for m in range(1, 101)]
方式二:通過重寫start_requests方法,獲取所有的起始url。(不用寫start_urls)
1 import scrapy 2 3 class MaitianSpider(scrapy.Spider): 4 name = 'maitian' 5 6 def start_requests(self): 7 pages=[] 8 for page in range(90,100): 9 url='http://bj.maitian.cn/zfall/PG{}'.format(page) 10 page=scrapy.Request(url) 11 pages.append(page) 12 return pages 13 14 #解析函數 15 def parse(self, response): 16 17 li_list = response.xpath('//div[@class="list_wrap"]/ul/li') 18 19 results = [] 20 for li in li_list: 21 title = li.xpath('./div[2]/h1/a/text()').extract_first().strip(), 22 price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip(), 23 square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡',''), 24 area = li.xpath('./div[2]/p[2]/span/text()[2]').re(r'昌平|朝陽|東城|大興|丰台|海淀|石景山|順義|通州|西城')[0], 25 adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[2] 26 27 dict = { 28 "標題":title, 29 "月租金":price, 30 "面積":square, 31 "區域":area, 32 "地址":adress 33 } 34 results.append(dict) 35 36 return results
四、數據持久化存儲
- 基於終端指令的持久化存儲
- 基於管道的持久化存儲
只要是數據持久化存儲,parse方法必須有返回值,也就是return後的內容
1. 基於終端指令的持久化存儲
執行輸出指定格式進行存儲:將爬取到的數據寫入不同格式的文件中進行存儲,windows終端不能使用txt格式
- scrapy crawl 爬蟲名稱 -o xxx.json
- scrapy crawl 爬蟲名稱 -o xxx.xml
- scrapy crawl 爬蟲名稱 -o xxx.csv
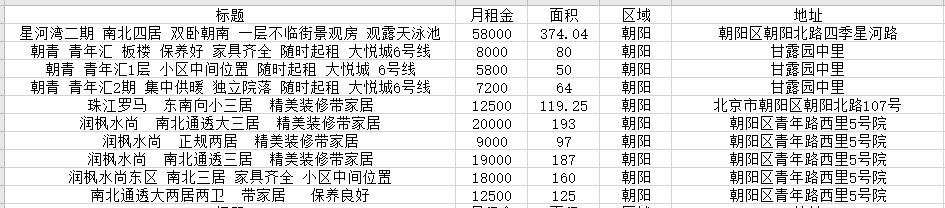
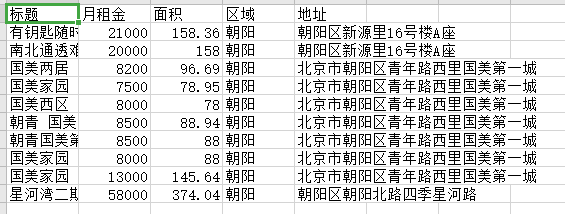
以麥田為例,spider中的程式碼不變,將返回值寫到qiubai.csv中。本地沒有,就會自己創建一個。本地有就會追加
scrapy crawl maitian -o maitian.csv
就會在項目目錄下看到,生成的文件
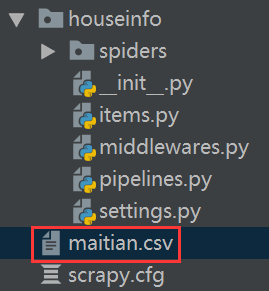
查看文件內容
2.基於管道的持久化存儲
scrapy框架中已經為我們專門集成好了高效、便捷的持久化操作功能,我們直接使用即可。要想使用scrapy的持久化操作功能,我們首先來認識如下兩個文件:
- items.py:數據結構模板文件。定義數據屬性。
- pipelines.py:管道文件。接收數據(items),進行持久化操作。
持久化流程:
① 爬蟲文件爬取到數據解析後,需要將數據封裝到items對象中。
② 使用yield關鍵字將items對象提交給pipelines管道,進行持久化操作。
③ 在管道文件中的process_item方法中接收爬蟲文件提交過來的item對象,然後編寫持久化存儲的程式碼,將item對象中存儲的數據進行持久化存儲(在管道的process_item方法中執行io操作,進行持久化存儲)
④ settings.py配置文件中開啟管道
2.1保存到本地的持久化存儲
爬蟲文件:maitian.py
1 import scrapy 2 from houseinfo.items import HouseinfoItem # 將item導入 3 4 class MaitianSpider(scrapy.Spider): 5 name = 'maitian' 6 start_urls = ['http://bj.maitian.cn/zfall/PG100'] 7 8 #解析函數 9 def parse(self, response): 10 11 li_list = response.xpath('//div[@class="list_wrap"]/ul/li') 12 13 for li in li_list: 14 item = HouseinfoItem( 15 title = li.xpath('./div[2]/h1/a/text()').extract_first().strip(), 16 price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip(), 17 square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡',''), 18 area = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[0], 19 adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[2] 20 ) 21 22 yield item # 提交給管道,然後管道定義存儲方式
items文件:items.py
1 import scrapy 2 3 class HouseinfoItem(scrapy.Item): 4 title = scrapy.Field() #存儲標題,裡面可以存儲任意類型的數據 5 price = scrapy.Field() 6 square = scrapy.Field() 7 area = scrapy.Field() 8 adress = scrapy.Field()
