HashMap原理。圖文並茂式解讀。這些注意點你一定還不了解
- 2019 年 10 月 3 日
- 筆記
概述
本篇文章我們來聊聊大家日常開發中常用的一個集合類 – HashMap。HashMap 最早出現在 JDK 1.2中,底層基於散列演算法實現。HashMap 允許 null 鍵和 null 值,在計算哈鍵的哈希值時,null 鍵哈希值為 0。HashMap 並不保證鍵值對的順序,這意味著在進行某些操作後,鍵值對的順序可能會發生變化。另外,需要注意的是,HashMap 是非執行緒安全類,在多執行緒環境下可能會存在問題。
屬性詳解
DEFAULT_INITIAL_CAPACITY 默認初始容量
MAXIMUM_CAPACITY 最大容量
DEFAULT_LOAD_FACTOR 默認負載因子
TREEIFY_THRESHOLD 一個桶的樹化閾值(超過此值會變成紅黑樹)
UNTREEIFY_THRESHOLD 一個樹的鏈表還原閾值(小於此值在resize的時候會變回鏈表)
MIN_TREEIFY_CAPACITY 哈希表的最小樹形化容量(為了避免進行擴容、樹形化選擇的衝突,這個值不能小於 4 * TREEIFY_THRESHOLD)
table
HashMap中的數組(hash表)。hash表的長度總是在2^n。至於原因嗎,後面專門會說的。數組裡存儲的是Node節點的數據
entrySet
Node<K,V> 節點構成的 set
size
當前map中存儲節點的數據
modCount
hashMap發生結構性變化的次數,節點轉紅黑樹、擴容等操作。
threshold、loadFactor
擴容闕值和裝載因子。
源碼知識點必備
getGenericInterfaces和getInterfaces區別
getGenericInterfaces獲取直接介面
getInterfaces獲取所有介面
ParameterizedType
是Type的子介面,表示一個有參數的類型。就是我們俗稱的泛型。實現這個介面的類必須提供equals方法。
getRawType
返回最外層<>前面那個類型,即Map<K ,V>的Map。
getActualTypeArguments
