數據科學完整流程概述
數據科學交流群,QQ群號:189158789 ,歡迎各位對數據科學感興趣的小夥伴的加入!
此文章的目的旨在統一各種分析過程中的術語以及流程,並試圖構建更為完整、更為詳盡的處理流程,針對不同場景下不同規模的數據集,此框架應該根據實際情況進行適當的裁剪!!!
注意:此版本只是一個粗糙的版本,隨著學習的深入,後續可能會不斷更新,如果有什麼問題,請在評論區留言,或者進入我新建的數據科學群一起討論!
目錄
〇、商業理解(Business Understanding)
本節內容內容照搬CRISP-DM1.0中的內容,不過該階段更多時候是一個仁者見仁、智者見智的狀態,畢竟商業上很多知識都來自於各行業從業者或者管理者們的實踐而得,沒有一個統一的標準。
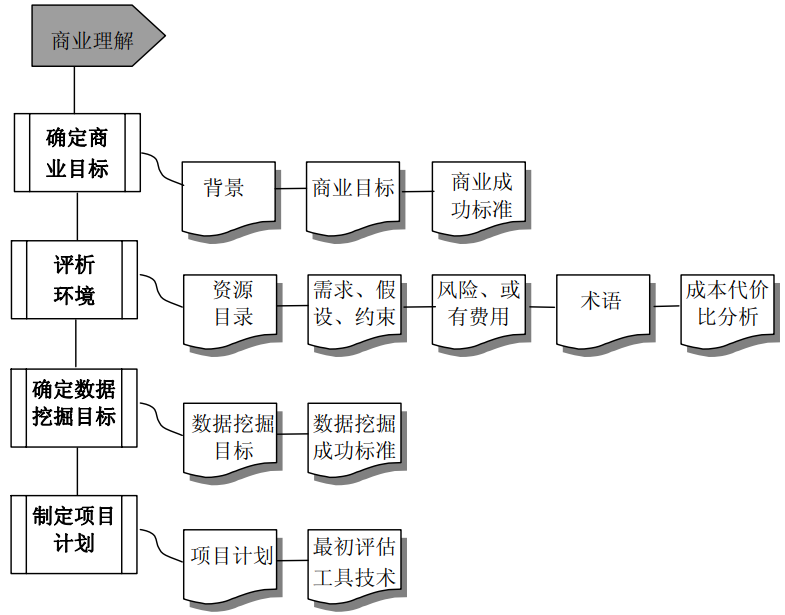
更多細節內容可以參照這份文檔進行學習:
點擊以上鏈接即可下載!!!
一、數據收集(Data Collection)
1.1.收集方法
關於數據採集的方式和方法,可以參照我之前寫的一篇文檔:
常用的數據採集方法有哪些? – PurStar – 部落格園
//www.cnblogs.com/purstar/p/14224062.html
2.2.原始數據收集報告
可以在收集數據的時候寫出一份原始數據收集報告,大概內容如下:
列出獲得的數據集(或多個數據集),包括它們在項目中的位置,獲得的方法及遇到的問題。記錄遇到的問題和解決方案有助於遷移到將來項目或者推進類似項目。 ……
二、數據理解(Data Understanding)
2.1.數據描述
描述數據可以採用如下相關的一些概念,當然根據實際情況,可能還有其他更多數據的屬性可以用作描述:
數據來源(一手數據、二手數據)
數據存儲(文件系統、資料庫、雲存儲……)
數據格式(CSV、TXT、PDF、……)
數據字元編碼(ASCII、UTF-8、GBK 和 GB2312、Unicode、……)
數據規模(數據規模的大小可能會決定後面數據處理或分析的工具):
- 單錶行數
- 單表列數
- 多表之間的關係
- 整體所佔空間的大小
數據結構類型:結構化、半結構化、非結構化(一般流程是將半結構化或者非結構化的數據轉換為結構化數據再進行處理,詳細概念可以參考這篇內容 數據類型的多樣性:結構化數據、半結構化數據、非結構化數據 – PurStar – 部落格園)
數據粒度:細化程度越高,粒度越小;細化程度越低,粒度越大。例如具體城市比省份或者國家更精細等等……
數據的精確含義:查看列或者行所代表的含義,一般數據比較大的情況下,會查看前幾行或後幾行等等,如果有數據字典那就更好了!
數據字典:數據字典是指對數據的數據項、數據結構、數據流、數據存儲、處理邏輯等進行定義和描述。
變數類型:
- 名義變數:統計學術語,是以貨幣單位為基準的變數。
- 實際變數:實際變數不包含價格變動因素,名義的包含;把名義變數剔除價格變動因素就是實際變數 。
- 定量數據:定量數據本質上是數值,應該是衡量某樣東西的數量。
- 定性數據:定性數據本質上是類別,應該是描述某樣東西的性質。
- 定類變數:又稱「定類尺度」。根據定性的原則區分總體各個案類別的變數。
- 定序變數:定序變數是變數的一種,區別同一類別個案中等級次序的變數。
- 定距變數:定距變數也稱間距變數,是取值具有”距離」特徵的變數。
- 定比變數:定比變數又稱「定比尺度」或「比率尺度」。區別同一類別個案中等級次序及其距離的變數。
數據等級的總結:
下表總結里 每個等級上可行與不可行的操作:

下表展示了每個等級上可行與不可行的統計類型:
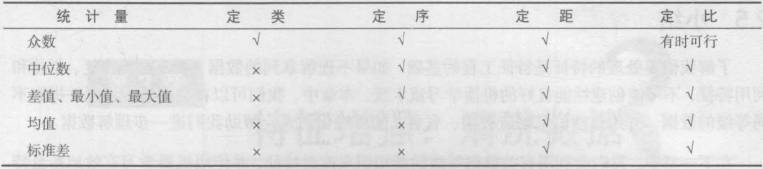
下表顯示了每個等級上可以或不可以繪製的圖表:

當你拿到一個新的數據集時,下面是針對變數理解和處理的基工作流程:
(1)數據有沒有組織?數據是以表格形式存在、有不同的行列,還是以非結構化的文本格式存在?
