ElasticSearch極簡入門總結
- 2021 年 1 月 23 日
- 筆記
一,目錄
-
安裝es
-
項目添加maven依賴
-
es客戶端組件注入到spring容器中
-
es與mysql表結構對比
-
索引的刪除創建
-
文檔的crud
-
es能快速搜索的核心-倒排索引
-
基於倒排索引的精確搜索、全文搜索(重點)
-
es集群
二,二,安裝ES環境(安裝完成後,開啟ES,默認埠9200能訪問到,說明成功了)
安裝文章
三,Java項目中添加ES的maven依賴
1.<dependency>
2. <groupId>org.elasticsearch.client</groupId>
3. <artifactId>elasticsearch-rest-high-level-client</artifactId>
4. <version>7.10.2</version>
</dependency>
四,四,將ES客戶端組件注入到spring容器中(客戶端組件RestHighLevelClient,其封裝了操作es的crud方法,底層原理就是模擬各種es需要的請求)
1.package com.shuang.config;
2.
3.import org.apache.http.HttpHost;
4.import org.elasticsearch.client.RestClient;
5.import org.elasticsearch.client.RestHighLevelClient;
6.import org.springframework.context.annotation.Bean;
7.import org.springframework.context.annotation.Configuration;
8.
9.@Configuration //xml文件-bean
10.public class ElasticSearchClientConfig {
11.
12. @Bean
13. public RestHighLevelClient restHighLevelClient(){
14. RestHighLevelClient client = new RestHighLevelClient(
15. RestClient.builder(
16. //多個集群,就new多個
17. new HttpHost("localhost", 9200, "http")));
18. return client;
19. }
20.}
五,到這裡,springboot整合ES就好了。相較於springboot操作mysql需要jdbc支援,ES直接一步封裝到位,後期可以直接使用。
六,在進行crud前,我們先對比一下es與mysql。看完後,我們正式開始crue

七,索引的操作(對應的mysql就是資料庫的創建、刪除)在kibana中可以傻瓜式的創建索引與刪除索引
1)java程式碼創建索引
package com.shuang;
@SpringBootTest
class DemoApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
void contextLoads() throws IOException {
//1,創建索引表
CreateIndexRequest request=new CreateIndexRequest("shuangbao");
//2,客戶端執行請求 IndicesClient,請求後獲得響應
CreateIndexResponse createIndexResponse=
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
}
2)刪除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request=new DeleteIndexRequest();
AcknowledgedResponse delete =restHighLevelClient.indices().delete(request,RequestOptions.DEFAULT);
System.out.println(delete);
}
八,操作文檔(es7中」類型」我們一般都是設置為默認的_doc,es8中將移除」類型」,相當於mysql的表沒有了),文檔相當於mysql中的一條記錄。es中插入一條json數據,如果沒有指明文檔id,就會隨機生成一個
先新建索引,默認類型為_doc,建立文檔結構json格式的屬性有string類型的name,integer類型的age。
1.PUT /shuang_index1
2. {
3. "settings": {
4. "index": {
5. "number_of_replicas": "1",
6. "number_of_shards": "5" }
7. },
8. "mappings": {
9. "test_type": {
10. "properties": {
11. "name": {
12. "type": "string",
13. },
14. "age": {
15. "type": "integer"
16. }
17. }
18. }
19. }
20. }
插入一條文檔id為1的數據
PUT shuang_index2/_doc/1
{
"name":"shuang1",
"age":"1"
}
1)獲取文檔的資訊,這裡我們獲取文檔id為1的資訊
//獲取文檔的資訊
@Test
void testIsGetDocument() throws IOException {
GetRequest getRequest=new GetRequest("shuang_index1","1");
//不獲取返回的_source的上下文
GetResponse getResponse=restHighLevelClient.get(getRequest,RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//列印文檔的數據_source
System.out.println(getResponse); //列印文檔id為1的完整返回資訊
}
{"age":1,"name":"shuang1"}
"_index":"shuang_index1","_type":"_doc","_id":"1","_version":1,"_seq_no":4,"_primary_term":1,"found":true,"_source":{"age":1,"name":"shuang1"}}
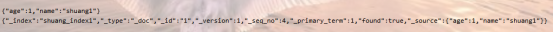
2)插入數據(數據來源可以是其他地方)
1.@Test
2.void testBulkRequest() throws IOException {
3. BulkRequest bulkRequest=new BulkRequest();
4. bulkRequest.timeout("10s");
5.
6. ArrayList<User> userList=new ArrayList<>();
7. userList.add(new User("jiang1",1));
8. userList.add(new User("jiang2",2));
9. userList.add(new User("jiang3",3));
10. userList.add(new User("jiang4",4));
11. userList.add(new User("jiang5",5));
12. userList.add(new User("jiang6",6));
13. userList.add(new User("jiang7",7));
14. userList.add(new User("jiang8",8));
15.
16. //批處理請求
17. for(int i=0;i<userList.size();i++){
18. //批量更新和刪除,就在這裡修改對應的請求就可以了
19. bulkRequest.add(
20. new IndexRequest("shuang_index1")
21. .id(""+(i+1))
22. .source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
23.
24. }
25. BulkResponse bulkResponse=restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
26.
27. System.out.println(bulkResponse.hasFailures());//是否失敗,返回false代表成功
28.}
3)刪除文檔資訊
1.@Test
2.void testDeleteRequest() throws IOException {
3. DeleteRequest request=new DeleteRequest("shuang_index1","1");
4. request.timeout("1s");
5.
6. DeleteResponse deleteResponse=restHighLevelClient.delete(request,RequestOptions.DEFAULT);
7. System.out.println(deleteResponse.status());
8.
9.}
4)更新文檔資訊
1.@Test
2. void testUpdateRequest() throws IOException {
3. UpdateRequest updateRequest=new UpdateRequest("shuang_index1","1");
4. updateRequest.timeout("1s");
5.
6. User user=new User("爽爽爽",18);
7. updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
8.
9. UpdateResponse updateResponse=restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);
10.
11. System.out.println(updateResponse.status());
12. }
九,倒排索引
前面介紹了文檔的查找,是普通的查找get方式的,需要指定_index、_type、_id。也就是根據id從正排索引中獲取內容,確定唯一文檔。
但搜索search方式需要一種更複雜的模型,因為不知道查詢會命中哪些文檔。採用倒排索引可以滿足複雜的搜索過程。

