keycloak集群化的思考
簡介
單體服務如果想要突破到高並發服務就需要升級為集群服務。同時集群化也為高可用打下了堅實的基礎。縱觀現在比較流行的服務或者中間件,不管是RabbitMQ還是redis都提供了集群的功能。
作為硬核工業代表的wildfly也不例外,最近研究了一下keycloak的集群,發現它的底層伺服器用的也是wildfly,本文將會和大家探討一下keycloak的集群的架構思路。
keycloak中的集群
我們知道,keycloak中有兩種模式,一種叫做Standalone,一種叫做domain。
這兩種模式的區別只是在於部署文件是否被集中管理,如果部署文件需要一個一個的手動拷貝,那麼就是standalone模式。如果是一鍵化的自動安裝,那麼就是domain模式。
standalone模式下有一個配置文件叫做 /standalone/configuration/standalone-ha.xml,這個就是在standalone模式下配置集群的xml文件了。
而domain模式下,配置文件都是在domain controller這個機子上進行配置的,具體的文件是 domain/configuration/domain.xml 。
我們看下ha具體是用的集群相關的組件:
<profile name="full-ha">
...
<subsystem xmlns="urn:jboss:domain:modcluster:5.0">
<proxy name="default" advertise-socket="modcluster" listener="ajp">
<dynamic-load-provider>
<load-metric type="cpu"/>
</dynamic-load-provider>
</proxy>
</subsystem>
<subsystem xmlns="urn:jboss:domain:infinispan:11.0">
...
</subsystem>
<subsystem xmlns="urn:jboss:domain:jgroups:8.0">
<channels default="ee">
<channel name="ee" stack="udp" cluster="ejb"/>
</channels>
<stacks>
<stack name="udp">
...
</stack>
<stack name="tcp">
...
</stack>
</stacks>
</subsystem>
...
</profile>
主要用的是modcluster,infinispan和jgroups。
除此之外,keycloak還介紹了一種叫做跨數據中心的集群
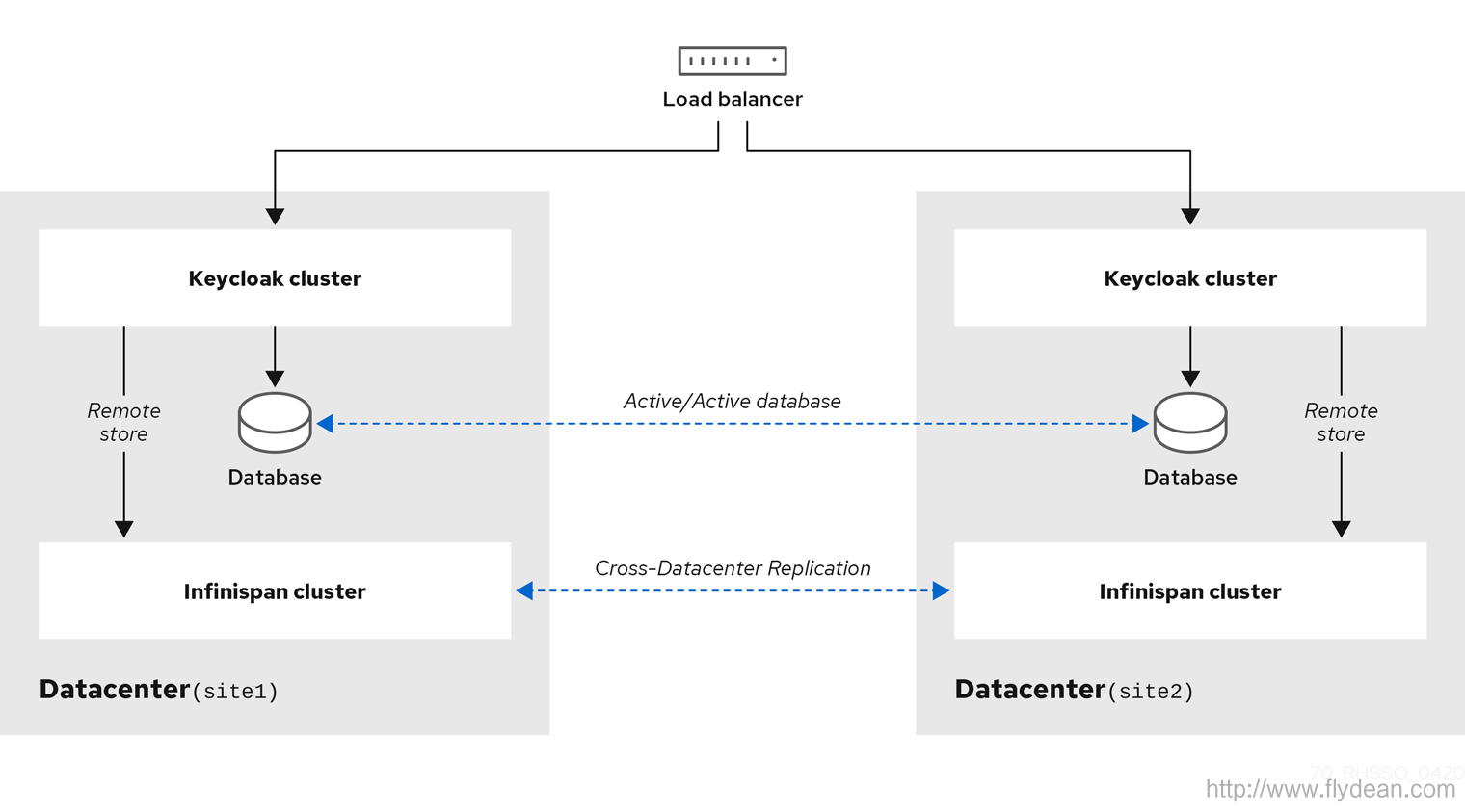
這種模式主要用在服務是跨數據中心的情況,比如說異地機房這樣的容災性特彆強的情況。
看完keycloak的基本集群搭建之後,我們來講一下keycloak集群中一些比較關鍵的概念和使用。
load balancing負載均衡
