剪枝決策樹原理與Python實現
一、決策樹模型
決策樹(Decision Tree)是一種常見的機器學習演算法,而其核心便是「分而治之」的劃分策略。例如,以西瓜為例,需要判斷一個西瓜是否是一個好瓜,那麼就可以根據經驗考慮「西瓜是什麼顏色?」,如果是「青綠色」,那麼接著考慮「它的根蒂是什麼形態?」,如果是「蜷縮」,那麼再接著考慮「敲打聲音如何?」,如果是「濁響」,那麼就可以判定這個西瓜可能是一個「好瓜」。
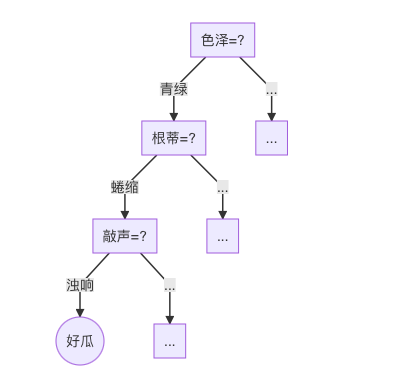
上圖便是一個決策樹模型基本決策流程。由上圖可見,決策樹模型通常包含一個根結點,若干中間節點和若干葉結點。其中,每個葉結點保存了當前特徵分支\(x_i\)的標記\(y_i\),而其餘的每個結點則保存了當前結點劃分的特徵和劃分的依據(特徵值)。
下面是決策樹模型訓練的偽程式碼:
生成決策樹(D,F):# D為數據集,F為特徵向量
生成一個結點node
1)如果無法繼續劃分,標記為D中樣本數最多的類:
a. D中標記相同,無需劃分
b. F為空,無法劃分
c. D在F上取值相同,無需劃分
2)如果可以繼續劃分:
選擇最優劃分屬性f;
遍歷D在f上的每一種取值f『:
為node生成一個新的分支;
D『為D在f上取值為f』的子集;
(1)如果D『為空,將分支節點標記為D中樣本最多的類;
(2)如果D』不為空,生成決策樹(D’,F \ {f})
二、選擇劃分
由前面的偽程式碼不難看出,生成決策樹的關鍵在於選擇最優的劃分屬性。為了衡量各個特徵劃分的優劣,這裡引入了純度(purity)的概念。即,希望隨著劃分的進行,決策樹的分支節點所包含的樣本儘可能屬於同一類別。現在已經有了幾種用來度量樣本集純度的指標:
2.1 資訊熵和資訊增益
資訊熵(information entropy)是度量樣本集純度的常用指標,其定義如下:
\]
其中,\(p_k\)為\(D\)中第\(k\)類樣本所佔比例,而\(Ent(D)\)越小,則說明樣本集的純度越高。
以一個選定的特徵將樣本劃分為\(v\)個子集,則可以分別計算出這\(v\)個子集的資訊熵\(Ent(D^i)\),賦予每個子集權重\(\frac{|D^i|}{|D|}\)求出各個子集資訊熵的加權平均值,便可以得到劃分後的平均資訊熵。定義資訊增益(information gain):
\]
那麼,資訊增益越大,說明樣本集以特徵\(f\)進行劃分獲得的純度提升越大(劃分後子節點的平均資訊熵越小)。著名的ID3決策樹便是採用資訊增益作為標準來選擇劃分屬性。
2.2 增益率
通過對資訊熵公式進行分析不難發現,資訊增益對於可取值數目較多的特徵有所偏好。因為如果D在f上可取值較多,那麼劃分後各個子集的純度往往較高,資訊熵也會較小,最後產生大量的分支,嚴重影響決策樹的泛化性能。所以C4.5決策樹在資訊增益的基礎上引入了增益率(gain rate)的概念:
\]
\]
其中\(IV\)稱為屬性f的固有值(intrinsic value),屬性f的可取值數目越多,\(IV\)越大。不難看出,增益率對於屬性f可取值較少的屬性有所偏好,所以通常的策略是:先選擇資訊增益高於平均水平的屬性,然後從中選擇增益率最小的屬性進行劃分。
2.3 基尼指數
CART決策樹(分類回歸樹)採用基尼指數(Gini index)來選擇劃分屬性。樣本集\(D\)的純度可用基尼值來度量,其定義如下:
\]
不難看出,\(Gini(D)\)反映了從\(D\)中任意抽取兩個樣本,其類標不一致的概率。因此,基尼值越小,樣本集純度越高。那麼屬性f的基尼指數則定義為:
\]
因此,以基尼指數為評價標準的最優劃分屬性為\(f^*=\arg\min_{f\in F}Gini\_index(D, f)\)。
三、剪枝
在訓練決策樹模型的時候,有時決策樹會將訓練集的一些特有性質當作一般性質進行了學習,從而產生過多的分支,不僅效率下降還可能導致過擬合(over fitting)從而降低泛化性能。剪枝(pruning)就是通過主動去掉決策樹的一些分支從而防止過擬合的一種手段。
3.1 預剪枝
預剪枝(prepruning)是指在生成決策樹的過程中,對每個結點劃分前進行模擬,如果劃分後不能帶來決策樹泛化性能的提升,則停止劃分並將當前結點標記為葉結點。