(2)每列的數據是定量的還是定性的?單元格中的數代表的是數值還是字元串?
(3)每列處於哪個等級?是定類、定序、定距,還是定比?
(4)我們可以用什麼圖表?條形圖、餅圖、莖葉圖、箱型圖、直方圖,還是其他?
下圖是對以上邏輯的可視化:

冗餘變數:一般指重複或者多餘的變數
完整性:取值範圍、取值的一致性、異常值、整體完整性
預設值、默認值:指一個屬性、參數在被修改前的初始值。
關鍵字:
- 公共關鍵字:公共關鍵字指的是在關係資料庫中,關係之間的聯繫是通過相容或相同的屬性或屬性組來表示的。
- 外關鍵字:如果公共關鍵字在一個關係中是主關鍵字,那麼這個公共關鍵字被稱為另一個關係的外關鍵字。
- 侯選關鍵字:如果一個超關鍵字去掉其中任何一個欄位後不再能唯一地確定記錄,則稱它為「候選關鍵字」(Candidate Key)。
- 主關鍵字:關鍵字(primary key)是表中的一個或多個欄位,它的值用於唯一的標識表中的某一條記錄。
……
2.2.探索性數據分析(EDA)
2.2.1.CDA與EDA的區別
傳統的多元分析方法採用的是「假定—模擬—檢驗」的證實性數據分析策略(confirmatory data analysis,CDA),即首先需要假設數據總體服從某種分布(如正態分布)。然而,在實際問題中有許多數據並不滿足這一前提假設,因而需要使用穩健的或非參數的方法去解決。但是,但數據維數很高時,這些方法都將面臨一些困難。
為了克服CDA這種分析策略所具有的一些困難,需要對數據不做假設或者只做很少的假設,進而「直觀審視數據——通過電腦模擬數據結構——檢驗」這樣一種探索性數據分析策略(exploratory data analysis,EDA)。
探索性數據分析是在盡量少的先驗假定下對數據進行處理,通過作圖、製表等形式以及方程擬合、計算某些特徵量等手段,探索數據的結構和規律的一種數據分析方法。與證實性數據分析相比,探索性數據分析具有如下特點:
(1)研究從原始數據人手,完全以實際數據為依據,而不必對數據的分布進行假設。
(2)分析方法從實際出發,不以某種理論為依據。探索性數據分析在尋求數據內在的數量特徵、數量關係和數量變化時,什麼方法可以達到這一目的就採用什麼方法,方法的選擇完全取決於數據的特點和研究目的。
(3)分析工具簡單直觀,更易於普及。探索性數據分析強調直觀及數據可視化,使分析者能一日瞭然地看出數據中隱含的有價值的資訊,顯示出其遵循的普遍規律及與眾不同的突出特點,促進發現規律,得到啟迪,滿足分析者的多方而要求,這也是探索性數據分析策略對於數據分析工作的主要貢獻。
2.2.2.基本統計分析
1.描述統計分析
1)描述集中趨勢的指標:
常用的有算術均數(mean)、幾何均數(geometric mean)和中位數(median)等
其中算術均數適用於正態分布和對稱分布的資料;
幾何均數適用於經對數轉換後呈對稱分布的資料,它不能用本章講解的模組直接求出;
中位數適用於各種分布類型的資料,尤其是偏態分布資料和一端或兩端無確切數值的資料。
2) 描述離散趨勢的指標:
常用的有極差(range)、四分位數間距(quartile range)、方差(variance)、標準差(standard deviation)等。
極差反映一組變數值最大值和最小值之差;
四分位數間距一般和中位數一起描述偏態分布資料的分布特徵;
方差和標準差只適合於正態分布的資料。
3)百分位數指標(Percentile):
是一種位置指標,適合於各種分布類型的資料。
4)描述數據分布的統計量(Distribution):
偏度係數、峰度係數。用來說明數據偏離正態分布的程度。
2.頻數分析
1)頻數表:頻數表是數理統計中由於所觀測的數據較多,為簡化計算,將這些數據按等間隔分組,然後按選舉唱票法數出落在每個組內觀測值的個數,稱為(組)頻數。
2)列聯表:列聯表(contingency table)是觀測數據按兩個或更多屬性(定性變數)分類時所列出的頻數表。它是由兩個以上的變數進行交叉分類的頻數分布表。
3)獨立性檢驗
①卡方檢驗。檢驗多個總體比率的相等性、檢驗兩個分類變數的獨立性、檢驗一個總體的概率分布是否服從一個歷史概率分布。
②Fisher精確檢驗,原假設:邊界固定的列聯表中行和列是相互獨立的,不能用於2*2列聯表。
③CMH檢驗的原假設是兩個名義變數在第三個變數的每一層中都是條件獨立的。
3、相關
在完成獨立性檢驗後,如果拒絕原假設,那麼兩變數之間的相關性如何?使用assocstats總體來說,較大的值意味著強的相關性。
