Redis 核心篇:唯快不破的秘密
天下武功,無堅不摧,唯快不破!
學習一個技術,通常只接觸了零散的技術點,沒有在腦海里建立一個完整的知識框架和架構體系,沒有系統觀。這樣會很吃力,而且會出現一看好像自己會,過後就忘記,一臉懵逼。
跟著「碼哥位元組」一起吃透 Redis,深層次的掌握 Redis 核心原理以及實戰技巧。一起搭建一套完整的知識框架,學會全局觀去整理整個知識體系。
系統觀其實是至關重要的,從某種程度上說,在解決問題時,擁有了系統觀,就意味著你能有依據、有章法地定位和解決問題。
Redis 全景圖
全景圖可以圍繞兩個緯度展開,分別是:
應用緯度:快取使用、集群運用、數據結構的巧妙使用
系統緯度:可以歸類為三高
- 高性能:執行緒模型、網路 IO 模型、數據結構、持久化機制;
- 高可用:主從複製、哨兵集群、Cluster 分片集群;
- 高拓展:負載均衡
Redis 系列篇章圍繞如下思維導圖展開,這次從 《Redis 唯快不破的秘密》一起探索 Redis 的核心知識點。
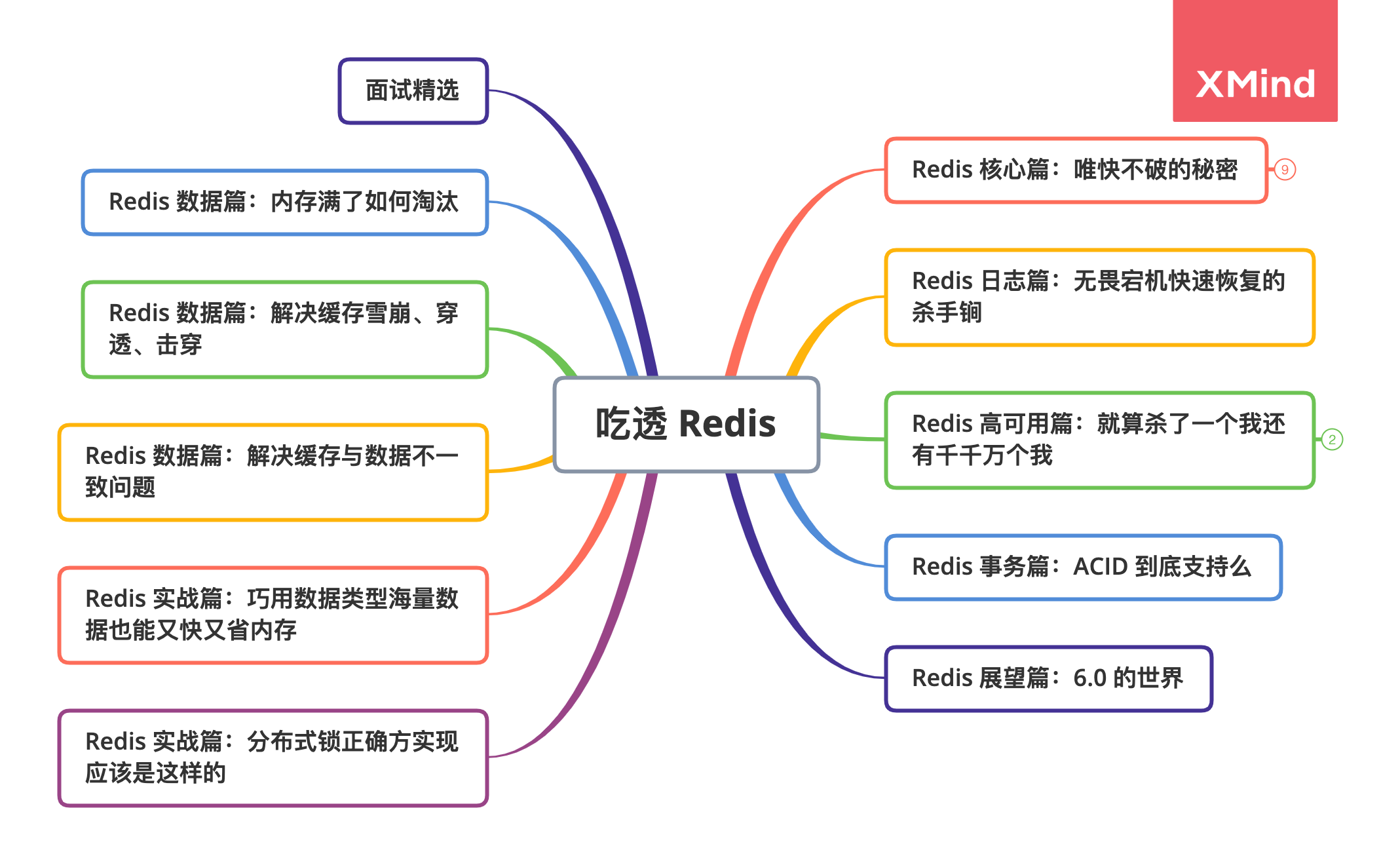
唯快不破的秘密
65 哥前段時間去面試 996 大廠,被問到「Redis 為什麼快?」
65 哥:額,因為它是基於記憶體實現和單執行緒模型
面試官:還有呢?
65 哥:沒了呀。
很多人僅僅只是知道基於記憶體實現,其他核心的原因模凌兩可。今日跟著「碼哥位元組」一起探索真正快的原因,做一個唯快不破的真男人!
Redis 為了高性能,從各方各面都進行了優化,下次小夥伴們面試的時候,面試官問 Redis 性能為什麼如此高,可不能傻傻的只說單執行緒和記憶體存儲了。
根據官方數據,Redis 的 QPS 可以達到約 100000(每秒請求數),有興趣的可以參考官方的基準程式測試《How fast is Redis?》,地址://redis.io/topics/benchmarks
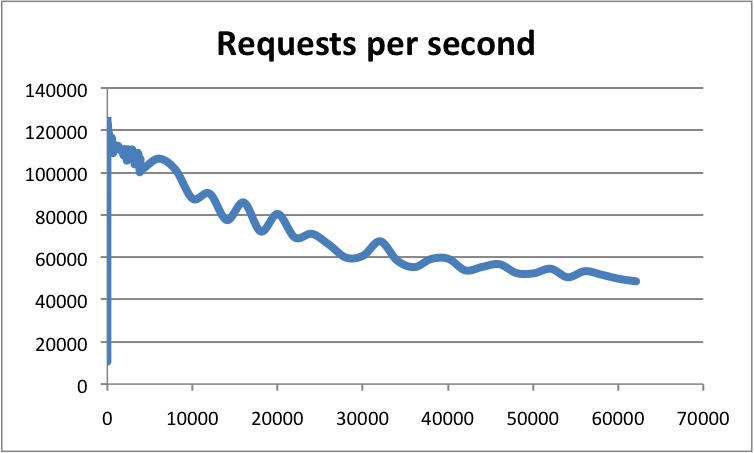
橫軸是連接數,縱軸是 QPS。此時,這張圖反映了一個數量級,希望大家在面試的時候可以正確的描述出來,不要問你的時候,你回答的數量級相差甚遠!
完全基於記憶體實現
65 哥:這個我知道,Redis 是基於記憶體的資料庫,跟磁碟資料庫相比,完全吊打磁碟的速度,就像段譽的凌波微步。對於磁碟資料庫來說,首先要將數據通過 IO 操作讀取到記憶體里。
沒錯,不論讀寫操作都是在記憶體上完成的,我們分別對比下記憶體操作與磁碟操作的差異。
磁碟調用棧圖
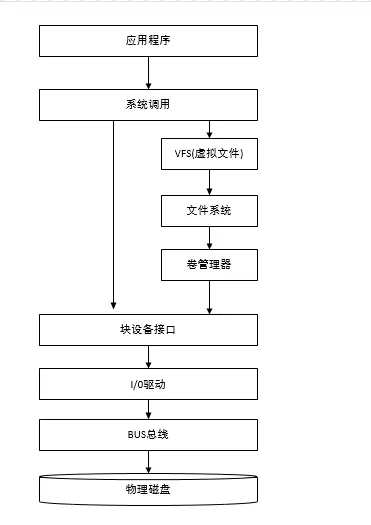
記憶體操作
記憶體直接由 CPU 控制,也就是 CPU 內部集成的記憶體控制器,所以說記憶體是直接與 CPU 對接,享受與 CPU 通訊的最優頻寬。
Redis 將數據存儲在記憶體中,讀寫操作不會因為磁碟的 IO 速度限制,所以速度飛一般的感覺!
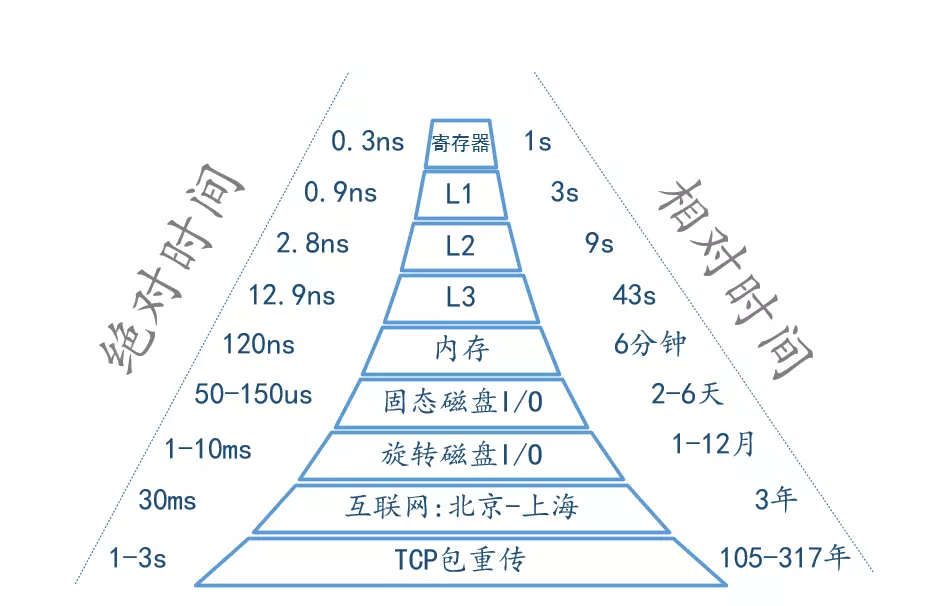
最後以一張圖量化系統的各種延時時間(部分數據引用 Brendan Gregg)
高效的數據結構
65 哥:學習 MySQL 的時候我知道為了提高檢索速度使用了 B+ Tree 數據結構,所以 Redis 速度快應該也跟數據結構有關。
回答正確,這裡所說的數據結構並不是 Redis 提供給我們使用的 5 種數據類型:String、List、Hash、Set、SortedSet。
在 Redis 中,常用的 5 種數據類型和應用場景如下:
- String: 快取、計數器、分散式鎖等。
- List: 鏈表、隊列、微博關注人時間軸列表等。
- Hash: 用戶資訊、Hash 表等。
- Set: 去重、贊、踩、共同好友等。
- Zset: 訪問量排行榜、點擊量排行榜等。
上面的應該叫做 Redis 支援的數據類型,也就是數據的保存形式。「碼哥位元組」要說的是針對這 5 種數據類型,底層都運用了哪些高效的數據結構來支援。
65 哥:為啥搞這麼多數據結構呢?
當然是為了追求速度,不同數據類型使用不同的數據結構速度才得以提升。每種數據類型都有一種或者多種數據結構來支撐,底層數據結構有 6 種。
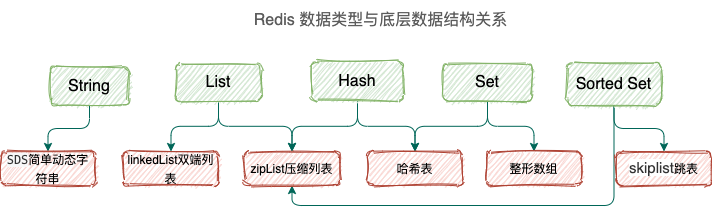
Redis hash 字典
Redis 整體就是一個 哈希表來保存所有的鍵值對,無論數據類型是 5 種的任意一種。哈希表,本質就是一個數組,每個元素被叫做哈希桶,不管什麼數據類型,每個桶裡面的 entry 保存著實際具體值的指針。
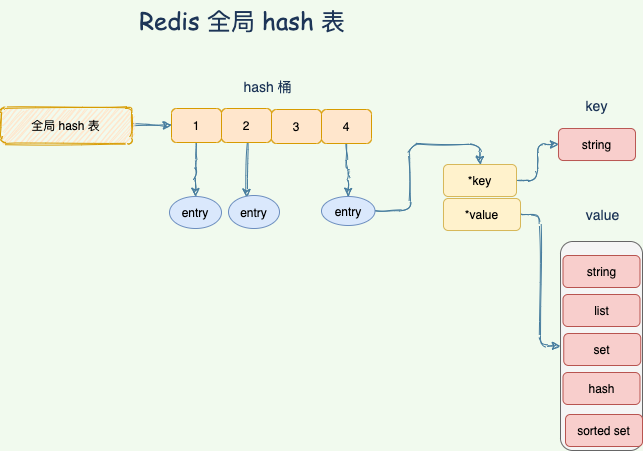
整個資料庫就是一個全局哈希表,而哈希表的時間複雜度是 O(1),只需要計算每個鍵的哈希值,便知道對應的哈希桶位置,定位桶裡面的 entry 找到對應數據,這個也是 Redis 快的原因之一。
那 Hash 衝突怎麼辦?
當寫入 Redis 的數據越來越多的時候,哈希衝突不可避免,會出現不同的 key 計算出一樣的哈希值。
Redis 通過鏈式哈希解決衝突:也就是同一個 桶裡面的元素使用鏈表保存。但是當鏈表過長就會導致查找性能變差可能,所以 Redis 為了追求快,使用了兩個全局哈希表。用於 rehash 操作,增加現有的哈希桶數量,減少哈希衝突。
開始默認使用 hash 表 1 保存鍵值對數據,哈希表 2 此刻沒有分配空間。當數據越來多觸發 rehash 操作,則執行以下操作:
- 給 hash 表 2 分配更大的空間;
- 將 hash 表 1 的數據重新映射拷貝到 hash 表 2 中;
- 釋放 hash 表 1 的空間。
值得注意的是,將 hash 表 1 的數據重新映射到 hash 表 2 的過程中並不是一次性的,這樣會造成 Redis 阻塞,無法提供服務。
而是採用了漸進式 rehash,每次處理客戶端請求的時候,先從 hash 表 1 中第一個索引開始,將這個位置的 所有數據拷貝到 hash 表 2 中,就這樣將 rehash 分散到多次請求過程中,避免耗時阻塞。
SDS 簡單動態字元
65 哥:Redis 是用 C 語言實現的,為啥還重新搞一個 SDS 動態字元串呢?
字元串結構使用最廣泛,通常我們用於快取登陸後的用戶資訊,key = userId,value = 用戶資訊 JSON 序列化成字元串。
C 語言中字元串的獲取 「MageByte」的長度,要從頭開始遍歷,直到 「\0」為止,Redis 作為唯快不破的男人是不能忍受的。
C 語言字元串結構與 SDS 字元串結構對比圖如下所示:

SDS 與 C 字元串區別
O(1) 時間複雜度獲取字元串長度
C 語言字元串布吉路長度資訊,需要遍歷整個字元串時間複雜度為 O(n),C 字元串遍歷時遇到 ‘\0’ 時結束。
SDS 中 len 保存這字元串的長度,O(1) 時間複雜度。
空間預分配
SDS 被修改後,程式不僅會為 SDS 分配所需要的必須空間,還會分配額外的未使用空間。
分配規則如下:如果對 SDS 修改後,len 的長度小於 1M,那麼程式將分配和 len 相同長度的未使用空間。舉個例子,如果 len=10,重新分配後,buf 的實際長度會變為 10(已使用空間)+10(額外空間)+1(空字元)=21。如果對 SDS 修改後 len 長度大於 1M,那麼程式將分配 1M 的未使用空間。
惰性空間釋放
當對 SDS 進行縮短操作時,程式並不會回收多餘的記憶體空間,而是使用 free 欄位將這些位元組數量記錄下來不釋放,後面如果需要 append 操作,則直接使用 free 中未使用的空間,減少了記憶體的分配。
二進位安全
在 Redis 中不僅可以存儲 String 類型的數據,也可能存儲一些二進位數據。
二進位數據並不是規則的字元串格式,其中會包含一些特殊的字元如 ‘\0’,在 C 中遇到 ‘\0’ 則表示字元串的結束,但在 SDS 中,標誌字元串結束的是 len 屬性。
zipList 壓縮列表
壓縮列表是 List 、hash、 sorted Set 三種數據類型底層實現之一。
當一個列表只有少量數據的時候,並且每個列表項要麼就是小整數值,要麼就是長度比較短的字元串,那麼 Redis 就會使用壓縮列表來做列表鍵的底層實現。
ziplist 是由一系列特殊編碼的連續記憶體塊組成的順序型的數據結構,ziplist 中可以包含多個 entry 節點,每個節點可以存放整數或者字元串。
ziplist 在表頭有三個欄位 zlbytes、zltail 和 zllen,分別表示列表佔用位元組數、列表尾的偏移量和列表中的 entry 個數;壓縮列表在表尾還有一個 zlend,表示列表結束。
struct ziplist<T> {
int32 zlbytes; // 整個壓縮列表佔用位元組數
int32 zltail_offset; // 最後一個元素距離壓縮列表起始位置的偏移量,用於快速定位到最後一個節點
int16 zllength; // 元素個數
T[] entries; // 元素內容列表,挨個挨個緊湊存儲
int8 zlend; // 標誌壓縮列表的結束,值恆為 0xFF
}

如果我們要查找定位第一個元素和最後一個元素,可以通過表頭三個欄位的長度直接定位,複雜度是 O(1)。而查找其他元素時,就沒有這麼高效了,只能逐個查找,此時的複雜度就是 O(N)
雙端列表
Redis List 數據類型通常被用於隊列、微博關注人時間軸列表等場景。不管是先進先出的隊列,還是先進後出的棧,雙端列表都很好的支援這些特性。

Redis 的鏈表實現的特性可以總結如下:
- 雙端:鏈表節點帶有 prev 和 next 指針,獲取某個節點的前置節點和後置節點的複雜度都是 O(1)。
- 無環:表頭節點的 prev 指針和表尾節點的 next 指針都指向 NULL,對鏈表的訪問以 NULL 為終點。
- 帶表頭指針和表尾指針:通過 list 結構的 head 指針和 tail 指針,程式獲取鏈表的表頭節點和表尾節點的複雜度為 O(1)。
- 帶鏈表長度計數器:程式使用 list 結構的 len 屬性來對 list 持有的鏈表節點進行計數,程式獲取鏈表中節點數量的複雜度為 O(1)。
- 多態:鏈表節點使用 void* 指針來保存節點值,並且可以通過 list 結構的 dup、free、match 三個屬性為節點值設置類型特定函數,所以鏈表可以用於保存各種不同類型的值。
後續版本對列表數據結構進行了改造,使用 quicklist 代替了 ziplist 和 linkedlist。
quicklist 是 ziplist 和 linkedlist 的混合體,它將 linkedlist 按段切分,每一段使用 ziplist 來緊湊存儲,多個 ziplist 之間使用雙向指針串接起來。
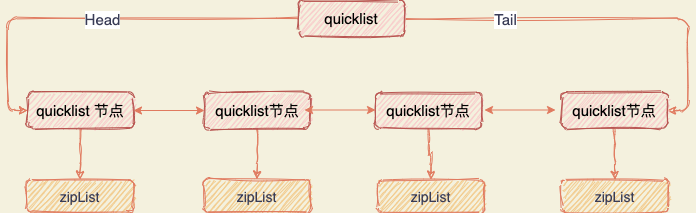
這也是為何 Redis 快的原因,不放過任何一個可以提升性能的細節。
skipList 跳躍表
sorted set 類型的排序功能便是通過「跳躍列表」數據結構來實現。
跳躍表(skiplist)是一種有序數據結構,它通過在每個節點中維持多個指向其他節點的指針,從而達到快速訪問節點的目的。
跳躍表支援平均 O(logN)、最壞 O(N)複雜度的節點查找,還可以通過順序性操作來批量處理節點。
跳錶在鏈表的基礎上,增加了多層級索引,通過索引位置的幾個跳轉,實現數據的快速定位,如下圖所示:
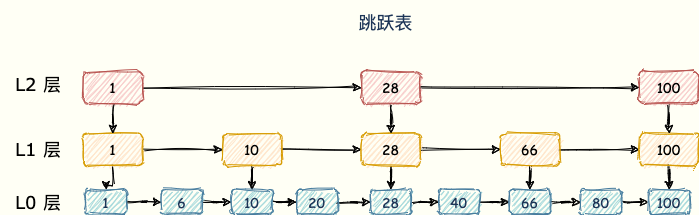
當需要查找 40 這個元素需要經歷 三次查找。
整數數組(intset)
當一個集合只包含整數值元素,並且這個集合的元素數量不多時,Redis 就會使用整數集合作為集合鍵的底層實現。結構如下:
typedef struct intset{
//編碼方式
uint32_t encoding;
//集合包含的元素數量
uint32_t length;
//保存元素的數組
int8_t contents[];
}intset;
contents 數組是整數集合的底層實現:整數集合的每個元素都是 contents 數組的一個數組項(item),各個項在數組中按值的大小從小到大有序地排列,並且數組中不包含任何重複項。length 屬性記錄了整數集合包含的元素數量,也即是 contents 數組的長度。
合理的數據編碼
Redis 使用對象(redisObject)來表示資料庫中的鍵值,當我們在 Redis 中創建一個鍵值對時,至少創建兩個對象,一個對象是用做鍵值對的鍵對象,另一個是鍵值對的值對象。
例如我們執行 SET MSG XXX 時,鍵值對的鍵是一個包含了字元串「MSG「的對象,鍵值對的值對象是包含字元串”XXX”的對象。
redisObject
typedef struct redisObject{
//類型
unsigned type:4;
//編碼
unsigned encoding:4;
//指向底層數據結構的指針
void *ptr;
//...
}robj;
其中 type 欄位記錄了對象的類型,包含字元串對象、列表對象、哈希對象、集合對象、有序集合對象。
對於每一種數據類型來說,底層的支援可能是多種數據結構,什麼時候使用哪種數據結構,這就涉及到了編碼轉化的問題。
那我們就來看看,不同的數據類型是如何進行編碼轉化的:
String:存儲數字的話,採用 int 類型的編碼,如果是非數字的話,採用 raw 編碼;
List:List 對象的編碼可以是 ziplist 或 linkedlist,字元串長度 < 64 位元組且元素個數 < 512 使用 ziplist 編碼,否則轉化為 linkedlist 編碼;
注意:這兩個條件是可以修改的,在 redis.conf 中:
list-max-ziplist-entries 512
list-max-ziplist-value 64
Hash:Hash 對象的編碼可以是 ziplist 或 hashtable。
當 Hash 對象同時滿足以下兩個條件時,Hash 對象採用 ziplist 編碼:
- Hash 對象保存的所有鍵值對的鍵和值的字元串長度均小於 64 位元組。
- Hash 對象保存的鍵值對數量小於 512 個。
否則就是 hashtable 編碼。
Set:Set 對象的編碼可以是 intset 或 hashtable,intset 編碼的對象使用整數集合作為底層實現,把所有元素都保存在一個整數集合裡面。
保存元素為整數且元素個數小於一定範圍使用 intset 編碼,任意條件不滿足,則使用 hashtable 編碼;
Zset:Zset 對象的編碼可以是 ziplist 或 zkiplist,當採用 ziplist 編碼存儲時,每個集合元素使用兩個緊挨在一起的壓縮列表來存儲。
Ziplist 壓縮列表第一個節點存儲元素的成員,第二個節點存儲元素的分值,並且按分值大小從小到大有序排列。

當 Zset 對象同時滿足一下兩個條件時,採用 ziplist 編碼:
- Zset 保存的元素個數小於 128。
- Zset 元素的成員長度都小於 64 位元組。
如果不滿足以上條件的任意一個,ziplist 就會轉化為 zkiplist 編碼。注意:這兩個條件是可以修改的,在 redis.conf 中:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
單執行緒模型
65 哥:為什麼 Redis 是單執行緒的而不用多執行緒並行執行充分利用 CPU 呢?
我們要明確的是:Redis 的單執行緒指的是 Redis 的網路 IO 以及鍵值對指令讀寫是由一個執行緒來執行的。 對於 Redis 的持久化、集群數據同步、非同步刪除等都是其他執行緒執行。
至於為啥用單執行緒,我們先了解多執行緒有什麼缺點。
多執行緒的弊端
使用多執行緒,通常可以增加系統吞吐量,充分利用 CPU 資源。
但是,使用多執行緒後,沒有良好的系統設計,可能會出現如下圖所示的場景,增加了執行緒數量,前期吞吐量會增加,再進一步新增執行緒的時候,系統吞吐量幾乎不再新增,甚至會下降!

在運行每個任務之前,CPU 需要知道任務在何處載入並開始運行。也就是說,系統需要幫助它預先設置 CPU 暫存器和程式計數器,這稱為 CPU 上下文。
這些保存的上下文存儲在系統內核中,並在重新計劃任務時再次載入。這樣,任務的原始狀態將不會受到影響,並且該任務將看起來正在連續運行。
切換上下文時,我們需要完成一系列工作,這是非常消耗資源的操作。
另外,當多執行緒並行修改共享數據的時候,為了保證數據正確,需要加鎖機制就會帶來額外的性能開銷,面臨的共享資源的並發訪問控制問題。
引入多執行緒開發,就需要使用同步原語來保護共享資源的並發讀寫,增加程式碼複雜度和調試難度。
單執行緒又什麼好處?
- 不會因為執行緒創建導致的性能消耗;
- 避免上下文切換引起的 CPU 消耗,沒有多執行緒切換的開銷;
- 避免了執行緒之間的競爭問題,比如添加鎖、釋放鎖、死鎖等,不需要考慮各種鎖問題。
- 程式碼更清晰,處理邏輯簡單。
單執行緒是否沒有充分利用 CPU 資源呢?
官方答案:因為 Redis 是基於記憶體的操作,CPU 不是 Redis 的瓶頸,Redis 的瓶頸最有可能是機器記憶體的大小或者網路頻寬。既然單執行緒容易實現,而且 CPU 不會成為瓶頸,那就順理成章地採用單執行緒的方案了。原文地址://redis.io/topics/faq。
I/O 多路復用模型
Redis 採用 I/O 多路復用技術,並發處理連接。採用了 epoll + 自己實現的簡單的事件框架。epoll 中的讀、寫、關閉、連接都轉化成了事件,然後利用 epoll 的多路復用特性,絕不在 IO 上浪費一點時間。
65 哥:那什麼是 I/O 多路復用呢?
在解釋 IO 多慮復用之前我們先了解下基本 IO 操作會經歷什麼。
基本 IO 模型
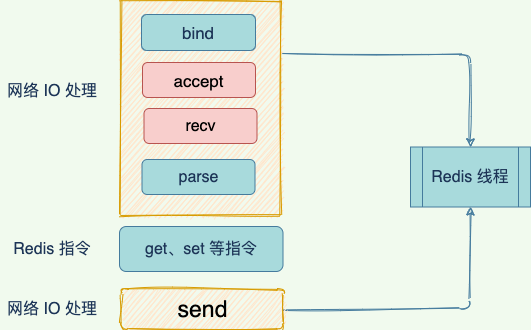
一個基本的網路 IO 模型,當處理 get 請求,會經歷以下過程:
- 和客戶端建立建立
accept; - 從 socket 種讀取請求
recv; - 解析客戶端發送的請求
parse; - 執行
get指令; - 響應客戶端數據,也就是 向 socket 寫回數據。
其中,bind/listen、accept、recv、parse 和 send 屬於網路 IO 處理,而 get 屬於鍵值數據操作。既然 Redis 是單執行緒,那麼,最基本的一種實現是在一個執行緒中依次執行上面說的這些操作。
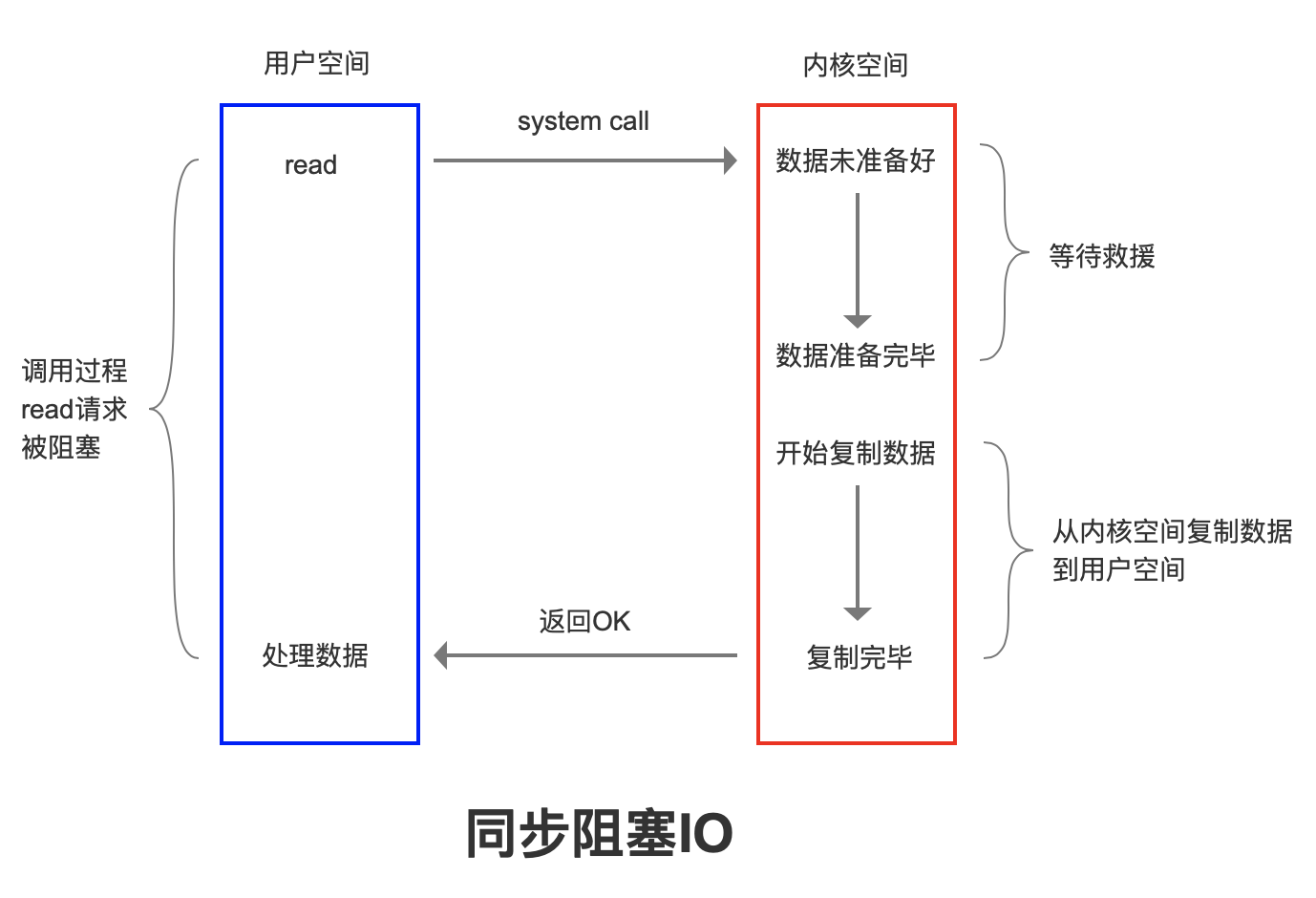
關鍵點就是 accept 和 recv 會出現阻塞,當 Redis 監聽到一個客戶端有連接請求,但一直未能成功建立起連接時,會阻塞在 accept() 函數這裡,導致其他客戶端無法和 Redis 建立連接。
類似的,當 Redis 通過 recv() 從一個客戶端讀取數據時,如果數據一直沒有到達,Redis 也會一直阻塞在 recv()。
阻塞的原因由於使用傳統阻塞 IO ,也就是在執行 read、accept 、recv 等網路操作會一直阻塞等待。如下圖所示:
IO 多路復用
多路指的是多個 socket 連接,復用指的是復用一個執行緒。多路復用主要有三種技術:select,poll,epoll。epoll 是最新的也是目前最好的多路復用技術。
它的基本原理是,內核不是監視應用程式本身的連接,而是監視應用程式的文件描述符。
當客戶端運行時,它將生成具有不同事件類型的套接字。在伺服器端,I / O 多路復用程式(I / O 多路復用模組)會將消息放入隊列(也就是 下圖的 I/O 多路復用程式的 socket 隊列),然後通過文件事件分派器將其轉發到不同的事件處理器。
簡單來說:Redis 單執行緒情況下,內核會一直監聽 socket 上的連接請求或者數據請求,一旦有請求到達就交給 Redis 執行緒處理,這就實現了一個 Redis 執行緒處理多個 IO 流的效果。
select/epoll 提供了基於事件的回調機制,即針對不同事件的發生,調用相應的事件處理器。所以 Redis 一直在處理事件,提升 Redis 的響應性能。
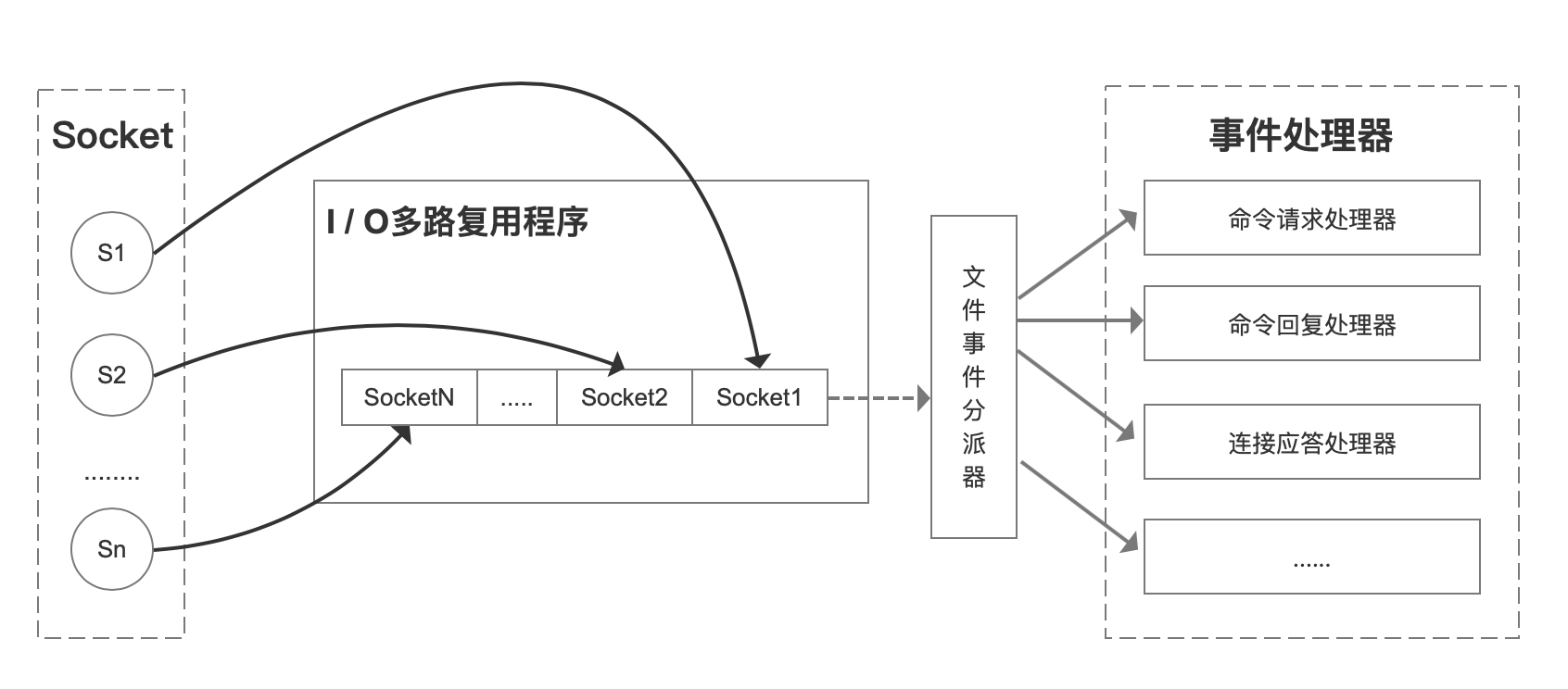
Redis 執行緒不會阻塞在某一個特定的監聽或已連接套接字上,也就是說,不會阻塞在某一個特定的客戶端請求處理上。正因為此,Redis 可以同時和多個客戶端連接並處理請求,從而提升並發性。
唯快不破的原理總結
65 哥:學完之後我終於知道 Redis 為何快的本質原因了,「碼哥」你別說話,我來總結!一會我再點贊和分享這篇文章,讓更多人知道 Redis 快的核心原理。
- 純記憶體操作,一般都是簡單的存取操作,執行緒佔用的時間很多,時間的花費主要集中在 IO 上,所以讀取速度快。
- 整個 Redis 就是一個全局 哈希表,他的時間複雜度是 O(1),而且為了防止哈希衝突導致鏈表過長,Redis 會執行 rehash 操作,擴充 哈希桶數量,減少哈希衝突。並且防止一次性 重新映射數據過大導致執行緒阻塞,採用 漸進式 rehash。巧妙的將一次性拷貝分攤到多次請求過程後總,避免阻塞。
- Redis 使用的是非阻塞 IO:IO 多路復用,使用了單執行緒來輪詢描述符,將資料庫的開、關、讀、寫都轉換成了事件,Redis 採用自己實現的事件分離器,效率比較高。
- 採用單執行緒模型,保證了每個操作的原子性,也減少了執行緒的上下文切換和競爭。
- Redis 全程使用 hash 結構,讀取速度快,還有一些特殊的數據結構,對數據存儲進行了優化,如壓縮表,對短數據進行壓縮存儲,再如,跳錶,使用有序的數據結構加快讀取的速度。
- 根據實際存儲的數據類型選擇不同編碼
下一篇「碼哥位元組」將帶來 《Redis 日誌篇:無畏宕機快速恢復的殺手鐧》,關注我,獲取真正的硬核知識點。
另外技術讀者群也開通了,後台回復「加群」獲取「碼哥位元組」作者微信,一起成長交流。
以上就是 Redis 唯快不破的秘密詳解,覺得不錯請點贊、分享,「碼哥位元組」感激不盡。



