Storm 系列(二)—— Storm 核心概念詳解
- 2019 年 10 月 3 日
- 筆記
一、Storm核心概念
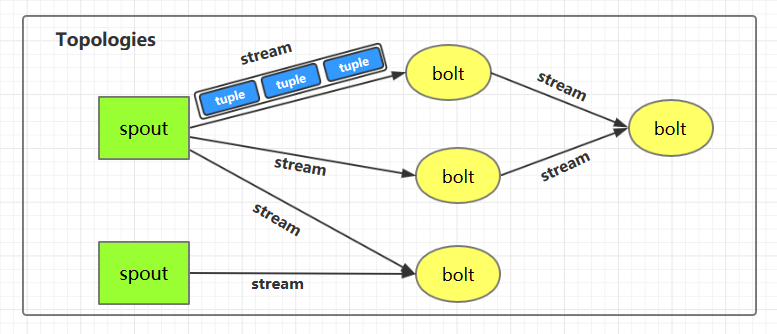
1.1 Topologies(拓撲)
一個完整的 Storm 流處理程式被稱為 Storm topology(拓撲)。它是一個是由 Spouts 和 Bolts 通過 Stream 連接起來的有向無環圖,Storm 會保持每個提交到集群的 topology 持續地運行,從而處理源源不斷的數據流,直到你將主動其殺死 (kill) 為止。
1.2 Streams(流)
Stream 是 Storm 中的核心概念。一個 Stream 是一個無界的、以分散式方式並行創建和處理的 Tuple 序列。Tuple 可以包含大多數基本類型以及自定義類型的數據。簡單來說,Tuple 就是流數據的實際載體,而 Stream 就是一系列 Tuple。
1.3 Spouts
Spouts 是流數據的源頭,一個 Spout 可以向不止一個 Streams 中發送數據。Spout 通常分為可靠和不可靠兩種:可靠的 Spout 能夠在失敗時重新發送 Tuple, 不可靠的 Spout 一旦把 Tuple 發送出去就置之不理了。
1.4 Bolts
Bolts 是流數據的處理單元,它可以從一個或者多個 Streams 中接收數據,處理完成後再發射到新的 Streams 中。Bolts 可以執行過濾 (filtering),聚合 (aggregations),連接 (joins) 等操作,並能與文件系統或資料庫進行交互。
1.5 Stream groupings(分組策略)
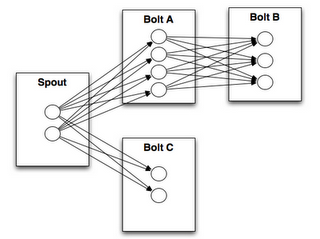
spouts 和 bolts 在集群上執行任務時,是由多個 Task 並行執行 (如上圖,每一個圓圈代表一個 Task)。當一個 Tuple 需要從 Bolt A 發送給 Bolt B 執行的時候,程式如何知道應該發送給 Bolt B 的哪一個 Task 執行呢?
這是由 Stream groupings 分組策略來決定的,Storm 中一共有如下 8 個內置的 Stream Grouping。當然你也可以通過實現 CustomStreamGrouping 介面來實現自定義 Stream 分組策略。
-
Shuffle grouping
Tuples 隨機的分發到每個 Bolt 的每個 Task 上,每個 Bolt 獲取到等量的 Tuples。
-
Fields grouping
Streams 通過 grouping 指定的欄位 (field) 來分組。假設通過
user-id欄位進行分區,那麼具有相同user-id的 Tuples 就會發送到同一個 Task。 -
Partial Key grouping
Streams 通過 grouping 中指定的欄位 (field) 來分組,與
Fields Grouping相似。但是對於兩個下游的 Bolt 來說是負載均衡的,可以在輸入數據不平均的情況下提供更好的優化。 -
All grouping
Streams 會被所有的 Bolt 的 Tasks 進行複製。由於存在數據重複處理,所以需要謹慎使用。
-
Global grouping
整個 Streams 會進入 Bolt 的其中一個 Task,通常會進入 id 最小的 Task。
-
None grouping
當前 None grouping 和 Shuffle grouping 等價,都是進行隨機分發。
-
Direct grouping
Direct grouping 只能被用於 direct streams 。使用這種方式需要由 Tuple 的生產者直接指定由哪個 Task 進行處理。
-
Local or shuffle grouping
如果目標 Bolt 有 Tasks 和當前 Bolt 的 Tasks 處在同一個 Worker 進程中,那麼則優先將 Tuple Shuffled 到處於同一個進程的目標 Bolt 的 Tasks 上,這樣可以最大限度地減少網路傳輸。否則,就和普通的
Shuffle Grouping行為一致。
二、Storm架構詳解
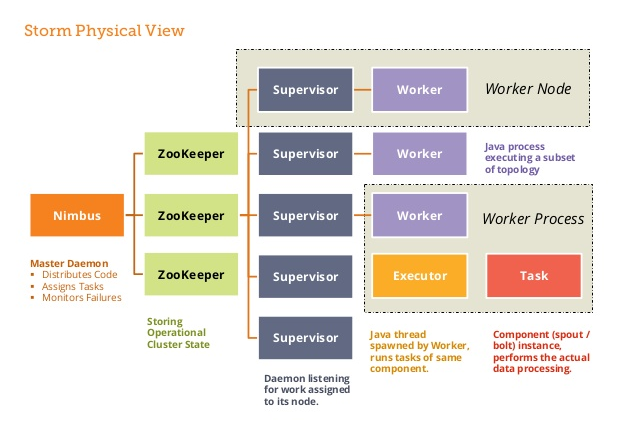
2.1 Nimbus進程
也叫做 Master Node,是 Storm 集群工作的全局指揮官。主要功能如下:
- 通過 Thrift 介面,監聽並接收 Client 提交的 Topology;
- 根據集群 Workers 的資源情況,將 Client 提交的 Topology 進行任務分配,分配結果寫入 Zookeeper;
- 通過 Thrift 介面,監聽 Supervisor 的下載 Topology 程式碼的請求,並提供下載 ;
- 通過 Thrift 介面,監聽 UI 對統計資訊的讀取,從 Zookeeper 上讀取統計資訊,返回給 UI;
- 若進程退出後,立即在本機重啟,則不影響集群運行。
2.2 Supervisor進程
也叫做 Worker Node , 是 Storm 集群的資源管理者,按需啟動 Worker 進程。主要功能如下:
- 定時從 Zookeeper 檢查是否有新 Topology 程式碼未下載到本地 ,並定時刪除舊 Topology 程式碼 ;
- 根據 Nimbus 的任務分配計劃,在本機按需啟動 1 個或多個 Worker 進程,並監控所有的 Worker 進程的情況;
- 若進程退出,立即在本機重啟,則不影響集群運行。
2.3 zookeeper的作用
Nimbus 和 Supervisor 進程都被設計為快速失敗(遇到任何意外情況時進程自毀)和無狀態(所有狀態保存在 Zookeeper 或磁碟上)。 這樣設計的好處就是如果它們的進程被意外銷毀,那麼在重新啟動後,就只需要從 Zookeeper 上獲取之前的狀態數據即可,並不會造成任何數據丟失。
2.4 Worker進程
Storm 集群的任務構造者 ,構造 Spoult 或 Bolt 的 Task 實例,啟動 Executor 執行緒。主要功能如下:
- 根據 Zookeeper 上分配的 Task,在本進程中啟動 1 個或多個 Executor 執行緒,將構造好的 Task 實例交給 Executor 去運行;
- 向 Zookeeper 寫入心跳 ;
- 維持傳輸隊列,發送 Tuple 到其他的 Worker ;
- 若進程退出,立即在本機重啟,則不影響集群運行。
2.5 Executor執行緒
Storm 集群的任務執行者 ,循環執行 Task 程式碼。主要功能如下:
- 執行 1 個或多個 Task;
- 執行 Acker 機制,負責發送 Task 處理狀態給對應 Spout 所在的 worker。
2.6 並行度

1 個 Worker 進程執行的是 1 個 Topology 的子集,不會出現 1 個 Worker 為多個 Topology 服務的情況,因此 1 個運行中的 Topology 就是由集群中多台物理機上的多個 Worker 進程組成的。1 個 Worker 進程會啟動 1 個或多個 Executor 執行緒來執行 1 個 Topology 的 Component(組件,即 Spout 或 Bolt)。
Executor 是 1 個被 Worker 進程啟動的單獨執行緒。每個 Executor 會運行 1 個 Component 中的一個或者多個 Task。
Task 是組成 Component 的程式碼單元。Topology 啟動後,1 個 Component 的 Task 數目是固定不變的,但該 Component 使用的 Executor 執行緒數可以動態調整(例如:1 個 Executor 執行緒可以執行該 Component 的 1 個或多個 Task 實例)。這意味著,對於 1 個 Component 來說,#threads<=#tasks(執行緒數小於等於 Task 數目)這樣的情況是存在的。默認情況下 Task 的數目等於 Executor 執行緒數,即 1 個 Executor 執行緒只運行 1 個 Task。
總結如下:
- 一個運行中的 Topology 由集群中的多個 Worker 進程組成的;
- 在默認情況下,每個 Worker 進程默認啟動一個 Executor 執行緒;
- 在默認情況下,每個 Executor 默認啟動一個 Task 執行緒;
- Task 是組成 Component 的程式碼單元。
參考資料
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
