用動圖講解分散式 Raft
一、Raft 概述
Raft 演算法是分散式系統開發首選的共識演算法。比如現在流行 Etcd、Consul。
如果掌握了這個演算法,就可以較容易地處理絕大部分場景的容錯和一致性需求。比如分散式配置系統、分散式 NoSQL 存儲等等,輕鬆突破系統的單機限制。
Raft 演算法是通過一切以領導者為準的方式,實現一系列值的共識和各節點日誌的一致。
二、Raft 角色
2.1 角色
跟隨者(Follower):普通群眾,默默接收和來自領導者的消息,當領導者心跳資訊超時的時候,就主動站出來,推薦自己當候選人。
候選人(Candidate):候選人將向其他節點請求投票 RPC 消息,通知其他節點來投票,如果贏得了大多數投票選票,就晉陞當領導者。
領導者(Leader):霸道總裁,一切以我為準。處理寫請求、管理日誌複製和不斷地發送心跳資訊,通知其他節點「我是領導者,我還活著,你們不要」發起新的選舉,不用找新領導來替代我。
如下圖所示,分別用三種圖代表跟隨者、候選人和領導者。

三、單節點系統
3.1 資料庫伺服器
現在我們想像一下,有一個單節點系統,這個節點作為資料庫伺服器,且存儲了一個值為 X。

