C語言之數據在記憶體中的存儲
C語言之數據在記憶體中的存儲
在我們學習此之前,我們先來回憶一下C語言中都有哪些數據類型呢?
首先我們來看看C語言中的基本的內置類型:
char //字元數據類型 short //短整型 int //整形 long //長整型 long long //更長的整形 float //單精度浮點數 double //雙精度浮點數
在這,值得一提的是C語言的基本類型中並沒有字元串類型,而字元串的實現一般都是通過數組來實現
C語言的數據類型我們可以基本分為5種類型
1.整型家族
char //字元形其實也屬於整形,因為在字元的儲存是存的是它的ASCII碼值 unsigned char signed char
short unsigned short [int] signed short [int]
int unsigned int signed int
long unsigned long [int] signed long [int]
2.浮點型家族
float double
3.構造類型
> 數組類型 > 結構體類型 struct > 枚舉類型 enum > 聯合類型 union
4.指針類型
int *pi;
char *pc;
float* pf;
void* pv;
5.空類型
void 表示空類型(無類型) 通常應用於函數的返回類型、函數的參數、指針類型。
在複習了一遍數據類型之後,我們現在來談談數據到底是怎麼存儲的
一.整形在記憶體中的存儲
首先我們來看看整形
比如,下面再平常不過的式子
int a = 10; int b = -20;
先不管其他的,我們先來看看它在記憶體里是怎麼放的
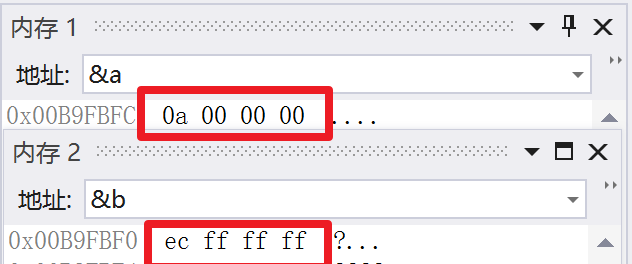
我們得到了一串數字,而這些數字代表這什麼呢?
原來是一串16進位的數字啊
我們知道一個整形系統分配四個位元組來儲存
而一個位元組又有8個比特位,所以就會有32個二進位的0或1.我們把上面兩串16進位的數字轉為2進位來看一看有什麼不同。
00001010000000000000000000000000 11101100111111111111111111111111
在這我們來看看10的二進位
00000000000000000000000000001010
有什麼不同呢?
在這我們來介紹一下原碼,反碼,補碼
電腦中的有符號數有三種表示方法,即原碼、反碼和補碼。
三種表示方法均有符號位和數值位兩部分,符號位都是用0表示「正」,用1表示「負」,而數值位 三種表示方法各不相同。
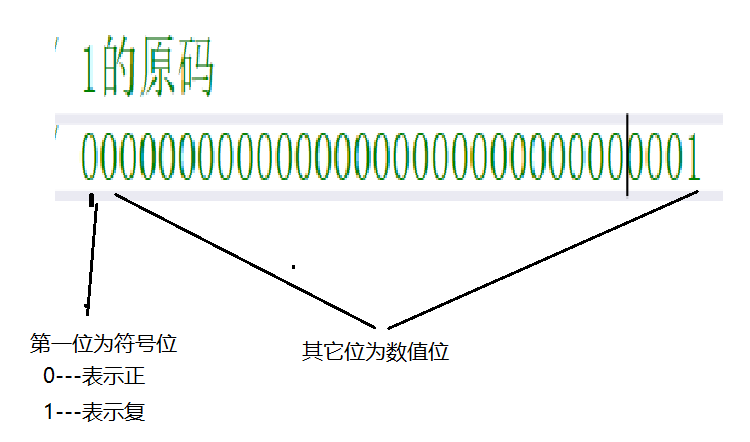
