李宏毅機器學習課程筆記-4.1分類簡介及其與回歸的區別
分類模型應用案例(Classification Cases)
- 信用評分(Credit Scoring)
- 輸入:收入、儲蓄、職業、年齡、信用歷史等等
- 輸出:是否貸款
- 醫療診斷(Medical Diagnosis)
- 輸入:現在癥狀、年齡、性別、病史
- 輸出:哪種疾病
- 手寫文字識別(Handwritten Character Recognition)
- 輸入:文字圖片
- 輸出:是哪一個漢字
- 人臉識別(Face Recognition)
- 輸入:面部圖片
- 輸出:是哪個人
把分類當成回歸去做?
不行。
-
假設有兩個類別,其中類別1的標籤為1,類別2的標籤為-1,那0就是分界線,大於0就是類別1,小於0就是類別2。
回歸模型會懲罰那些太正確的樣本。如果結果遠遠大於1,它的分類應該是類別1還是類別2?這時為了降低整體誤差,需要調整已經找到的回歸函數,就會導致結果的不準確。
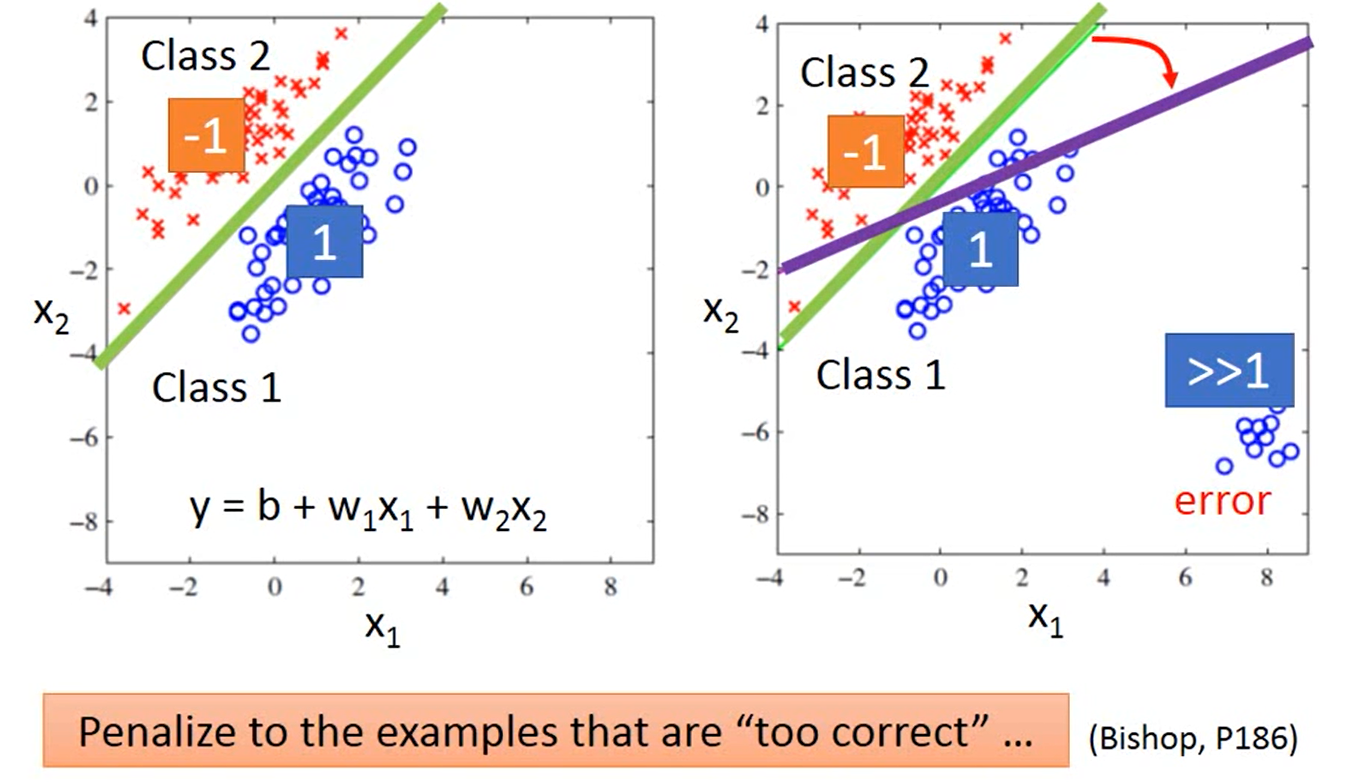
-
假設有多個類別,類別1的標籤是1,類別2的標籤是2,類別3的標籤是3。
這樣的話,標籤間具有2和3相近、3大於2這種本來不存在的數字關係。

理想替代方案(Ideal Alternatives)
-
模型
模型可以根據特徵判斷類型,輸入是特徵,輸出是類別
-
損失函數
預測錯誤的次數,即\(L(f)=\sum_n\delta(f(x^n)\neq\hat y^n)\)。
這個函數不可微
-
如何找到最好的函數
比如感知機(Perceptron)、支援向量機(SVM)
Github(github.com):@chouxianyu
Github Pages(github.io):@臭鹹魚
知乎(zhihu.com):@臭鹹魚
部落格園(cnblogs.com):@臭鹹魚
B站(bilibili.com):@絕版臭鹹魚
微信公眾號:@臭鹹魚的快樂生活
轉載請註明出處,歡迎討論和交流!