管道文件:pipelines.py
1 class HouseinfoPipeline(object): 2 def __init__(self): 3 self.file = None 4 5 #開始爬蟲時,執行一次 6 def open_spider(self,spider): 7 self.file = open('maitian.csv','a',encoding='utf-8') # 選用了追加模式 8 self.file.write(",".join(["標題","月租金","面積","區域","地址","n"])) 9 print("開始爬蟲") 10 11 # 因為該方法會被執行調用多次,所以文件的開啟和關閉操作寫在了另外兩個只會各自執行一次的方法中。 12 def process_item(self, item, spider): 13 content = [item["title"], item["price"], item["square"], item["area"], item["adress"], "n"] 14 self.file.write(",".join(content)) 15 return item 16 17 # 結束爬蟲時,執行一次 18 def close_spider(self,spider): 19 self.file.close() 20 print("結束爬蟲")
配置文件:settings.py
1 #偽裝請求載體身份 2 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 3 4 #可以忽略或者不遵守robots協議 5 ROBOTSTXT_OBEY = False 6 7 #開啟管道 8 ITEM_PIPELINES = { 9 'houseinfo.pipelines.HouseinfoPipeline': 300, #數值300表示為優先順序,值越小優先順序越高 10 }
五、爬取多級頁面
爬取多級頁面,會遇到2個問題:
問題1:如何對下一層級頁面發送請求?
答:在每一個解析函數的末尾,通過Request方法對下一層級的頁面手動發起請求
# 先提取二級頁面url,再對二級頁面發送請求。多級頁面以此類推 def parse(self, response): next_url = response.xpath('//div[2]/h2/a/@href').extract()[0] # 提取二級頁面url yield scrapy.Request(url=next_url, callback=self.next_parse) # 對二級頁面發送請求,注意要用yield,回調函數不帶括弧
問題2:解析的數據不在同一張頁面中,最終如何將數據傳遞
答:涉及到請求傳參,可以在對下一層級頁面發送請求的時候,通過meta參數進行數據傳遞,meta字典就會傳遞給回調函數的response參數。下一級的解析函數通過response獲取item. 先通過 response.meta返回接收到的meta字典,再獲得item字典
# 通過meta參數進行Request的數據傳遞,meta字典就會傳遞給回調函數的response參數 def parse(self, response): item = Item() # 實例化item對象 Item["field1"] = response.xpath('expression1').extract()[0] # 列表中只有一個元素 Item["field2"] = response.xpath('expression2').extract() # 列表 next_url = response.xpath('expression3').extract()[0] # 提取二級頁面url # meta參數:請求傳參.通過meta參數進行Request的數據傳遞,meta字典就會傳遞給回調函數的response參數 yield scrapy.Request(url=next_url, callback=self.next_parse,meta={'item':item}) # 對二級頁面發送請求 def next_parse(self,response): # 通過response獲取item. 先通過 response.meta返回接收到的meta字典,再獲得item字典 item = response.meta['item'] item['field'] = response.xpath('expression').extract_first() yield item #提交給管道
案例1:麥田,對所有頁碼發送請求。不推薦將每一個頁碼對應的url存放到爬蟲文件的起始url列表(start_urls)中。這裡我們使用Request方法手動發起請求。
# -*- coding: utf-8 -*- import scrapy from houseinfo.items import HouseinfoItem # 將item導入 class MaitianSpider(scrapy.Spider): name = 'maitian' start_urls = ['http://bj.maitian.cn/zfall/PG{}'.format(page) for page in range(1,4)] #爬取多頁 page = 1 url = 'http://bj.maitian.cn/zfall/PG%d' #解析函數 def parse(self, response): li_list = response.xpath('//div[@class="list_wrap"]/ul/li') for li in li_list: item = HouseinfoItem( title = li.xpath('./div[2]/h1/a/text()').extract_first().strip(), price = li.xpath('./div[2]/div/ol/strong/span/text()').extract_first().strip(), square = li.xpath('./div[2]/p[1]/span[1]/text()').extract_first().replace('㎡',''), area = li.xpath('./div[2]/p[2]/span/text()[2]').re(r'昌平|朝陽|東城|大興|丰台|海淀|石景山|順義|通州|西城')[0], # 