因為是集群結構,所以我們後端是有多台伺服器的,那麼用戶通過客戶端來訪問我們服務的時候,究竟應該定位到哪一台伺服器呢?
這時就要用到負載均衡軟體了,也就是load balancing。
一般來說三種負載均衡的方式:
第一種,就是客戶端負載均衡,客戶端已經知道了服務端的多個服務地址,在發送請求的時候由客戶端自行選擇要請求的服務地址。
這種模式一般都要配置一個強力的客戶端API,通過這個客戶端API來進行路由功能,比如說Memcached。
Memcached的神奇來自兩階段哈希(two-stagehash)。Memcached就像一 個巨大的、存儲了很多<key,value>對的哈希表。通過key,可以存儲或查詢任意的數據。
客戶端可以把數據存儲在多台memcached上。當查詢數據時,客戶端首 先參考節點列表計算出key的哈希值(階段一哈希),進而選中一個節點;客戶端將請求發送給選中的節點,然後memcached節點通過一個內部的哈希演算法(階段二哈希),查找真正的數據(item)。
第二種,就是代理服務負載均衡,這種模式下,會有一個代理伺服器和後端的多個服務進行連接,客戶端是和這個代理伺服器進行交互,由代理伺服器來代替客戶端選擇到底要路由到哪個服務。
這種代理的路由的軟體就多了,比如我們熟悉的nginx和HTTPD,還有ildFly with mod_cluster, HA Proxy, 或者其他的硬體負載均衡。
第三種,是路由負載均衡,在這種模式下,用戶隨機選擇一個後端伺服器進行請求連接,然後在伺服器內部進行路由,將這個請求發送到其他的伺服器中。
這種模式下,一般需要在伺服器內部實現特定的負載均衡功能。
暴露客戶端IP地址
不管使用的是什麼模式的負載均衡,我們都有可能在業務中需要使用到客戶訪問的IP地址。
我們在特定的業務中需要獲取到用戶的ip地址來進行一些操作,比如記錄用戶的操作日誌,如果不能夠獲取到真實的ip地址的話,則可能使用錯誤的ip地址。還有就是根據ip地址進行的認證或者防刷工作。
如果我們在服務之前使用了反向代理伺服器的話,就會有問題。所以需要我們配置反向代理伺服器,保證X-Forwarded-For和X-Forwarded-Proto這兩個HTTP header的值是有效的。
然後伺服器端就可以從X-Forwarded-For獲取到客戶的真實ip地址了。
在keycloak中,如果是http forwarding,則可以這樣配置:
<subsystem xmlns="urn:jboss:domain:undertow:10.0">
<buffer-cache name="default"/>
<server name="default-server">
<ajp-listener name="ajp" socket-binding="ajp"/>
<http-listener name="default" socket-binding="http" redirect-socket="https"
proxy-address-forwarding="true"/>
...
</server>
...
