三種梯度下降演算法的區別(BGD, SGD, MBGD)
前言
我們在訓練網路的時候經常會設置 batch_size,這個 batch_size 究竟是做什麼用的,一萬張圖的數據集,應該設置為多大呢,設置為 1、10、100 或者是 10000 究竟有什麼區別呢?
# 手寫數字識別網路訓練方法
network.fit(
train_images,
train_labels,
epochs=5,
batch_size=128)
批量梯度下降(Batch Gradient Descent,BGD)
梯度下降演算法一般用來最小化損失函數:把原始的數據網路餵給網路,網路會進行一定的計算,會求得一個損失函數,代表著網路的計算結果與實際的差距,梯度下降演算法用來調整參數,使得訓練出的結果與實際更好的擬合,這是梯度下降的含義。
批量梯度下降是梯度下降最原始的形式,它的思想是使用所有的訓練數據一起進行梯度的更新,梯度下降演算法需要對損失函數求導數,可以想像,如果訓練數據集比較大,所有的數據需要一起讀入進來,一起在網路中去訓練,一起求和,會是一個龐大的矩陣,這個計算量將非常巨大。當然,這也是有優點的,那就是因為考慮到所有訓練集的情況,因此網路一定在向最優(極值)的方向在優化。
隨機梯度下降(Stochastic Gradient Descent,SGD)
與批量梯度下降不同,隨機梯度下降的思想是每次拿出訓練集中的一個,進行擬合訓練,進行迭代去訓練。訓練的過程就是先拿出一個訓練數據,網路修改參數去擬合它並修改參數,然後拿出下一個訓練數據,用剛剛修改好的網路再去擬合和修改參數,如此迭代,直到每個數據都輸入過網路,再從頭再來一遍,直到參數比較穩定,優點就是每次擬合都只用了一個訓練數據,每一輪更新迭代速度特別快,缺點是每次進行擬合的時候,只考慮了一個訓練數據,優化的方向不一定是網路在訓練集整體最優的方向,經常會抖動或收斂到局部最優。
小批量梯度下降(Mini-Batch Gradient Descent,MBGD)
小批量梯度下降採用的還是電腦中最常用的折中的解決辦法,每次輸入網路進行訓練的既不是訓練數據集全體,也不是訓練數據集中的某一個,而是其中的一部分,比如每次輸入 20 個。可以想像,這既不會造成數據量過大計算緩慢,也不會因為某一個訓練樣本的某些雜訊特點引起網路的劇烈抖動或向非最優的方向優化。
對比一下這三種梯度下降演算法的計算方式:批量梯度下降是大矩陣的運算,可以考慮採用矩陣計算優化的方式進行並行計算,對記憶體等硬體性能要求較高;隨機梯度下降每次迭代都依賴於前一次的計算結果,因此無法並行計算,對硬體要求較低;而小批量梯度下降,每一個次迭代中,都是一個較小的矩陣,對硬體的要求也不高,同時矩陣運算可以採用並行計算,多次迭代之間採用串列計算,整體來說會節省時間。
看下面一張圖,可以較好的體現出三種剃度下降演算法優化網路的迭代過程,會有一個更加直觀的印象。
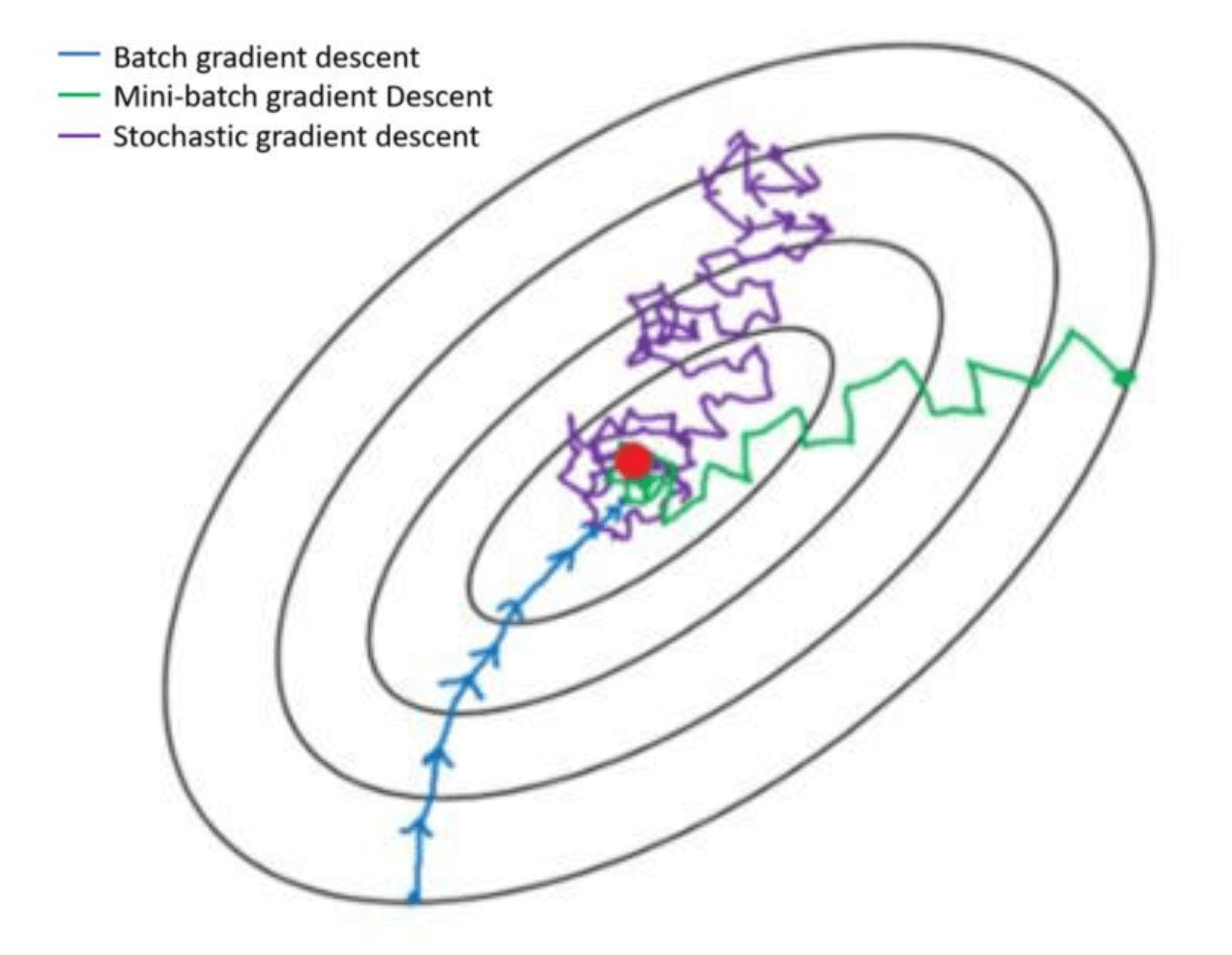
總結
梯度下降演算法的調優,訓練數據集很小,直接採用批量梯度下降;每次只能拿到一個訓練數據,或者是在線實時傳輸過來的訓練數據,採用隨機梯度下降;其他情況或一般情況採用批量梯度下降演算法更好。
- 本文首發自: RAIS