- 相關係數:相關係數是最早由統計學家卡爾·皮爾遜設計的統計指標,是研究變數之間線性相關程度的量,一般用字母 r 表示。由於研究對象的不同,相關係數有多種定義方式,較為常用的是皮爾遜相關係數。
- 協方差:協方差(Covariance)在概率論和統計學中用于衡量兩個變數的總體誤差。而方差是協方差的一種特殊情況,即當兩個變數是相同的情況。
- 偏相關係數:亦稱「凈相關」、「純相關」、「條件相關」。偏相關係數不為零的兩個隨機變數稱做偏相關(參見「偏相關係數」)。偏相關性,是兩個隨機變數在排除了其餘部分或全部隨機變數影響情形下的凈相關性或純相關性,是兩個隨機變數在處於同一體系的其餘部分或全部隨機變數取給定值的情形下的條件相關性。偏相關分析的主要作用在於,在所有的自變數中,判斷哪些自變數對因變數的影響較大,從而選擇作為必需的自變數。
4.T檢驗:
在探究中,我們最常見的行為是對兩組進行比較,如果結果變數是類別型的就使用前面學過的相關性的顯著性檢驗進行檢驗,如果是連續型的並且假設其稱正態分布,使用t檢驗。
5.組間差異的非參數檢驗
①兩組的比較
Wilcoxon秩和檢驗是依據兩總體中位數之差的一種非參數方法,還有一種是符號檢驗。目的是通過中位數比較兩組是否相同。
②多於兩組的比較
如果沒有滿足方差設計的假設,Kruskal是一種在各組獨立的情況下的方式,Friedman是在各組不獨立時的方式。也是通過中位數進行檢驗。
通過以上檢驗雖然可以拒絕原假設,但檢驗並沒有告訴你哪些地區顯著的與其他地區不同。使用U檢驗可以對兩組間進行比較。
③組間差異的可視化
箱線圖和核密度圖
2.2.3.模式發現
降維——線性方法:
- 主成分分析——PCA
- 奇異值分解——SVD
- 非負矩陣分解
- Fisher線性判別
- 本徵維數
- 最近鄰法
- 關聯維數
- 最大似然估計
- 包數估計
降維——非線性方法:
- 多維尺度分析——MDS
- 度量MDS
- 非度量MDS
- 流形學習
- 局部線性嵌入
- 等距特徵映射
- 海賽特徵映射
- 人工神經網路方法
- 自組織映射
- 生成式拓撲映射
- 曲元分析
數據巡查
- 總體巡查法
- 插值巡查法
- 投影追蹤法
- 獨立成分分析
發現類——各種聚類技術……
平滑散點圖
……
2.2.4.數據可視化
最有價值的圖表系列
深度好文 | Matplotlib可視化最有價值的 50 個圖表(附完整 Python 源程式碼)
//liyangbit.com/pythonvisualization/matplotlib-top-50-visualizations/
聚類可視化:
- 樹狀圖
- 樹圖
- 矩形圖
- ReClus圖
- 數據影像
分布圖形:
- 直方圖(一元、二元、……)
- 箱線圖
- 分位數圖
- 概率圖
- q-q圖
- 分位數圖
- 袋狀圖
- 測距儀箱線圖
多元可視化:
- 象形圖
- 散點圖
- 動態圖
- 協同圖
- 點陣圖
- 繪點為線
- 數據巡查
- 雙標圖
2.3.數據品質評價
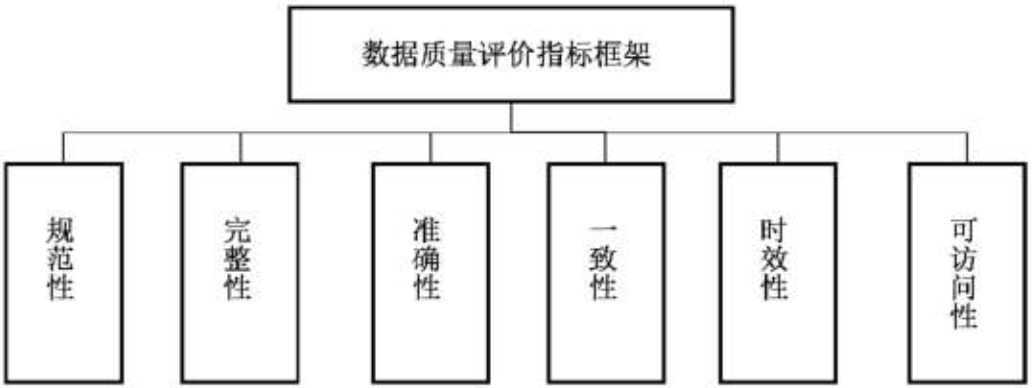
說明:
- 規範性——數據符合數據標準、數據模型、業務規則、無數據或權威參考數據的程度。
- 完整性——按照數據規則要求,數據元素被賦予數值的程度。
- 準確性——數據準確表示其所描述的其實實體(實際對象)真實值的程度。
- 一致性——數據與其他特定上下文中使用的數據無矛盾的程度。
- 時效性——數據在時間變化中的正確程度。
- 可訪問性—— 數據能被訪問的程度。
更為詳細的內容請參考國家標準:
三、數據準備(Data preparation)、數據預處理
3.1.選擇數據、數據抽取:
總體與樣本:
對總體進行逐個數據取樣或記錄動態過程中的每一個階段,在大多數時候是不可能的或不合實際的。正如:
- 研究海豚交流方式的海洋生物學家不可能測試每一隻海豚
- 製造商要想知道一種建築材料在室外降解的速度有多快
他們不能因為測試而抓獲所有生物或者摧毀所有產品。
由於海量資料庫和功能強大的軟體的幫助,金融分析師往追蹤特定股票的未來表現時,可以分析某隻股票過去的每一手交易,但是他們無法對還未發生的交易進行研究。
數據的代表性
如果我們想通過一個項目對總體或全過程做概括性總結,對樣本的代表性作出合理的預期是十分關鍵的。無論何時,當我們依賴樣本資訊時,都冒著樣本可能無法代表總體的風險(一般來說,我們稱為抽樣誤差)。
統計學家對抽樣樣本有一些標準方法,但沒有一種方法可以保證某一樣本可以準確代表總體,僅有一些方法可以相對減小發生抽樣誤差的風險。此外,某些方法可以預測抽樣誤差。
如果我們能夠預測風險的範圍,那麼我們就可以從樣本中概括總體。反之,則不能!