</subsystem>
如果是AJP forward, 比如使用的是Apache HTTPD + mod-cluster, 則這樣配置:
<subsystem xmlns="urn:jboss:domain:undertow:10.0">
<buffer-cache name="default"/>
<server name="default-server">
<ajp-listener name="ajp" socket-binding="ajp"/>
<http-listener name="default" socket-binding="http" redirect-socket="https"/>
<host name="default-host" alias="localhost">
...
<filter-ref name="proxy-peer"/>
</host>
</server>
...
<filters>
...
<filter name="proxy-peer"
class-name="io.undertow.server.handlers.ProxyPeerAddressHandler"
module="io.undertow.core" />
</filters>
</subsystem>
sticky sessions 和 非sticky sessions
如果是在存在session的環境中,比如說web應用程式中,如果後端伺服器是cluster的情況下還需要考慮session共享的問題。
因為對於每個伺服器來說,它的session都是本地維護的,如果是多台伺服器想要session共享該怎麼辦呢?
一種辦法就是所有的伺服器都將session存放在同一個外部快取系統中,比如說redis。這樣不管用戶訪問到哪個server,都可以讀取到同一份session數據。
當然,這個快取系統可以是單點也可以是集群,如果是不同的數據中心的話,快取集群甚至還需要跨數據中心進行同步。
快取同步當然是一個很好的辦法,但是同步行動自然是有開銷的。有沒有更加簡單方便的處理方式呢? 比如固定一個用戶只訪問同一個伺服器這樣是不是就能解決快取同步的問題呢?
這種固定用戶訪問特定某個伺服器的模式,我們叫做sticky sessions模式。在這種模式下,可以不用考慮session同步的問題。當然,這種模式下,如果某個伺服器down機了,用戶的session就會丟失。所以還是要做一些session同步的工作,只不過不需要實時的同步而已。
另外,sticky session還有一個缺點:如果是後台的請求,則獲取不到session的資訊,也就無法實現sticky session,這個時候就需要進行後台數據的拷貝,這樣才能保證不管請求發送到哪裡都能夠表現一致。
shared databases
所有的應用都需要保存數據。通常來說,我們會有兩種數據:
一種是資料庫數據,這種數據將會永久存儲用戶資訊。
一種是cache,用作資料庫和應用程式的緩衝。
不管是哪種數據,都可以有集群模式,也就是多台伺服器同時讀寫數據。這樣對於共享的數據就涉及到了集群數據更新的問題。
集群數據的更新有兩種更新模式:
一種是可靠優先,Active/Active mode,一個節點更新的數據會立馬同步到另外一個節點。
一種是性能優先,Active/Passive mode,一個節點更新的數據不會立馬同步到另外一個節點中。
可靠優先的運行邏輯是,一個更新請求需要等待所有的集群服務返回更新成功才算成功。而性能優先的運行邏輯就是更新完主數據就算成功了,其他的節點會去非同步和主數據節點進行同步。
keycloak中使用的快取是infinispan,並且構建了多種session快取,不同的快取使用的是不同的同步策略:
-
authenticationSessions:這個快取保存的是登錄用戶的資訊,如果在sticky sessions模式下,是不需要進行數據同步的。
-
Action tokens:如果用戶需要非同步的進行郵件驗證,比如說忘記密碼等操作,則需要用到這種類型的快取。因為這種操作中的token只能夠被使用一次,所以需要數據的同步。
-
非認證的session資訊:因為不能保證sticky session模式的使用,所以需要複製。
-
loginFailures: 統計用戶的登錄異常情況,不需要被複制。
在快取保存數據,需要注意數據更新後的失效問題。
在keycloak中,使用了一個單獨的work快取,這個快取是所有數據中心同步的,它不存儲實際的數據,只存儲要無效的數據通知。各個數據的服務從work快取中讀取無效的數據列表,進行相應的數據快取無效化處理。
multicasting
最後,如果集群需要動態發現和管理節點的功能的話,還需要進行IP廣播。比如說可以使用JGroups來實現這個功能。
總結
keycloak的底層是wildfly,本身已經支援很多強大的工業組件,它的設計理念是讓程式業務邏輯和其他的通用的生產級特性(高可用,負載均衡,快取集群,消息隊列等)區分開,只用專註於業務邏輯的實現和編寫,其他的事情交給伺服器去做即可。
大家可以多研究下這些優秀的伺服器框架,可以得到一些不同的體會。
本文作者:flydean程式那些事
本文鏈接://www.flydean.com/keycloak-cluster-in-depth/
本文來源:flydean的部落格
歡迎關注我的公眾號:「程式那些事」最通俗的解讀,最深刻的乾貨,最簡潔的教程,眾多你不知道的小技巧等你來發現!