3.2 客戶端
左邊綠色的實心圈就是客戶端,右邊的藍色實心圈就是節點 a(Node a)。Term 代表任期,後面會講到。

3.3 客戶端向伺服器發送數據
客戶端向單節點伺服器發送了一條更新操作,設置資料庫中存的值為 8。單機環境下(單個伺服器節點),客戶端從伺服器拿到的值也是 8。一致性非常容易保證。

3.4 多節點如何保證一致性?
但如果有多個伺服器節點,怎麼保證一致性呢?比如有三個節點:a,b,c。如下圖所示。這三個節點組成一個資料庫集群。客戶端對這三個節點進行更新操作,如何保證三個節點中存的值一致?這個就是分散式一致性問題。Raft 演算法就是來解決這個問題的。當然還有其他協議也可以保證,本篇只針對 Raft 演算法。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-kROgpTbp-1611583074646)(//cdn.jayh.club/blog/20210122/tL0NtaVcAcei.gif)]
在多節點集群中,在節點故障、分區錯誤等異常情況下,Raft 演算法如何保證在同一個時間,集群中只有一個領導者呢?下面就開始講解 Raft 演算法選舉領導者的過程。
四、選舉領導過程
4.1 初始狀態
初始狀態下,集群中所有節點都是跟隨者的狀態。
如下圖所示,有三個節點(Node) a、b、c,任期(Term)都為 0。
4.2 成為候選者
Raft 演算法實現了隨機超時時間的特性,每個節點等待領導者節點心跳資訊的超時時間間隔是隨機的。比如 A 節點等待超時的時間間隔 150 ms,B 節點 200 ms,C 節點 300 ms。那麼 a 先超時,最先因為沒有等到領導者的心跳資訊,發生超時。如下圖所示,三個節點的超時計時器開始運行。
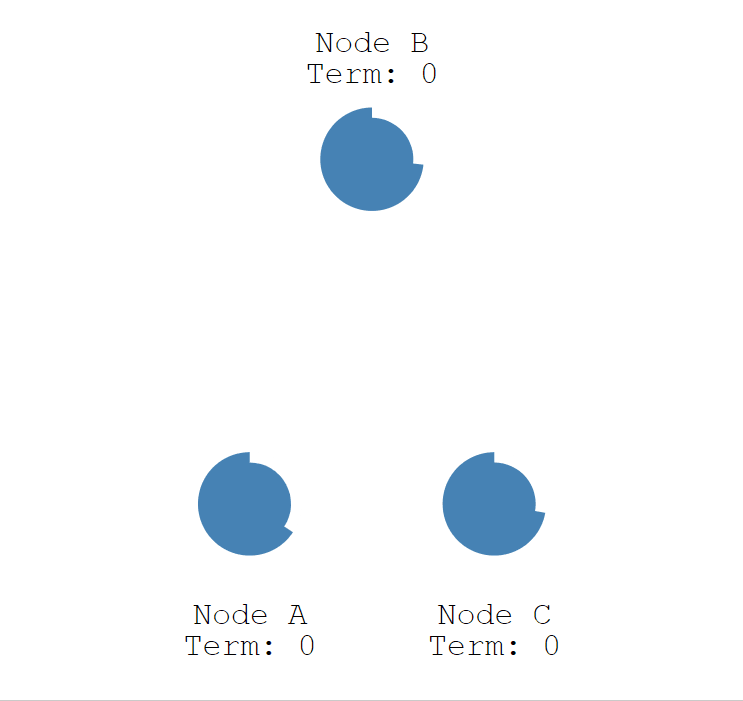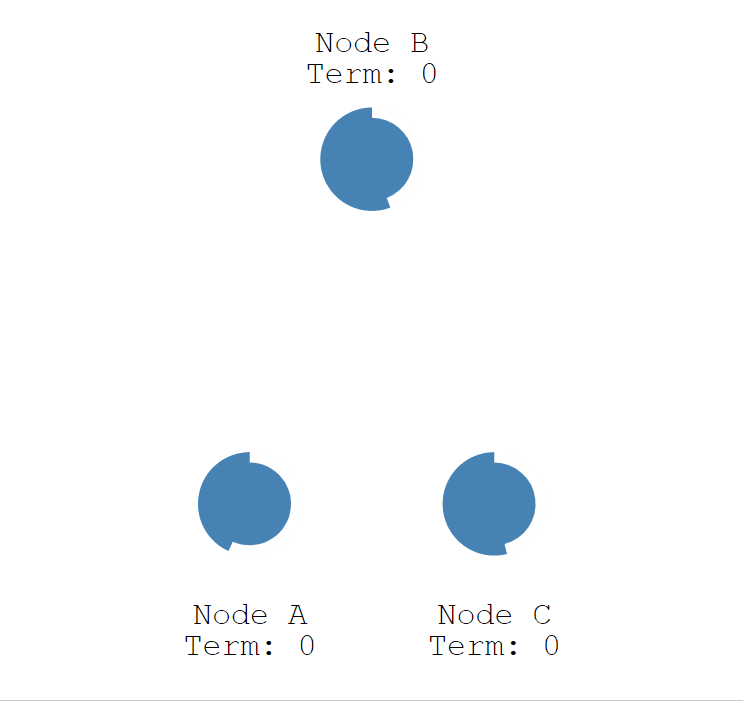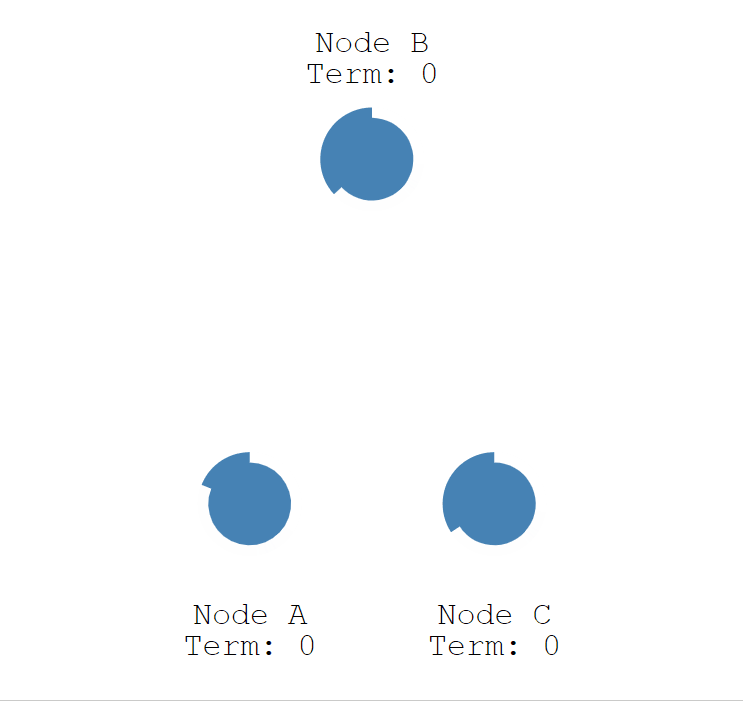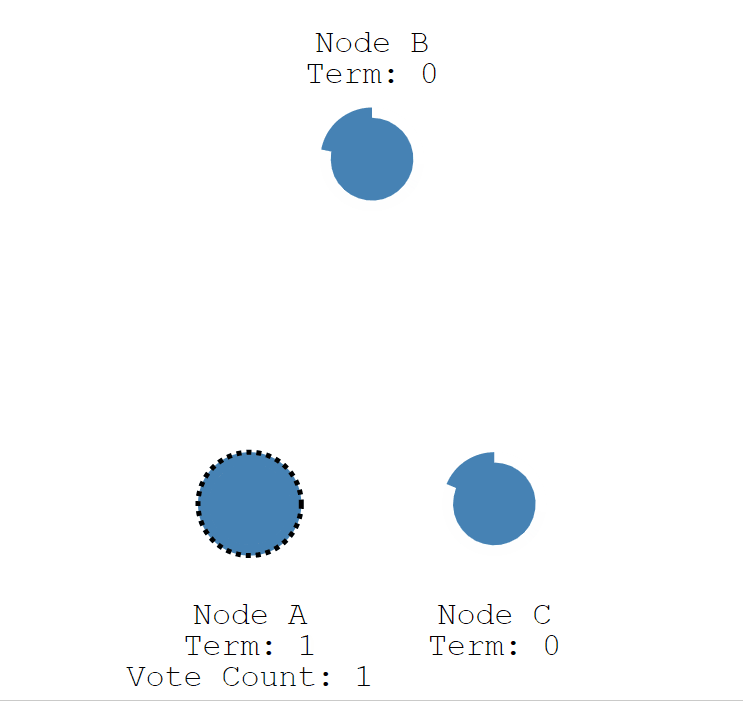
當 A 節點的超時時間到了後,A 節點成為候選者,並增加自己的任期編號,Term 值從 0 更新為 1,並給自己投了一票。