抽樣技術:
概率抽樣的類型
- 簡單隨機抽樣
- 系統抽樣
- 分層抽樣
- 整群抽樣
非概率抽樣的類型
- 簡單抽樣
- 配額抽樣
- 判斷抽樣
- 雪球取樣
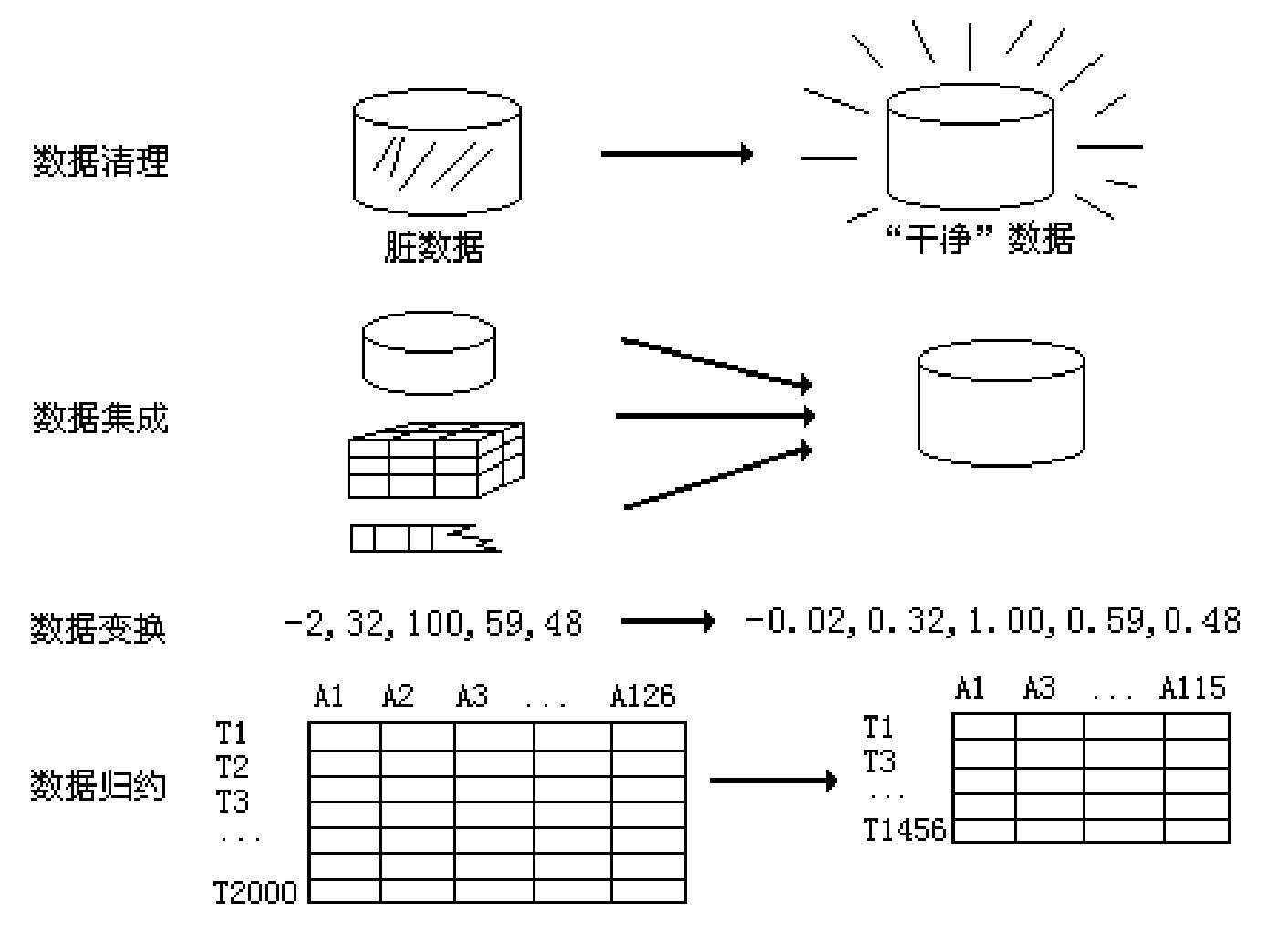
3.2.數據清洗、數據清理:
數據清洗是指發現並糾正數據文件中可識別的錯誤的一道程式,包括檢查數據一致性,處理無效值和缺失值等。與問卷審核不同,錄入後的數據清理一般是由電腦而不是人工完成。
需要著重處理以下類型的數據:
- 重複值
- 遺漏值或空值
- 噪音數據(錯誤值或異常值)
- 不一致數據
3.3.構造數據、數據派生:
該任務包括構造性的數據準備操作,如派生屬性、全新記錄的生成、或現有屬性的值轉換。
1)屬性派生(Derived attributes ):
派生屬性或者數據是在原有屬性和數據的基礎上構建出來的。例如: area=length*width。
2)單一屬性轉化(Single-attribute transformations )
有時把區間值轉換成離散欄位(例,年齡到年齡段),有時離散欄位(如, 「絕對正確」, 「正確」, 「不知道」, 「錯誤」 )轉換成數值型。這取決於建模工具或演算法的要求。
3)生成新紀錄:
生成的記錄是全新的記錄,它引入了新知識或表示了還沒有表示過的數據,例如,已聚類的數據有助於生成一條記錄來表示聚類的成員模板,以做進一步的處理。
3.4.整合數據、數據集成:
在企業中,由於開發時間或開發部門的不同,往往有多個異構的、運行在不同的軟硬體平台上的資訊系統同時運行,這些系統的數據源彼此獨立、相互封閉,使得數據難以在系統之間交流、共享和融合,從而形成了”資訊孤島“。隨著資訊化應用的不斷深入,企業內部、企業與外部資訊交互的需求日益強烈,急切需要對已有的資訊進行整合,聯通「資訊孤島」,共享資訊。
數據集成:數據集成通過應用間的數據交換從而達到集成,主要解決數據的分布性和異構性的問題,其前提是被集成應用必須公開數據結構,即必須公開表結構,表間關係,編碼的含義等。
實體識別:
實體就是名詞,也就是說人名、地名、物名都是實體。在電腦領域進行實體識別是一個大活,好在我們並不想弄明白裡面的機理,因而只需要清楚在數據清洗的過程中我們需要怎麼對待實體即可。
