Spark學習進度-Transformation運算元
Transformation運算元
intersection
交集
/*
交集
*/
@Test
def intersection(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.intersection(rdd2)
.collect()
.foreach(println(_))
}
union
並集
/*
並集
*/
@Test
def union(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.union(rdd2)
.collect()
.foreach(println(_))
}

subtract
差集
@Test
def subtract(): Unit ={
val rdd1=sc.parallelize(Seq(1,2,3,4,5))
val rdd2=sc.parallelize(Seq(3,4,5,6,7))
rdd1.subtract(rdd2)
.collect()
.foreach(println(_))
}
輸出:

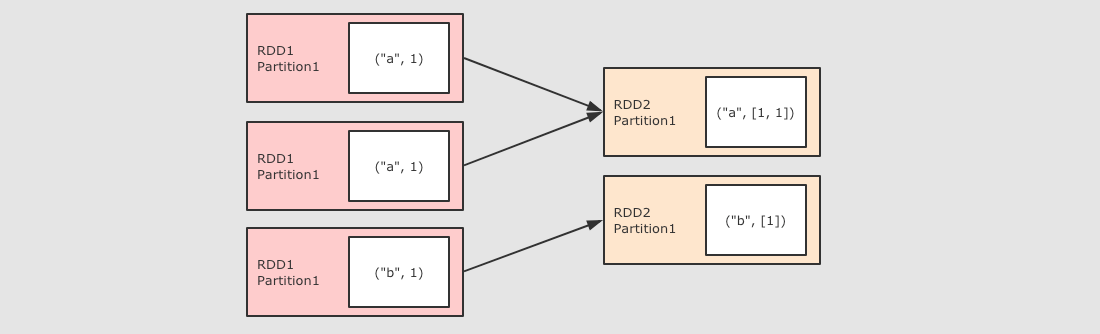
groupByKey
作用
-
GroupByKey 運算元的主要作用是按照 Key 分組, 和 ReduceByKey 有點類似, 但是 GroupByKey 並不求聚合, 只是列舉 Key 對應的所有 Value
/*
groupByKey 運算結果的格式:(K,(value1,value2))
reduceByKey 能否在Map端做Combiner
*/
@Test
def groupByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.groupByKey()
.collect()
.foreach(println(_))
}
distinct
作用:用於去重
@Test
def distinct(): Unit ={
sc.parallelize(Seq(1,1,2,2,3))
.distinct()
.collect()
.foreach(println(_))
}
輸出:1,2,3
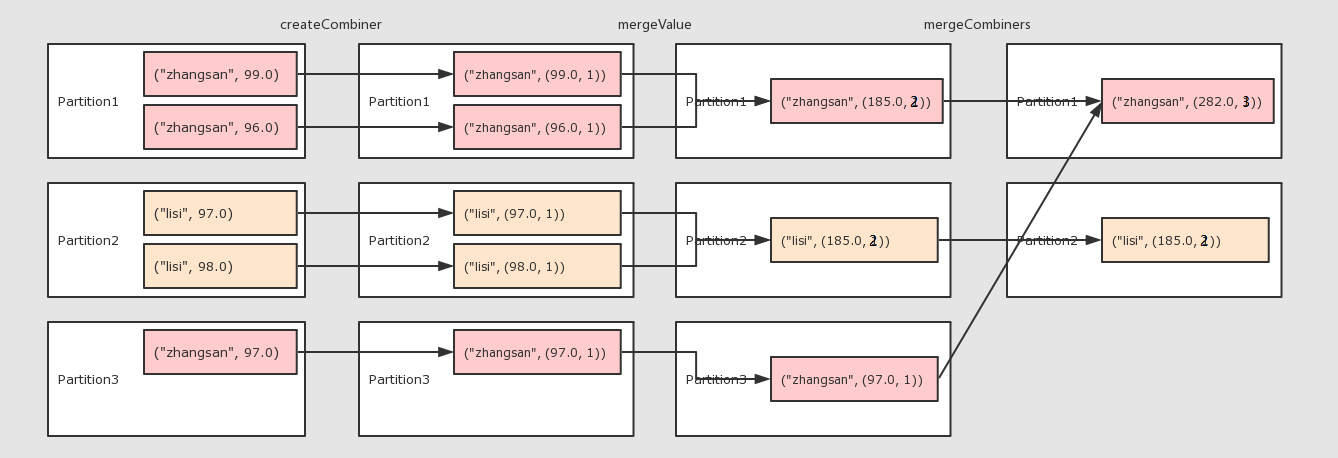
combineByKey
作用
-
對數據集按照 Key 進行聚合
調用
-
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
參數
-
createCombiner將 Value 進行初步轉換 -
mergeValue在每個分區把上一步轉換的結果聚合 -