- Node A:Term = 1, Vote Count = 1。
- Node B:Term = 0。
- Node C:Term = 0。
4.3 投票
我們來看下候選者如何成為領導者的。
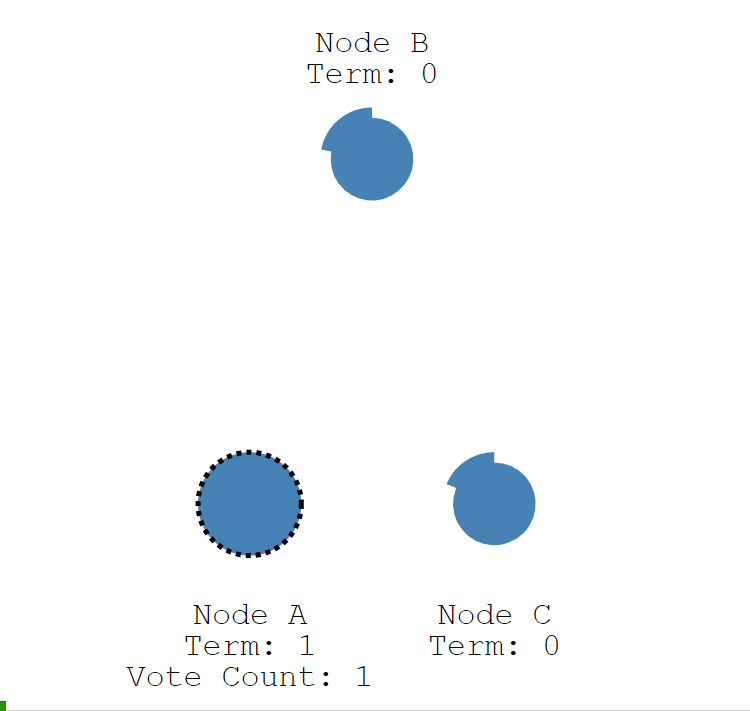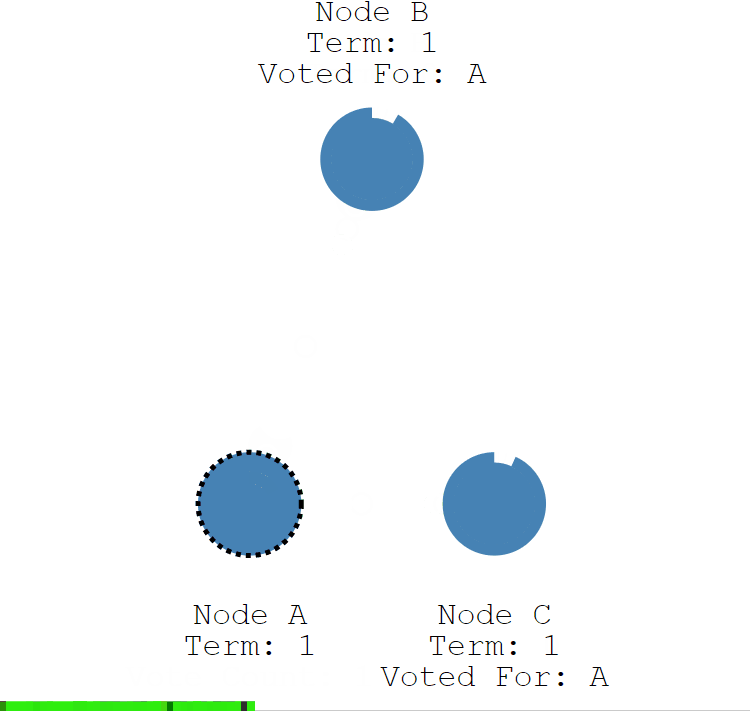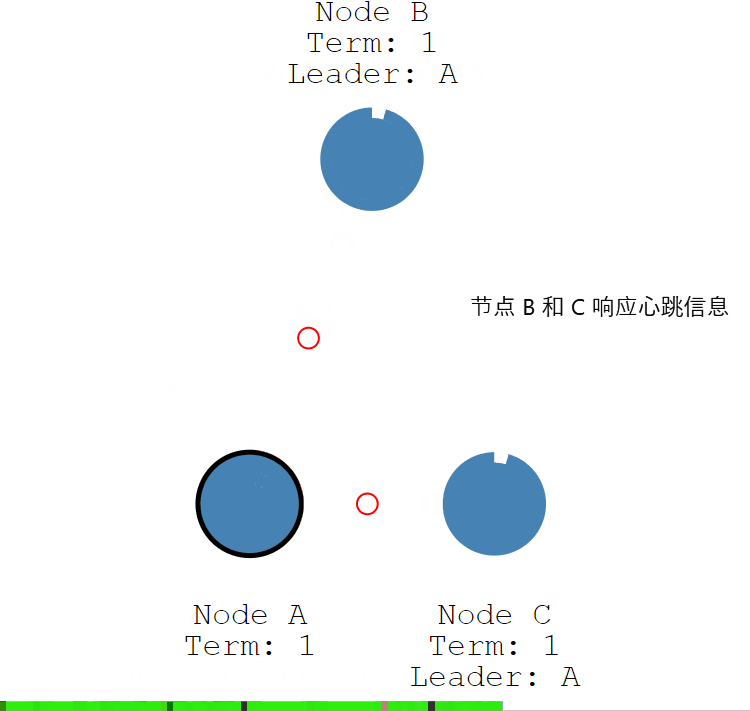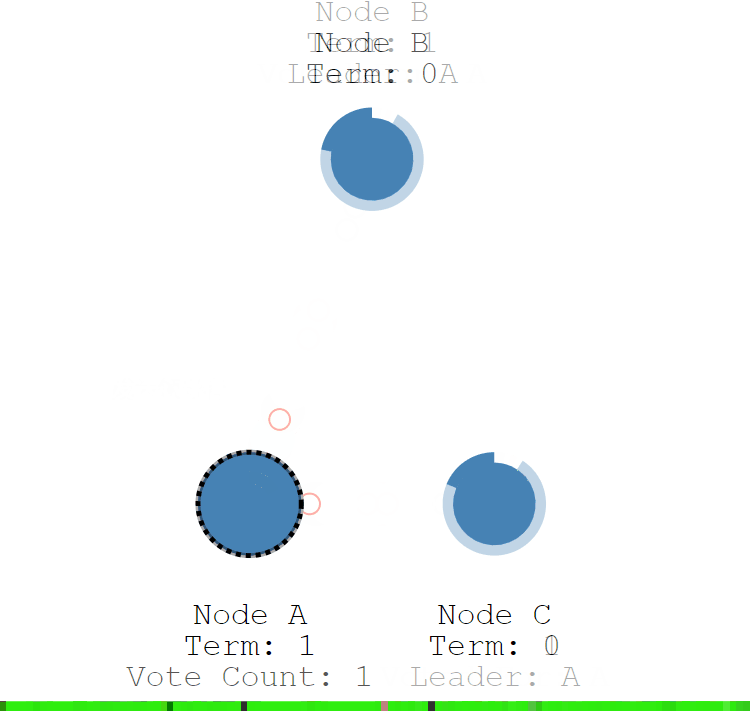
- 第一步:節點 A 成為候選者後,向其他節點發送請求投票 RPC 資訊,請它們選舉自己為領導者。
- 第二步:節點 B 和 節點 C 接收到節點 A 發送的請求投票資訊後,在編號為 1 的這屆任期內,還沒有進行過投票,就把選票投給節點 A,並增加自己的任期編號。
- 第三步:節點 A 收到 3 次投票,得到了大多數節點的投票,從候選者成為本屆任期內的新的領導者。
