Document-level Neural Relation Extraction with Edge-oriented Graphs 論文閱讀
Background
-
論文動機
-
Entity relations can be better expressed through ==unique edge representations== formed as paths between nodes.(沒有依據啊…)
許多graph-based model 都是基於node, 文章發現entity 之間的relation,可以通過節點之間的路徑形成唯一的edge representation
entity之間的關係不唯一,為什麼要規定representation要唯一呢?
-
每一個target entity的mentions對於entity之間的relation是非常重要的
-
-
論文貢獻
- 本文提出了一種新穎的圖神經模型(==面向邊而非節點==),與現有的模型不同的是它專註於構造一種 unique 的節點和邊,將資訊encode到邊表示(edge representation)而不是節點表示(node representation);
- 基於多實例學習(multi-instance learning,MIL)學習句子內和句子間的關係;
- 模型**==完全不依賴句法依賴工具==**(也就不會帶來因為工具的誤差帶來的噪音問題),可以有效編碼文檔級別的關係依賴;
- 實驗發現,inter-sentence 關係檢測的結果對 intra-sentence 關係檢測任務是有益的;
-
背景
異質網路:根據不同的邊來區分網路的類型;
同質網路:雖節點不同,邊的類型不同,但是把所有的節點當作同質關係進行處理,利用attention或者其他的方式自動進行區分。
Model
TASK definition: 給定標註好的document(entity與mentions),目標是抽取出所有entity pair的relation。

-
Sentence Encoding Layer
BiLSTM: The output of the encoder results in contextualized representations for each word of the input sentence.
-
Graph Layer
The contextualized word representations from encoder are used to construct a document-level graph structure. 來自編碼器的context表示被用來構建文檔級圖結構。
-
Node construction (三種不同類型的節點構造)
在EoG模型中,有三種node: mention node、entity node、sentence node。
mention node:所有entity的mentions的集合。每一個mention node的representation是此mention的所有word embedding的平均;entity node:所有entity的集合,每一個entity node的representation是該entity所有的mentions的平均;sentence node:所有sentence的集合,每一個sentence node是該sentence中所有word embedding的平均。
除此之外,我們為了區別不同類型的node,還給每一個node的representation上concat對應類型的node embedding t。
-
mention node
\mathbf{n}_{m}=\left[\operatorname{avg}_{w_{i} \in m}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{m}\right]
-
entity node
\mathbf{n}_{e}=\left[\operatorname{avg}_{w_{i} \in e}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{e}\right]
-
sentence node
\mathbf{n}_{s}=\left[\operatorname{avg}_{w_{i} \in s}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{s}\right]
-
-
Edge construction 不同的節點根據不同的性質生成不同種類的邊
上文的三種節點類型 邊的類型有
種 即 [MM, MS, ME, SS, ES, EE ] 六種, mention-mention(MM)、mention-entity(ME)、mention-sentence(MS)、entity-sentence(ES)、sentence-sentence(SS)。
==Using heuristic rules (啟發式規則)that stem from(源自) the natural associations between the elements of a document==(這個是怎麼做到呢?)
其中,The elements of a document: mentions, entities, and sentence.
Connections between nodes are based on Pre-defined document-level interactions:
-
MM :更好表達共指資訊,還有mention之間的交互,除了基本資訊之外還加入了 上下文資訊 context 和 距離資訊 (distance embedding associated with the distance between the two mentions):
x_{MM}=[n_{m_i};n_{m_j};c_{m_i,m_j};d_{m_i,m_j}]
x_{MM}表示的是對於mention pair (m_i,m_j)的 MM edge,;
當i=1,j=2,有x_{MM}=[n_{m_1};n_{m_2};c_{m_1,m_2};d_{m_1,m_2}];
上下文資訊:主要是應對類似it這種指代方法,否則不好推斷此類節點的表達;其中 a_i表示sentence的第i個word對此mention pair的重要性程度,也就是attention weight.
\alpha_{k,i}=n^T_{m_k}w_i \\ a_{k,i}=\frac{exp(\alpha_{k,i})}{\sum_{j\in[1,n],j\not\in m_k}exp(\alpha_{k,j})} \\ a_i=(a_{1,i}+ a_{2,i})/2 \\ c_{m_1,m_2}=H^Ta \\ k=\{1,2\}
-
MS: 將mention與此mention所在的sentence node進行連接;
-
**ME: **連接所有的mention與其對應的entity;
-
SS: 將所有的sentence node進行連接,以獲得non-local information.更好的表達在長距離上的依賴關係,相比mention,句子的數目少很多,在整體上尋找相關性;
\mathrm{x}_{\mathrm{SS}}=\left[\mathrm{n}_{s_i} ; \mathrm{n}_{s_j}; \mathrm{d}_{s_i,s_j}\right]
We connect all sentence nodes in the graph.
-
ES: 如果一個sentence中至少存在一個entity的mention,那麼我們將sentence node與entity node進行連接;
\mathrm{x}_{\mathrm{MS}}=\left[\mathrm{n}_{e} ; \mathrm{n}_{s}\right]
-
EE:
無論我們建立什麼類型的邊節點關係 最終的目的都是尋找 EE 之間是否存在關係;異構的邊應該統一到相同的表達中: 我們最終目的是提取出entity pair的relation,所以我們對所有的edge representation都做一個線性變換,從而讓其維度一致
\mathbf{e}_{z}^{(1)}=\mathbf{W}_{z} \mathbf{x}_{z}
其中,z \in[\mathrm{MM}, \mathrm{MS}, \mathrm{ME}, \mathrm{SS}, \mathrm{ES}], \mathbf{e}_{z}^{(1)} is an edge representation of length 1;
把不同邊的類型根據不同的矩陣轉換映射到相同的空間當中來進行後續的推導;
-
-
-
Inference Layer
由於我們沒有直接的EE edge,所以我們需要得到entity之間的唯一路徑的表示,來產生EE edge的representation。這裡使用了two-step inference mechanism來實現這一點。
-
The first step: 利用中間節點 k 在兩個節點 i 和 j 之間產生一條路徑,如下:
f\left(\mathbf{e}_{i k}^{(l)}, \mathbf{e}_{k j}^{(l)}\right)=\sigma\left(\mathbf{e}_{i k}^{(l)} \odot\left(\mathbf{W} \mathbf{e}_{k j}^{(l)}\right)\right)
-
The second step: 將原始edge(如果存在的話)與新產生的edge進行聚合,如下:
e^{(2l)}_{ij}=\beta e^{(2l)}_{ij}+(1-\beta)\sum_{k\not=i,j}f(e^{(l)}_{ik},e^{(l)}_{kj})
重複上述兩步N次,我們就可以得到比較充分混合的EE edge。通常情況下,\beta
==實際上,這一步就是為了解決logical reasoning。==
-
-
Classification Layer
這裡使用softmax進行分類,因為實驗所使用的兩個數據集其實都是每一個entity pair都只有一個relation。具體公式:
y=softmax(W_ce_{EE}+b_c)
Experiment
-
數據集: CDR、GDA
-
實驗結果:
EoG(Full): 全連接;
The graph node all connected each other, including the E node.
EoG(NoInf): 取消推理模組;
No inference model, where the iterative algorithm is ignored.
EoG(Sen): 單句內訓練,而非文檔;
Trained on sentence instead of document.
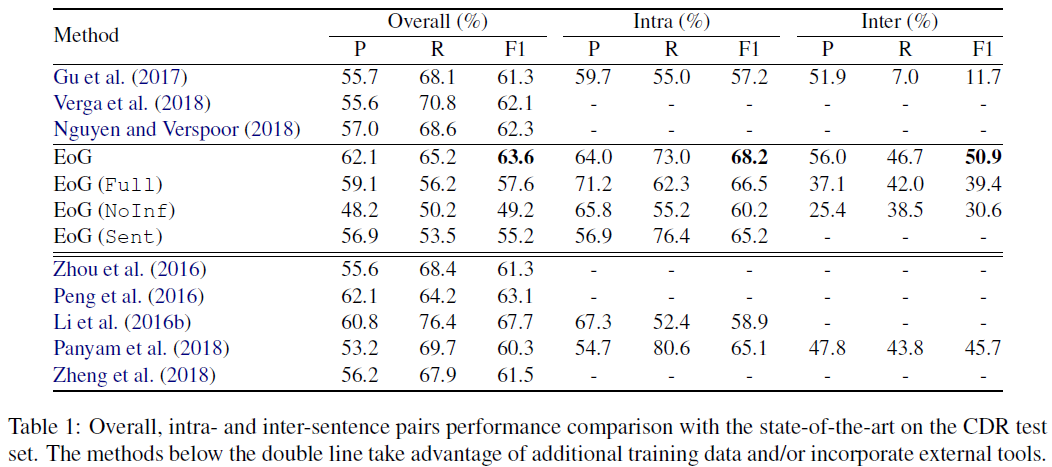


- 分析與討論

SS_{direct}:只連接相接的sentence node(順序連接)
SS_{direct} 只能捕獲到局部的資訊,收斂速度慢,同時也證明了句子間資訊抽取的有效性;
結論:SS 僅需要更少的推理環節就可以達到收斂的效果;

當entity pair之間相差4句以上時,EoG(full)結果明顯要好,這說明原始的EoG忽略了一些重要節點之間的交互資訊,那麼能不能讓模型自動選擇哪些節點要交互,哪些節點不要交互呢?(在LSR就是這麼做的)除此之外,作者還對不同的component進行了消融實驗。如下:

去掉SS對結果影響巨大,這說明對於document-level RE,提取inter-sentence之間的交互資訊是非常重要的,另外,MM似乎對結果影響最小,但是我認為MM對於entity pair的relation identification是非常重要的,只是EoG裡面構造的方式不對,在之後的GAIN模型裡面,可以看到MM對結果提升巨大,當然構建方式不一樣。