例如,數據分析者或電腦如何才能確信一個資料庫中的 customer_id 和另一個資料庫中的 cust_number 指的是同一實體?通常,資料庫和數據倉庫有元數據——關於數據的數據。這種元數據可以幫助避免模式集成中的錯誤。
大致說來,我們需要在數據清洗的時候把兩個本來不是同一個東西的實體區別開,也需要把本來是一個東西的實體對的上。大致工作有如下幾項:
-
同名異義:例如蘋果既可以代表手機也可以代表水果。再譬如姓名王偉是一個很普通的名字,但是它卻表示不同的實體。
-
異名同義:例如我們的團隊中有個「濤哥」,名字叫做「張濤」,很多場合下我們得知道這是一個人。又譬如「李白」和「李太白」指的就是一個人。又譬如我們會習慣性的給某個人加上職位性的稱謂,譬如說「陳主任」、「王博士」、「周院長」等等。我們需要能夠將這些稱謂與之真姓名對應起來。
-
單位統一:用於描述同一個實體的屬性有的時候可能會出現單位不統一的情況,也需要能夠統一起來,譬如1200cm與1.2m,要知道電腦在進行處理的時候是沒有量綱的,要麼統一量綱,要麼去量綱化(歸一化)。
-
ID-Mapping:ID-Mapping實際上是一個互聯網領域的術語,意思是將不同資料庫或者帳號系統中的人對應起來。譬如說你辦了中國移動的手機卡,他們就會知道你用的是某個手機號,而如果你使用今日頭條你就會留下各種瀏覽新聞的痕迹,如果現在中國移動要和今日頭條合作,那麼就得打通兩邊的數據,「打通」的第一步就是知道中國移動的張三就是今日頭條的張三,這個過程在當下可以通過設備的IMIS號碼進行比照進行,其他的ID-Mapping需要採取不同的策略。歸根到底,ID-Mapping需要的是採用唯一識別號(學號,學校-年級-班級-姓名,設備號等)進行帳號的用戶匹配。這在大數據強調的數據孤島問題解決上有著重要的意義。
數據冗餘:
數據冗餘可能來源於數據屬性命名的不一致,在解決數據冗餘的過程中對於數值屬性可以利用皮爾遜積矩Ra,b來衡量,它是一個位於[-1,1]之間的數值,大於零那麼屬性之間呈現正相關,否則為反相關。絕對值越大表明兩者之間相關性越強。對於離散數據可以利用卡方檢驗來檢測兩個屬性之間的關聯。
冗餘可以被相關分析檢測到。例如,給定兩個屬性,根據可用的數據,這種分析可以度量一個屬性能在多大程度上蘊涵另一個。對於標稱數據,我們使用卡方檢驗。對於數值屬性,我們使用相關係數和協方差,它們都評估一個屬性的值如何隨另一個變化。
數據衝突:
成的第三個重要問題是數據值衝突的檢測與處理。例如,對於現實世界的同一實體,來自不同數據源的屬性值可能不同。這可能是因為表示、比例或編碼不同。例如,重量屬性可能在一個系統中以公制單位存放,而在另一個系統中以英制單位存放。不同旅館的價格不僅可能涉及不同的貨幣,而且可能涉及不同的服務(如免費早餐)和稅。數據這種語義上的異種性,是數據集成的巨大挑戰。
仔細將多個數據源中的數據集成起來,能夠減少或避免結果數據集中數據的冗餘和不一致性。這有助於提高其後挖掘的精度和速度。
3.5.數據變換:
1)平滑:
去掉數據中的噪音。這種技術包括
- 分箱:分箱方法通過考察「鄰居」(即,周圍的值)來平滑存儲數據的值。存儲的值被分布到一些「桶」或箱中。由於分箱方法導致值相鄰,因此它進行局部平滑。
- 聚類:局外者可以被聚類檢測。聚類將類似的值組織成群或「聚類」。直觀地,落在聚類集合之外的值被視為局外者。
- 回歸:可以通過讓數據適合一個函數(如回歸函數)來平滑數據。線性回歸涉及找出適合兩個變數的「最佳」直線,使得一個變數能夠預測另一個。
2)聚集(顆粒度轉化):
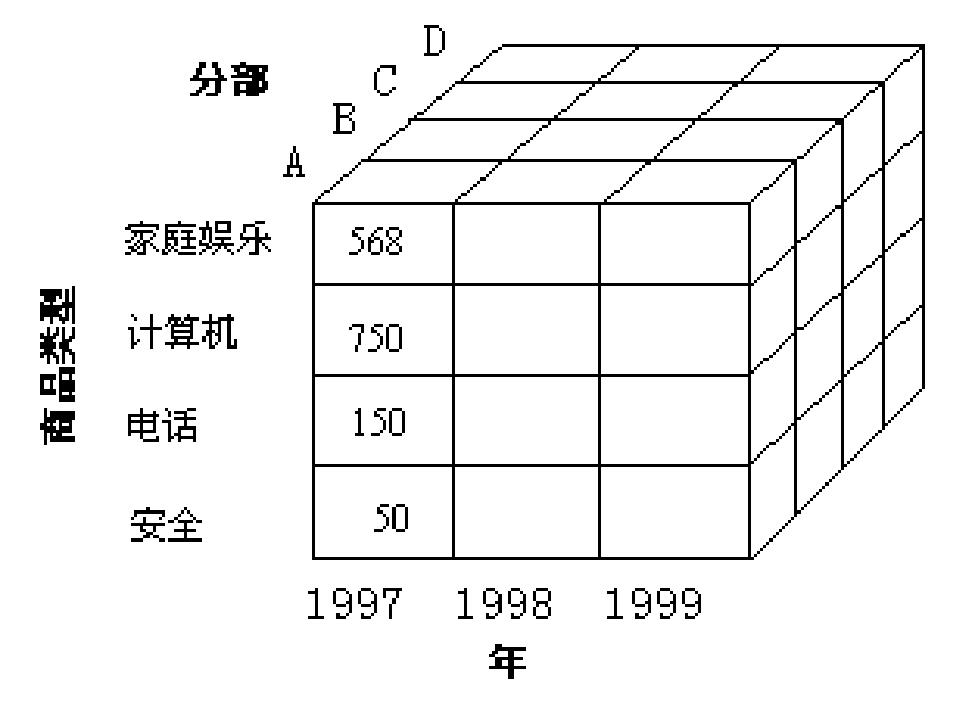
對數據進行匯總和聚集。例如,可以聚集日銷售數據,計算月和年銷售額。通常,這一步用來為多粒度數據分析構造數據方。
3)數據泛化:
使用概念分層,用高層次概念替換低層次「原始」數據。例如,分類的屬性,如 street,可以泛化為較高層的概念,如 city 或 country。類似地,數值屬性,如 age,可以映射到較高層
概念,如 young, middle-age 和 senior。
4)規範化:
將屬性數據按比例縮放,使之落入一個小的特定區間,如-1.0 到 1.0 或 0.0 到 1.0。
- 最小-最大規範化
- z-score 規範化
- 按小數定標規範化
5)屬性構造(或特徵構造):
可以構造新的屬性並添加到屬性集中,以幫助挖掘過程。
屬性構造是由給定的屬性構造和添加新的屬性,以幫助提高精度和對高維數據結構的理解。例如,我們可能根據屬性 height 和 width 添加屬性 area。屬性結構可以幫助平緩使用判定樹演算法分類的分裂問題。那裡,沿著導出判定樹9的一條路徑重複地測試一個屬性。屬性構造操作符的例子包括二進位屬性的 and 和名字屬性的 product。通過組合屬性,屬性構造可以發現關於數據屬性間聯繫