獲取「泛型實例」中<>裡面的「泛型變數」(也叫類型參數)的值,這個值是一個類型。因為可能有多個「泛型變數」(如:Map<K,V>),所以返回的是一個Type[]。
注意:無論<>中有幾層<>嵌套,這個方法僅僅脫去最外層的<>,之後剩下的內容就作為這個方法的返回值,所以其返回值類型是不確定的。
getOwnerType
獲得這個類型的所有者的類型,主要對嵌套定義的內部類而言。列如對java.util.Map.Node<K,V> 調用getOwnerType方法返回的是interface java.util.Map介面
comparableClassFor
HashMap類中有一個comparableClassFor(Object x)方法,當x的類型為X,且X直接實現了Comparable介面(比較類型必須為X類本身)時,返回x的運行時類型;否則返回null。通過這個方法,我們可以搞清楚一些與類型、泛型相關的概念和方法
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
hashCode與自己的高16為進行異或 。 這樣更分散
ps:
& : 全部為1則為1,否則為0 偏0
| : 有一個為1則為1,否則為0 偏1
^ : 相同為0 不同為1 更加均衡。 均勻(分散)
hash表維護
在文章開頭我們就解釋了HashMap中table就是我們的hash表。直觀上我們可以理解成一個開闢空間的數組。HashMap通過hash(key)這個方法獲取hash值。然後通過hash值確定key在hash表中的位置((n - 1) & hash)。
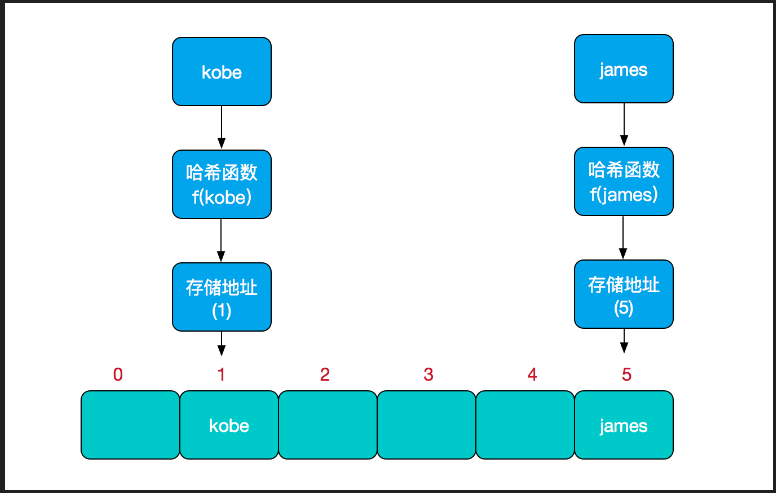
綜合上圖我們也會發現問題了。key的個數是無限的。但是我們的hash表是有限的。如何能保證hash(key)不會落在同一個位置呢。答案是不能。換句話說就是我們hash(key)無法保證。也就是hashMap會發生hash碰撞的。hash函數只能盡量避免hash碰撞。上面的(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)就是為了讓hash更加分散點。這一點上面也作出了解釋。