原碼
直接將二進位按照正負數的形式翻譯成二進位就可以。
反碼
將原碼的符號位不變,其他位依次按位取反就可以得到了。
補碼
反碼+1就得到補碼。
那我們來舉個例子
對於正整數,它的原碼 反碼 補碼 都相同
那麼對於負整數呢,繼續來看看

現在我們應該對原碼反碼補碼有了初步的了解,我們繼續接著上面來看
電腦儲存的是補碼,那麼我們現在來寫出 10 和 -20 的補碼來看看於上述記憶體中存的是否一樣
// 10的原碼,反碼,補碼 // 00000000000000000000000000001010 // -20的原碼 // 10000000000000000000000000010100 // -20的反碼 // 11111111111111111111111111101011 // -20的補碼 // 11111111111111111111111111101100
我們將其轉換為16進位來看看
10的補碼 00 00 00 0A -20的補碼 FF FF FF EC
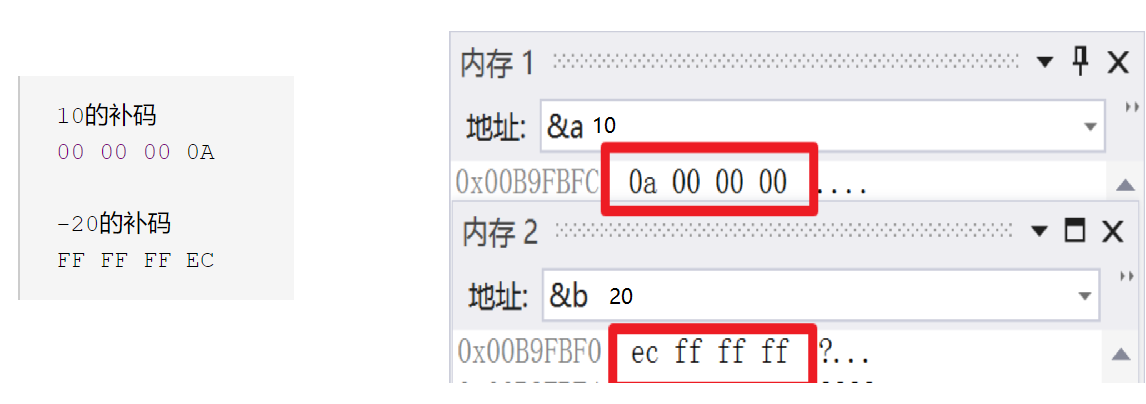
這時,我們似乎發現它們倆的補碼似乎按位元組反了過來,這是為什麼呢?
所以,這又引出了一個新的知識點——大小端
介紹 什麼大端小端: 大端(存儲)模式,是指數據的低位保存在記憶體的高地址中,而數據的高位,保存在記憶體的低地址中;
小端(存儲)模式,是指數據的低位保存在記憶體的低地址中,而數據的高位,,保存在記憶體的高地址中。 為什麼有大端和小端: 為什麼會有大小端模式之分呢?這是因為在電腦系統中,我們是以位元組為單位的,
每個地址單元都對應著一 個位元組,一個位元組為8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具 體的編譯器),
另外,對於位數大於8位的處理器,例如16位或者32位的處理器,由於暫存器寬度大於一個字 節,那麼必然存在著一個如果將多個位元組安排的問題。
因此就導致了大端存儲模式和小端存儲模式。 例如一個 16bit 的 short 型 x ,在記憶體中的地址為 0x0010 , x 的值為 0x1122 ,
那麼 0x11 為高位元組, 0x22 為低位元組。
對於大端模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。
小端模式,剛好相反。
我們常用的 X86 結構是小端模式,而 KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬體來選擇是大端模式還是小端模式。
那麼怎麼來判斷自己的編譯器是大端還是小端呢?
#define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> int check_sys() { int a = 1; return (*(char*)&a); } int main() { int ret = check_sys(); if (ret == 1) { printf("小端\n"); } else { printf("大端\n"); } return 0; }
運行結果如下

但,我們可能還是不知道它是怎麼實現的,所以在這解釋一下
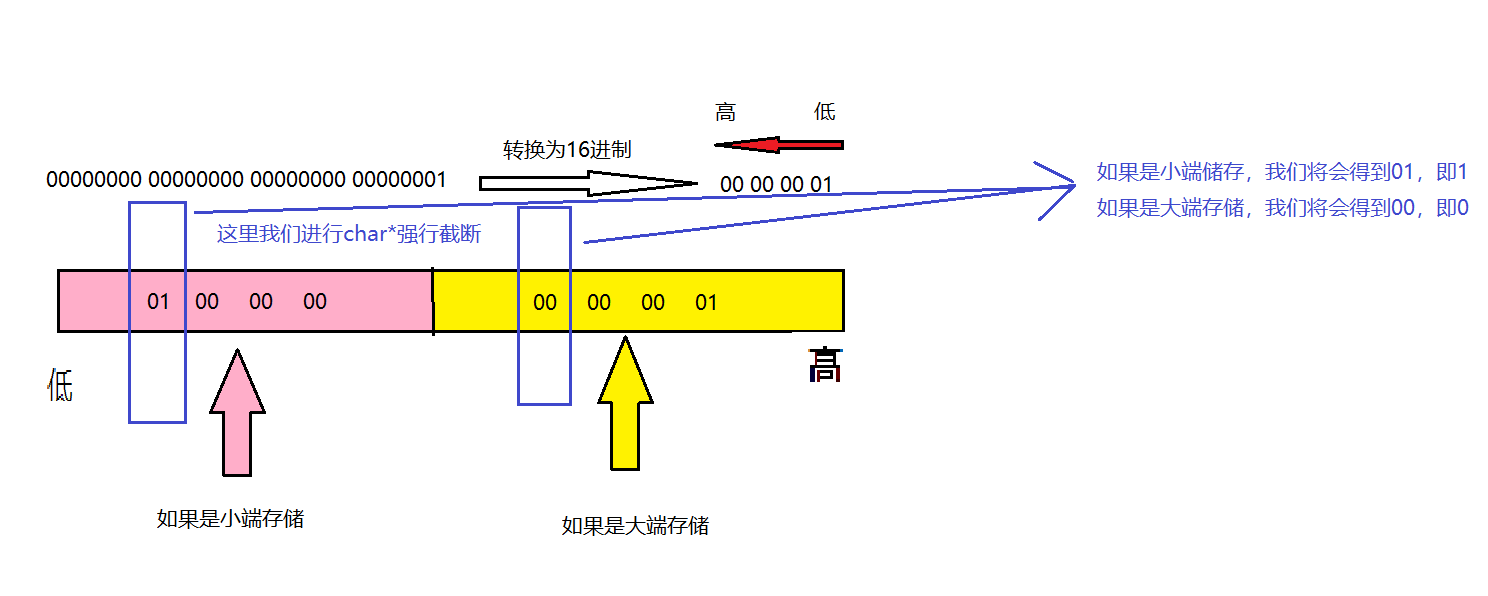
相信現在大家應該對此清楚了不少
那麼,現在我們將上述程式碼微做修改用我們的Keil C51來試一試
#include <reg52.h> #define uint unsigned int sbit LSA=P2^2; sbit LSB=P2^3; sbit LSC=P2^4; void delay(uint a) { while(a--); } int check_sys() { int a = 1; return (*(char*)&a); } int main() { int ret = check_sys(); LSA=1; LSB=1; LSC=1; while(1) { if (ret == 1) { P0=0x06;//在數碼管的首位顯示 1 } else { P0=0x3f;//在數碼管的首位顯示 0 } delay(1000); } }
運行結果
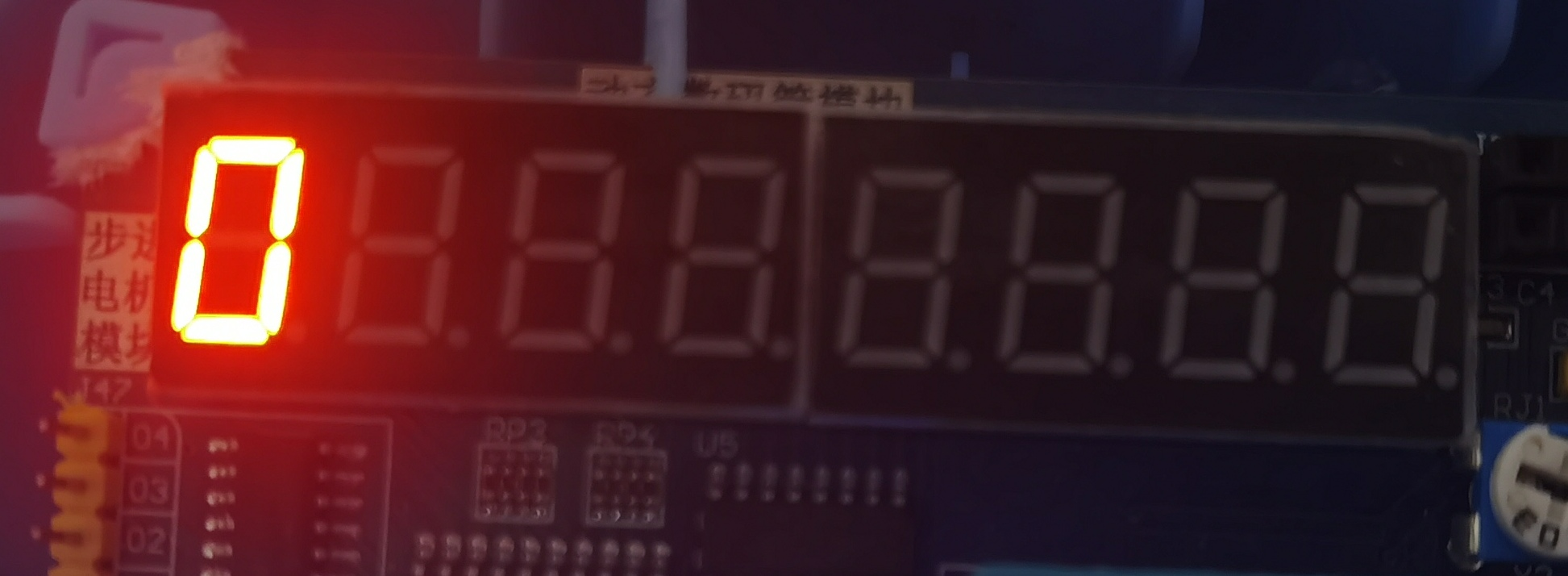
結果正如介紹所說,keil c51為大端存儲
那麼接下來我們來看看幾道題,以此加深我們對此的理解
1. //輸出什麼? #include <stdio.h> int main() { char a= -1; signed char b=-1;
unsigned char c=-1; printf("a=%d,b=%d,c=%d",a,b,c);
return 0; }
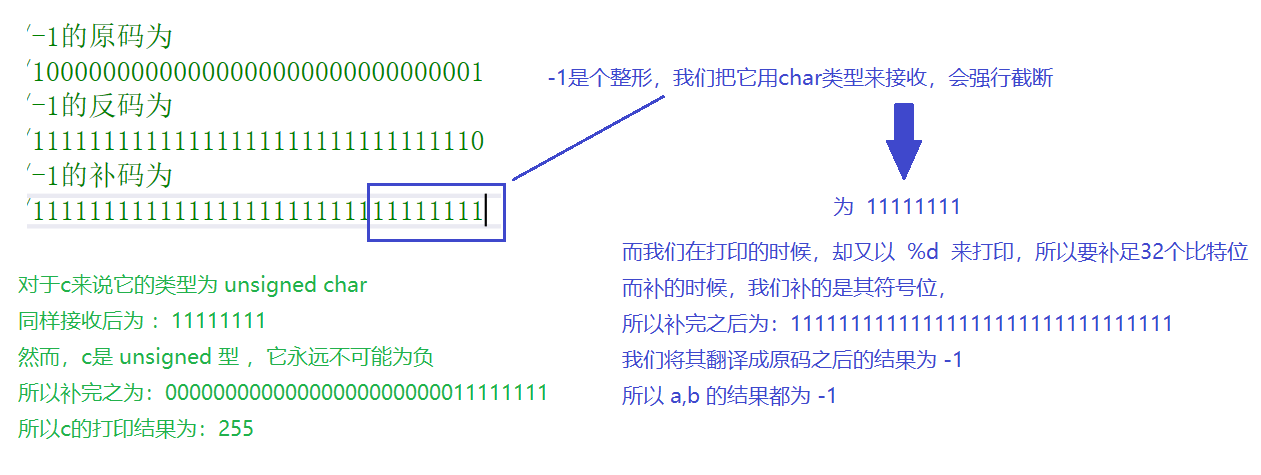
運行結果:
2. #include <stdio.h> unsigned char i = 0;
int main() { for(i = 0;i<=255;i++) { printf("hello world\n"); } return 0; }
那,這一題的結果 不知大家是否能夠想到是一直列印 hello world

我們對整形的存儲就停在這
接下來我們以一道題來進入浮點型在記憶體中的存儲
int main() { int n = 9; float *pFloat = (float *)&n;
printf("n的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
*pFloat = 9.0;
printf("n的值為:%d\n",n);
printf("*pFloat的值為:%f\n",*pFloat);
return 0; }
這道題許多人會給出 9 9.000000 9 9.000000 的答案
可事實並非如此
這題的答案為:

為什麼呢?
所以
二.浮點型在記憶體中的存儲
根據國際標準IEEE(電氣和電子工程協會)754,任意一個二進位浮點數V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符號位,當s=0,V為正數;當s=1,V為負數。
M表示有效數字,大於等於1,小於2。
2^E表示指數位。
我們舉個例子如 5.5
我們可以寫成 101.1(2進位)
按上述改為:
(-1)^ 0 *1.011*2^2
那麼 S=0, M=1.011, E=2.
IEEE 754規定: 對於32位的浮點數,最高的1位是符號位s,接著的8位是指數E,剩下的23位為有效數字M。

對於64位的浮點數,最高的1位是符號位S,接著的11位是指數E,剩下的52位為有效數字M。

而 IEEE 754對有效數字M和指數E,還有一些特別規定。 前面說過, 1≤M<2 ,也就是說,M可以寫成 1.xxxxxx 的形 式,其中xxxxxx表示小數部分。
IEEE 754規定,在電腦內部保存M時,默認這個數的第一位總是1,因此可以被捨去,只保存後面的xxxxxx部分。 比如保存1.01的時候,只保存01,等到讀取的時候,再把第一位的1加上去。這樣做的目的,是節省1位有效數字。 以32位浮點數為例,留給M只有23位,將第一位的1捨去以後,等於可以保存24位有效數字。
至於指數E,情況就比較複雜
首先,E為一個無符號整數(unsigned int) 這意味著,如果E為8位,它的取值範圍為0~255;如果E為11位,它的 取值範圍為0~2047。但是,我們知道,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入記憶體時E的真 實值必須再加上一個中間數,對於8位的E,這個中間數是127;對於11位的E,這個中間數是1023。比如,2^10的E 是10,所以保存成32位浮點數時,必須保存成10+127=137,即10001001。
那麼根據上面所述 現在 S=0, M=011, E=129
所以在記憶體中就為 0 10000001 01100000000000000000000 將其換為16進位為 40 b0 00 00
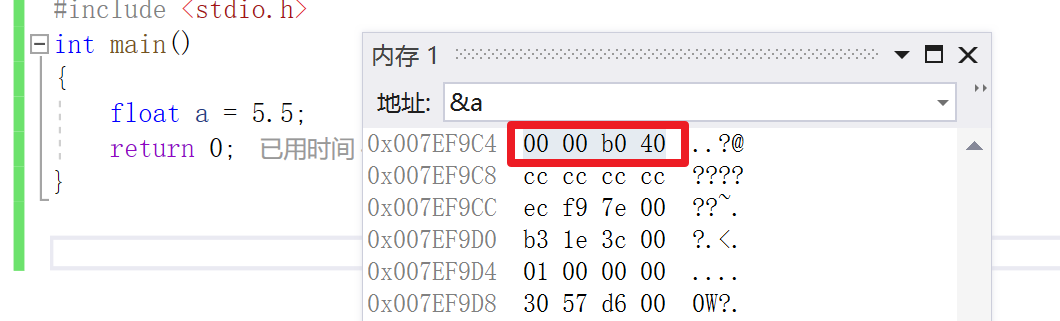
然後,指數E從記憶體中取出還可以再分成三種情況:
1.E不全為0或1
這時,浮點數就採用下面的規則表示,即指數E的計算值減去127(或1023),得到真實值,再將有效數字M前 加上第一位的1。
2.E全為0
這時,浮點數的指數E等於1-127(或者1-1023)即為真實值, 有效數字M不再加上第一位的1,而是還原為
0.xxxxxx的小數。這樣做是為了表示±0,以及接近於0的很小的數字。
3.E全為1
這時,如果有效數字M全為0,表示±無窮大(正負取決於符號位s);
此時是否對前面所提到的那一題恍然大悟了呢