- 第四步:節點 A 作為領導者,固定的時間間隔給 節點 B 和節點 C 發送心跳資訊,告訴節點 B 和 C,我是領導者,組織其他跟隨者發起新的選舉。
- 第五步:節點 B 和節點 C 發送響應資訊給節點 A,告訴節點 A 我是正常的。
4.4 任期
英文單詞是 term,領導者是有任期的。
- 自動增加:跟隨者在等待領導者心跳資訊超時後,推薦自己為候選人,會增加自己的任期號,如上圖所示,節點 A 任期為 0,推舉自己為候選人時,任期編號增加為 1。
- 更新為較大值:當節點發現自己的任期編號比其他節點小時,會更新到較大的編號值。比如節點 A 的任期為 1,請求投票,投票消息中包含了節點 A 的任期編號,且編號為 1,節點 B 收到消息後,會將自己的任期編號更新為 1。
- 恢復為跟隨者:如果一個候選人或者領導者,發現自己的任期編號比其他節點小,那麼它會立即恢復成跟隨者狀態。這種場景出現在分區錯誤恢復後,任期為 3 的領導者受到任期編號為 4 的心跳消息,那麼前者將立即恢復成跟隨者狀態。
- 拒絕消息:如果一個節點接收到較小的任期編號值的請求,那麼它會直接拒絕這個請求,比如任期編號為 6 的節點 A,收到任期編號為 5 的節點 B 的請求投票 RPC 消息,那麼節點 A 會拒絕這個消息。