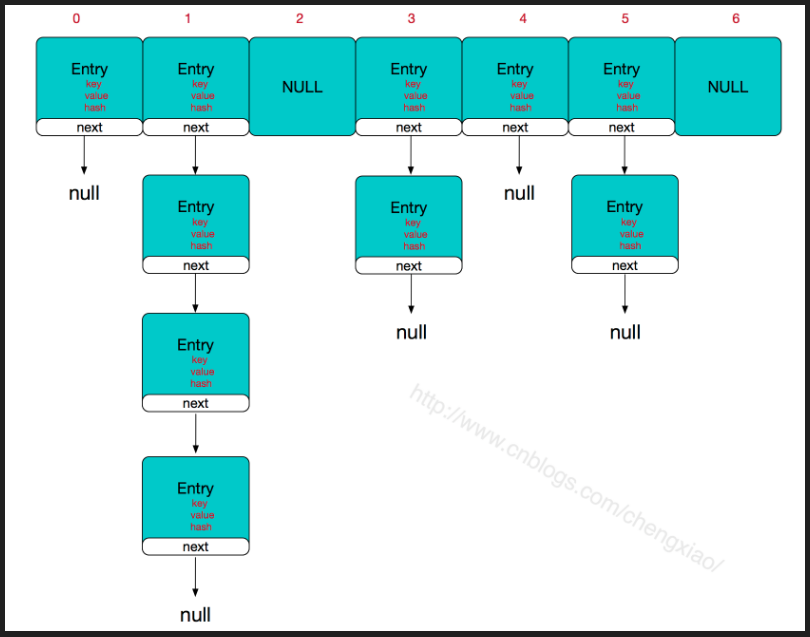
HashMap 數組長度是2^n ?
上面解釋了hashmap中hash函數為什麼要^ 。 那麼深度源碼的小夥伴可能會問,為什麼hashmap默認容量是16以及後期每次擴容的時候為什麼是翻倍擴容。簡而言之。為什麼hashMap數組長度永遠是2的倍數呢。
上面我們知道如何通過hash確定在數組中位置的。
(n - 1) & hash
關於這個n是數組的長度,hash就是key值通過hash函數計算出來的hash值。
& 運算規則是: 全部為1則為1,否則為0
假設目前hashMap容量是16 , 我們來看看在擴容前後我們key的在是數組中的索引。
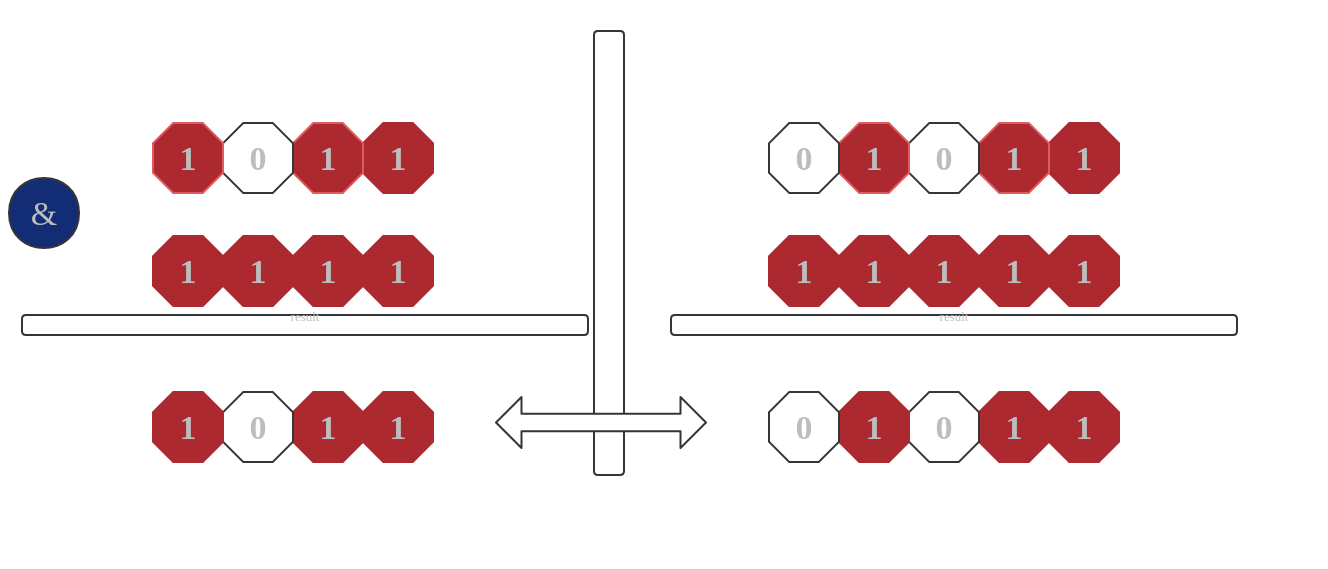
經過圖片鮮明的對比我們發現,擴容前後是不會影響原來數據(高位為0)的索引位置的。這裡要注意的是並不是說所有數據不受影響,只要原來從右至左第五位為0的hash會受影響,其他不會。這樣大大減少了數組位置調換的操作。性能上也大大的提高了。從這裡也可以看出hashmap容量越大,擴容是越複雜,因為容量越大,需要換位置的索引越多。
那麼如果我們擴容是不是選擇擴大2倍 , 我們看看會發生什麼樣情況。
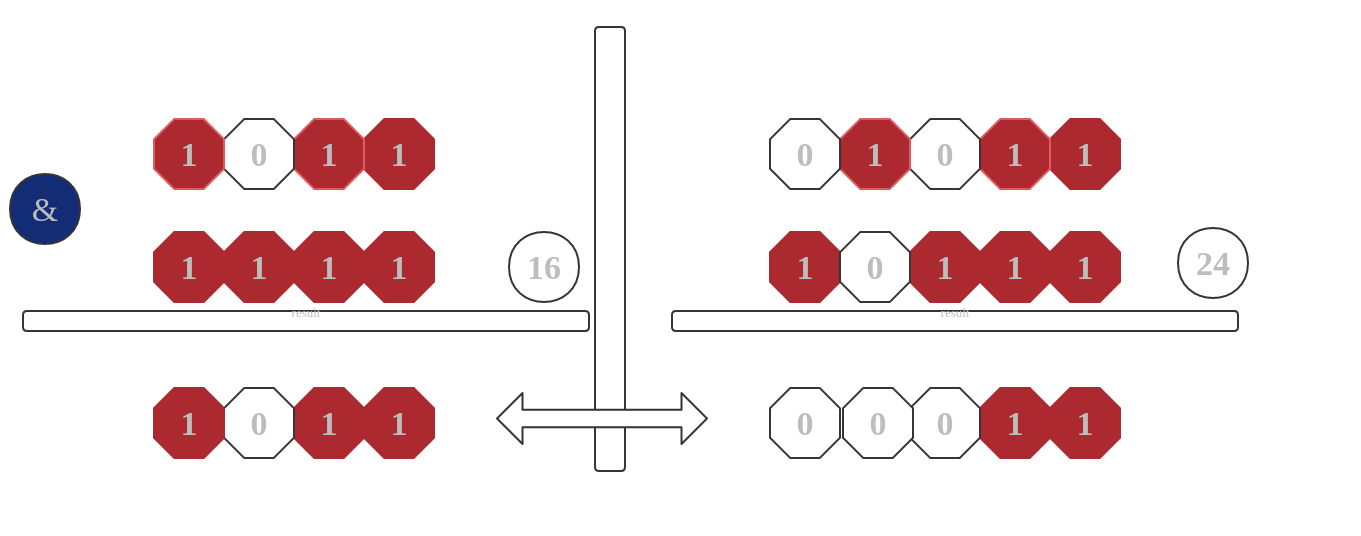
上圖中是有16擴展成了24容量。這個時候我們會發現除了(從右至左)第五位以為第四位的數據也發生了變化。這樣造成的介面是第四位和第五位的數據都會變化。這樣增加了索引位置的數量。所以我們需要在每次擴容為原來的2倍。
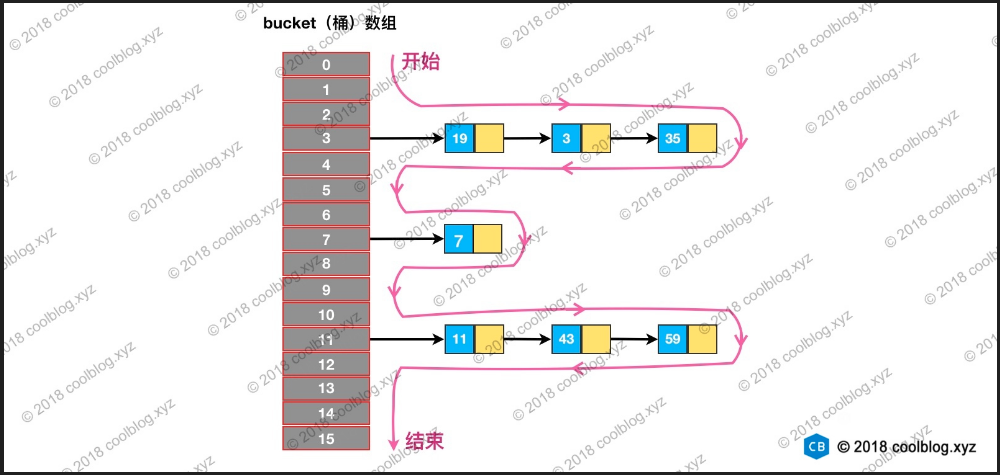
神奇的hashmap遍歷
做Java的肯定會遇到的一種情況是,為什麼我的map遍歷的順序和我添加的順序不一致呢。有時候我們做列表展示的時候對順序是有要求的。但是hashmap偏偏和我們想的不一樣。今天華仔帶你看看為什麼會出現這種神奇的遍歷。