也可以通過正則匹配提取出來 adress = li.xpath('./div[2]/p[2]/span/text()[2]').extract_first().strip().split('xa0')[2] ) ['http://bj.maitian.cn/zfall/PG{}'.format(page) for page in range(1, 4)] yield item # 提交給管道,然後管道定義存儲方式 if self.page < 4: self.page += 1 new_url = format(self.url%self.page) # 這裡的%是拼接的意思 yield scrapy.Request(url=new_url,callback=self.parse) # 手動發起一個請求,注意一定要寫yield
案例2:這個案例比較好的一點是,parse函數,既有對下一頁的回調,又有對詳情頁的回調
import scrapy class QuotesSpider(scrapy.Spider): name = 'quotes_2_3' start_urls = [ 'http://quotes.toscrape.com', ] allowed_domains = [ 'toscrape.com', ] def parse(self,response): for quote in response.css('div.quote'): yield{ 'quote': quote.css('span.text::text').extract_first(), 'author': quote.css('small.author::text').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), } author_page = response.css('small.author+a::attr(href)').extract_first() authro_full_url = response.urljoin(author_page) yield scrapy.Request(authro_full_url, callback=self.parse_author) # 對詳情頁發送請求,回調詳情頁的解析函數 next_page = response.css('li.next a::attr("href")').extract_first() # 通過css選擇器定位到下一頁 if next_page is not None: next_full_url = response.urljoin(next_page) yield scrapy.Request(next_full_url, callback=self.parse) # 對下一頁發送請求,回調自己的解析函數 def parse_author(self,response): yield{ 'author': response.css('.author-title::text').extract_first(), 'author_born_date': response.css('.author-born-date::text').extract_first(), 'author_born_location': response.css('.author-born-location::text').extract_first(), 'authro_description': response.css('.author-born-location::text').extract_first(),
案例3:爬取www.id97.com電影網,將一級頁面中的電影名稱,類型,評分,二級頁面中的上映時間,導演,片長進行爬取。(多級頁面+傳參)
# -*- coding: utf-8 -*- import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' allowed_domains = ['www.id97.com'] start_urls = ['http://www.id97.com/'] def parse(self, response): div_list = response.xpath('//div[@class="col-xs-1-5 movie-item"]') for div in div_list: item = MovieproItem() item['name'] = div.xpath('.//h1/a/text()').extract_first() item['score'] = div.xpath('.//h1/em/text()').extract_first() item['kind'] = div.xpath('.//div[@class="otherinfo"]').xpath('string(.)').extract_first() item['detail_url'] = div.xpath('./div/a/@href').extract_first() #meta參數:請求傳參.通過meta參數進行Request的數據傳遞,meta字典就會傳遞給回調函數的response參數 yield scrapy.Request(url=item['detail_url'],callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response): #通過response獲取item. 先通過 response.meta返回接收到的meta字典,再獲得item字典 item = response.meta['item'] item['actor'] = response.xpath('//div[@class="row"]//table/tr[1]/a/text()').extract_first() item['time'] = response.xpath('//div[@class="row"]//table/tr[7]/td[2]/text()').extract_first() item['long'] = response.xpath('//div[@class="row"]//table/tr[8]/td[2]/text()').extract_first() yield item #提交item到管道
案例4:稍複雜,可參考鏈接進行理解:https://github.com/makcyun/web_scraping_with_python/tree/master/,https://www.cnblogs.com/sanduzxcvbnm/p/10277414.html


1 #!/user/bin/env python 2 3 """ 4 爬取豌豆莢網站所有分類下的全部 app 5 數據爬取包括兩個部分: 6 一:數據指標 7 1 爬取首頁 8 2 爬取第2頁開始的 ajax 頁 9 二:圖標 10 使用class方法下載首頁和 ajax 頁 11 分頁循環兩種爬取思路, 12 指定頁數進行for 循環,和不指定頁數一直往下爬直到爬不到內容為止 13 1 for 循環 14 """ 15 16 import scrapy 17 from wandoujia.items import WandoujiaItem 18 19 import requests 20 from pyquery import PyQuery as pq 21 import re 22 import csv 23 import pandas as pd 24 import numpy as np 25 import time 26 import pymongo 27 import json 28 import os 29 from urllib.parse import urlencode 30 import random 31 import logging 32 33 logging.basicConfig(filename='wandoujia.log',filemode='w',level=logging.DEBUG,format='%(asctime)s %(message)s',datefmt='%Y/%m/%d %I:%M:%S %p') 34 # https://juejin.im/post/5aee70105188256712786b7f 35 logging.warning("warn message") 36 logging.error("error message") 37 38 39 class WandouSpider(scrapy.Spider): 40 name = 'wandou' 41 allowed_domains = ['www.wandoujia.com'] 42 start_urls = ['http://www.wandoujia.com/'] 43 44 def __init__(self): 45 self.cate_url = 'https://www.wandoujia.com/category/app' 46 # 首頁url 47 self.url = 'https://www.wandoujia.com/category/' 48 # ajax 請求url 49 self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more?' 50 # 實例化分類標籤 51 self.wandou_category = Get_category() 52 53 def start_requests(self): 54 yield scrapy.Request(self.cate_url,callback=self.get_category) 55 56 def get_category(self,response): 57 # # num = 0 58 cate_content = self.wandou_category.parse_category(response) 59 for item in cate_content: 60 child_cate = item['child_cate_codes'] 61 for cate in child_cate: 62 cate_code = item['cate_code'] 63 cate_name = item['cate_name'] 64 child_cate_code = cate['child_cate_code'] 65 child_cate_name = cate['child_cate_name'] 66 67 68 # # 單類別下載 69 # cate_code = 5029 70 # child_cate_code = 837 71 # cate_name = '通訊社交' 72 # child_cate_name = '收音機' 73 74 # while循環 75 page = 1 # 設置爬取起始頁數 76 print('*' * 50) 77 78 # # for 循環下一頁 79 # pages = [] 80 # for page in range(1,3): 81 # print('正在爬取:%s-%s 第 %s 頁 ' % 82 # (cate_name, child_cate_name, page)) 83 logging.debug('正在爬取:%s-%s 第 %s 頁 ' % 84 (cate_name, child_cate_name, page)) 85 86 if page == 1: 87 # 構造首頁url 88 category_url = '{}{}_{}' .format(self.url, cate_code, child_cate_code) 89 else: 90 params = { 91 'catId': cate_code, # 大類別 92 'subCatId': child_cate_code, # 小類別 93 'page': page, 94 } 95 category_url = self.ajax_url + urlencode(params) 96 97 dict = {'page':page,'cate_name':cate_name,'cate_code':cate_code,'child_cate_name':child_cate_name,'child_cate_code':child_cate_code} 98 99 yield scrapy.Request(category_url,callback=self.parse,meta=dict) 100 101 # # for 循環方法 102 # pa = yield scrapy.Request(category_url,callback=self.parse,meta=dict) 