手把手教你用深度學習做物體檢測(二):數據標註
- 2019 年 10 月 3 日
- 筆記
「本篇文章將開始我們訓練自己的物體檢測模型之旅的第一步—— 數據標註。」
上篇文章介紹了如何基於訓練好的模型檢測圖片和影片中的物體,若你也想先感受一下物體檢測,可以看看上篇文章:《手把手教你用深度學習做物體檢測(一):快速感受物體檢測的酷炫 》。
其實,網上關於數據標註的文章已有很多,但大多數都會有一些細節問題,比如中文編碼問題,比如標註的數據放置的目錄結構不對導致訓練報錯的問題等等,而這些問題,在本篇文章中都考慮到了,所以只要你按照步驟一步步來,並且使用本文中的程式碼,將會避免遇到上面所說的問題。
我們已經知道,物體檢測,簡言之就是框出影像中的目標物體,就像下圖這樣:

然而,能夠識別出該圖中的人、狗、馬的模型是經過了大量數據訓練得到的,這些訓練用的數據,包含了圖片本身,圖片中的待檢測目標的類別和矩形框的坐標等。一般而言,初始的數據都是需要人工來標註的,比如下面這張圖:

我們除了要把圖片本身餵給神經網路,還要把圖片中的長頸鹿、斑馬的類別以及在圖片中的位置資訊一併餵給神經網路,現在你可能會想,類別資訊倒還好,看一眼就知道有哪些類別了,但是目標的位置資訊如何得到?難道要用像素尺量么?
其實,已經有很多物體檢測的先驅者們開發出了一些便捷的物體檢測樣本標註工具,這裡我們會介紹一個很好用的工具——labelImg,該工具已經在github上開源了,地址:https://github.com/tzutalin/labelImg

該工具對於windows、Linux、Mac作業系統都支援,這裡介紹windows和Linux下的安裝方法,Mac下的安裝可以去看項目的README文檔。
- Windows
github上提供了windows下的exe文件,下載下來後直接雙擊運行即可打開labelImg,進行數據的標註,下載鏈接如下:https://github.com/tzutalin/labelImg/files/2638199/windows_v1.8.1.zip - Linux
Linux下的安裝,需要從源碼構建,README文檔中提供了python2 + Qt4和python3+Qt5的構建方法,這裡僅介紹後者,在終端中輸入以下命令:
--構建 sudo apt-get install pyqt5-dev-tools sudo pip3 install -r requirements/requirements-linux-python3.txt make qt5py3 --打開 python3 labelImg.py python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE] 無論是windows還是linux下,都提供了一個預定義的類別文件,data/predefined_classes.txt,其內容如下:

這是方便我們在標註目標類別的時候可以從下拉框中選擇,所以當然也可以修改這個文件,定義好自己要檢測的目標的類別,支援中文。
接下來,我們以windows為例,雙擊labelImage.exe,稍等幾秒鐘,就會看到如下介面:

然後,我們載入一個圖片目錄,第一張圖片會自動打開,此時我們按下 w 鍵,就可以標註目標了,如果發現快捷鍵不能用,可能是目前處在中文輸入法狀態,切換到英文狀態就好了:
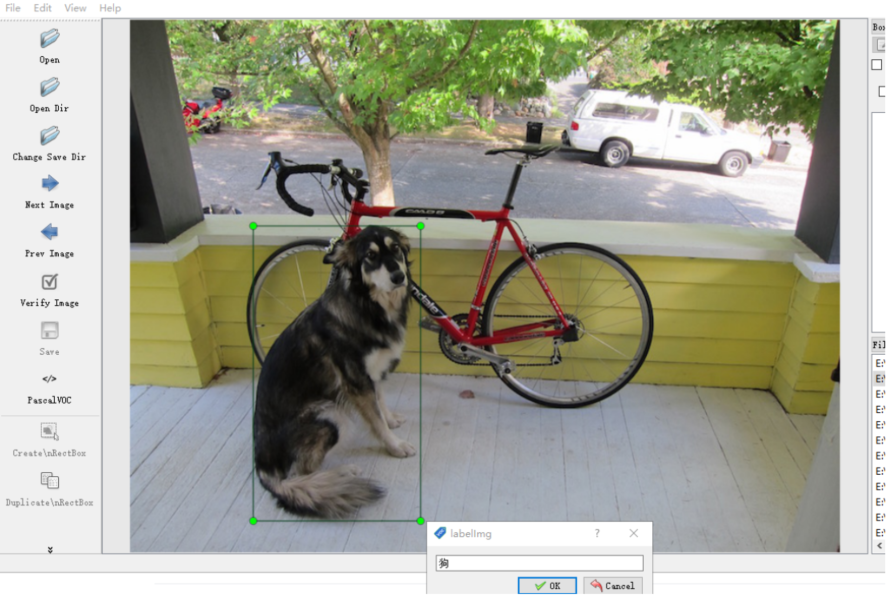
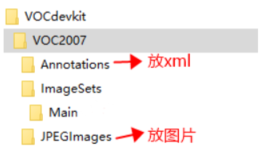
標註完成後記得保存操作,然後按下快捷鍵 d,就可以切換到下一張繼續標註。當所有的圖片標註完成後,我們還有一些事情要做,就是按照voc2007的數據集標準將圖片和xml文件放到固定的目錄結構下,具體的結構如下:
接著,我們要將圖片數據集劃分成訓練集、驗證集、測試集,可以使用如下python程式碼,將該程式碼文件和ImageSets目錄放在同一級執行:
""" 將voc_2007格式的數據集劃分下訓練集、測試集和驗證集 """ import os import random trainval_percent = 0.96 train_percent = 0.9 xmlfilepath = 'Annotations' txtsavepath = 'ImageSetsMain' total_xml = os.listdir(xmlfilepath) num=len(total_xml) list=range(num) tv=int(num*trainval_percent) tr=int(tv*train_percent) trainval= random.sample(list,tv) train=random.sample(trainval,tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w', encoding="utf-8") ftest = open('ImageSets/Main/test.txt', 'w', encoding="utf-8") ftrain = open('ImageSets/Main/train.txt', 'w', encoding="utf-8") fval = open('ImageSets/Main/val.txt', 'w', encoding="utf-8") for i in list: name=total_xml[i][:-4]+'n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest .close() 執行後,會在ImageSets/Main目錄下生成如下文件:

接下來,可以生成 yolov3 需要的數據格式了,我們使用如下程式碼,將程式碼文件和VOCdevkit目錄放在同一級執行,注意修改程式碼中的classes為你想要檢測的目標類別集合:
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] # classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] classes = ["人","狗","滑鼠","車"] def convert(size, box): dw = 1./(size[0]) dh = 1./(size[1]) x = (box[0] + box[1])/2.0 - 1 y = (box[2] + box[3])/2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(year, image_id): in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult)==1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)): os.makedirs('VOCdevkit/VOC%s/labels/'%(year)) image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() list_file = open('%s_%s.txt'%(year, image_set), 'w') for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpgn'%(wd, year, image_id)) convert_annotation(year, image_id) list_file.close() # os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt") # os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt") os.system("cat 2007_train.txt 2007_val.txt > train.txt") os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")執行後,會在當前目錄生成幾個文件:
2007_train.txt ——訓練集 2007_val.txt ——驗證集 2007_test.txt ——測試集 train.txt —— 訓練集+驗證集 train.all.txt —— 訓練集+驗證集+測試集我們只需要測試集和訓練集,所以保留train.txt和2007_test.txt,其它文件可以刪除,然後把train.txt重命名為2007_train.txt(不重命名也可以的,只是為了和2007_test.txt名字看起來風格一致),如此我們就有了兩個符合yolov3訓練和測試要求的數據集2007_train.txt和2007_test.txt,注意,這兩個txt中包含的僅僅是圖片的路徑。
除了上面的幾個文件外,我們還會發現在VOCdevkit/VOC2007目錄下生成了一個labels目錄,該目錄下生成了和JPEGImages目錄下每張圖片對應的txt文件,所以如果有500張圖片,就會有500個txt,具體內容如下:

可以看到,每一行代表當前txt所對應的圖片里的一個目標的標註資訊,總共有5列,第一列是該目標的類別,第二、三列是目標的歸一化後的中心位置坐標,第四、五列是目標的歸一化後的寬和高。
當我們得到了2007_train.txt、2007_test.txt、labels目錄和其下的txt文件後,數據標註工作就算完成了,那麼如何使用這些數據來訓練我們自己的物體檢測模型呢?
既然我們準備的數據是符合yolov3要求的,那麼我們當然是基於yolov3演算法來使用這些數據訓練出我們自己的模型,具體步驟將會在下一篇《手把手教你用深度學習做物體檢測(三):模型訓練》中介紹。
ok,本篇就這麼多內容啦~,感謝閱讀O(∩_∩)O,88~
名句分享
孩兒立志出鄉関,學不成名誓不還,埋骨何須桑梓地,人生無處不青山。——毛澤東
為您推薦
手把手教你用深度學習做物體檢測(一): 快速感受物體檢測的酷炫
ubuntu16.04安裝Anaconda3
Unbuntu下持續觀察NvidiaGPU的狀態
想看更多好文?長按識別下方二維碼關注滌生吧O(∩_∩)O~