public final void forEach(Consumer<? super K> action) { Node<K,V>[] tab; if (action == null) throw new NullPointerException(); if (size > 0 && (tab = table) != null) { int mc = modCount; for (int i = 0; i < tab.length; ++i) { for (Node<K,V> e = tab[i]; e != null; e = e.next) action.accept(e.key); } if (modCount != mc) throw new ConcurrentModificationException(); } } 從上面的程式碼我們可以看出來hashmap在遍歷時候,是先遍曆數組然後取到數組中鏈表(紅黑樹)按照順序獲取node節點的。也即是說我們先按數組再按鏈表順序。而不是按照你添加先後的順序。而上面我們了解添加的node決定其位置的是key的hash值。所以這就解釋了為什麼hashmap遍歷的時候和我們添加不一致的了。
put 流程跟蹤
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } 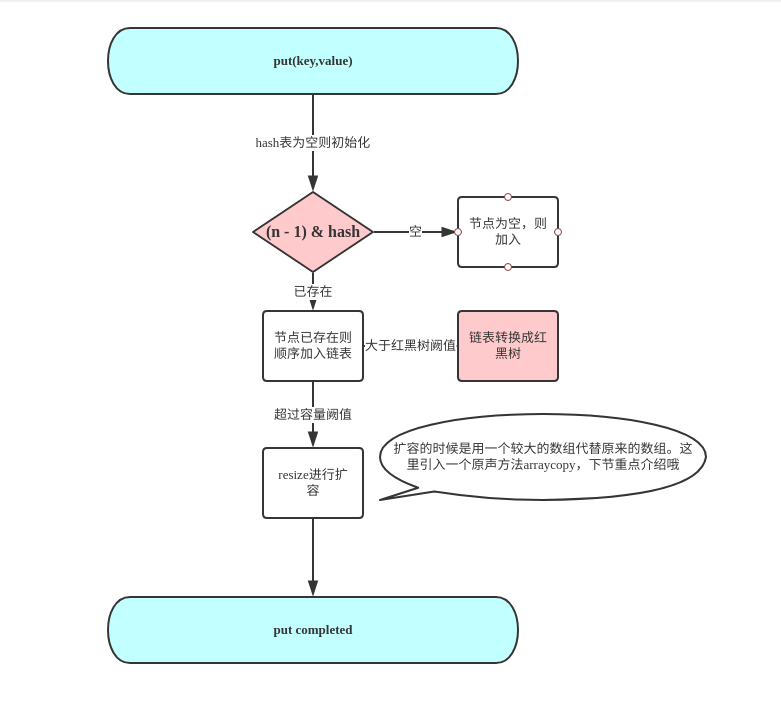
其他方法原理是相同的。值得注意的是remove後臨界情況會發生紅黑樹轉鏈表。所以轉紅黑樹的這個闕值的選取有時候會影響性能的高低。下面看看put的實際源碼吧。拜讀下大佬的程式碼。
上面的程式碼可以看出來put實際調用的方法是putVal();
int hash : key對應的hash值
K key, : key
V value, : value
onlyIfAbsent : 如果存在則忽略,默認false表示新值會覆蓋舊值
boolean evict: 表示是否在構造table時調用
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } 寒暄一句
個人幾天時間總結的,有網上前輩的總結,也有加入個人的想法。
再次申明:以上圖片部分來自網路。
# 加入戰隊
微信公眾號