3.2 後剪枝
後剪枝(post-pruning)則是指在生成一棵決策樹後,自下而上地對非葉結點進行考察,如果將該結點對應的子樹替換為葉結點能帶來泛化性能的提升,則進行替換。
3.3 剪枝示例
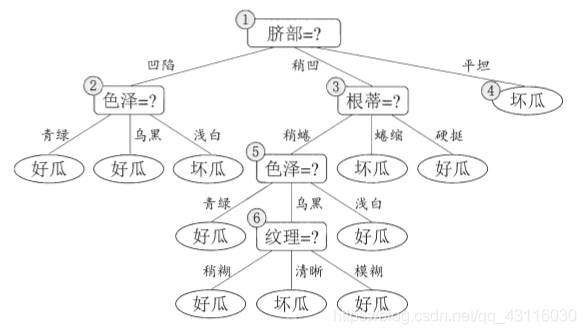
那麼如何判斷模型的泛化性能是否提升?舉個栗子來說明(周志華《機器學習》P80-P83):假設生成的決策樹如下,
預留的驗證集如下:
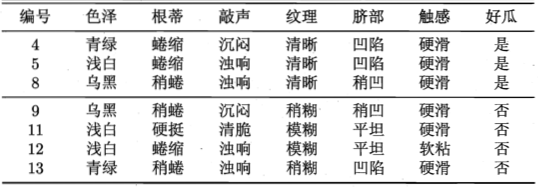
以預剪枝為例,首先看根結點。假設不進行劃分,將結點1標記為\(D\)中樣本最多的類別「是」,用驗證集進行評估,易得準確率為\(\frac{3}{7}=42.9\%\)。如果進行劃分,則結點2、3、4將分別被標記為「是」、「是」、「否」,用驗證集評估則易得準確率為\(\frac{5}{7}=71.4\%>42.9\%\),所以繼續劃分。再看結點2,劃分前驗證集準確率為\(71.4\%\),劃分後卻下降到了\(57.1\%\),所以不進行劃分。以此為例,最終可以將前面的決策樹剪枝為如下形式:
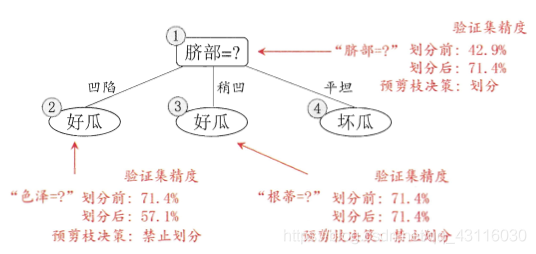
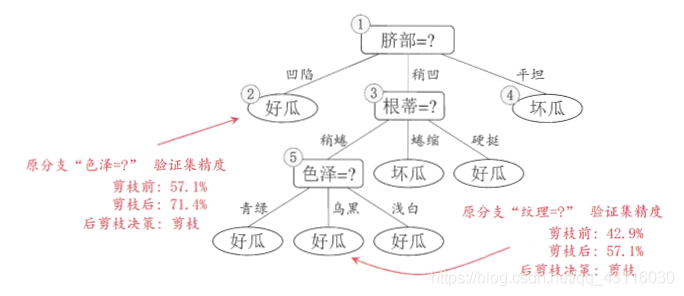
而後剪枝則只是在生成決策樹後,從下往上開始判斷泛化性能,這裡不再贅述(詳情可見周志華《機器學習》P82-P83)。後剪枝後決策樹形式如下:
3.4 預剪枝和後剪枝對比
| 項目 | 預剪枝 | 後剪枝 | 不剪枝 |
|---|---|---|---|
| 時間 | 生成決策樹時 | 生成決策樹後 | \ |
| 方向 | 自上而下 | 自下而上 | \ |
| 效率 | 高 | 低 | 中 |
| 擬合度 | 欠擬合風險 | 擬合較好 | 過擬合風險 |
四、Python實現
4.1 基尼值和基尼指數
基尼值:
def _gini(self, y): # 基尼值
y_ps = []
y_unque = np.unique(y)
for y_u in y_unque:
y_ps.append(np.sum(y == y_u) / len(y))
return 1 - sum(np.array(y_ps) ** 2)
基尼指數:
def _gini_index(self, X, y, feature): # 特徵feature的基尼指數
X_y = np.hstack([X, y.reshape(-1, 1)])
unique_feature = np.unique(X_y[:, feature])
gini_index = []
for uf in unique_feature:
sub_y = X_y[X_y[:, feature] == uf][:, X_y.shape[1] - 1]
gini_index.append(len(sub_y) / len(y) * self._gini(sub_y))
return sum(gini_index), feature
4.2 選擇劃分特徵
劃分特徵的選擇依賴於前面的基尼指數函數:
def _best_feature(self, X, y, features): # 選擇基尼指數最低的特徵
return min([self._gini_index(X, y, feature) for feature in features], key=lambda x:x[0])[1]
4.3 後剪枝演算法
def _post_pruning(self, X, y):
nodes_mid = [] # 棧,存儲所有中間結點
nodes = [self.root] # 隊列,用於輔助廣度優先遍歷
while nodes: # 通過廣度優先遍歷找到所有中間結點
node = nodes.pop(0)
if node.sub_node:
nodes_mid.append(node)
for sub in node.sub_node:
nodes.append(sub)
while nodes_mid: # 開始剪枝