的丟失資訊,這對知識發現是有用的。
6)格式化
如改變數據排列順序或次序
3.6.數據規約:
1. 數據方聚集: 聚集操作用於數據方中的數據。
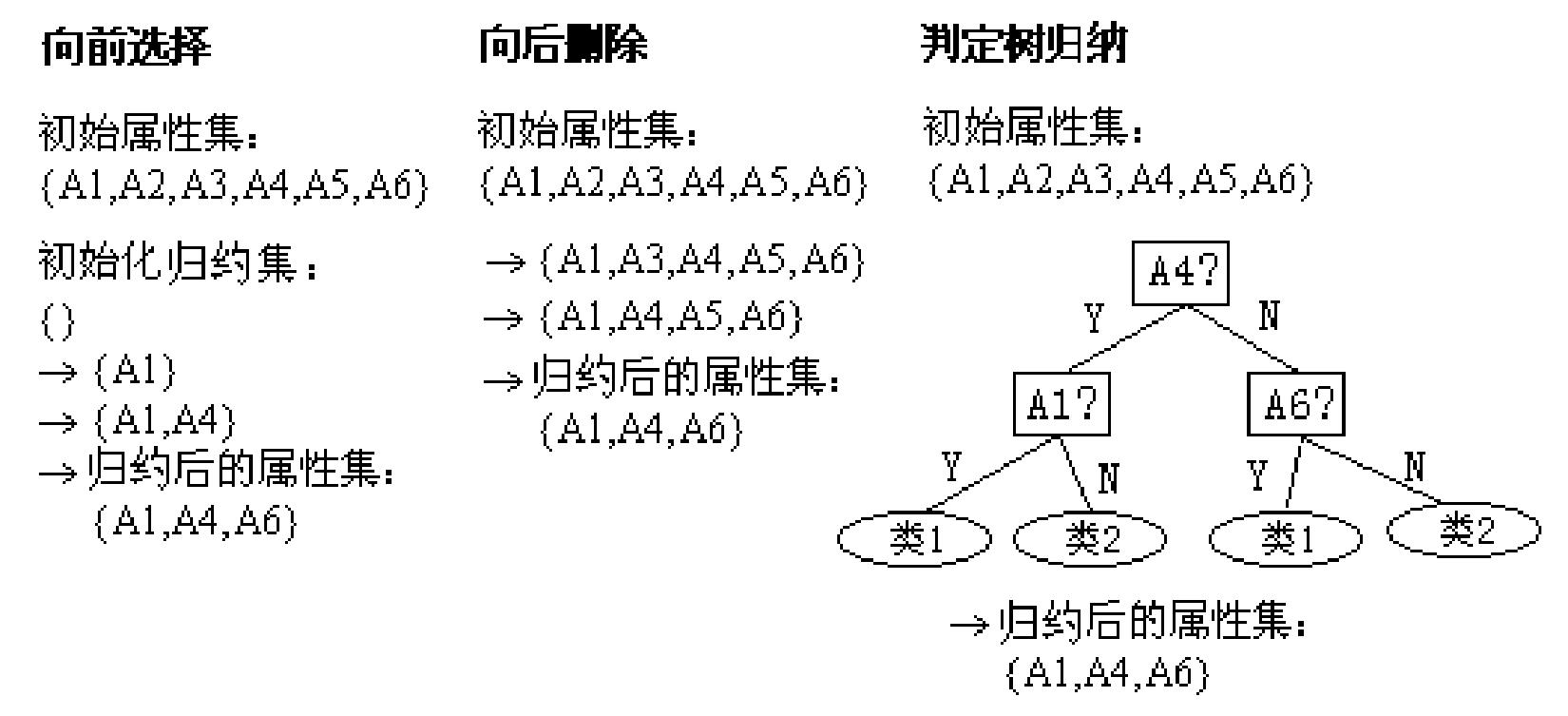
2. 維歸約:可以檢測並刪除不相關、弱相關或冗餘的屬性或維。
3. 數據壓縮: 使用編碼機制壓縮數據集。
在數據壓縮時,應用數據編碼或變換,以便得到原數據的歸約或「壓縮」表示。如果原數據可以由壓縮數據重新構造而不丟失任何資訊,則所使用的數據壓縮技術是無損的。如果我們只能重新構造原數據的近似表示,則該數據壓縮技術是有損的。有一些很好的串壓縮演算法。儘管它們是無損的,但它們只允許有限的數據操作。
兩種有效的有損數據壓縮方法:
- 離散小波變換(DWT)
- 主要成分分析(PCA)
4. 數值壓縮: 用替代的、較小的數據表示替換或估計數據,如參數模型(只需要存放模型參數,而不是實際數據)或非參數方法,如聚類、選樣和使用直方圖。
5. 離散化和概念分層產生: 屬性的原始值用區間值或較高層的概念替換。概念分層允許挖掘多個抽象層上的數據,是數據挖掘的一種強有力的工具。
四、特徵工程(feature engineering)
4.1.特徵構建、特徵創建
- 填充分類特徵
- 編碼分類變數
- 擴展數值特徵
4.2.特徵提取、特徵抽取
- 針對文本特徵的提取
- 詞袋法
- CountVectorizer
- TF-IDF向量化器
- 針對影像特徵的提取
4.3.特徵選擇
特徵太少,不足以描述數據,造成偏差過高;特徵太多,一是增大計算成本,二是造成維度災難(方差過高導致過擬合)。
愛因斯坦:「盡量讓事情簡單,但不能過於簡單。」機器學習演算法性能的上限,取決於特徵的選擇。
特徵選擇技術可以精簡掉無用的特徵,以降低最終模型的複雜性,它的最終目的是得到一個簡約模型,在不降低預測準確率或對預測準確率影響不大的情況下提高計算速度。
為了得到這樣的模型,有些特徵選擇技術需要訓練不止一個待選模型。換言之,特徵選擇不是為了減少訓練時間(實際上,一些技術會增加總體訓練時間),而是為了減少模型評分時間。
粗略地說,特徵選擇技術可以分為以下三類。
1)過濾器法、Filter
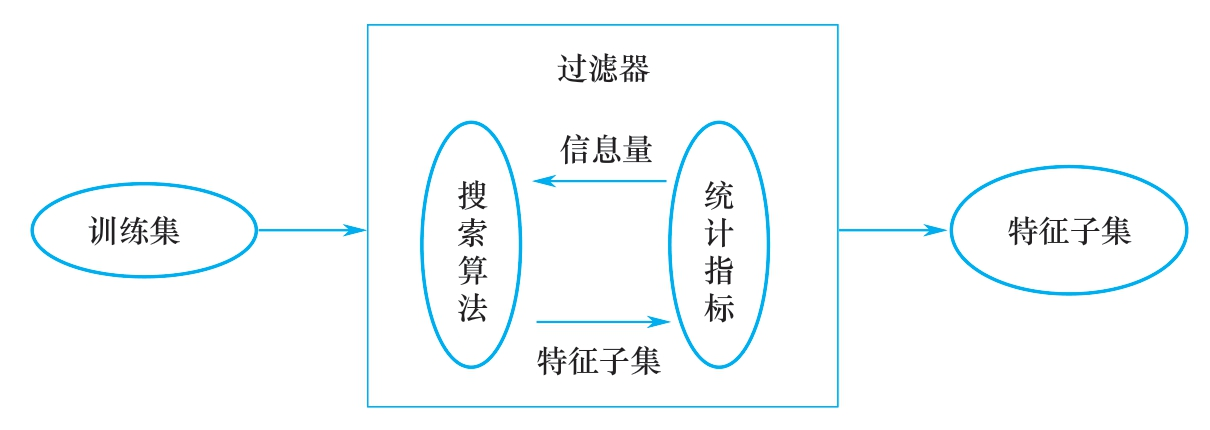
