redis集群
redis5之前集群搭建需要ruby環境,redis5之後就不需要了,只用redis-cli就可以創建集群了,本文redis版本:5.0.4
1.前期回顧
前面說了redis的主從複製可以保證數據容災,就是主節點壞了,從節點中也保存著完整數據,不會造成數據丟失的情況;
然後又說了哨兵模式(sentinel),這個是在主從複製的基礎上增強了一下,當主節點壞了,從節點中就會選舉出來一個當作主節點,繼續對外提供服務,而不需要人為的去操作,這叫做保證自動故障轉移;
注意,哨兵的個數之前只配置了一個,其實可以配置多個,防止一個哨兵由於網路延遲等原因誤判了;多個哨兵的時候超過半數的哨兵覺得主節點掛了那麼就是主節點掛了,才會選舉新的主節點;
哨兵模式下,使用springboot去連接redis的時候,連接的哨兵節點哦!因為此時主節點的ip是不確定的,有興趣的可以自己測試;
2. redis單機版的缺陷
哨兵模式下,其實就可以適用於絕大多數公司的場景了,畢竟也沒有那麼多的用戶
但是對於比較大的公司,用戶數量賊多,然後並發量賊高,然後redis主節點只有一個,一下子就能將redis主節點打趴下了,然後哨兵重新推選新的主節點剛剛站起來,然後又一下子被打趴下了,不斷的重複直至所有的redis節點都被打趴下了,最終所有請求都來到資料庫,資料庫也掛了….這也就是單節點並發壓力的問題
而且只有單節點的話,redis持久化數據越來越多,直至最後持久化了TB級別的數據,其實是比較誇張的
所以我們更希望能有多個redis主節點伺服器可以提供服務,每個主節點有從節點,而且還有有類似之前說的哨兵機制,那麼持久化的數據能大概均分到各個伺服器,而且可用性也有,單節點並發和磁碟壓力也會大大的緩解
3 redis集群(cluster)說明
集群就類似下面這個圖,集群中三個節點提供服務,三個節點都是主節點,同時三個節點都有從節點;
在集群模式下,主從節點自動的會有哨兵功能,即主節點掛了,從節點就會頂上;
下面的這種,redis持久化的數據可以大概的平均分成三份,分別存到每個節點中,所以,每個節點中存的數據是不一樣的!!!
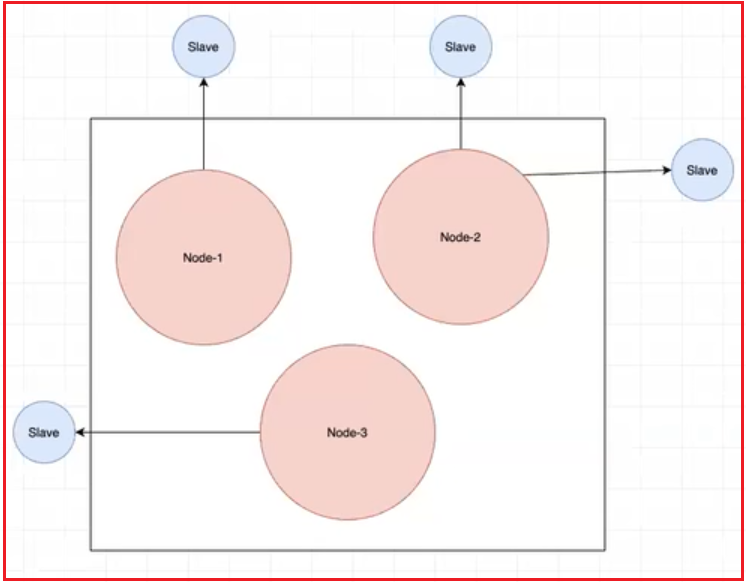
那麼問題來了,一個集群中有那麼多節點,我們如果要向裡面存數據,那麼怎麼選擇節點呢? 只有先選擇了節點然後才能往這個節點中存入數據
例如set a 1,那麼應該怎麼向集群中存呢?
