Spark學習進度-Spark環境搭建&Spark shell
Spark環境搭建
下載包
所需Spark包:我選擇的是2.2.0的對應Hadoop2.7版本的,下載地址://archive.apache.org/dist/spark/spark-2.2.0/
Spark 集群高可用搭建
對於 Spark Standalone 集群來說, 當 Worker 調度出現問題的時候, 會自動的彈性容錯, 將出錯的 Task 調度到其它 Worker 執行
但是對於 Master 來說, 是會出現單點失敗的, 為了避免可能出現的單點失敗問題, Spark 提供了兩種方式滿足高可用
-
使用 Zookeeper 實現 Masters 的主備切換
-
使用文件系統做主備切換
Step 1 停止 Spark 集群
cd /export/servers/spark
sbin/stop-all.shStep 2 修改配置文件, 增加 Spark 運行時參數, 從而指定 Zookeeper 的位置
-
進入
spark-env.sh所在目錄, 打開 vi 編輯cd /export/servers/spark/conf vi spark-env.sh -
編輯
spark-env.sh, 添加 Spark 啟動參數, 並去掉 SPARK_MASTER_HOST 地址
# 指定 Java Home export JAVA_HOME=/export/servers/jdk1.8.0_141 # 指定 Spark Master 地址 # export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 # 指定 Spark History 運行參數 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" # 指定 Spark 運行時參數 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"

Step 3 分發配置文件到整個集群
cd /export/servers/spark/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWDStep 4 啟動
-
在
node01上啟動整個集群cd /export/servers/spark sbin/start-all.sh sbin/start-history-server.sh -
在
node02上單獨再啟動一個 Mastercd /export/servers/spark sbin/start-master.sh
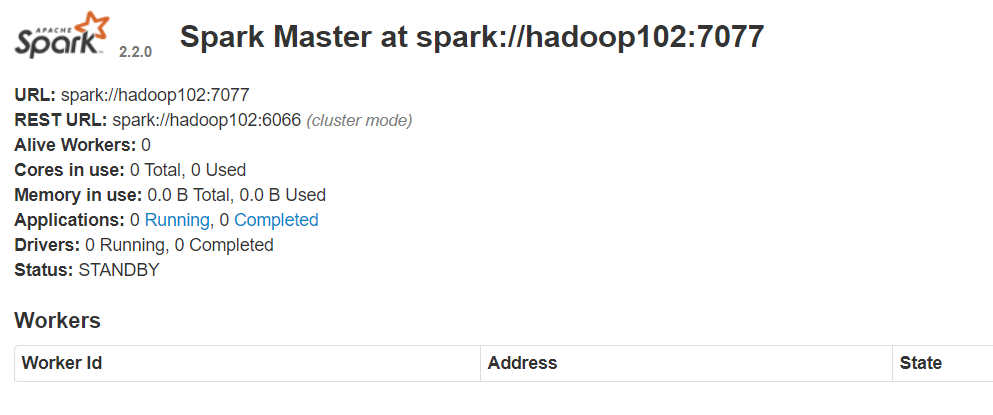
Step 5 查看 node01 master 和 node02 master 的 WebUI
-
你會發現一個是
ALIVE(主), 另外一個是STANDBY(備)

Spark shell
簡單介紹
Spark shell 是 Spark 提供的一個基於 Scala 語言的互動式解釋器, 類似於 Scala 提供的互動式解釋器, Spark shell 也可以直接在 Shell 中編寫程式碼執行
這種方式也比較重要, 因為一般的數據分析任務可能需要探索著進行, 不是一蹴而就的, 使用 Spark shell 先進行探索, 當程式碼穩定以後, 使用獨立應用的方式來提交任務, 這樣是一個比較常見的流程
Spark shell 的方式編寫 WordCount
|
Spark shell 簡介
|
|
Master地址的設置
Master 的地址可以有如下幾種設置方式
|
Step 1 準備文件
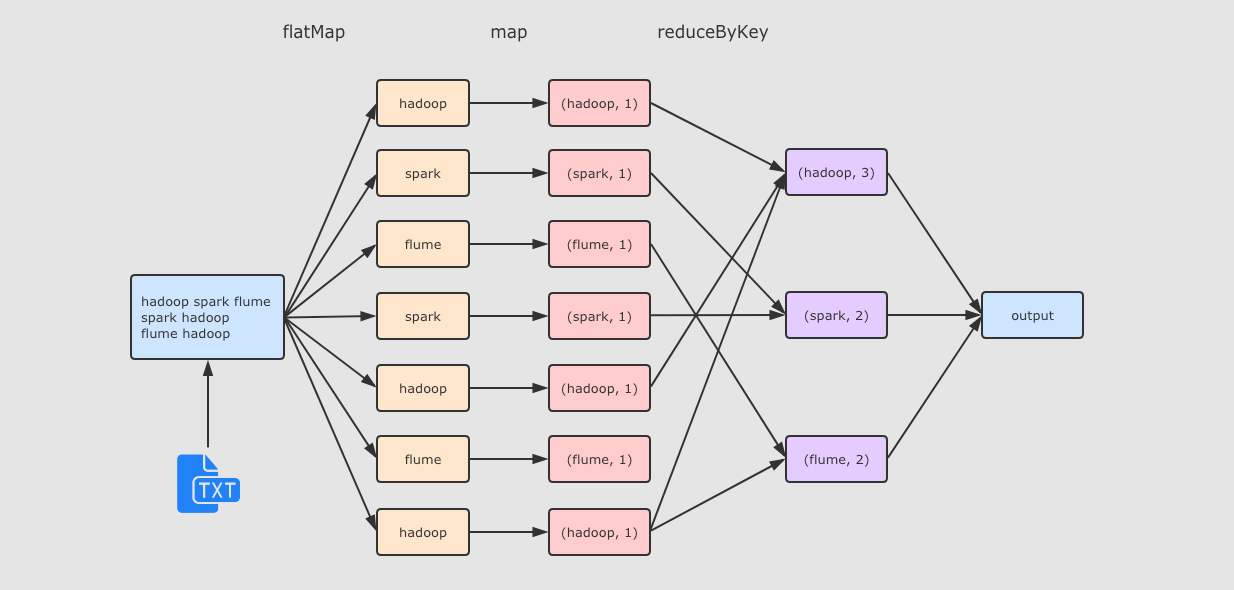
在 hadoop01 中創建文件 /export/data/wordcount.txt,文件內容如下
hadoop spark flume
spark hadoop
flume hadoopStep 2 啟動 Spark shell
cd /export/servers/spark
bin/spark-shell --master local[2]Step 3 執行如下程式碼

運行流程