Redis快取篇(二)淘汰機制:快取滿了怎麼辦?
上一講提到,快取的容量總是小於後端資料庫的。隨著業務系統的使用,快取數據會撐滿記憶體空間,該怎麼處理呢?
本節我們來學習記憶體淘汰機制。在Redis 4.0之前有6種記憶體淘汰策略,之後又增加2種,一共8種,如下圖所示:
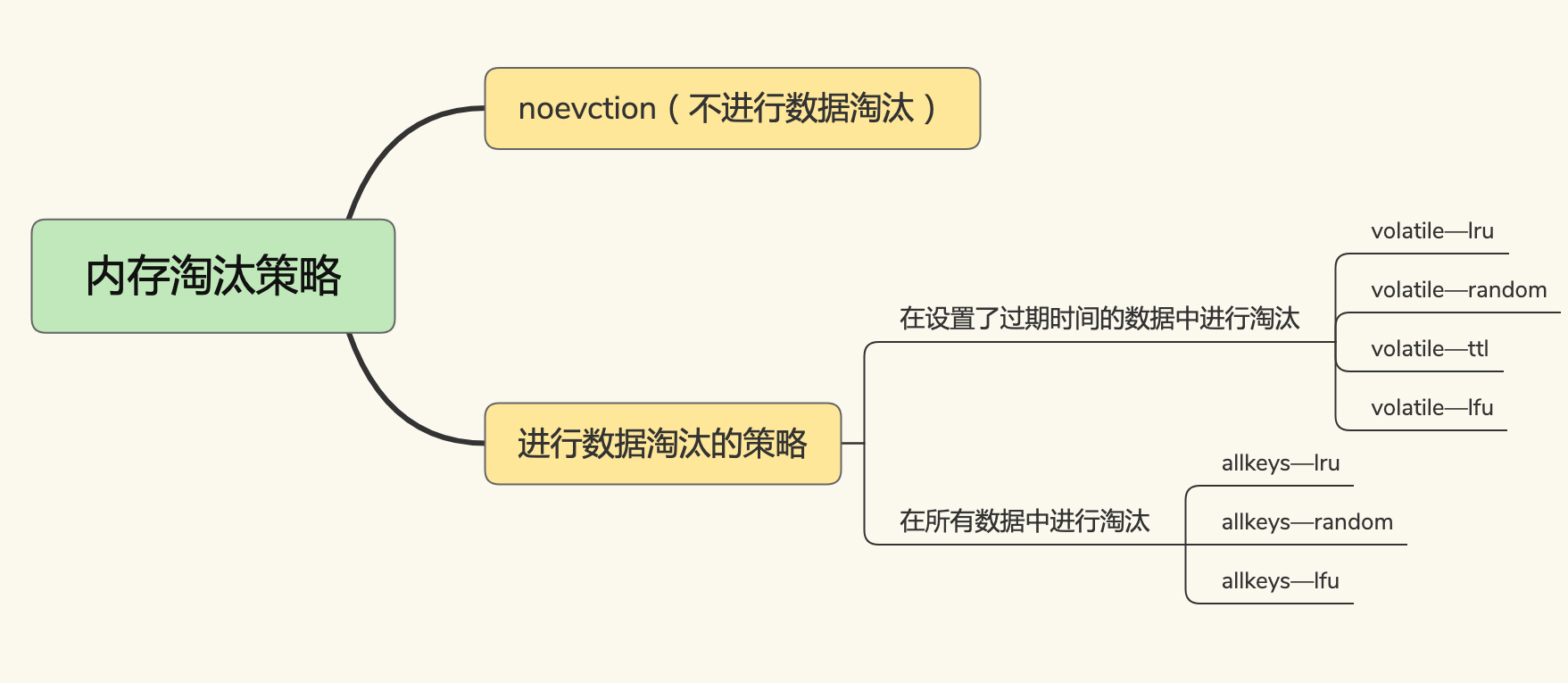
- noeviction策略:記憶體空間達到maxmemory時,不會淘汰數據,有新寫入時會返回錯誤。
- volatile-ttl策略:針對設置了過期時間的鍵值對,根據過期時間的先後進行修改,越早過期的越先被刪除。
- volatile-random策略:在設置了過期時間的鍵值對中,進行隨機刪除。
- volatile-lru策略:使用LRU演算法篩選設置了過期時間的鍵值對,進行刪除。
- volatile-lfu策略:使用LFU演算法篩選設置了過期時間的鍵值對,進行刪除。
- allkeys-random策略:在所有鍵值對中隨機選擇並刪除數據。
- allkeys-lru策略:使用LRU演算法在所有數據中進行篩選並刪除數據。
- allkeys-lfu策略:使用LFU演算法在所有數據中進行篩選並刪除數據。
對於TTL、Random比較好理解,下面學習一下LRU和LFU演算法。
LRU演算法
LRU演算法,全稱Least Recently Used。
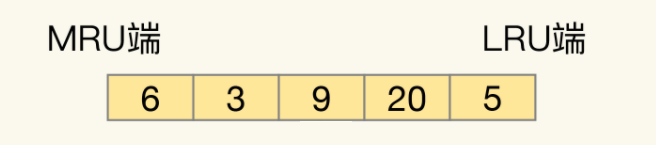
其中MRU端指最近訪問的數據;LRU端指最早訪問的數據。
被訪問的數據和新插入的數據會移到MRU端,空間滿了後從LRU端刪除。這樣一來,最早訪問的數據會逐漸被淘汰。
但LRU演算法也有其缺點:
- 需要用鏈表管理所有快取數據,帶來額外的空間開銷
- 大量數據被訪問,就會帶來很多鏈表移動操作,降低Redis性能
而Redis對其進行簡化:
- Redis會記錄每個數據的最近一次訪問的時間戳(RedisObject中的lru欄位)
- Redis第一次淘汰數據時,會隨機選出N個數據,作為一個候選集合。
- 然後比較這N個數據的lru,把lru最小的從快取中淘汰。
當再次淘汰數據時,會挑選數據放到第一次淘汰時的候選集合,要求小於候選集合中最小的lru值才能加入。
其中maxmemory-samples配置項:表示選出的個數N。可以通過以下命令進行設置:
CONFIG SET maxmemory-samples 100
LFU演算法
LFU演算法是在LRU策略基礎上,為每個數據增加一個計數器,來統計這個數據的訪問次數。
使用LFU策略篩選淘汰數據時,根據數據的訪問次數進行篩選,把訪問次數最低的數據淘汰。如果兩個數據訪問次數相同,再比較兩個數據的訪問時效性,把更久的數據淘汰。
如何實現
LFU也是使用RedisObject的lru欄位來實現。
把24bit的lru欄位拆分成兩部分:
- ldt值:lru欄位的前16bit,表示數據的訪問時間戳;
- counter值:lru欄位的後8bit,表示數據的訪問次數;
當LFU策略淘汰數據時,Redis在候選集合中,根據lru欄位的後8bit選擇訪問次數最小的數據進行淘汰。如果訪問次數相同,再根據lru欄位的前16bit值大小,選擇更久的數據進行淘汰。
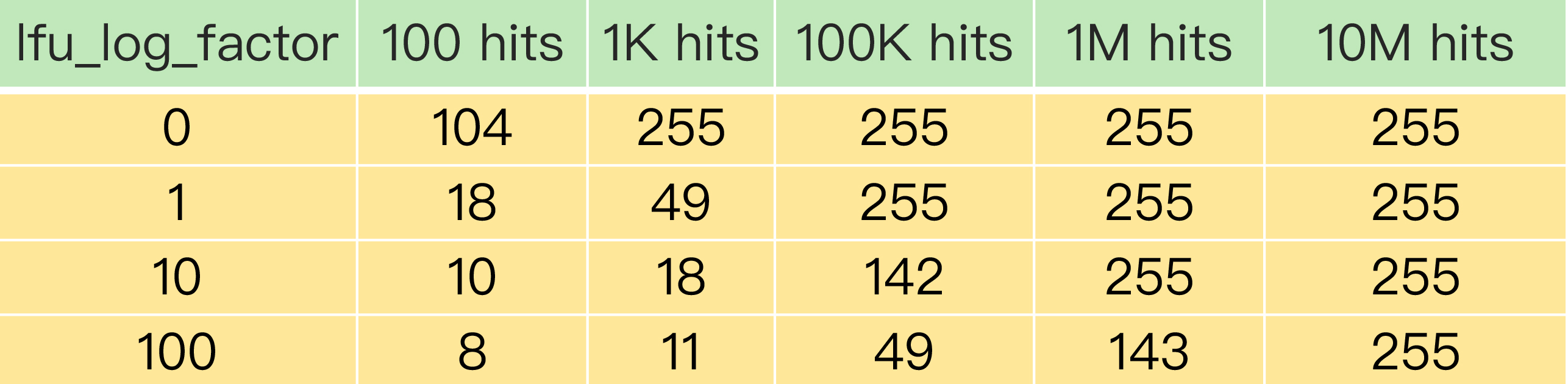
關於counter只有8bit(255)的問題
Redis並沒有採用數據每被訪問一次,就+1的規則,而是採用一個類似於隨機+1的規則:
double r = (double)rand()/RAND_MAX; ... double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++;
通過設置 lfu_log_factor 配置項來控制計數器值增加的速度,避免counter很快到255。下圖是 lfu_log_factor 設置不同值時,counter的增長情況:
總結
- 如何設置快取空間大小:設置為總數據量的15%到30%,兼顧訪問性能和記憶體空間開銷。
- 優先使用allkeys-lru策略。如果業務數據中有明顯的冷熱數據區分,建議使用allkeys-lru策略。
- 如果業務數據訪問頻繁相關不大,沒有明顯的冷熱數據區分,建議使用allkeys-random策略。
- 如果業務中有置頂的需要,可以使用volatile-lru策略,同時不給這些置頂數據設置過期時間。