mergeCombiners在所有分區上把每個分區的聚合結果聚合 -
partitioner可選, 分區函數 -
mapSideCombiner可選, 是否在 Map 端 Combine -
serializer序列化器
例子:算個人得分的平均值
@Test
def combineByKey(): Unit ={
var rdd=sc.parallelize(Seq(
("zhangsan", 99.0),
("zhangsan", 96.0),
("lisi", 97.0),
("lisi", 98.0),
("zhangsan", 97.0)
))
//2.運算元運算
// 2.1 createCombiner 轉換數據
// 2.2 mergeValue 分區上的聚合
// 2.3 mergeCombiners 把所有分區上的結果再次聚合,生成最終結果
val combineResult = rdd.combineByKey(
createCombiner = (curr: Double) => (curr, 1),
mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1),
mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2)
)
val resultRDD = combineResult.map(item => (item._1, item._2._1 / item._2._2))
resultRDD.collect().foreach(print(_))
}
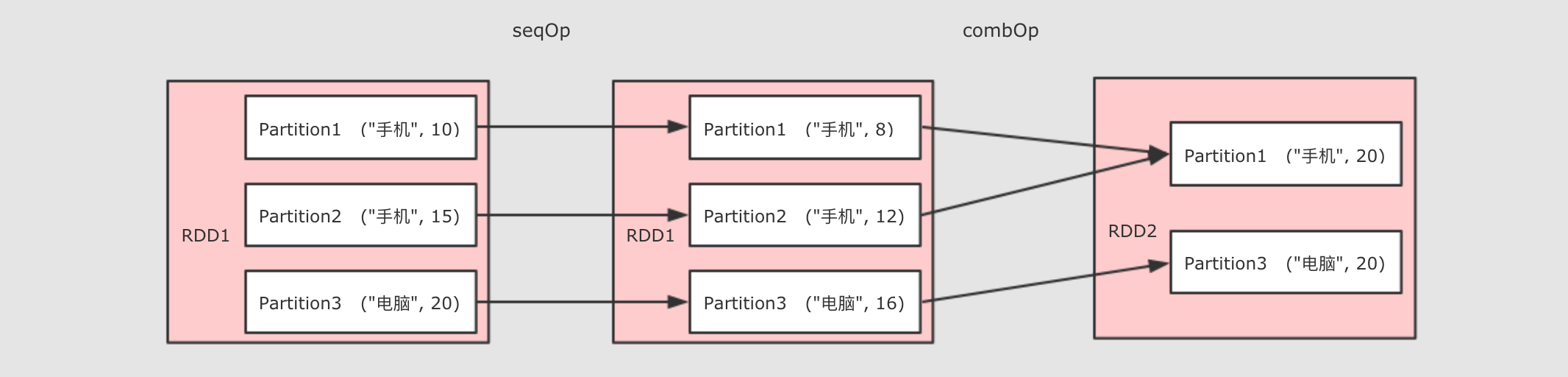
aggregateByKey
作用
-
聚合所有 Key 相同的 Value, 換句話說, 按照 Key 聚合 Value
調用
-
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
參數
-
zeroValue初始值 -
seqOp轉換每一個值的函數 -
comboOp將轉換過的值聚合的函數
/*
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
zeroValue 初始值
seqOp 轉換每一個值的函數
comboOp 將轉換過的值聚合的函數
*/
@Test
def aggregateByKey(): Unit ={
val rdd=sc.parallelize(Seq(("手機",10.0),("手機",15.0),("電腦",20.0)))
rdd.aggregateByKey(0.8)(( zeroValue,item) =>item * zeroValue,(curr,agg) => curr+agg)
.collect()
.foreach(println(_))
// (手機,20.0)
// (電腦,16.0)
}
foldByKey
作用
-
和 ReduceByKey 是一樣的, 都是按照 Key 做分組去求聚合, 但是 FoldByKey 的不同點在於可以指定初始值
/*
foldByKey可以指定初始值
*/
@Test
def foldByKey(): Unit ={
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.foldByKey(zeroValue = 10)( (curr,agg) => curr + agg )
.collect()
.foreach(println(_))
}

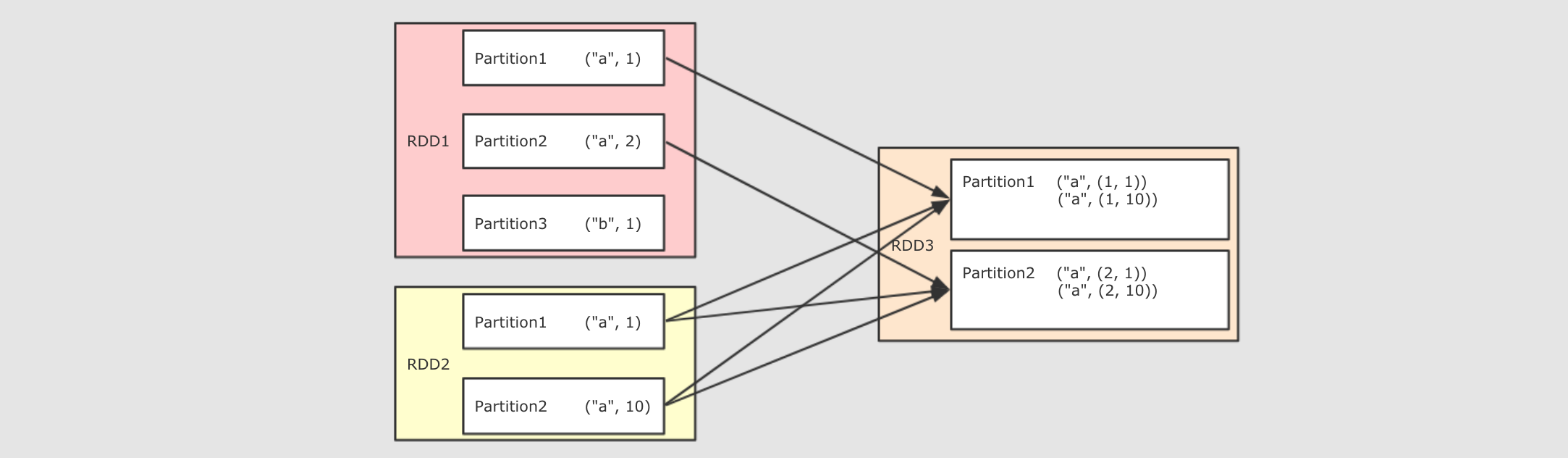
join
作用
-
將兩個 RDD 按照相同的 Key 進行連接
@Test
def join(): Unit ={
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12)))
rdd1.join(rdd2).collect().foreach(println(_))
// (a,(1,10))
// (a,(1,11))
// (a,(1,12))
// (a,(2,10))
// (a,(2,11))
// (a,(2,12))
}
sortBy
sortBy`可以指定按照哪個欄位來排序, `sortByKey`直接按照 Key 來排序
@Test
def sortBy(): Unit ={
val rdd=sc.parallelize(Seq(8,4,5,6,2,1,1,9))
val rdd2=sc.parallelize(Seq(("a",1),("b",3),("c",2)))
//rdd.sortBy(item =>item).collect().foreach(println(_))
rdd2.sortBy(item => item._2).collect().foreach(println(_))
rdd2.sortByKey().collect().foreach(println(_))
}
repartition
重新進行分區
@Test
def partitioning(): Unit ={
val rdd=sc.parallelize(Seq(1,2,3,4,5),2)
//println((rdd.repartition(5)).partitions.size)
println(rdd.coalesce(5,true).partitions.size)
}