過濾技術對特徵進行預處理,以除去那些不太可能對模型有用處的特徵。例如,我們可以計算出每個特徵與響應變數之間的相關性或互資訊,然後過濾掉那些在某個閾值之下的特徵。過濾技術的成本比下面描述的打包技術低廉得多,但它們沒有考慮我們要使用的模型,因此,它們有可能無法為模型選擇出正確的特徵。我們最好謹慎地使用預過濾技術,以免在有用特徵進入到模型訓練階段之前不經意地將其刪除。
2)打包方法、封裝器法、Wrapper
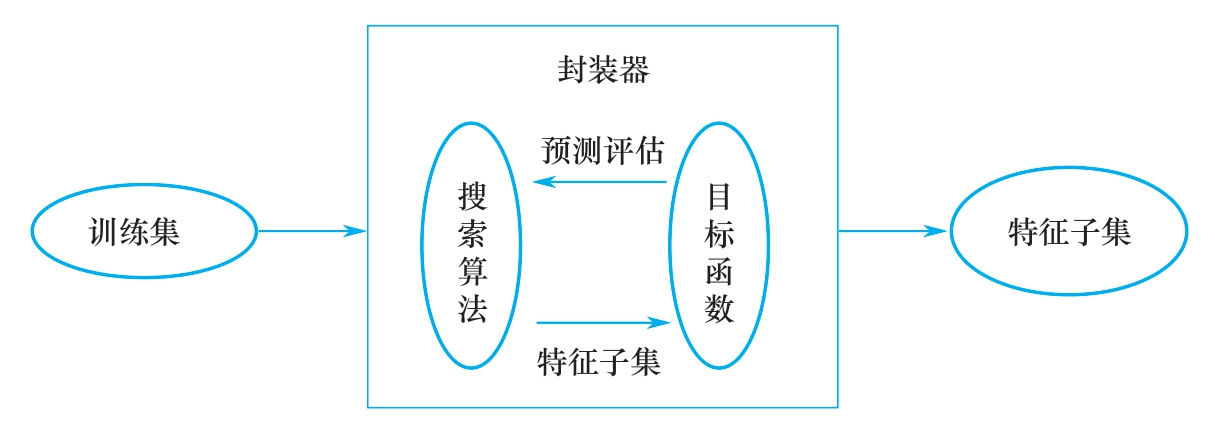
這些技術的成本非常高昂,但它們可以試驗特徵的各個子集,這意味著我們不會意外地刪除那些本身不提供什麼資訊但和其他特徵組合起來卻非常有用的特徵。打包方法將模型視為一個能對推薦的特徵子集給出合理評分的黑盒子。它們使用另外一種方法迭代地對特徵子集進行優化。
3)嵌入式方法、Embedded
這種方法將特徵選擇作為模型訓練過程的一部分。例如,特徵選擇是決策樹與生俱來的一種功能,因為它在每個訓練階段都要選擇一個特徵來對樹進行分割。另一個例子是ℓ1 正則項,它可以添加到任意線性模型的訓練目標中。 ℓ1 正則項鼓勵模型使用更少的特徵,而不是更多的特徵,所以又稱為模型的稀疏性約束。嵌入式方法將特徵選擇整合為模型訓練過程的一部分。它們不如打包方法強大,但成本也遠不如打包方法那麼高。與過濾技術相比,嵌入式方法可以選擇出特別適合某種模型的特徵。從這個意義上說,嵌入式方法在計算成本和結果品質之間實現了某種平衡。
4.4.特徵變換、特徵轉換
- 主成分分析PCA
- 線性判別分析LDA
4.5.特徵學習-以AI促AI
- 受限玻爾茲曼機 RBM
- 伯努利受限玻爾茲曼機BernoulliRBM
- 學習文本特徵:
- Word2vec
- GloVe
五、建模(Modeling)
5.1.選擇建模技術
自己生成了一張思維導圖:
點擊即可下載
5.2.生成測試設計
略,可參照
點擊以上鏈接即可下載!!!
5.3.建立模型
略,可參照
點擊以上鏈接即可下載!!
5.4.評估模型
略,可參照
點擊以上鏈接即可下載!!
六、評價(Evaluation)
略,可參照
點擊以上鏈接即可下載!!
七、部署(Deployment)
略,可參照
點擊以上鏈接即可下載!!
數據科學交流群,QQ群號:189158789 ,歡迎各位對數據科學感興趣的小夥伴的加入!