103 # pages.append(pa) 104 # return pages 105 106 def parse(self, response): 107 if len(response.body) >= 100: # 判斷該頁是否爬完,數值定為100是因為無內容時長度是87 108 page = response.meta['page'] 109 cate_name = response.meta['cate_name'] 110 cate_code = response.meta['cate_code'] 111 child_cate_name = response.meta['child_cate_name'] 112 child_cate_code = response.meta['child_cate_code'] 113 114 if page == 1: 115 contents = response 116 else: 117 jsonresponse = json.loads(response.body_as_unicode()) 118 contents = jsonresponse['data']['content'] 119 # response 是json,json內容是html,html 為文本不能直接使用.css 提取,要先轉換 120 contents = scrapy.Selector(text=contents, type="html") 121 122 contents = contents.css('.card') 123 for content in contents: 124 # num += 1 125 item = WandoujiaItem() 126 item['cate_name'] = cate_name 127 item['child_cate_name'] = child_cate_name 128 item['app_name'] = self.clean_name(content.css('.name::text').extract_first()) 129 item['install'] = content.css('.install-count::text').extract_first() 130 item['volume'] = content.css('.meta span:last-child::text').extract_first() 131 item['comment'] = content.css('.comment::text').extract_first().strip() 132 item['icon_url'] = self.get_icon_url(content.css('.icon-wrap a img'),page) 133 yield item 134 135 # 遞歸爬下一頁 136 page += 1 137 params = { 138 'catId': cate_code, # 大類別 139 'subCatId': child_cate_code, # 小類別 140 'page': page, 141 } 142 ajax_url = self.ajax_url + urlencode(params) 143 144 dict = {'page':page,'cate_name':cate_name,'cate_code':cate_code,'child_cate_name':child_cate_name,'child_cate_code':child_cate_code} 145 yield scrapy.Request(ajax_url,callback=self.parse,meta=dict) 146 147 148 149 # 名稱清除方法1 去除不能用於文件命名的特殊字元 150 def clean_name(self, name): 151 rule = re.compile(r"[/\:*?"<>|]") # '/ : * ? " < > |') 152 name = re.sub(rule, '', name) 153 return name 154 155 def get_icon_url(self,item,page): 156 if page == 1: 157 if item.css('::attr("src")').extract_first().startswith('https'): 158 url = item.css('::attr("src")').extract_first() 159 else: 160 url = item.css('::attr("data-original")').extract_first() 161 # ajax頁url提取 162 else: 163 url = item.css('::attr("data-original")').extract_first() 164 165 # if url: # 不要在這裡添加url存在判斷,否則空url 被過濾掉 導致編號對不上 166 return url 167 168 169 # 首先獲取主分類和子分類的數值程式碼 # # # # # # # # # # # # # # # # 170 class Get_category(): 171 def parse_category(self, response): 172 category = response.css('.parent-cate') 173 data = [{ 174 'cate_name': item.css('.cate-link::text').extract_first(), 175 'cate_code': self.get_category_code(item), 176 'child_cate_codes': self.get_child_category(item), 177 } for item in category] 178 return data 179 180 # 獲取所有主分類標籤數值程式碼 181 def get_category_code(self, item): 182 cate_url = item.css('.cate-link::attr("href")').extract_first() 183 184 pattern = re.compile(r'.