node = nodes_mid.pop(len(nodes_mid) - 1)
y_pred = self.predict(X)
from sklearn.metrics import accuracy_score
score = accuracy_score(y, y_pred)
temp = node.sub_node
node.sub_node = None
if accuracy_score(y, self.predict(X)) <= score:
node.sub_node = temp
4.4 訓練演算法
首先需要將數據集劃分為訓練集和驗證集,訓練集用於訓練決策樹,驗證集用於後剪枝。訓練演算法按照偽程式碼編寫即可。
def fit(self, X, y):
# 將數據集劃分為訓練集和驗證集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.7, test_size=0.3)
queue = [[self.root, list(range(X_train.shape[0])), list(range(X_train.shape[1]))]]
while queue: # 廣度優先生成樹
node, indexs, features = queue.pop(0)
node.y = ss.mode(y_train[indexs])[0][0] # 這裡給每一個結點都添加了類標是為了防止測試集出現訓練集中沒有的特徵值
# 如果樣本全部屬於同一類別
unique_y = np.unique(y_train[indexs])
if len(unique_y) == 1:
continue
# 如果無法繼續進行劃分
if len(features) < 2:
if len(features) == 0 or len(np.unique(X_train[indexs, features[0]])) == 1:
continue
# 選擇最優劃分特徵
feature = self._best_feature(X_train[indexs], y_train[indexs], features)
node.feature = feature
features.remove(feature)
# 生成子節點
for uf in np.unique(X_train[indexs, feature]):
sub_node = Node(value=uf)
node.append(sub_node)
new_indexs = []
for index in indexs:
if X_train[index, feature] == uf:
new_indexs.append(index)
queue.append([sub_node, new_indexs, features])
self._post_pruning(X_valid, y_valid)
return self
4.6 導入鳶尾花數據集測試
導入鳶尾花數據集測試:
if __name__ == "__main__":
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.metrics import classification_report
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = KBinsDiscretizer(encode="ordinal").fit_transform(X) # 離散化
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, test_size=0.3)
classifier = DecisionTreeClassifier().fit(X_train, y_train)
y_pred = classifier.predict(X_test)
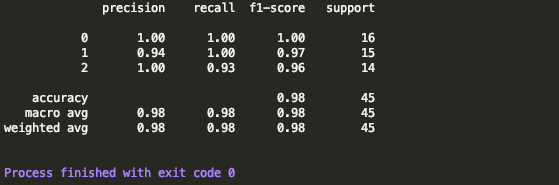
print(classification_report(y_test, y_pred))
分類報告: