數倉建設中最常用模型–Kimball維度建模詳解
數倉建模首推書籍《數據倉庫工具箱:維度建模權威指南》,本篇文章參考此書而作。
文章首發公眾號:五分鐘學大數據,公眾號中發送「維度建模」即可獲取此書籍第三版電子書
先來介紹下此書,此書是基於作者 60 多年的實際業務環境而總結的經驗及教訓,為讀者提供正式的維度設計和開發技術。面向數倉和BI設計人員,書中涉及到的內容非常廣泛,圍繞一系列的商業場景或案例研究進行組織。強烈建議買一本實體書研究,反覆通讀全書至少三遍以上,你的技術將會有質的飛躍。

因為本文是純理論知識,密密麻麻的字,很多人可能看不下去,所以我盡量用最少的字來表達,盡量將晦澀難懂的詞語轉化為通俗易於理解的詞,將文中的重點加粗展示,內容盡量精簡,以保證在不表達錯誤的情況下更利於讀者學習!希望和大家能一起學習,一起進步,努力到達我們自己的金字塔頂部
維度建模是什麼
維度模型是數據倉庫領域大師Ralph Kimball 所倡導,以分析決策的需求出發構建模型,構建的數據模型為分析需求服務,因此它重點解決用戶如何更快速完成分析需求,同時還有較好的大規模複雜查詢的響應性能。
維度建模是 數據倉庫/商業智慧 項目成功的關鍵,為什麼這麼說,因為不管我們的數據量從GB到TG還是到PB,雖然數據量越來越大,但是數據展現要獲得成功,就必須建立在簡單性的基礎之上,而維度建模就是時刻考慮如何能夠提供簡單性,以業務為驅動,以用戶理解性和查詢性能為目標。
維度建模:維度建模是專門應用於分析型資料庫、數據倉庫、數據市集建模的方法。數據市集可以理解為一種「小型的數據倉庫」
維度建模指導我們在數據倉庫中如何建表
維度建模分為兩種表:事實表和維度表
- 事實表:必然存在的一些數據,像採集的日誌文件,訂單表,都可以作為事實表
特徵:是一堆主鍵的集合,每個主鍵對應維度表中的一條記錄,客觀存在的,根據主題確定出需要使用的數據 - 維度表:維度就是所分析的數據的一個量,維度表就是以合適的角度來創建的表,分析問題的一個角度:時間、地域、終端、用戶等角度
維度建模的三種模式
- 星形模式:以事實表為中心,所有的維度表直接連在事實表上,最簡單最常用的一種
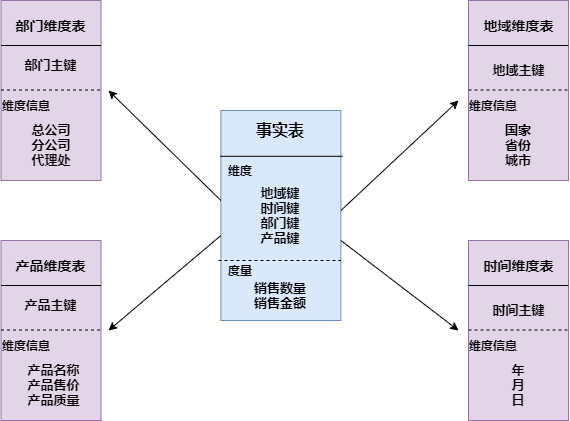
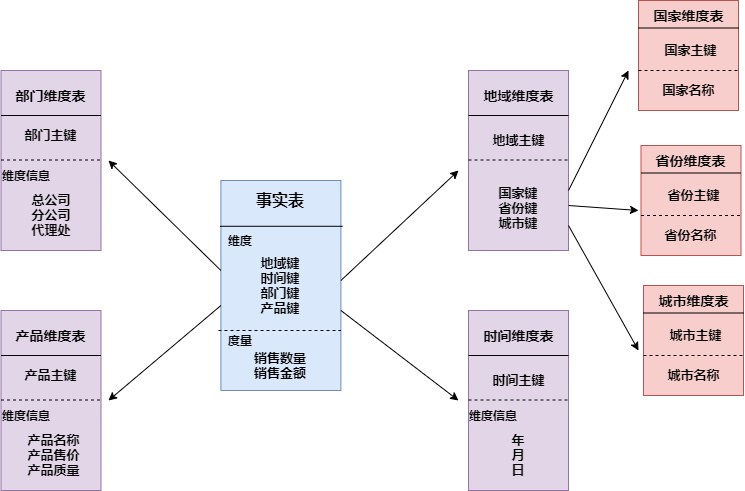
- 雪花模式:雪花模式的維度表可以擁有其他的維度表,這種表不易維護,一般不推薦使用
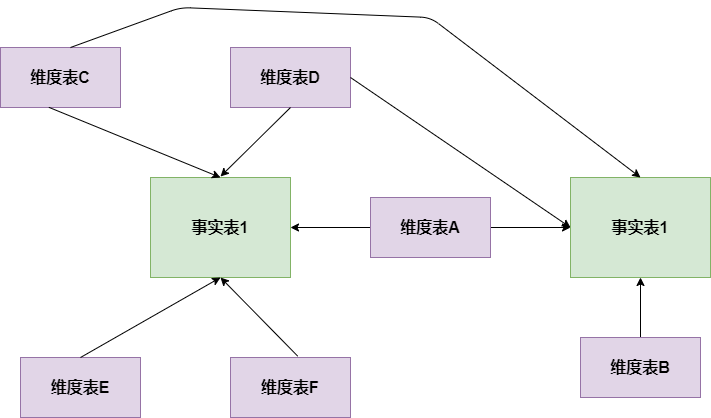
- 星座模型:基於多張事實表,而且共享維度資訊,即事實表之間可以共享某些維度表
維度建模怎麼建
我們知道事實表,維度表,星形模型,星座模型這些概念了,但是實際業務中,給了我們一堆數據,我們怎麼拿這些數據進行數倉建設呢,數倉工具箱作者根據自身60多年的實際業務經驗,給我們總結了如下四步,請務必記住!
數倉工具箱中的維度建模四步走:
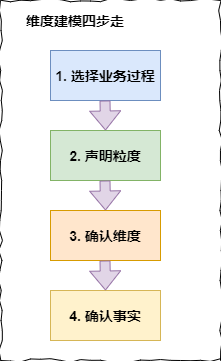
請牢記以上四步,不管什麼業務,就按照這個步驟來,順序不要搞亂,因為這四步是環環相扣,步步相連。下面詳細拆解下每個步驟怎麼做
1、選擇業務過程
維度建模是緊貼業務的,所以必須以業務為根基進行建模,那麼選擇業務過程,顧名思義就是在整個業務流程中選取我們需要建模的業務,根據運營提供的需求及日後的易擴展性等進行選擇業務。比如商城,整個商城流程分為商家端,用戶端,平台端,運營需求是總訂單量,訂單人數,及用戶的購買情況等,我們選擇業務過程就選擇用戶端的數據,商家及平台端暫不考慮。業務選擇非常重要,因為後面所有的步驟都是基於此業務數據展開的。
2、聲明粒度
先舉個例子:對於用戶來說,一個用戶有一個身份證號,一個戶籍地址,多個手機號,多張銀行卡,那麼與用戶粒度相同的粒度屬性有身份證粒度,戶籍地址粒度,比用戶粒度更細的粒度有手機號粒度,銀行卡粒度,存在一對一的關係就是相同粒度。為什麼要提相同粒度呢,因為維度建模中要求我們,在同一事實表中,必須具有相同的粒度,同一事實表中不要混用多種不同的粒度,不同的粒度數據建立不同的事實表。並且從給定的業務過程獲取數據時,強烈建議從關注原子粒度開始設計,也就是從最細粒度開始,因為原子粒度能夠承受無法預期的用戶查詢。但是上卷匯總粒度對查詢性能的提升很重要的,所以對於有明確需求的數據,我們建立針對需求的上卷匯總粒度,對需求不明朗的數據我們建立原子粒度。
3、確認維度
維度表是作為業務分析的入口和描述性標識,所以也被稱為數據倉庫的「靈魂」。在一堆的數據中怎麼確認哪些是維度屬性呢,如果該列是對具體值的描述,是一個文本或常量,某一約束和行標識的參與者,此時該屬性往往是維度屬性,數倉工具箱中告訴我們牢牢掌握事實表的粒度,就能將所有可能存在的維度區分開,並且要確保維度表中不能出現重複數據,應使維度主鍵唯一
4、確認事實
事實表是用來度量的,基本上都以數量值表示,事實表中的每行對應一個度量,每行中的數據是一個特定級別的細節數據,稱為粒度。維度建模的核心原則之一是同一事實表中的所有度量必須具有相同的粒度。這樣能確保不會出現重複計算度量的問題。有時候往往不能確定該列數據是事實屬性還是維度屬性。記住最實用的事實就是數值類型和可加類事實。所以可以通過分析該列是否是一種包含多個值並作為計算的參與者的度量,這種情況下該列往往是事實。
事實表種類
事實表分為以下6類:
- 事務事實表
- 周期快照事實表
- 累積快照事實表
- 無事實的事實表
- 聚集事實表
- 合併事實表
簡單解釋下每種表的概念:
- 事務事實表
表中的一行對應空間或時間上某點的度量事件。就是一行數據中必須有度量欄位,什麼是度量,就是指標,比如說銷售金額,銷售數量等這些可加的或者半可加就是度量值。另一點就是事務事實表都包含一個與維度表關聯的外鍵。並且度量值必須和事務粒度保持一致。
- 周期快照事實表
顧名思義,周期事實表就是每行都帶有時間值欄位,代表周期,通常時間值都是標準周期,如某一天,某周,某月等。粒度是周期,而不是個體的事務,也就是說一個周期快照事實表中數據可以是多個事實,但是它們都屬於某個周期內。
- 累計快照事實表
周期快照事實表是單個周期內數據,而累計快照事實表是由多個周期數據組成,每行匯總了過程開始到結束之間的度量。每行數據相當於管道或工作流,有事件的起點,過程,終點,並且每個關鍵步驟都包含日期欄位。如訂單數據,累計快照事實表的一行就是一個訂單,當訂單產生時插入一行,當訂單發生變化時,這行就被修改。
- 無事實的事實表
我們以上討論的事實表度量都是數字化的,當然實際應用中絕大多數都是數字化的度量,但是也可能會有少量的沒有數字化的值但是還很有價值的欄位,無事實的事實表就是為這種數據準備的,利用這種事實表可以分析發生了什麼。
- 聚集事實表
聚集,就是對原子粒度的數據進行簡單的聚合操作,目的就是為了提高查詢性能。如我們需求是查詢全國所有門店的總銷售額,我們原子粒度的事實表中每行是每個分店每個商品的銷售額,聚集事實表就可以先聚合每個分店的總銷售額,這樣匯總所有門店的銷售額時計算的數據量就會小很多。
- 合併事實表
這種事實表遵循一個原則,就是相同粒度,數據可以來自多個過程,但是只要它們屬於相同粒度,就可以合併為一個事實表,這類事實表特別適合經常需要共同分析的多過程度量。
維度表技術
- 維度表結構
維度表謹記一條原則,包含單一主鍵列,但有時因業務複雜,也可能出現聯合主鍵,請盡量避免,如果無法避免,也要確保必須是單一的,這很重要,如果維表主鍵不是單一,和事實表關聯時會出現數據發散,導致最後結果可能出現錯誤。
維度表通常比較寬,包含大量的低粒度的文本屬性。
- 跨表鑽取
跨表鑽取意思是當每個查詢的行頭都包含相同的一致性屬性時,使不同的查詢能夠針對兩個或更多的事實表進行查詢
鑽取可以改變維的層次,變換分析的粒度。它包括上鑽/下鑽:
上鑽(roll-up):上卷是沿著維的層次向上聚集匯總數據。例如,對產品銷售數據,沿著時間維上卷,可以求出所有產品在所有地區每月(或季度或年或全部)的銷售額。
下鑽(drill-down):下鑽是上鑽的逆操作,它是沿著維的層次向下,查看更詳細的數據。
- 退化維度
退化維度就是將維度退回到事實表中。因為有時維度除了主鍵沒有其他內容,雖然也是合法維度鍵,但是一般都會退回到事實表中,減少關聯次數,提高查詢性能
- 多層次維度
多數維度包含不止一個自然層次,如日期維度可以從天的層次到周到月到年的層次。所以在有些情況下,在同一維度中存在不同的層次。
- 維度表空值屬性
當給定維度行沒有被全部填充時,或者當存在屬性沒有被應用到所有維度行時,將產生空值維度屬性。上述兩種情況,推薦採用描述性字元串代替空值,如使用 unknown 或 not applicable 替換空值。
- 日曆日期維度
在日期維度表中,主鍵的設置不要使用順序生成的id來表示,可以使用更有意義的數據表示,比如將年月日合併起來表示,即YYYYMMDD,或者更加詳細的精度。