*/(d+)') # 提取主類標籤程式碼 185 cate_code = re.search(pattern, cate_url) 186 return cate_code.group(1) 187 188 # 獲取所有子分類標籤數值程式碼 189 def get_child_category(self, item): 190 child_cate = item.css('.child-cate a') 191 child_cate_url = [{ 192 'child_cate_name': child.css('::text').extract_first(), 193 'child_cate_code': self.get_child_category_code(child) 194 } for child in child_cate] 195 196 return child_cate_url 197 198 # 正則提取子分類 199 def get_child_category_code(self, child): 200 child_cate_url = child.css('::attr("href")').extract_first() 201 pattern = re.compile(r'.*_(d+)') # 提取小類標籤編號 202 child_cate_code = re.search(pattern, child_cate_url) 203 return child_cate_code.group(1) 204 205 # # 可以選擇保存到txt 文件 206 # def write_category(self,category): 207 # with open('category.txt','a',encoding='utf_8_sig',newline='') as f: 208 # w = csv.writer(f) 209 # w.writerow(category.values())
View Code
以上4個案例都只貼出了爬蟲主程式腳本,因篇幅原因,所以item、pipeline和settings等腳本未貼出,可參考上面案例進行編寫。
六、Scrapy發送post請求
問題:在之前程式碼中,我們從來沒有手動的對start_urls列表中存儲的起始url進行過請求的發送,但是起始url的確是進行了請求的發送,那這是如何實現的呢?
解答:其實是因為爬蟲文件中的爬蟲類繼承到了Spider父類中的start_requests(self)這個方法,該方法就可以對start_urls列表中的url發起請求:
def start_requests(self): for u in self.start_urls: yield scrapy.Request(url=u,callback=self.parse)
注意:該方法默認的實現,是對起始的url發起get請求,如果想發起post請求,則需要子類重寫該方法。不過,一般情況下不用scrapy發post請求,用request模組。
例:爬取百度翻譯
# -*- coding: utf-8 -*- import scrapy class PostSpider(scrapy.Spider): name = 'post' # allowed_domains = ['www.xxx.com'] start_urls = ['https://fanyi.baidu.com/sug'] def start_requests(self): data = { # post請求參數 'kw':'dog' } for url in self.start_urls: yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse) # 發送post請求 def parse(self, response): print(response.text)
七、設置日誌等級
- 在使用scrapy crawl spiderFileName運行程式時,在終端里列印輸出的就是scrapy的日誌資訊。
- 日誌資訊的種類:
ERROR : 一般錯誤
WARNING : 警告
INFO : 一般的資訊
DEBUG : 調試資訊
- 設置日誌資訊指定輸出:
在settings.py配置文件中,加入
LOG_LEVEL = ‘指定日誌資訊種類’即可。
LOG_FILE = ‘log.txt’則表示將日誌資訊寫入到指定文件中進行存儲。
八、同時運行多個爬蟲
實際開發中,通常在同一個項目里會有多個爬蟲,多個爬蟲的時候是怎麼將他們運行起來呢?
運行單個爬蟲
import sys from scrapy.cmdline import execute if __name__ == '__main__': execute(["scrapy","crawl","maitian","--nolog"])
然後運行py文件即可運行名為‘maitian‘的爬蟲
同時運行多個爬蟲
步驟如下:
- 在spiders同級創建任意目錄,如:commands
- 在其中創建 crawlall.py 文件 (此處文件名就是自定義的命令)
- 在settings.py 中添加配置 COMMANDS_MODULE = '項目名稱.目錄名稱'
- 在項目目錄執行命令:scrapy crawlall
crawlall.py程式碼
1 from scrapy.commands import ScrapyCommand 2 from scrapy.utils.project import get_project_settings 3 4 class Command(ScrapyCommand): 5 6 requires_project = True 7 8 def syntax(self): 9 return '[options]' 10 11 def short_desc(self): 12 return 'Runs all of the spiders' 13 14 def run(self, args, opts): 15 spider_list = self.crawler_process.spiders.list() 16 for name in spider_list: 17 self.crawler_process.crawl(name, **opts.__dict__) 18 self.crawler_process.start()