原理:類似於java中的hashmap,如果我有一個容量為16383的數組,分成三份,上面節點node-1 中管理的是0-5461的位置,node-2管理的是5462-10922的位置,然後node-3管理的是10923-16383的位置
然後a首先經過hash再對16383取余,得到的結果肯定是在0-16383之間的某個數字(在redis中就叫做CRC16演算法),然後根據這個結果所在的位置就能確定放在哪個節點了
比如上面的set a 1 ,假設a經過CRC16演算法得到的結果是7000,那就肯定丟到node-2裡面去了,還是比較容易的,並且相同的鍵,經過CRC16演算法,每次都是一樣的,所以當使用get a 的時候,a經過CRC16之後,結果也是7000,也就到node-2中去取數據了
這實現了存的時候在哪個節點存,取得時候肯定就在那個節點去取;
4 redis在linux中簡單使用
之前單機版都是windows中配置的,現在我們在linux中玩一下
4.1 安裝redis源碼
redis中文網 根據提示下載redis源碼,我把安裝命令放在下面,注意下載你想要的版本;
#下載,解壓,編譯: wget //download.redis.io/releases/redis-5.0.4.tar.gz tar xzf redis-5.0.4.tar.gz cd redis-5.0.4 make #二進位文件是編譯完成後在src目錄下. 運行如下: src/redis-server #你能使用Redis的內置客戶端進行進行redis程式碼的編寫: $ src/redis-cli redis> set foo bar OK redis> get foo "bar"
你在執行make的時候應該會出錯,因為redis是c語言寫的,所以需要有c語言的編譯環境,使用命令:yum install -y gcc
然後進入解壓目錄執行: make MALLOC=libc
繼續在解壓目錄下執行:make install PREFIX=/usr/local/redis /usr/local/redis這個目錄表示你的redis需要安裝的位置,自己定義,後續的啟動redis就是在/usr/local/redis/bin
進入剛剛redis的安裝目錄,執行命令:./redis-server
可以發現使用linux安裝其實比較麻煩,而且如果你的運氣不好,在使用yum安裝gcc的時候也會有些奇葩的問題,慢慢踩坑吧!
4.2 啟動redis哨兵
在前面我們安裝了redis的源碼包和編譯後的redis,我們還需要redis服務端啟動時候的配置文件,在源碼包下,我們需要複製到編譯後的redis目錄下:cp /usr/local/java/redis/redis-5.0.4/redis.conf /usr/local/redis/bin 這個命令的前一個目錄需要改成你自己的redis源碼包的目錄
由於我的redis版本比較新,所以redis編譯後的包中有redis-sentinel文件,就不需要去源碼包複製了(假設你的本目錄沒有這個redis-sentinel文件,你就需要去源碼包中的src目錄下將這個文件redis-sentinel給複製過來)
我們在當前bin目錄下新建一個sentinel.conf配置文件,加入下面一行
sentinel monitor mymaster 127.0.0.1 6379 1
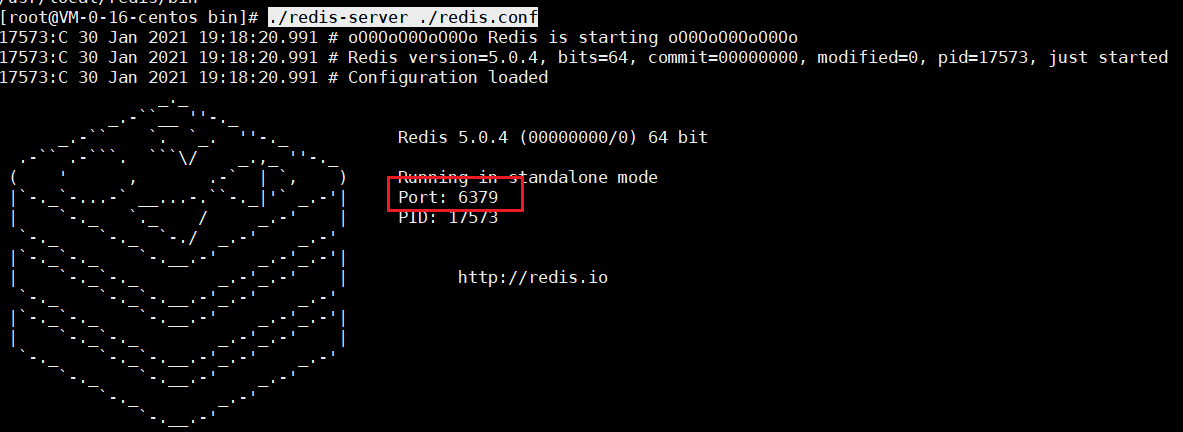
配置完畢,啟動redis服務端:./redis-server ./redis.conf
啟動哨兵節點:./redis-sentinel ./sentinel.conf
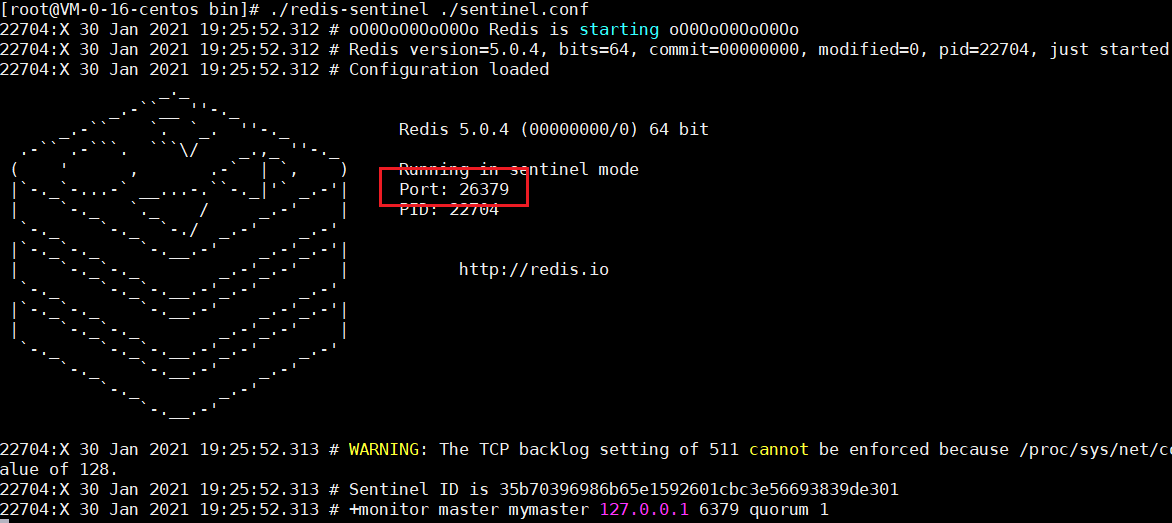
到這裡,說明我們redis配置很ok,當然你也可以自己配置一個從節點,跟window版本是一樣的,自己可以測試一下
5 redis集群搭建
5.1 提前須知
集群中的主從節點自帶哨兵功能,而且主節點必須是奇數,最低需要三個主節點
我這裡給每個主節點都配置一個從節點,三主三從,一共6個節點
我們設置5000,6000,7000為三個主節點,5001,6001,7001為三個從節點,注意,我們在集群中不能手動指定主節點和哪個從節點配對,這是隨機的!我們只能指定主節點
5.2 redis.conf配置文件修改
複製6份redis.conf配置文件,然後修改下面個地方:
port 6379 //redis服務端的埠 bind 0.0.0.0 //開啟遠程連接
daemonize yes //這裡表示redis服務端以守護進行開啟,也就是開啟redis的時候,是在後台運行的
dbfilename dump.rdb //rdb持久化文件名需要修改
appendfilename "appendonly.aof" //aof持久化文件名需要修改
appendonly yes //集群模式必須開啟aof持久化
dir . //持久化文件存放的目錄
cluster-enabled yes //開啟集群模式 cluster-config-file nodes-port.conf //集群節點配置文件 cluster-node-timeout 5000 //集群節點超時時間,單位毫秒
改完之後的文件放入下面的各自對應的目錄中:
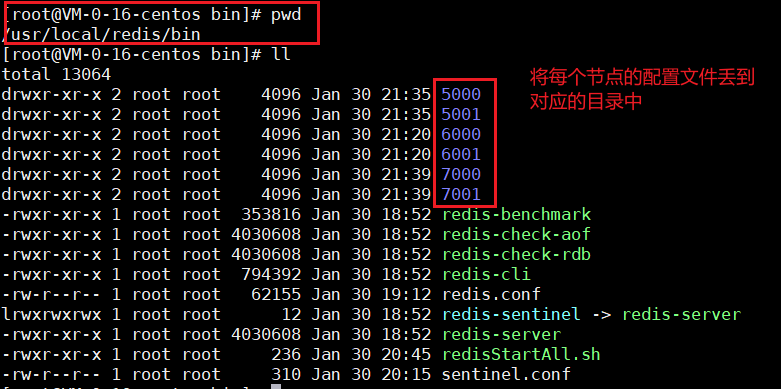
我們以5000埠為例,修改上面的幾條,其他的配置文件根據各自的埠進行修改:
port 5000 bind 0.0.0.0 daemonize yes dbfilename dump5000.rdb appendfilename "appendonly5000.aof" appendonly yes
dir ./5000
cluster-enabled yes cluster-config-file nodes-5000.conf cluster-node-timeout 5000
改了好半天,終於改完了6個配置文件,然後在bin目錄下編寫一個啟動所有節點的腳本: vim redisStartAll.sh
#! /bin/bash ./redis-server ./5000/redis5000.conf ./redis-server ./5001/redis5001.conf ./redis-server ./6000/redis6000.conf ./redis-server ./6001/redis6001.conf ./redis-server ./7000/redis7000.conf ./redis-server ./7001/redis7001.conf
給啟動腳本添加可執行許可權: chmod +x redisStartAll.sh
想要啟動所有redis節點,在bin目錄下直接執行: sh ./redisStartAll.sh

5.3 創建集群
我們將所有的節點啟動完畢之後,雖然說都是節點,但都是各自隔離的,沒有什麼聯繫,我們需要將這些節點設置一下;(還是強調一下,redis5.x版本的集群模式不需要ruby環境,直接使用本地的reids-cli就行了)
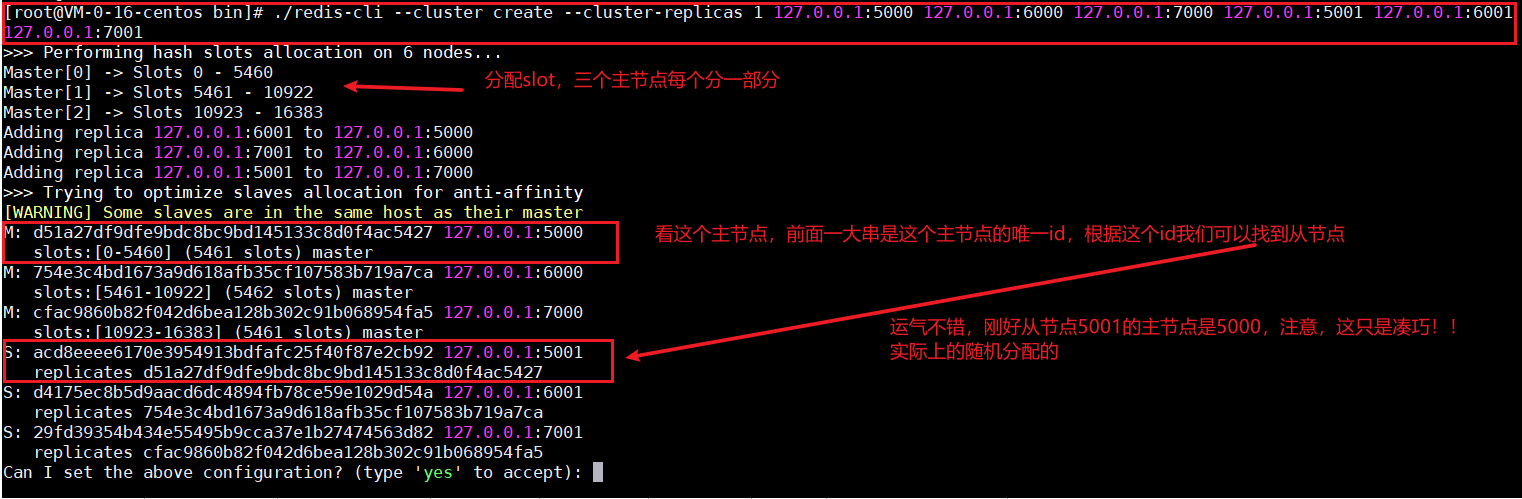
