Prometheus集群介紹-1
Prometheus監控介紹
公司做教育的,要遷移上雲,所以需要我這邊從零開始調研加後期維護Prometheus;近期看過二本方面的prometheus書籍,一本是深入淺出一般是實戰方向的;官方文檔主要內容大概也都瀏覽了一遍;在此做個總結;會分幾篇內容來寫;
本篇從Prometheus的單集群監控開始,介紹包括Prometheus的基本概念,基本原理,基於聯邦架構的多集群監控,基於Thanos的多集群監控;
1.Prometheus基本原理
簡介
Prometheus是當前最流行的開源多維監控解決方案,集採集,存儲,查詢,告警於一身。主要用於K8S集群的監控,其擁有強大的PromSQL語句,可進行非常複雜的監控數據聚合計算,且支援關係型聚合。其基本架構如下圖所示。
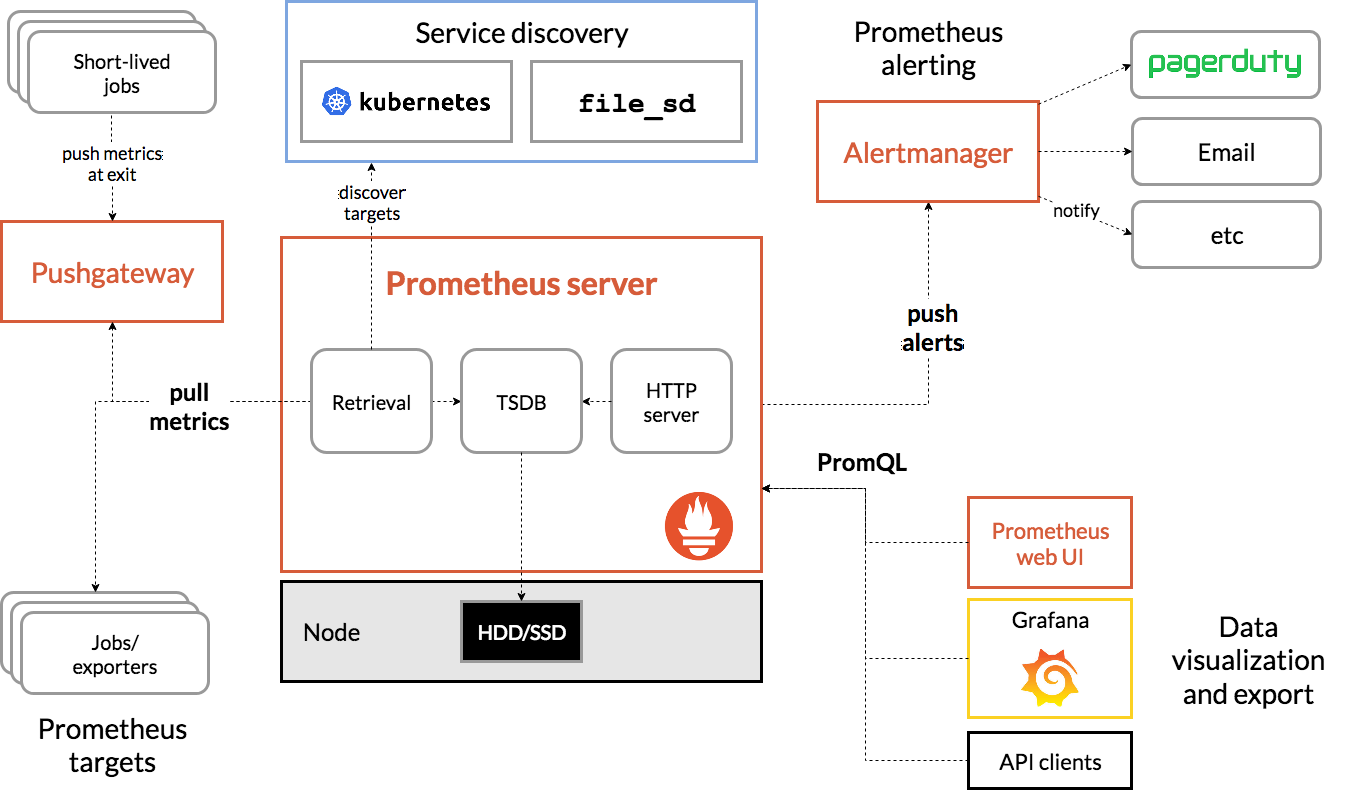
乍一看圖可能比較亂,簡單說明如下:
- 從配置文件載入採集配置
- 通過服務發現探測有哪些需要抓取的對象,也可以配置靜態的
- 周期性得往抓取對象發起抓取請求,得到數據,也就是metrics
- 將數據寫入本地盤或者寫往遠端存儲
- push需要發送警報的內容到Alertmanager組件
- 可通過grafana或者自帶的webUI展示數據
基本概念
job: Prometheus的採集任務由配置文件中一個個的Job組成,一個Job里包含該Job下的所有監控目標的公共配置,比如使用哪種服務發現去獲取監控目標,比如抓取時使用的證書配置,請求參數配置等等。
target: 一個監控目標就是一個target,一個job通過服務發現會得到多個需要監控的target,其包含一些label用於描述target的一些屬性。
relabel_configs: 每個job都可以配置一個或多個relabel_config,relabel_config會對target的label集合進行處理,可以根據label過濾一些target或者修改,增加,刪除一些label。relabel_config過程發生在target開始進行採集之前,針對的是通過服務發現得到的label集合。
metrics_relabel_configs:每個job還可以配置一個或者多個metrics_relabel_config,其配置方式和relabel_configs一模一樣,但是其用於處理的是從target採集到的數據中的label。也就是發送在採集之後;
series(序列):一個series就是指標名+label集合。
head series:Prometheus會將近2小時的series快取在內測中,稱為head series;
基本原理
服務發現:Prometheus周期性得以pull的形式對target進行指標採集,而監控目標集合是通過配置文件中所定義的服務發現機制來動態生成的。也可以靜態配置;
relabel:當服務發現得到所有target後,Prometheus會根據job中的relabel_configs配置對target進行relabel操作,得到target最終的label集合。
採集:進行完上述操作後,Prometheus為這些target創建採集循環,按配置文件里配置的採集間隔進行周期性拉取,採集到的數據根據Job中的metrics_relabel_configs進行relabel,然後再加入上邊得到的target最終label集合,綜合後得到最終的數據。
存儲:Prometheus不會將採集到的數據直接落盤,而是會將近2小時的series快取在內測中,2小時後,Prometheus會進行一次數據壓縮,將記憶體中的數據落盤。
流程:服務發現 ==> targets ==> relabel ==> 抓取 ==> metrics_relabel ==> 快取 ==> 2小時落盤
2.單集群監控方案
我現在用的就是單機群監控方案,後面多機房後,會用多集群監控方案;
對於單個集群,有幾個主流的指標來源方式,於以下幾個組件,Prometheus將從他們獲取數據。
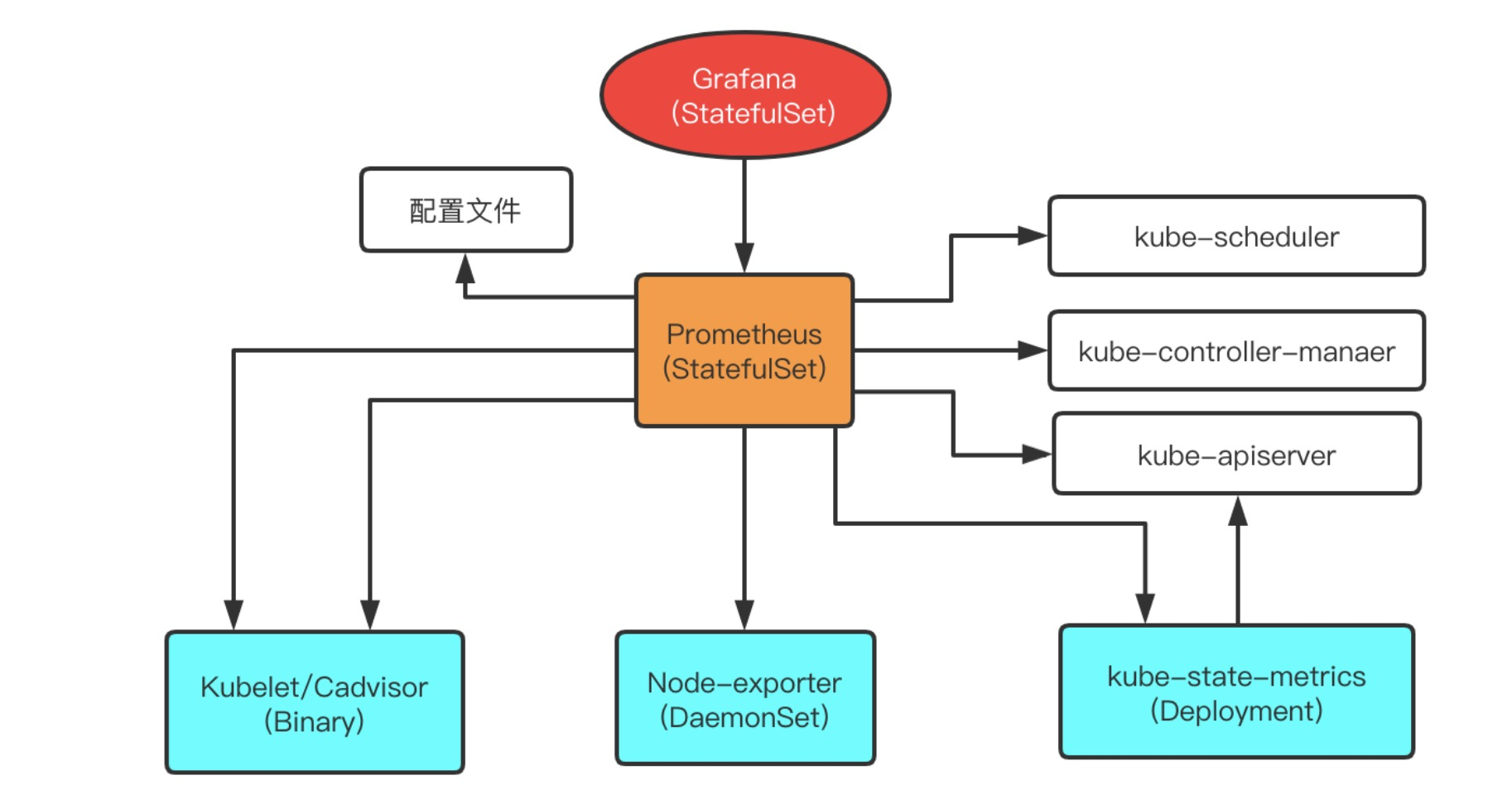
Kube-state-metrics: 通過watch API Server生成資源對象的狀態指標,比如Deployment、Pod、Service等,然後Prometheus進行採集;
metrics-server:metrics-server 一個集群範圍內的資源數據聚合工具,是 Heapster 的替代品,比如kube-controller-manager狀態資訊;
Node-exporter: 用於監控K8s節點的基本狀態,這個組件以DeamonSet的方式部署,每個節點一個,用於提供節點相關的指標,比如節點的cpu使用率,記憶體使用率等等;
Cadvisor: 這個組件目前已經整合到kubelet中了,它提供的是每個容器的運行時指標,比如一個容器的cpu使用率,記憶體使用率等等;
kube-state-metrics 主要關注的是業務相關的一些元數據,比如 Deployment、Pod、副本狀態等
metrics-server 主要關注的是資源度量 API 的實現,比如 CPU、文件描述符、記憶體、請求延時等指標。
單機群部署架構
單集群架構非常簡單,如圖所示。使用這種方式,就可以將集群的節點,組件,資源狀態,容器運行時狀態都給監控起來;
3. 多集群場景的特點
如果我們現在有多個集群,並希望他們的監控數據存儲到一起,可以進行聚合查詢,用上述部署方案顯然是不夠的,因為上述方案中的Prometheus只能識別出本集群內的被監控目標,即服務發現無法跨集群。另外就是網路限制,多個集群之間的網路有可能是不通的,這就使得即使在某個集群中知道另一個集群的target地址,也沒法去抓取數據。總結多集群的特點主要有:
- 服務發現隔離
- 網路隔離
那隻用Prometheus能解決嗎?
答案其實是能,用聯邦。
Prometheus支援拉取其他Prometheus的數據到本地,稱為聯邦機制。這樣我們就可以在每個集群內部署一個Prometheus,再在他們之上部署一個Top Prometheus,用於拉取各個集群內部的Prometheus數據進行匯總。
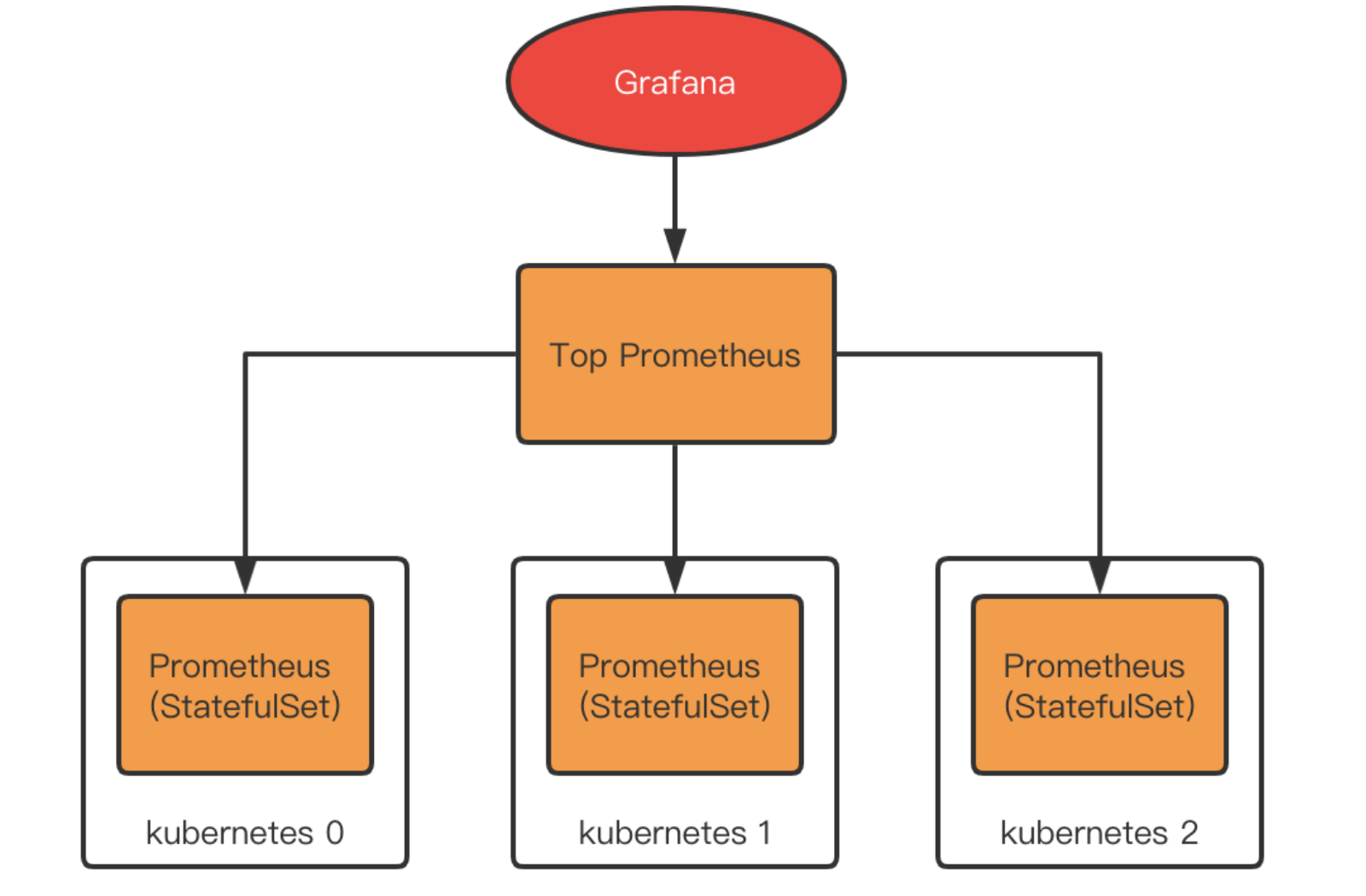
聯邦的問題在哪?
聯邦的方案其實也是社區所認可的,在集群規模普遍較小,整體數據量不大的情況下,聯邦的方案部署簡單,理解成本低,沒有其他組件的引入,是一個很不錯的選擇。
但是聯邦也有其問題。由於所有數據最終都由Top Prometheus進行存儲,當總數據量較大的時候,Top Prometheus的壓力將增大,甚至難抗重負,另外,每個集群中的Prometheus實際上也會保存數據(Prometheus2.x 不支援關閉本地存儲),所以實際上出現了數據無意義冗餘。總結而言,聯邦的問題主要是。
- Top Prometheus壓力大
- 數據有無意義冗餘
4.用Thanos實現多集群監控
Thanos簡介
Thanos 是一款開源的Prometheus 高可用解決方案,其支援從多個Prometheus中查詢數據並進行匯總和去重,並支援將Prometheus本地數據傳送到雲上對象存儲進行長期存儲。官方架構圖如下:
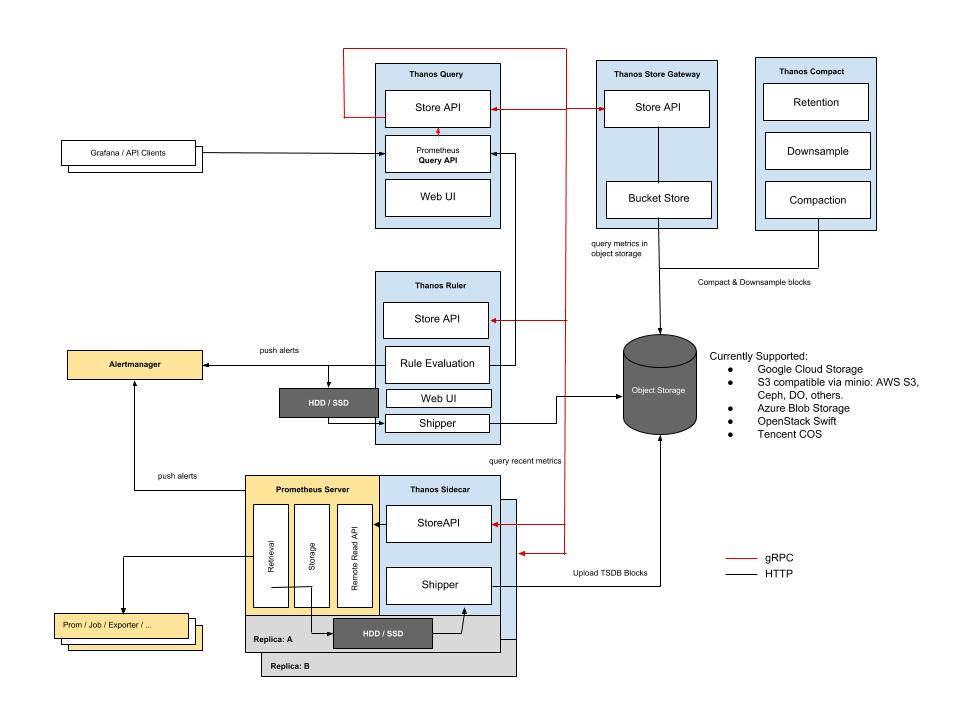
- Query: query代理Prometheus作為查詢入口,他會去所有Prometheus,Store, 以及 Ruler查詢數據,匯總並去重。
- Sidecar:將數據上傳到對象存儲,也負責接收Thanos query的查詢請求。
- Ruler:進行數據的預聚合及告警。
- Store:負責從對象存儲中查詢數據。
簡化版本圖:


部署方案
使用Thanos來替代聯邦方案,我們只需要將上圖中的Prometheus和Thanos sidecar部署到Kubernetes集群中,將Thano query等組件部署在原來Top Prometheus的位置即可。

相比聯邦的優勢
使用Thanos相比於之前使用聯邦,擁有一些較為明顯的優勢
- 由於數據不再存儲在單個Prometheus中,所以整體能承載的數據規模比聯邦大。
- 數據不再有不必要的冗餘。
- 由於Thanos有去重能力,實際上可以每個集群中部署兩個Prometheus來做數據多副本。
- 可以將數據存儲到對象存儲中,相比存儲在本地,能支援更長久的存儲。
5.總結
我們首先介紹了Prometheus的基本原理,並介紹了最為常用的使用Prometheus監控單一小集群的方案。
隨後,針對多集群場景,我們還談了聯邦方式與Thanos方式各有什麼優缺點。
後續我應該還會分享下三篇內容
- 1.Prometheus具體的配置說明;
- 2.Prometheus-operator部署prometheus集群;
- 3.Grafana面板展示以及PromQL語法查詢;


