技術基礎 | 監測Apache Cassandra的簡明方式——MCAC
點擊這裡在GitHub上訪問我們,以便深入了解DataStax的開源項目——Apache Cassandra指標收集器(Metric Collector for Apache Cassandra, or, MCAC)並試用示常式序。
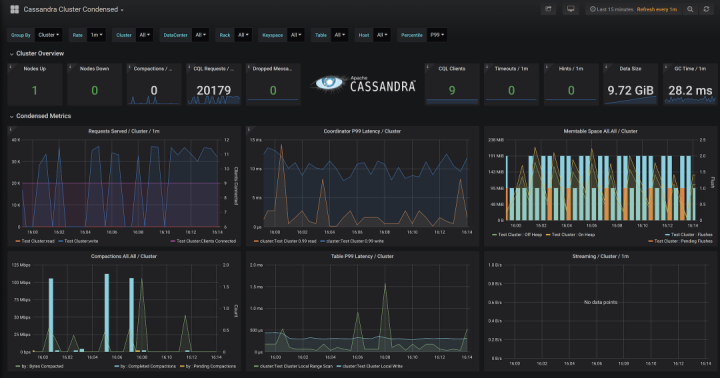
作為一個具有復原力的系統,Apache Cassandra可以讓用戶在其基礎上構建應用程式,但是很多使用者會感覺Cassandra有一點像是一個黑匣子。Cassandra並不是沒有豐富的監測指標,事實上,每個Cassandra表格都提供了超過300個指標系列(metric series)可供用戶使用。
但問題是,將集群本身、作業系統和應用層面的指標進行可視化並放入一個統一標準的視圖,這對於Cassandra的使用者來說並不容易。
01 什麼是Apache Cassandra指標收集器
為了解決這個問題,DataStax推出了一個新的開源項目,叫做Apache Cassandra指標收集器(Metric Collector for Apache Cassandra,簡稱為MCAC)。這個項目就Apache Cassandra的監測問題提供了一個開箱即用的解決方案。下面我們將簡單介紹這個工具是怎麼工作的。
MCAC是基於已經被廣泛運用的collectd守護進程構建的,並在其基礎上做了一些具有創意的微調。Collectd是一個指標收集守護進程,它己經被廣泛採用,並與包括prometheus、graphite、stackdriver以及其它各種外部指標系統集成良好。
雖然collectd可以開箱即用式地通過JMX(Java管理擴展)搜集指標數據,這個方法很可能耗時良久且只能適用於導出部分指標數據。更別提很多人根本不想在每個節點上都維護和配置指標守護進程。
我們已經將MCAC使用在了DataStax Astra中的Health(健康)標籤,並與我們為Apache Cassandra訂製的Kubernetes operator相捆綁。
02 MCAC的與眾不同之處
為了解決上述的問題,MCAC將我們的Java守護進程和可移植的Linux collectd打包成為一個單獨的組件。
開發者需要做的僅僅是將這個守護進程添加到cassandra-env.sh中,它將會啟動collectd並通過一個Unix套接字將Cassandra中的每一個指標數據傳入collectd。MCAC適用於從2.2到4.0的所有Apache Cassandra版本。
這種高效的傳遞指標數據的方式可以做到輸出每個節點的成千上萬個指標,同時幾乎不會對C*的性能構成任何影響。
MCAC不止發送指標數據,它還特別考慮了如何以開箱即用的方式與Prometheus協同工作。比如柱狀圖(histograms)是為了Prometheus中的聚合(aggregation)而特別設計,再比如標籤(labels)會在數據傳入時被自動轉換。這意味著你可以跨數據中心、跨機架(rack)甚至跨表靈活切割指標數據。
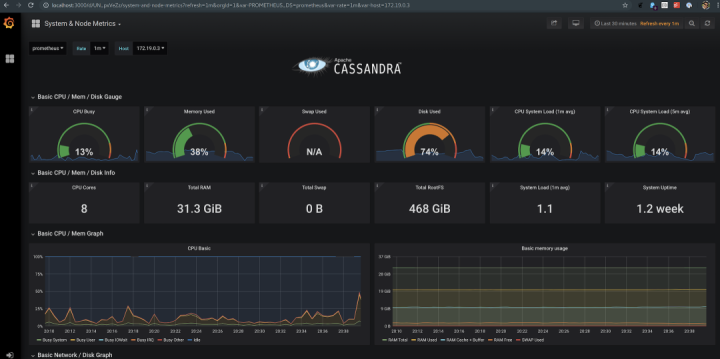
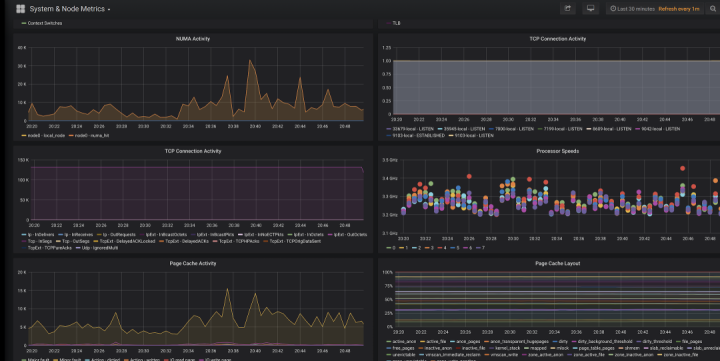
Cassandra的指標數據只是等式的一部分,藉助collectd,我們還可以收集並展示作業系統層面的指標數據,像是上下文切換(context switches)和磁碟/網路性能。
與節點活動情況相關的指標和非指標事件,MCAC也會為其創建歷史日誌。非指標事件包括關於刷盤(Flushes)、壓實操作(Compactions)、異常(Exceptions)、垃圾回收(GC)等細節資訊。這份DataLog(數據日誌)可以用於分析性能或其它對集群產生影響的事件。
如果您需要幫助,我們的SRE (Service Reliability Engineering)團隊隨時待命,幫助您診斷故障並解決問題。
最後,要是沒有辦法可視化這些指標數據可就太糟了!MCAC提供預置的Grafana儀錶盤,用來將所有指標聯結在一起。Grafana儀錶盤為使用者提供了監測Cassandra資料庫最好的解決方案。這些儀錶盤會隨著時間變化,它們關注系統的特定方面,從而讓使用者更容易藉此深入了解自己的集群。