搜索也分精確值搜索和全文搜索,對數據建立索引和執行搜索的原理如下圖所示:
十,查詢和全文查詢
Term(精確,不會被分詞器解析,keyword類型的欄位也不會被分詞器解析)和match(全文,會被分詞器解析)是兩個常用的基於倒排索引的搜索類型。他們對應的java類主要有 TermQueryBuilder和MatchQueryBuilder。
精確搜索(在shuang_index1索引中,name欄位為shuang1的文檔)
1.@Test
2. void testSearch() throws IOException {
3. SearchRequest searchRequest=new SearchRequest("shuang_index1");
4. //構建搜索條件
5. SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
6.
7. TermQueryBuilder termQueryBuilder=QueryBuilders.termQuery("name","shuang1");
8.
9. sourceBuilder.query(termQueryBuilder);
10. sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
11.
12. searchRequest.source(sourceBuilder);
13.
14. SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
15. System.out.println(JSON.toJSONString(searchResponse.getHits()));
16.
17. for(SearchHit documentFields :searchResponse.getHits().getHits()){
18. System.out.println(documentFields.getSourceAsMap());
19. }
20. }
第二個輸出是對搜索返回資訊進行了提取關鍵欄位。
全文搜索
1)在kibana上新建shuang_index2索引(相當於在navicat上去新建mysql資料庫)
一般我們不指定類型(系統會默認為_doc,es7不推薦使用了,es8將會移除類型,相當於mysql沒有了表這個結構)。
設置裡面的文檔欄位為name和age,它們類型為string與interger。
1.PUT /shuang_index2
2. {
3. "settings": {
4. "index": {
5. "number_of_replicas": "1", //設置副本數為1
6. "number_of_shards": "5" } //設置分片數為5
7. },
8. "mappings": {
9. "test_type": {
10. "properties": {
11. "name": {
12. "type": "string",
13. },
14. "age": {
15. "type": "integer"
16. }
17. }
18. }
19. }
20. }
2)插入數據(一般我們是從數據倉庫批量導入,java程式碼見上面文檔的插入)
Kibana控制台也可以自己手動插入
1.PUT shuang_index2/_doc/5
2.{
3. "name":"shuang e",
4. "age":"5"
5.}
這裡shuang_index2為索引、_doc為類型、5代表文檔id(大數據環境下,我們一般不指定文檔id,系統會隨機生成一個文檔id,唯一標識該文檔)。它們分別對應mysql的資料庫、表、行。name和age代表mysql欄位中的列屬性。文檔結構必須為json格式。
3)搭建好索引結構後,我們去用java程式碼實現一下
(內置分詞器先把shuang bao分詞為shuang 與 bao ,再去shuang_index2索引中去尋找,文檔1、2、3、4、5分別有name=shuang a、b、c、d、e。他們事先也被分詞器拆解了,只要有一個與上面對應,就搜索成功,並且會攜帶一個相似程度score返回)
1.@Test
2.void testSearch() throws IOException {
3. SearchRequest searchRequest=new SearchRequest("shuang_index2");
4. //構建搜索條件
5. SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();
6.
7. MatchQueryBuilder matchQueryBuilder=QueryBuilders.matchQuery("name","shuang bao");
8. sourceBuilder.query(matchQueryBuilder);
9. sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
10.
11. searchRequest.source(sourceBuilder);
12.
13. SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
14. System.out.println(searchResponse);
15.
16. for(SearchHit documentFields :searchResponse.getHits().getHits()){
17. System.out.println(documentFields.getSourceAsMap());
18. }
19.}
返回結果:
{"took":770,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":5,"relation":"eq"},"max_score":0.08701137,"hits":[{"_index":"shuang_index2","_type":"_doc","_id":"1","_score":0.08701137,"_source":{"name":"shuang a","age":"1"}},{"_index":"shuang_index2","_type":"_doc","_id":"2","_score":0.08701137,"_source":{"name":"shuang b","age":"2"}},{"_index":"shuang_index2","_type":"_doc","_id":"3","_score":0.08701137,"_source":{"name":"shuang c","age":"3"}},{"_index":"shuang_index2","_type":"_doc","_id":"4","_score":0.08701137,"_source":{"name":"shuang d","age":"4"}},{"_index":"shuang_index2","_type":"_doc","_id":"5","_score":0.08701137,"_source":{"name":"shuang e","age":"5"}}]}}
{name=shuang a, age=1}
{name=shuang b, age=2}
{name=shuang c, age=3}
{name=shuang d, age=4}
{name=shuang e, age=5}
十一,es集群

如圖3個es服務構成的集群,索引test分成了5片,一個副本(粗框的),而book一個分片一個副本。保證了如果有一個服務壞了,其他服務也能執行所有工作。
一個搜索請求必須詢問請求的索引中所有分片的某個副本來進行匹配。假設一個索引有5個主分片,每個主分片有1個副分片,共10個分片,一次搜索請求會由5個分片來共同完成,它們可能是主分片,也可能是副分片。也就是說,一次搜索請求只會命中所有分片副本中的一個。
ElasticSearch極簡入門總結就結束了感謝您的閱讀
