分散式理論 PACELC 了解么?
PACELC 基於 CAP 理論演進而來。
CAP 理論是一個分散式系統中老生常談的理論了:
- C(Consistency):一致性,所有節點在同一時間的數據完全一致。
- A(Availability):可用性,服務一直可用。
- P(Partition tolerance):分區容錯性,遇到某節點或網路分區故障的時候,仍然能夠對外提供滿足一致性和可用性的服務
系統設計中,這三點只能取其二,一般的分散式系統要求必須有分區容錯性。剩下的只能從 C 或者 A 中取捨。
但是這個理論並不能很好地應用於實際,首先, A 中是有一定爭議的,很長時間才返回,雖然可用,但是業務上可能不能接受。並且,系統大部分時間下,分區都是平穩運行的,並不會出錯,在這種情況下,系統設計要均衡的其實是延遲與數據一致性的問題,為了保證數據一致性,寫入與讀取的延遲就會增高。這就引出了 PACELC 理論。
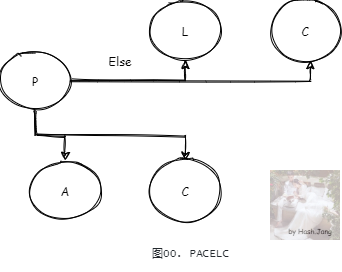
在出現分區錯誤的情況下,取前半部分 PAC,理論和 CAP 內容一致。沒有出現分區錯誤的情況下(PACELC 中的 E 代表 Else),取 LC,也就是 Latency(延遲)與 Consistency(一致性)。
現在,其實很多存儲,都已經實現了不同的 PACELC 的兼顧策略,並且交由用戶配置去靈活根據不同業務場景使用不同的策略。
DynamoDB,Riak,Cassandra 的 NWR 模型
例如 DynamoDB 和 Riak 還有 Cassandra 都是 Dynamo 理論論文的基於一致性哈希寫多份實現最終一致性的存儲,在默認情況下,是 P+A 以及 E+L 的系統,但是可以根據配置修改,主要基於NWR模型與同步和非同步備份。N 代表 N 個備份,W 代表要寫入至少 W 份才認為成功,R 表示至少讀取 R 個備份。配置的時候要求 W+R > N。 因為 W+R > N, 所以 R > N-W。這個是什麼意思呢?就是讀取的份數一定要比總備份數減去確保寫成功的倍數的差值要大。
也就是說,每次讀取,都至少讀取到一個最新的版本。從而不會讀到一份舊數據。當我們需要高可寫的環境的時候(例如,amazon 的購物車的添加請求應該是永遠不被拒絕的)我們可以配置W = 1 如果N=3 那麼R = 3。 這個時候只要寫任何節點成功就認為成功,但是讀的時候必須從所有的節點都讀出數據。如果我們要求讀的高效率,我們可以配置 W=N R=1。這個時候任何一個節點讀成功就認為成功,但是寫的時候必須寫所有三個節點成功才認為成功。
大家注意,一個操作的耗時是幾個並行操作中最慢一個的耗時。比如R=3的時候,實際上是向三個節點同時發了讀請求,要三個節點都返回結果才能認為成功。假設某個節點的響應很慢,它就會嚴重拖累一個讀操作的響應速度。
MongoDB
MongoDB 和上面的 Dynamo 類似,MongoDB關於一致性、可用性的權衡,取決於三者:
write-concern: 表示當寫請求在value個MongoDB實例處理之後才向客戶端返回read-concern: 設定是否必須從 primary 讀取最新的數據還是可以從 secondary 讀取最終一致性的數據。read-preference: 對於replica set,是返回當前節點的最新數據,還是返回寫入節點最多的數據,還是根據一些函數計算出的數據。
MySQL 同步
MySQL主從複製包括非同步模式、半同步模式、全同步複製
默認情況下是非同步模式,MySQL 一主多從部署讀寫分離的情況下,實現的為最終一致性,如果考慮一定延遲可以接受,一般可以通過 show slave status來查看主從延遲從而決定數據是否可以從 slave 讀取。 MyCat 等中間件就是用了這種機制。可以通過對於這個時延的容忍性,控制 L 與 C 的取捨 以及 A 與 C 的取捨。
全同步複製:指當主庫執行完一個事務,所有的從庫都執行了該事務才返回給客戶端。這樣保證了強一致性,但是響應時間變長了。
半同步複製:主庫在執行完客戶端提交的事務後不是立刻返回給客戶端,而是等待至少一個從庫接收到並寫到 relay log 中才返回給客戶端。這樣雖然還是有延遲,但是延遲小了很多並且數據相比於非同步複製更加不容易丟失。
一致性協議
一致性協議一般包括:
- 2PC,兩階段提交
- 3PC,三階段提交
- Paxos,Paxos 是很細緻的一致性協議,但是一般實現過於複雜僅僅是理論
- Raft,Raft 是能夠實現分散式系統強一致性的演算法,TiDB 的一致性協議就是基於 Raft
- ZAB,Zookeeper 的一致性協議,基於 Paxos 簡化
- NWR,上面提到的 dynamo 理論基礎的協議,將 PACELC 均衡交給用戶
每日一刷,輕鬆提升技術,斬獲各種offer:



