機器學習6-回歸改進
欠擬合與過擬合
什麼是過擬合與欠擬合
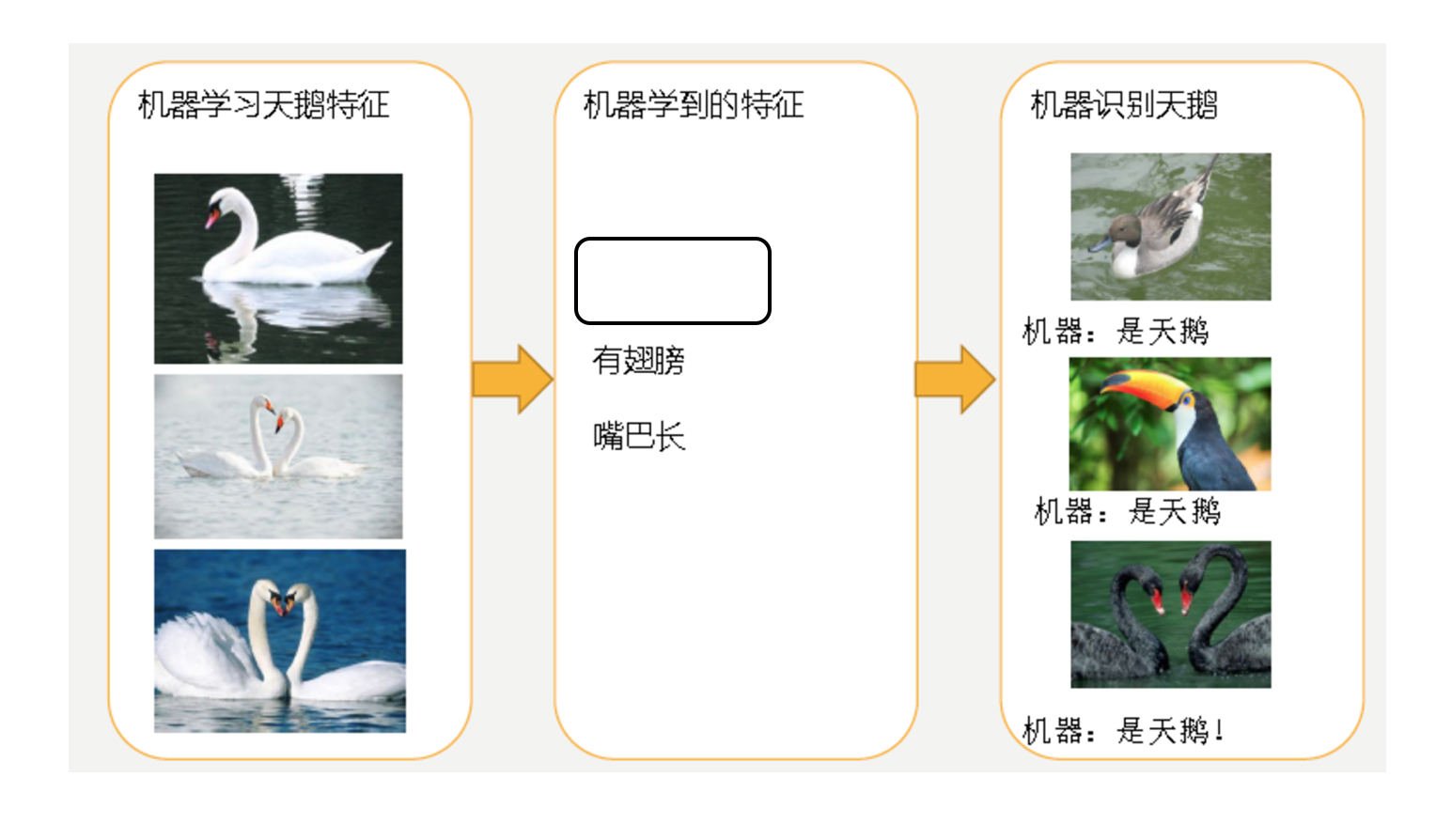
欠擬合
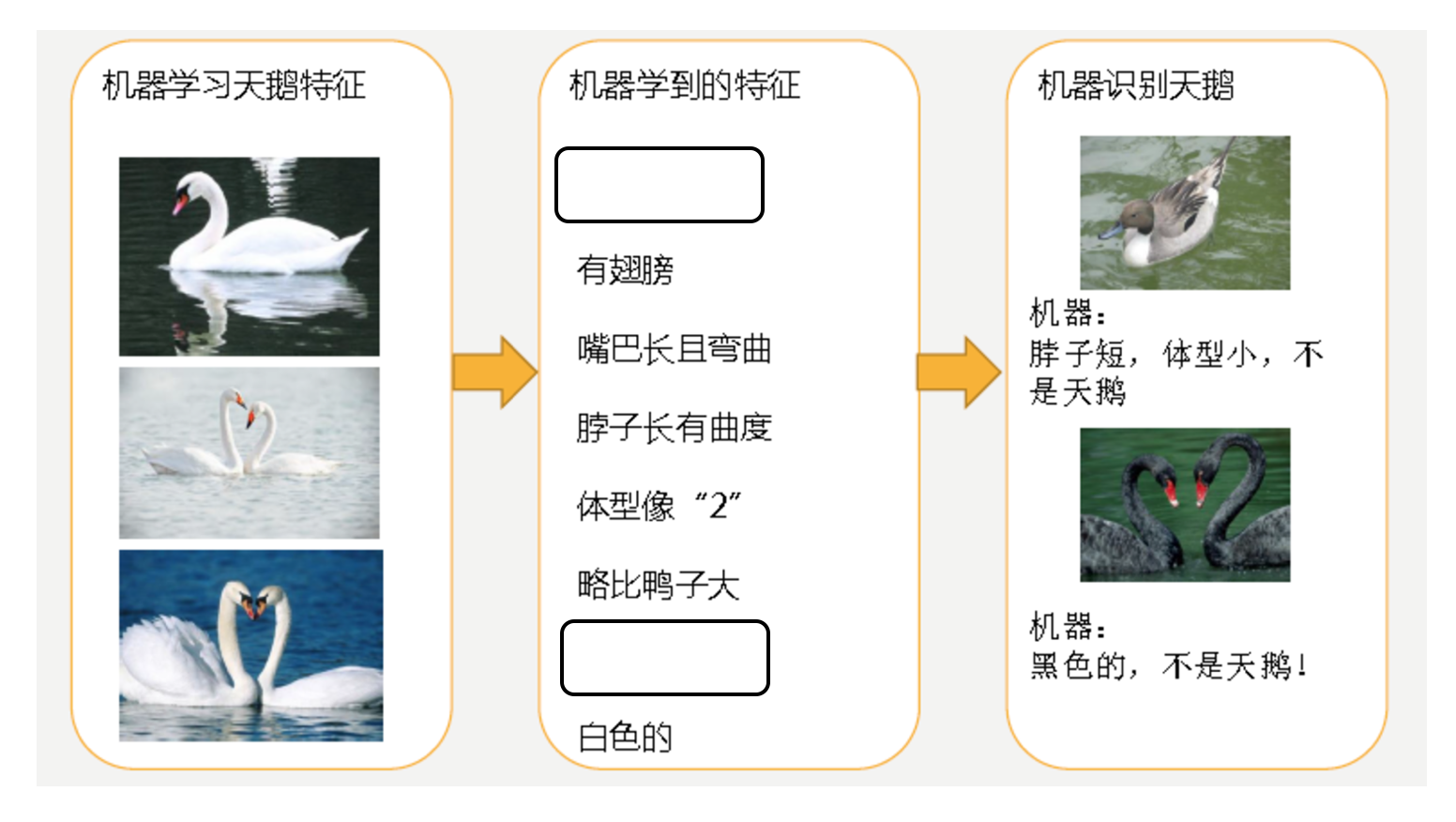
過擬合
- 第一種情況:因為機器學習到的天鵝特徵太少了,導致區分標準太粗糙,不能準確識別出天鵝。
- 第二種情況:機器已經基本能區別天鵝和其他動物了。然後,很不巧已有的天鵝圖片全是白天鵝的,於是機器經過學習後,會認為天鵝的羽毛都是白的,以後看到羽毛是黑的天鵝就會認為那不是天鵝。
定義
- 過擬合:一個假設在訓練數據上能夠獲得比其他假設更好的擬合, 但是在測試數據集上卻不能很好地擬合數據,此時認為這個假設出現了過擬合的現象。(模型過於複雜)
- 欠擬合:一個假設在訓練數據上不能獲得更好的擬合,並且在測試數據集上也不能很好地擬合數據,此時認為這個假設出現了欠擬合的現象。(模型過於簡單)
原因以及解決辦法
- 欠擬合原因以及解決辦法
- 原因:學習到數據的特徵過少
- 解決辦法:增加數據的特徵數量
- 過擬合原因以及解決辦法
- 原因:原始特徵過多,存在一些嘈雜特徵, 模型過於複雜是因為模型嘗試去兼顧各個測試數據點
- 解決辦法:
- 正則化

在學習的時候,數據提供的特徵有些影響模型複雜度或者這個特徵的數據點異常較多,所以演算法在學習的時候盡量減少這個特徵的影響(甚至刪除某個特徵的影響),這就是正則化
正則化類別
- L2正則化
- 作用:可以使得其中一些W的都很小,都接近於0,削弱某個特徵的影響
- 優點:越小的參數說明模型越簡單,越簡單的模型則越不容易產生過擬合現象
- Ridge回歸
- L1正則化
- 作用:可以使得其中一些W的值直接為0,刪除這個特徵的影響
- LASSO回歸
線性回歸的改進-嶺回歸
帶有L2正則化的線性回歸-嶺回歸
API
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=”auto”, normalize=False)
- 具有l2正則化的線性回歸
- alpha:正則化力度,也叫 λ
- λ取值:0~1 1~10
- solver:會根據數據自動選擇優化方法
- sag:如果數據集、特徵都比較大,選擇該隨機梯度下降優化
- normalize:數據是否進行標準化
- normalize=False:可以在fit之前調用preprocessing.StandardScaler標準化數據
- Ridge.coef_:回歸權重
- Ridge.intercept_:回歸偏置
Ridge方法相當於SGDRegressor(penalty=’l2′, loss=”squared_loss”),只不過SGDRegressor實現了一個普通的隨機梯度下降學習,推薦使用Ridge(實現了SAG)
sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正則化的線性回歸,可以進行交叉驗證
- coef_:回歸係數
案例-波士頓房價預測
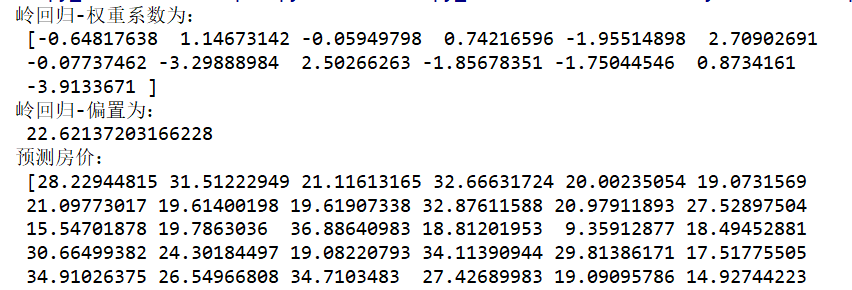
def linear3(): """ 嶺回歸的優化方法對波士頓房價預測 """ #獲取數據 boston=load_boston() #劃分數據集 x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,random_state=22) #標準化 transfer=StandardScaler() x_train=transfer.fit_transform(x_train) x_test=transfer.transform(x_test) #預估器 estimator=Ridge(alpha=0.0001, max_iter=100000) estimator.fit(x_train,y_train) #得出模型 print("嶺回歸-權重係數為:\n",estimator.coef_) print("嶺回歸-偏置為:\n",estimator.intercept_ ) #模型評估 y_predict = estimator.predict(x_test) print("預測房價:\n", y_predict) error = mean_squared_error(y_test, y_predict) print("嶺回歸-均方差誤差:\n", error) return None if __name__ == '__main__': linear3()
結果為:

分類演算法-邏輯回歸與二分類
邏輯回歸的應用場景
- 廣告點擊率
- 是否為垃圾郵件
- 是否患病
- 金融詐騙
- 虛假帳號
看到上面的例子,我們可以發現其中的特點,那就是都屬於兩個類別之間的判斷。邏輯回歸就是解決二分類問題的利器
邏輯回歸的原理
輸入
邏輯回歸的輸入就是一個線性回歸的結果。
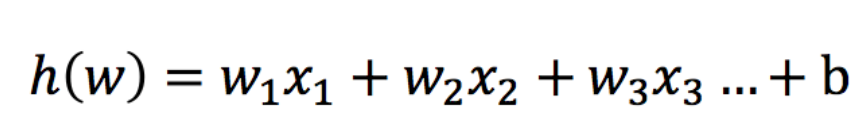
激活函數
- sigmoid函數
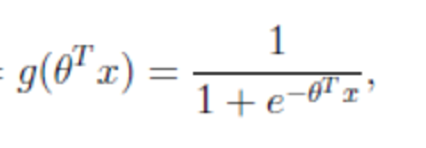
- 回歸的結果輸入到sigmoid函數當中
- 輸出結果:[0, 1]區間中的一個概率值,默認為0.5為閾值
輸出結果解釋(重要):假設有兩個類別A,B,並且假設我們的概率值為屬於A(1)這個類別的概率值。現在有一個樣本的輸入到邏輯回歸輸出結果0.6,那麼這個概率值超過0.5,意味著我們訓練或者預測的結果就是A(1)類別。那麼反之,如果得出結果為0.3那麼,訓練或者預測結果就為B(0)類別。
所以接下來我們回憶之前的線性回歸預測結果我們用均方誤差衡量,那如果對於邏輯回歸,我們預測的結果不對該怎麼去衡量這個損失呢?我們來看這樣一張圖
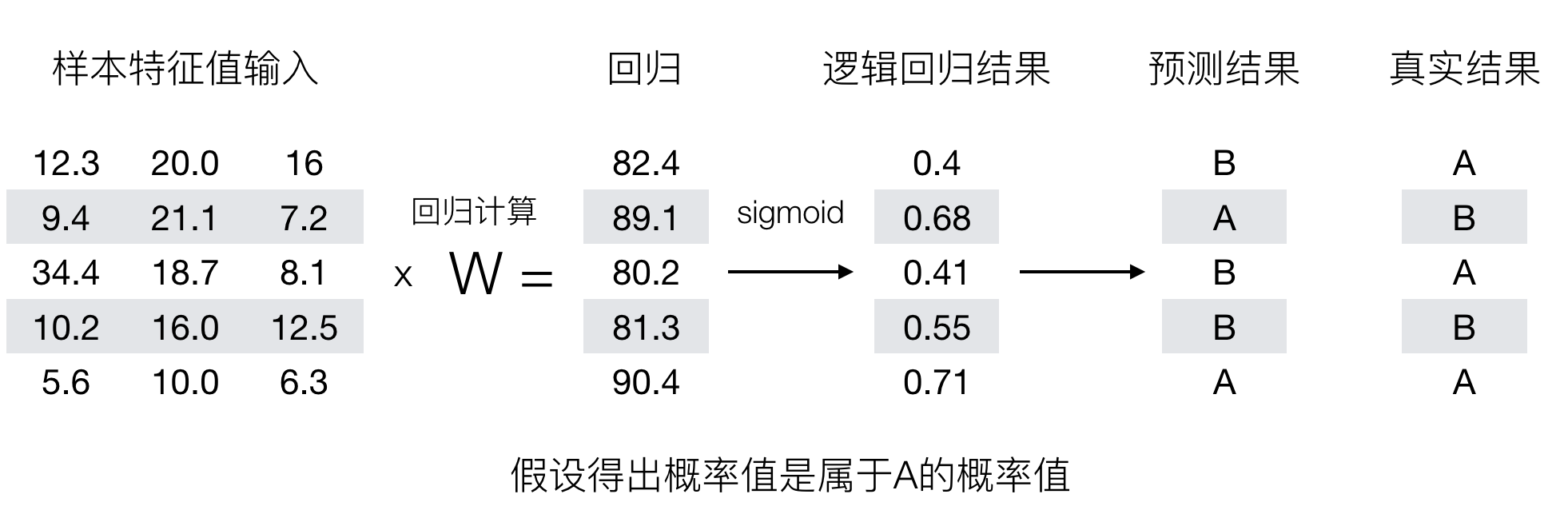
那麼如何去衡量邏輯回歸的預測結果與真實結果的差異呢?
損失以及優化
損失
邏輯回歸的損失,稱之為對數似然損失,公式如下:
- 分開類別:
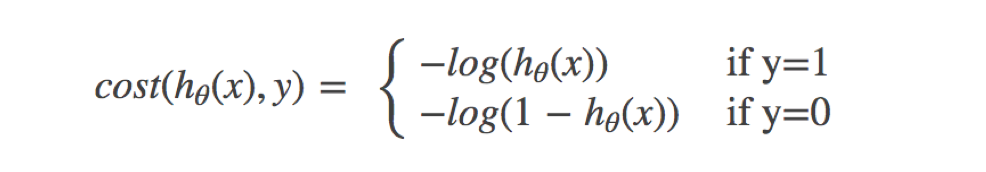
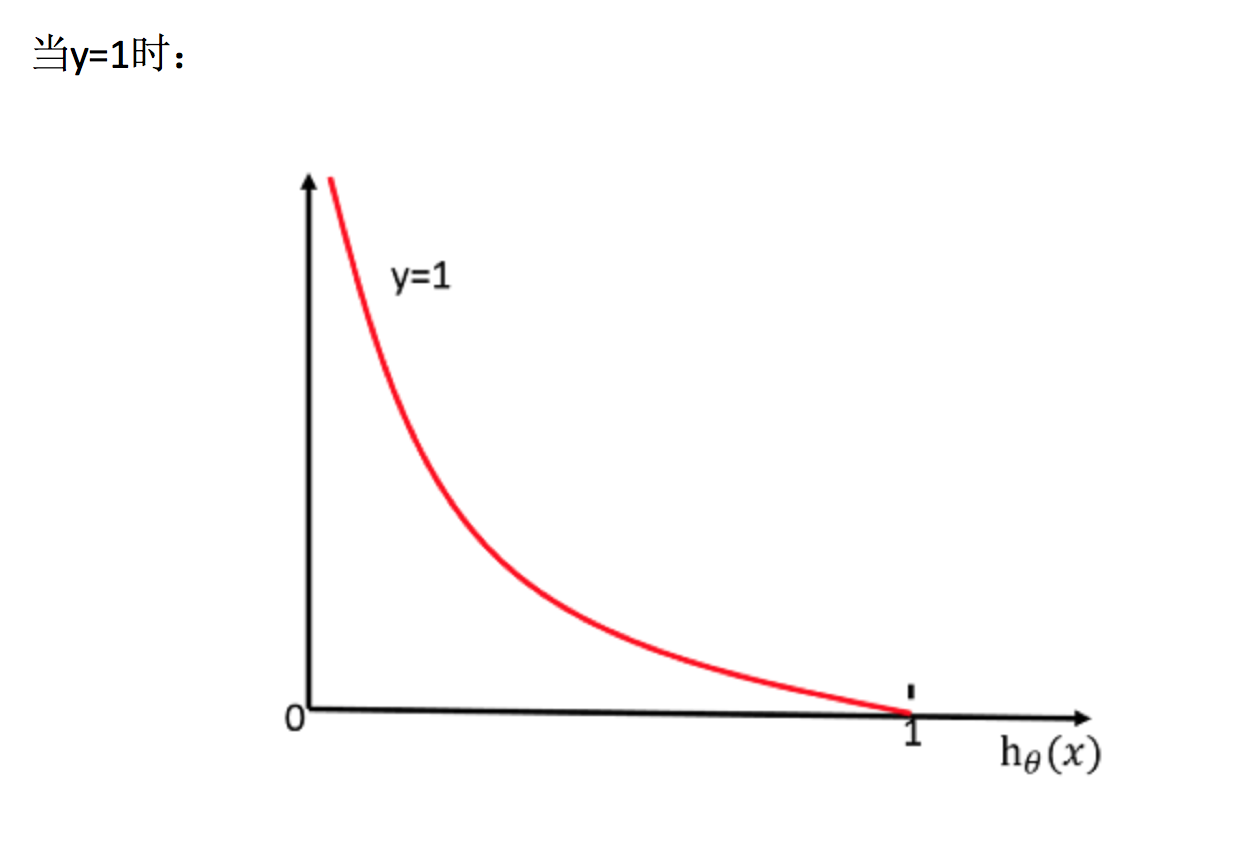
- 綜合完整損失函數
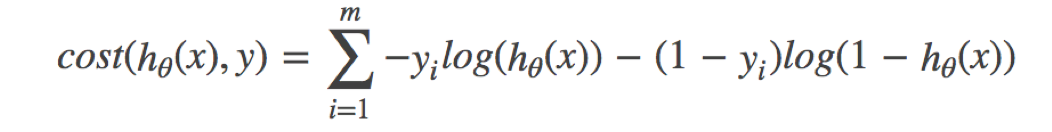
接下來我們呢就帶入上面那個例子來計算一遍,就能理解意義了。

邏輯回歸API
sklearn.linear_model.LogisticRegression(solver=’liblinear’, penalty=『l2』, C = 1.0)
- solver:優化求解方式(默認開源的liblinear庫實現,內部使用了坐標軸下降法來迭代優化損失函數)
- sag:根據數據集自動選擇,隨機平均梯度下降
- penalty:正則化的種類
- C:正則化力度
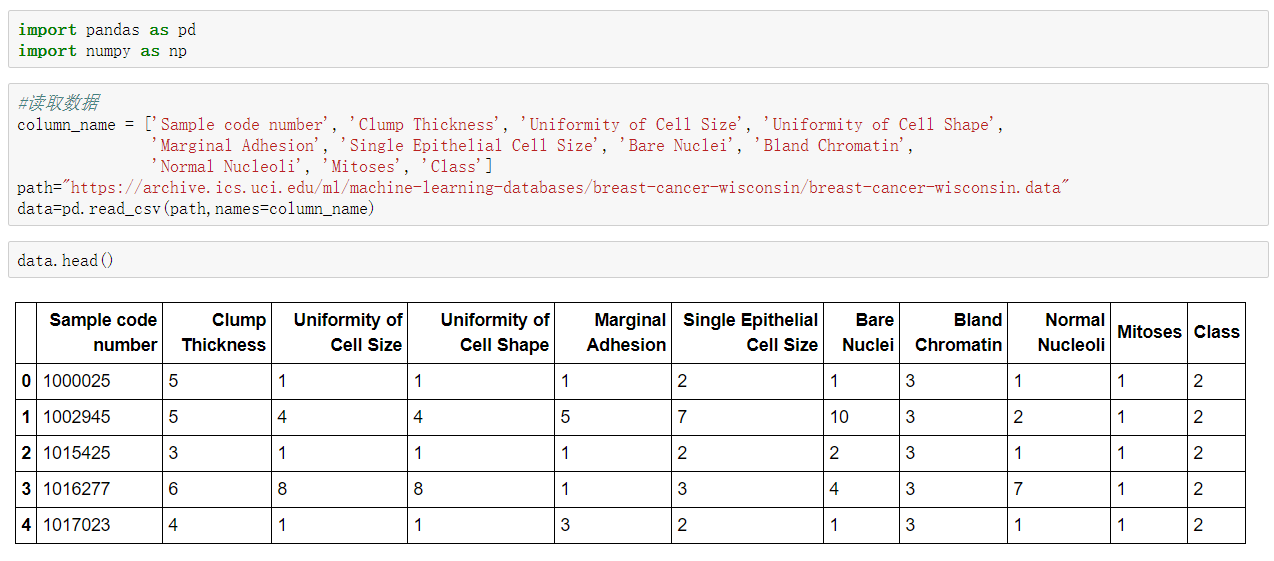
案例:癌症分類預測-良/惡性乳腺癌腫瘤預測
相關數據://archive.ics.uci.edu/ml/machine-learning-databases/
分析
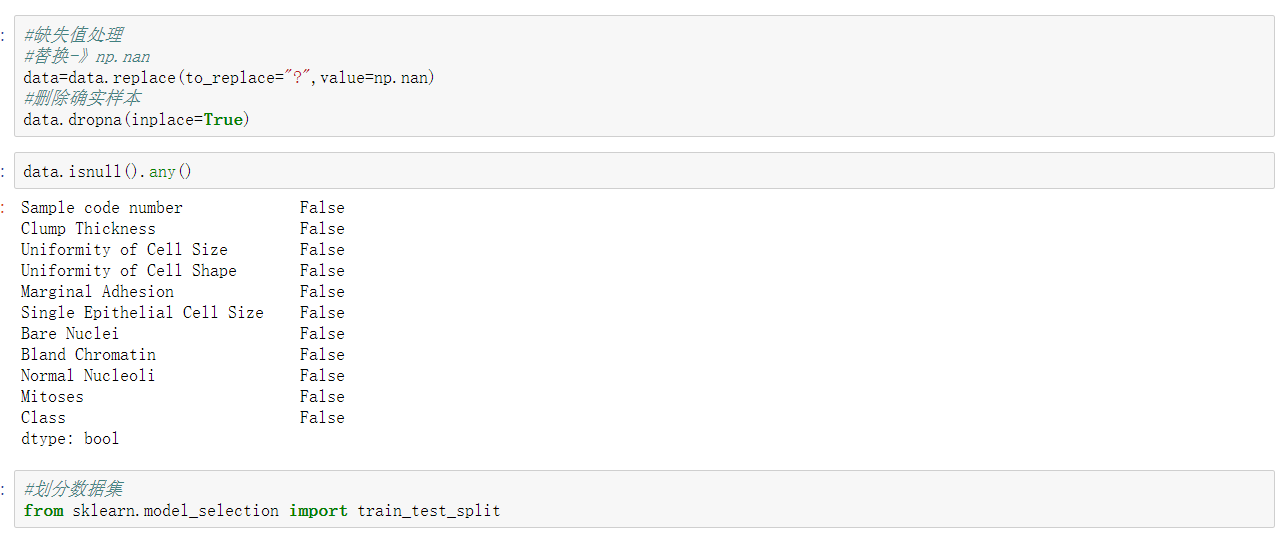
- 缺失值處理
- 標準化處理
- 邏輯回歸預測
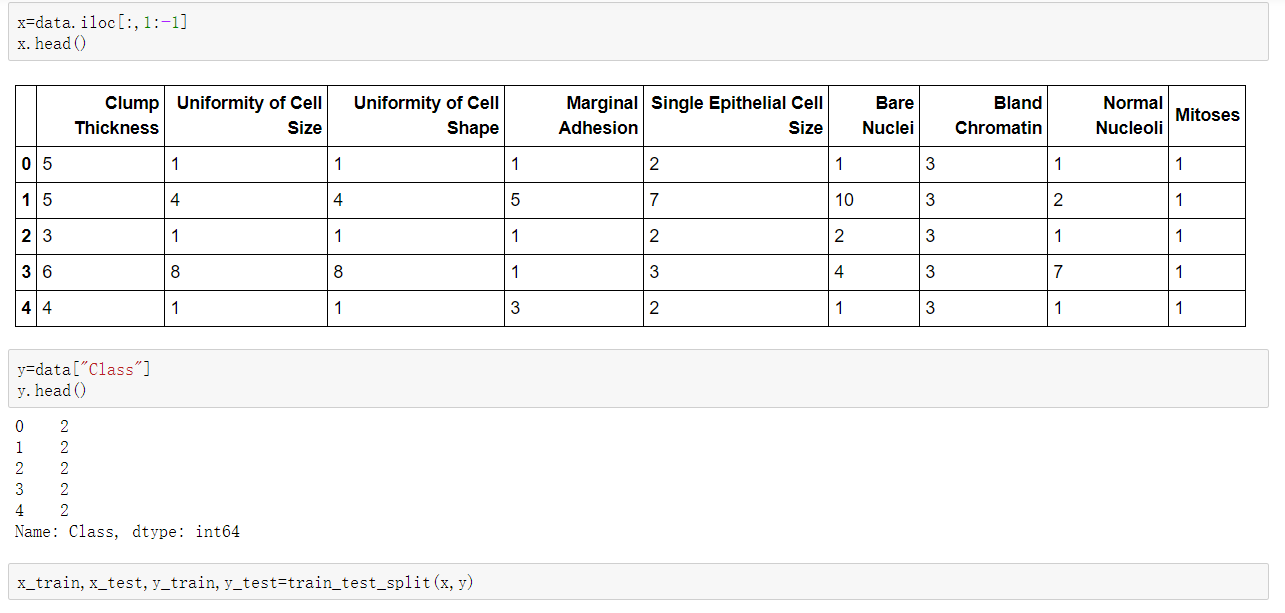
程式碼:
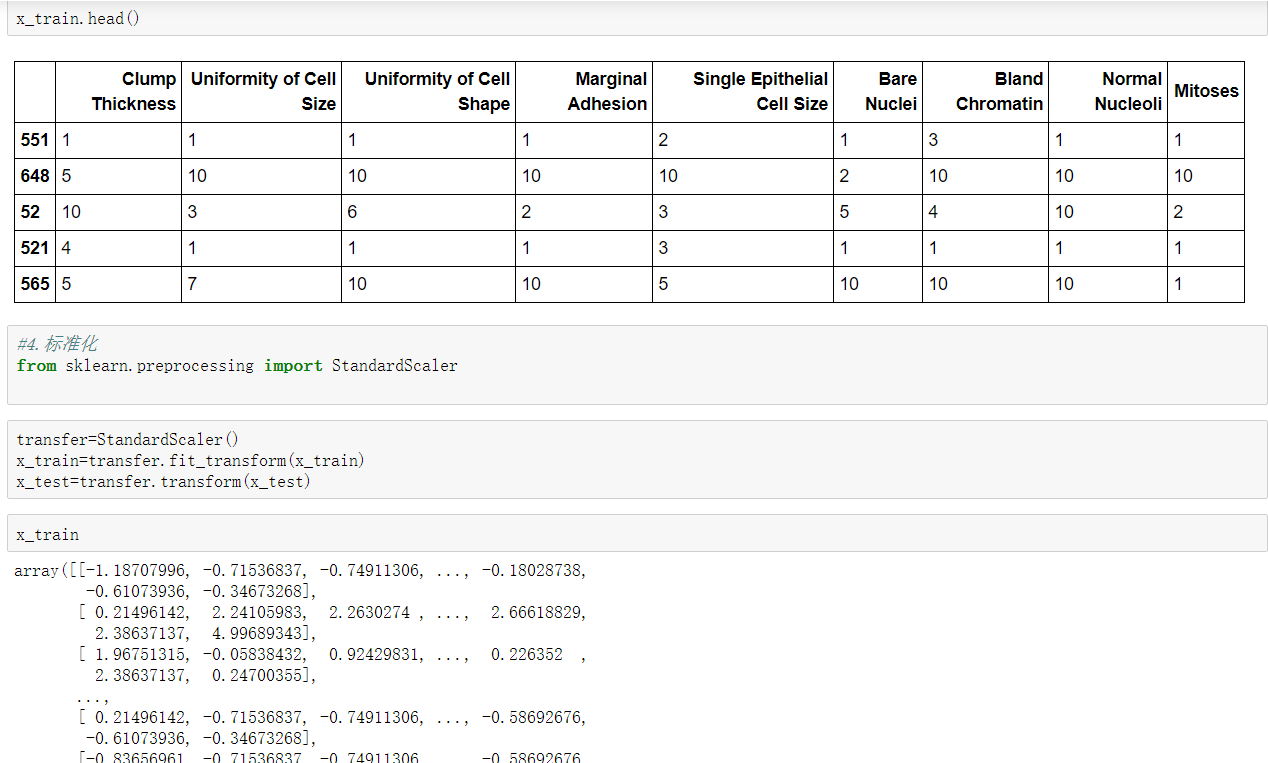
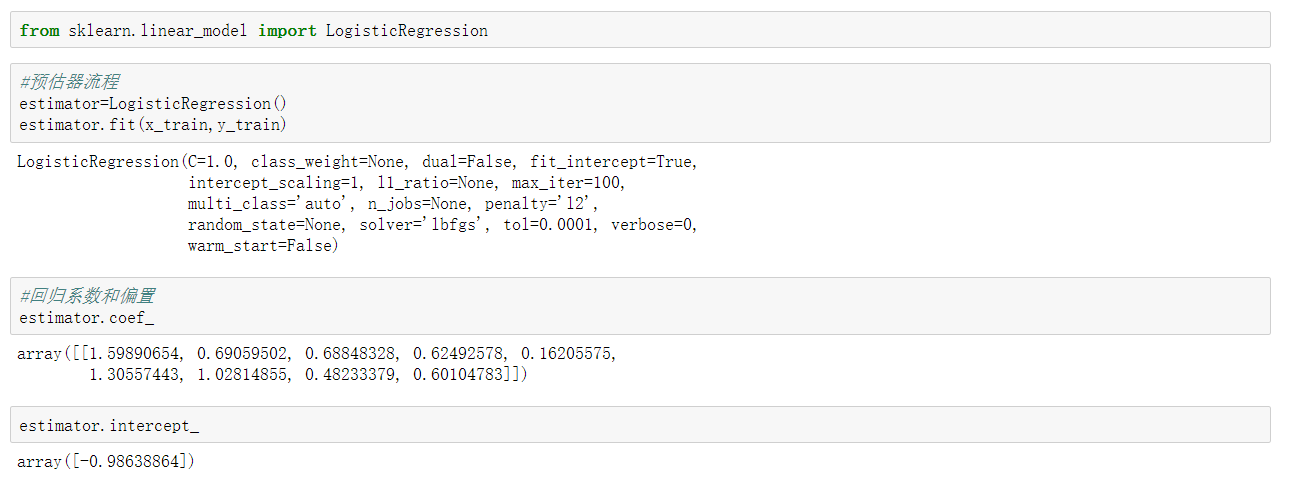
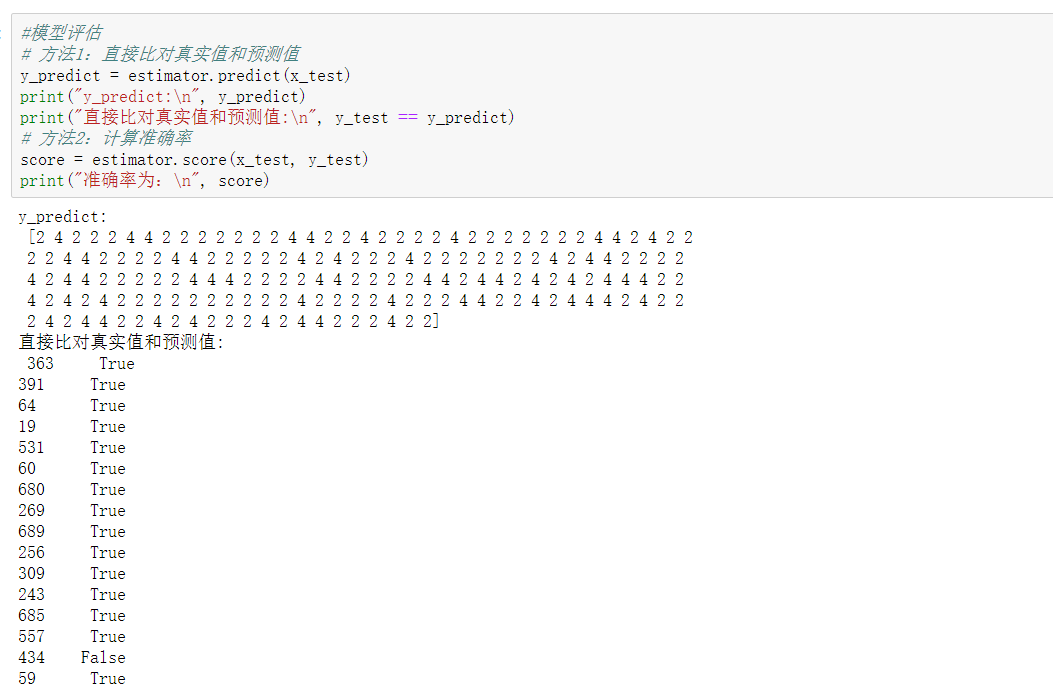
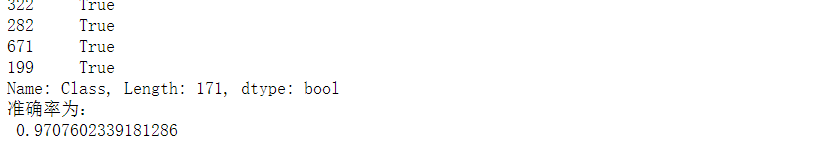
在很多分類場景當中我們不一定只關注預測的準確率!!!!!
比如以這個癌症舉例子!!!我們並不關注預測的準確率,而是關注在所有的樣本當中,癌症患者有沒有被全部預測(檢測)出來。
分類的評估方法
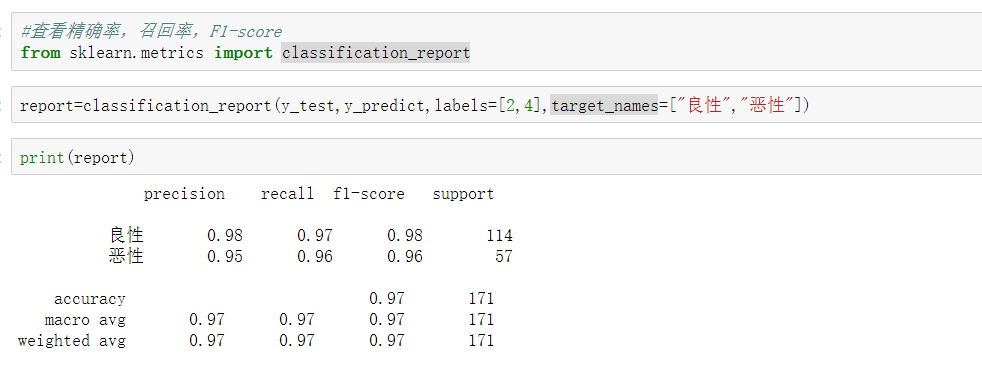
精確率與召回率
在分類任務下,預測結果(Predicted Condition)與正確標記(True Condition)之間存在四種不同的組合,構成混淆矩陣(適用於多分類)
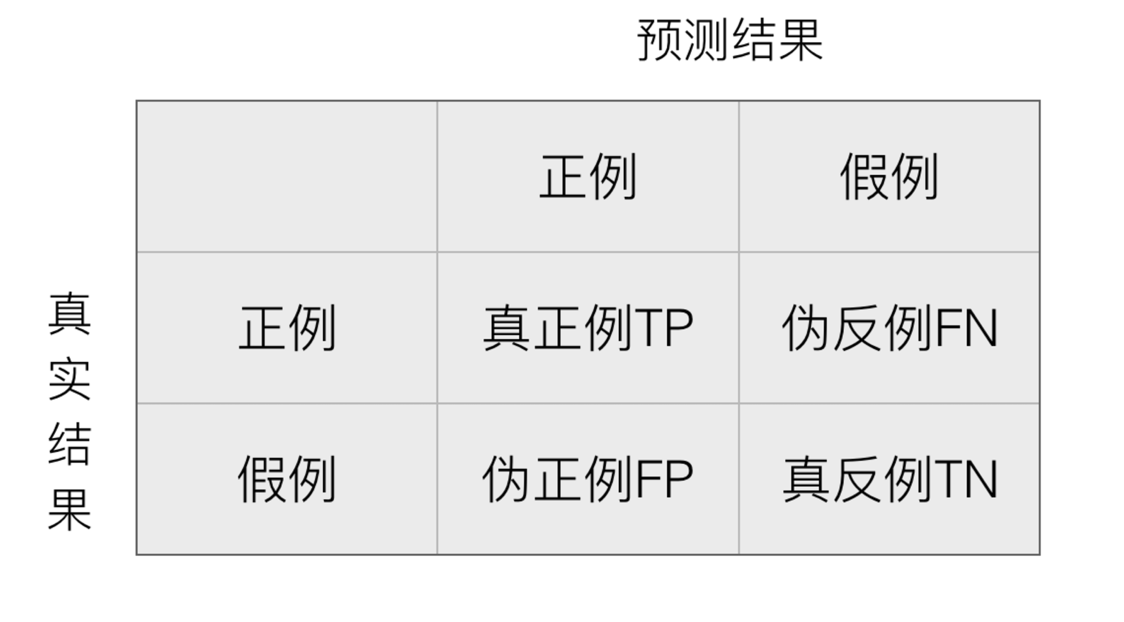
- 精確率:預測結果為正例樣本中真實為正例的比例(了解)

- 召回率:真實為正例的樣本中預測結果為正例的比例(查的全,對正樣本的區分能力)

還有其他的評估標準,F1-score,反映了模型的穩健型
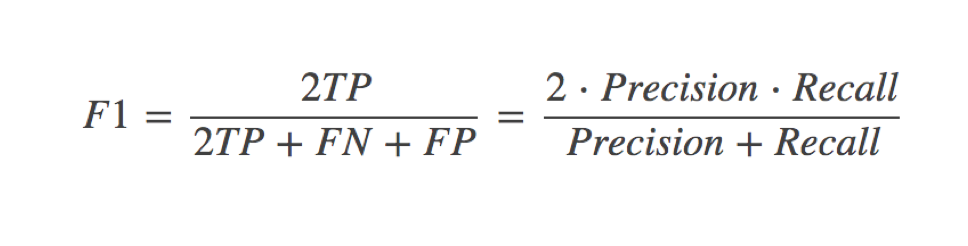
分類評估報告API
- sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
-
- y_true:真實目標值
- y_pred:估計器預測目標值
- labels:指定類別對應的數字
- target_names:目標類別名稱
- return:每個類別精確率與召回率
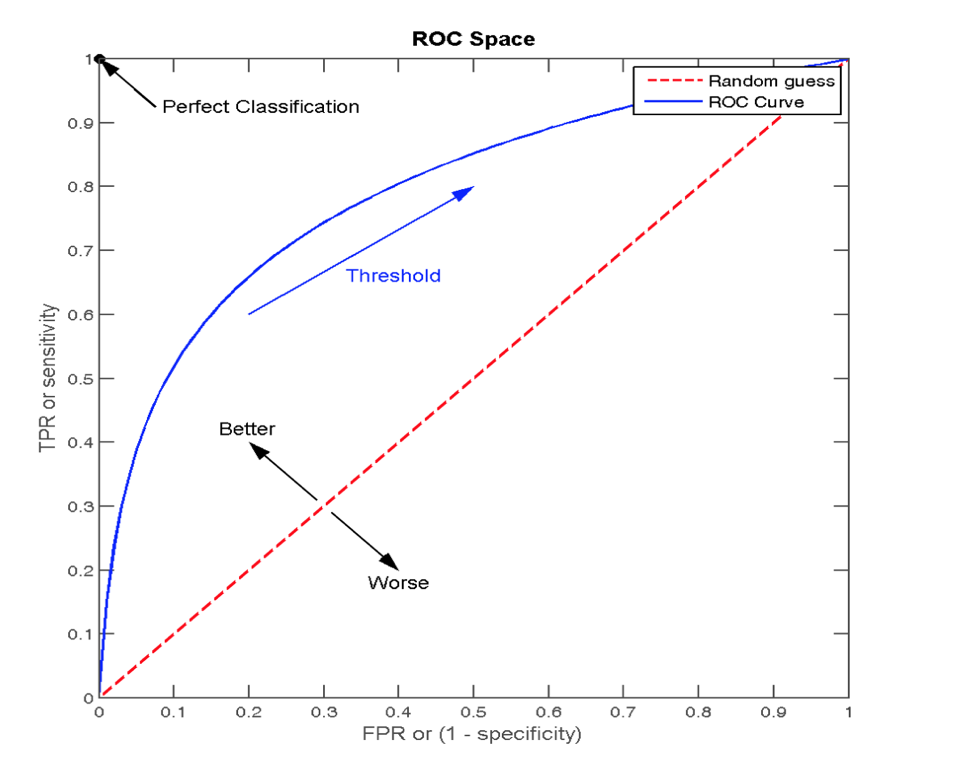
ROC曲線與AUC指標
知道TPR與FPR
- TPR = TP / (TP + FN)
- 所有真實類別為1的樣本中,預測類別為1的比例
- FPR = FP / (FP + FN)
- 所有真實類別為0的樣本中,預測類別為1的比例
ROC曲線
- ROC曲線的橫軸就是FPRate,縱軸就是TPRate,當二者相等時,表示的意義則是:對於不論真實類別是1還是0的樣本,分類器預測為1的概率是相等的,此時AUC為0.5
AUC指標
- AUC的概率意義是隨機取一對正負樣本,正樣本得分大於負樣本的概率
- AUC的最小值為0.5,最大值為1,取值越高越好
- AUC=1,完美分類器,採用這個預測模型時,不管設定什麼閾值都能得出完美預測。絕大多數預測的場合,不存在完美分類器。
- 0.5<AUC<1,優於隨機猜測。這個分類器(模型)妥善設定閾值的話,能有預測價值。
最終AUC的範圍在[0.5, 1]之間,並且越接近1越好
AUC計算API
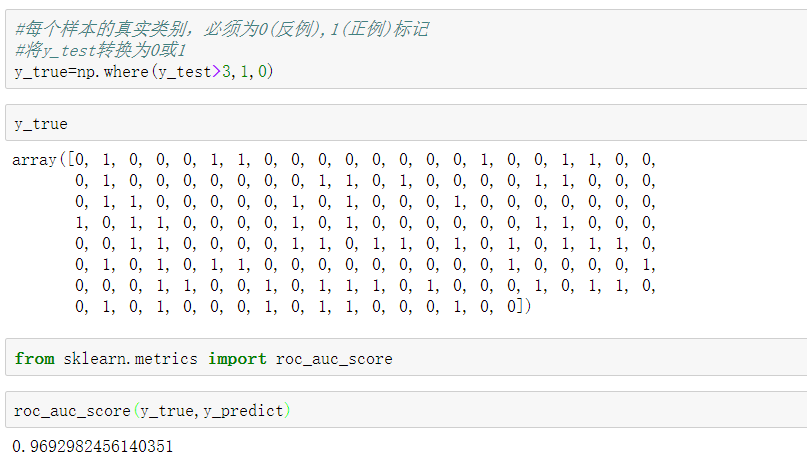
- from sklearn.metrics import roc_auc_score
- sklearn.metrics.roc_auc_score(y_true, y_score)
- 計算ROC曲線面積,即AUC值
- y_true:每個樣本的真實類別,必須為0(反例),1(正例)標記
- y_score:每個樣本預測的概率值
- sklearn.metrics.roc_auc_score(y_true, y_score)
總結
- AUC只能用來評價二分類
- AUC非常適合評價樣本不平衡中的分類器性能