在bin目錄下執行:./redis-cli –cluster create –cluster-replicas 1 127.0.0.1:5000 127.0.0.1:6000 127.0.0.1:7000 127.0.0.1:5001 127.0.0.1:6001 127.0.0.1:7001
命令說明,下圖所示;
到這裡,肯定有人想了,我要是有的主節點要有兩個從節點呢?推薦看看這個老哥的部落格,對這個命令解釋得很詳細

執行命令之後,輸入「yes」表示保存這個集群,如果你對當前集群不滿意,也可以重新執行一下上述命令
集群搭建完畢,我們只需要連接任意一個節點就能看看集群中節點的狀態:./redis-cli -p 6000 cluster nodes

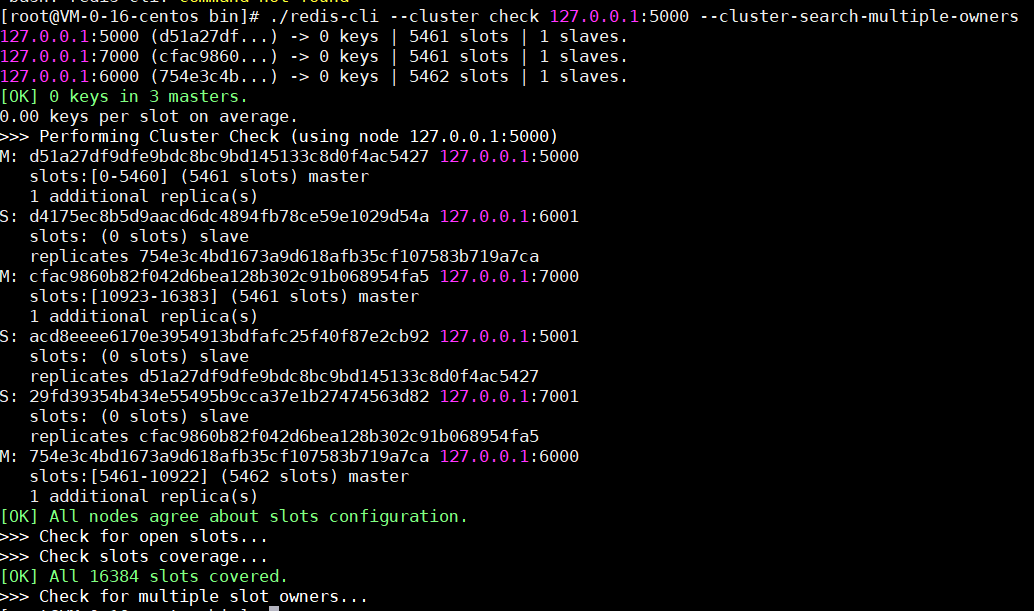
如果想看到集群中各個節點更詳細的資訊,也可以使用這個:./redis-cli –cluster check 127.0.0.1:5000 –cluster-search-multiple-owners
5.4 測試集群
我們關掉主節點5000,然後等幾秒鐘

然後再啟動5000這個節點,我們發現5000節點成了5001的從節點了

我們隨便連接一個節點放入數據:./redis-cli -p 5000 -c 注意要加上 -c 參數啊,這表示連接集群客戶端

從集群中取數據

6. 總結
到這裡redis的基礎知識就說完了,最開始說的就只有一個節點的單機結構,弊端是容災性差,這個節點壞了就就真的壞了,裡面的數據還有可能丟失;
然後就說了解決容災行的方案,即使用主從複製結構,但是主從當主節點壞了之後,雖然說數據肯定保存了一份在從節點那裡,但是需要人為的去重新部署redis
再進一步就是說了哨兵機制,有個哨兵(當然,哨兵可以配置多個)一直盯著我們的主節點,當主節點沒用了,就會自動的將從節點匯總選舉出來一個作為主節點,繼續向外提供服務
但是哨兵機制說到底還是單體架構,就會有單節點並發壓力的問題,只有一個主節點無法抗住並發壓力,而且所有數據都放在一台伺服器中,隨著redis用的時間越來越長,使得磁碟的空間也會很有壓力
解決方案就是集群方式,可以有多個主節點共同組成一個集群向外界提供服務,數據大概就是均分成多份分別放在這些主節點中,這緩解了磁碟壓力;而且每個主節點有多個從節點,且具備有主從複製+哨兵的作用,當主節點中數據有變化,就會同步到它對應的從節點中,提高了容災性,然後主節點掛了,從節點還能頂上,提高了故障轉移能力;
其實在集群創建完了之後,我們後續還可以向其中添加主節點和從節點的,這個就很容易了!