4.5 選舉規則
- 一個任期內,領導者一直都會領導者,直到自身出現問題(如宕機),或者網路問題(延遲),其他節點發起一輪新的選舉。
- 在一次選舉中,每一個伺服器節點最多會對一個任期編號投出一張選票,投完了就沒了。
4.6 大多數
假設一個集群由 N 個節點組成,那麼大多數就是至少 N/2+1。例如: 3 個節點的集群,大多數就是 2。
4.7 心跳超時
為了防止多個節點同時發起投票,會給每個節點分配一個隨機的選舉超時時間。這個時間內,節點不能成為候選者,只能等到超時。比如上述例子,節點 A 先超時,先成為了候選者。這種巧妙的設計,在大多數情況下只有一個伺服器節點先發起選舉,而不是同時發起選舉,減少了因選票瓜分導致選舉失敗的情況。
五、領導者故障
如果領導者節點出現故障,則會觸發新的一輪選舉。如下圖所示,領導者節點 B 發生故障,節點 A 和 節點 B 就會重新選舉 Leader。
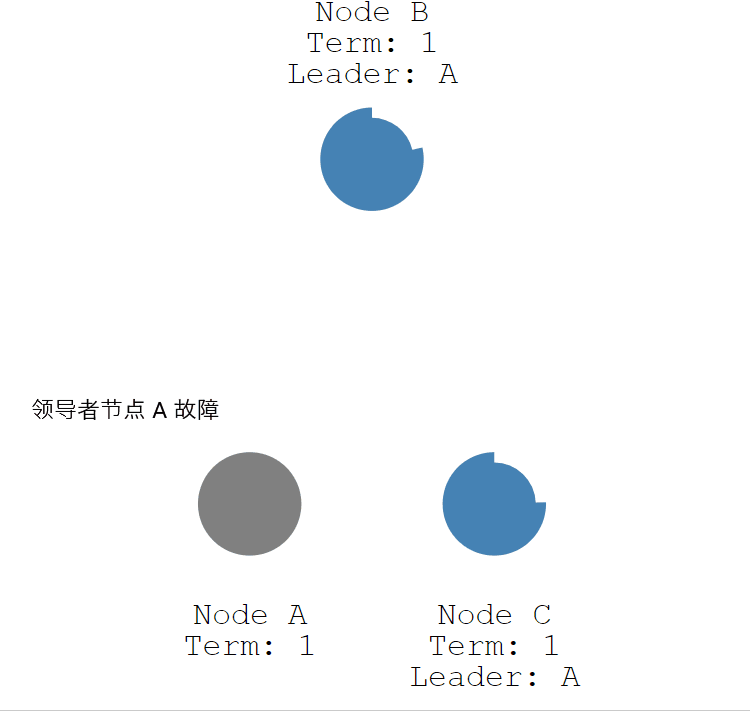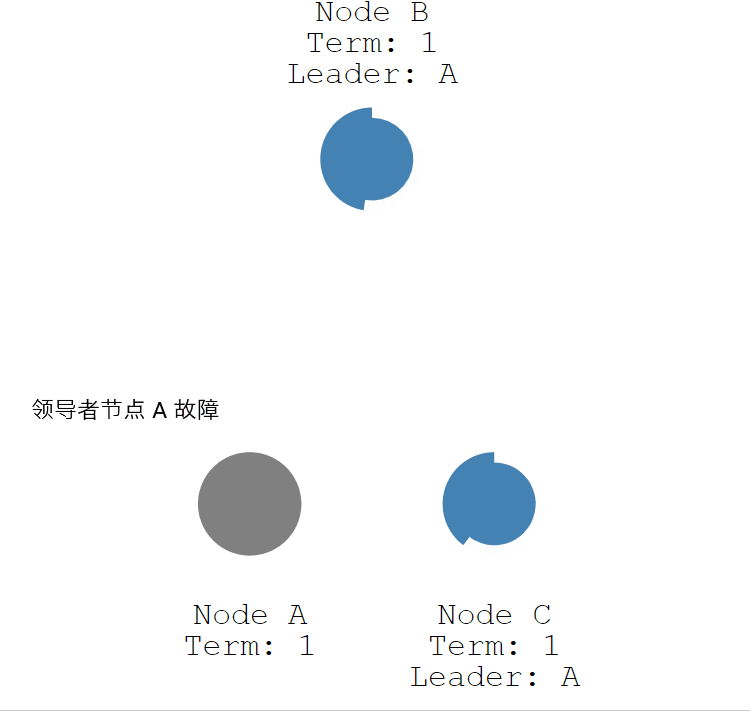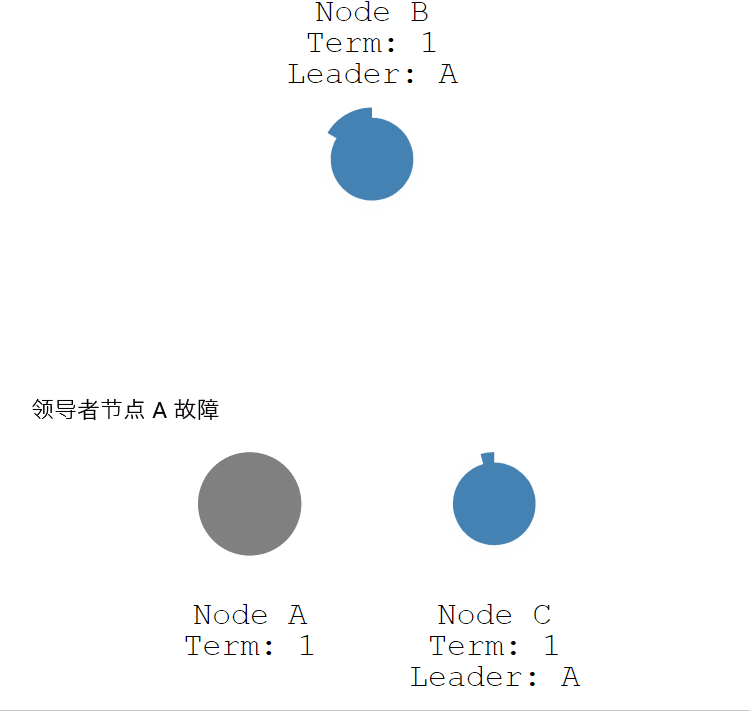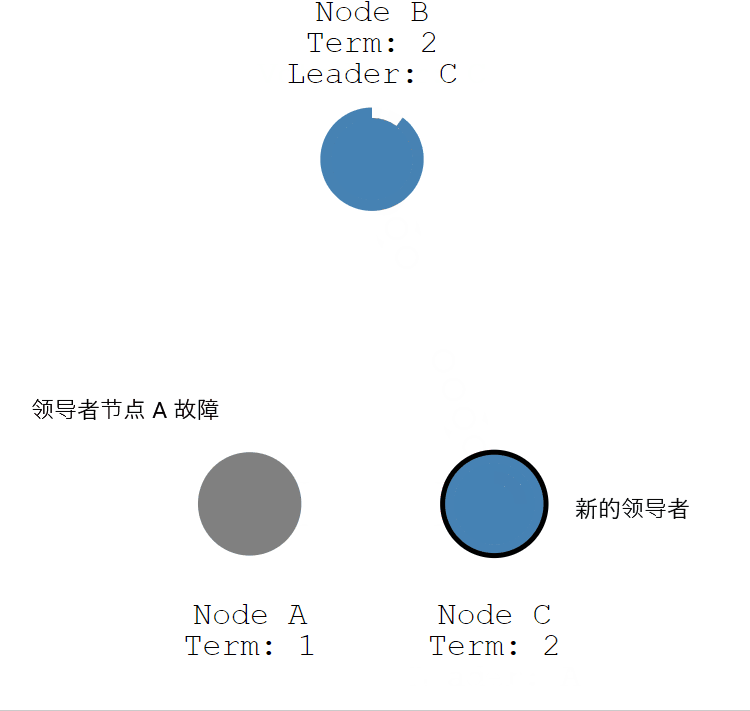
- 第一步 :節點 A 發生故障,節點 B 和節點 C 沒有收到領導者節點 A 的心跳資訊,等待超時。
- 第二步:節點 C 先發生超時,節點 C 成為候選人。
- 第三步:節點 C 向節點 A 和 節點 B 發起請求投票資訊。
- 第四步:節點 C 響應投票,將票投給了 C,而節點 A 因為發生故障了,無法響應 C 的投票請求。
- 第五步:節點 C 收到兩票(大多數票數),成為領導者。
- 第六步:節點 C 向節點 A 和 B 發送心跳資訊,節點 B 響應心跳資訊,節點 A 不響應心跳資訊。
總結
Raft 演算法通過以下幾種方式來進行領導選舉,保證了一個任期只有一位領導,極大減少了選舉失敗的情況。
- 任期
- 領導者心跳資訊
- 隨機選舉超時時間
- 先來先服務的投票原則
- 大多數選票原則
本篇通過動圖的方式來講解 Raft 演算法如何選舉領導者,更容易理解和消化。


