Redis基礎篇(四)持久化:記憶體快照(RDB)
AOF好處是每次執行只需要記錄操作命令,記錄量不大。但在故障恢復時,需要逐一執行AOF的操作命令,如果日誌很大,恢復就很慢。
今天學習另一種持久化方式:記憶體快照。記憶體快照,是Redis某一時刻的狀態,以文件的形式保存在磁碟上。這個快照文件就稱為RDB文件,其中RDB就是Redis Database的縮寫。
當故障恢復時,只要把RDB文件讀入記憶體即可,恢復速度很快。但是記憶體快照並不是最優選項,為什麼呢?
我們還需要考慮兩個問題:
- 對哪些數據做快照?這關係到快照的執行效率;
- 做快照時,數據還能被增刪改嗎?這關係到Redis是否被阻塞,能否同時正常處理請求。
對哪些數據做快照?
Redis的數據都在記憶體中,為了提供所有數據的可靠性保證,它執行的是全量快照。
Redis提供兩個命令生成RDB文件:
save:在主執行緒中執行,但會導致阻塞;bgsave:創建一個子進程,專門用於寫入RDB文件,避免了主執行緒的阻塞。也是Redis RDB文件生成的默認配置。
做快照時,數據還能被增刪改嗎?
如果快照執行期間數據不能被修改,是會有潛在問題的。假如做快照的20s時間裡,如果數據不能被修改,Redis就不能處理對這些數據的寫操作,那無疑就會給業務服務造成巨大影響。
Redis藉助作業系統提供的寫時複製技術(Copy-On-Write,COW),在執行快照的同時,正常處理寫操作。
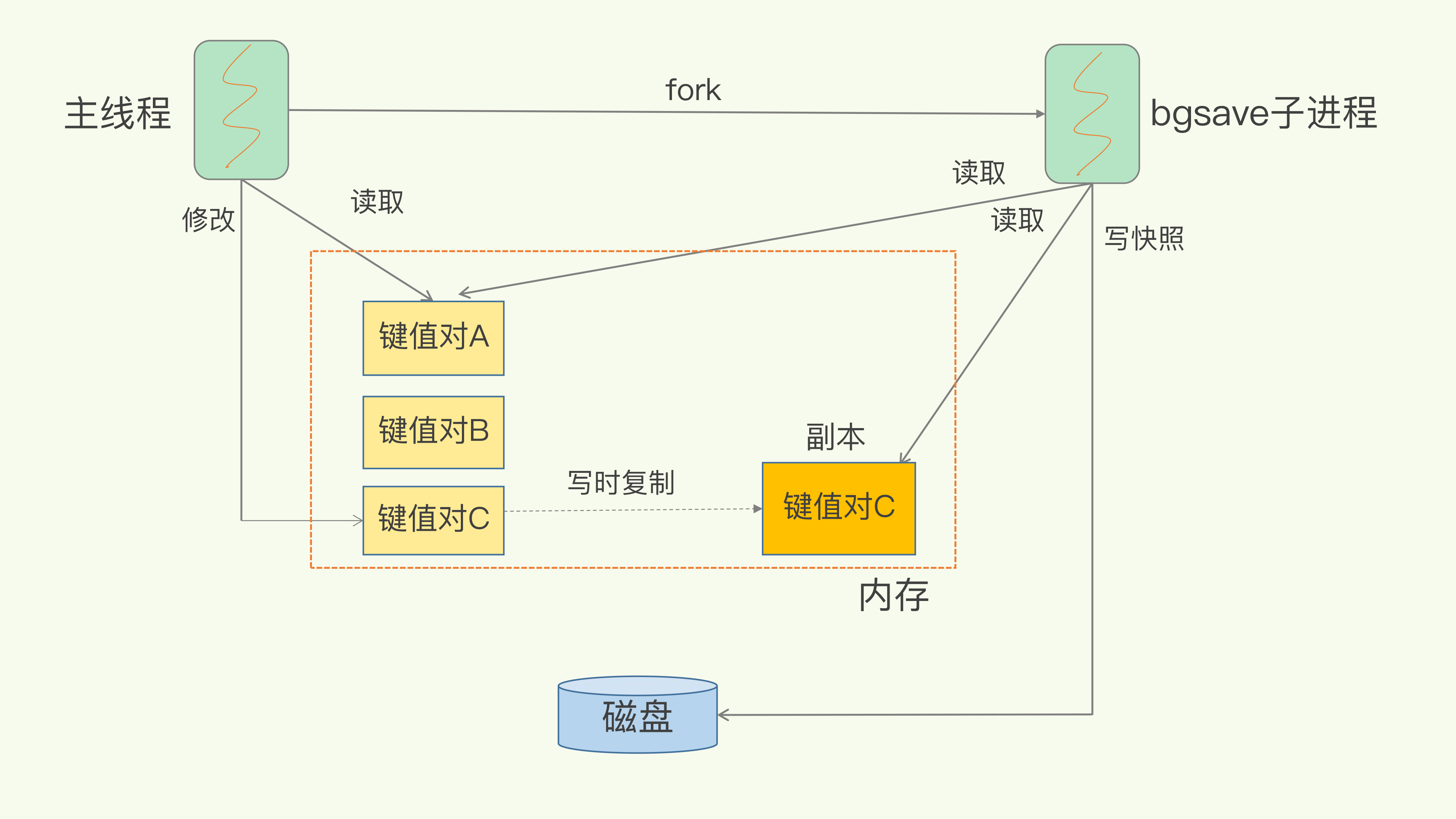
bgsave子進程是由主執行緒fork生成的,可以共享主執行緒的所有記憶體數據。
當主執行緒要修改數據時,通過COW複製一份副本出來給bgsave子進程。
這既保證快照的完整性,也允許主執行緒同時對數據進行修改,避免了對正常業務的影響。
可以每秒做一次快照嗎?
如果記憶體快照每隔幾分鐘執行一次,這樣就可能出現丟失數據的風險。那麼是否可以每秒做一次快照嗎?
如果頻繁地執行全量快照,會帶來兩方面開銷:
- 一是頻繁將全量數據寫入磁碟,會給磁碟帶來很大壓力。
- 二是bgsave子進程需要從主執行緒fork出來,fork創建過程本身會阻塞主執行緒,而且主執行緒的記憶體越大,阻塞時間越長。
既然頻繁執行全量快照不行,那還有什麼其他好方法嗎?
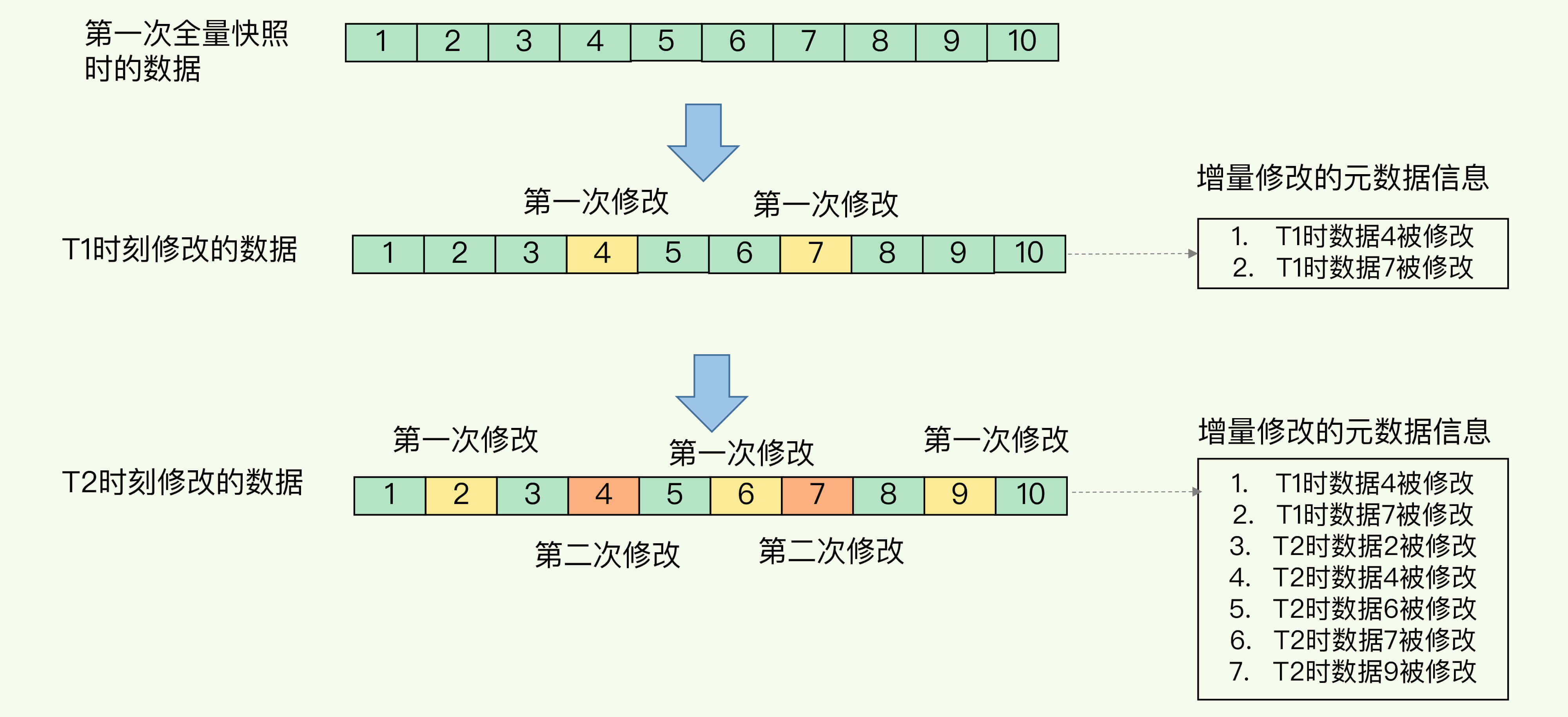
第一個方法是做增量快照。
在第一次做完全量快照後,T1和T2時刻如果再做快照,只需要將被修改的數據寫入快照文件就行了。如下圖所示:
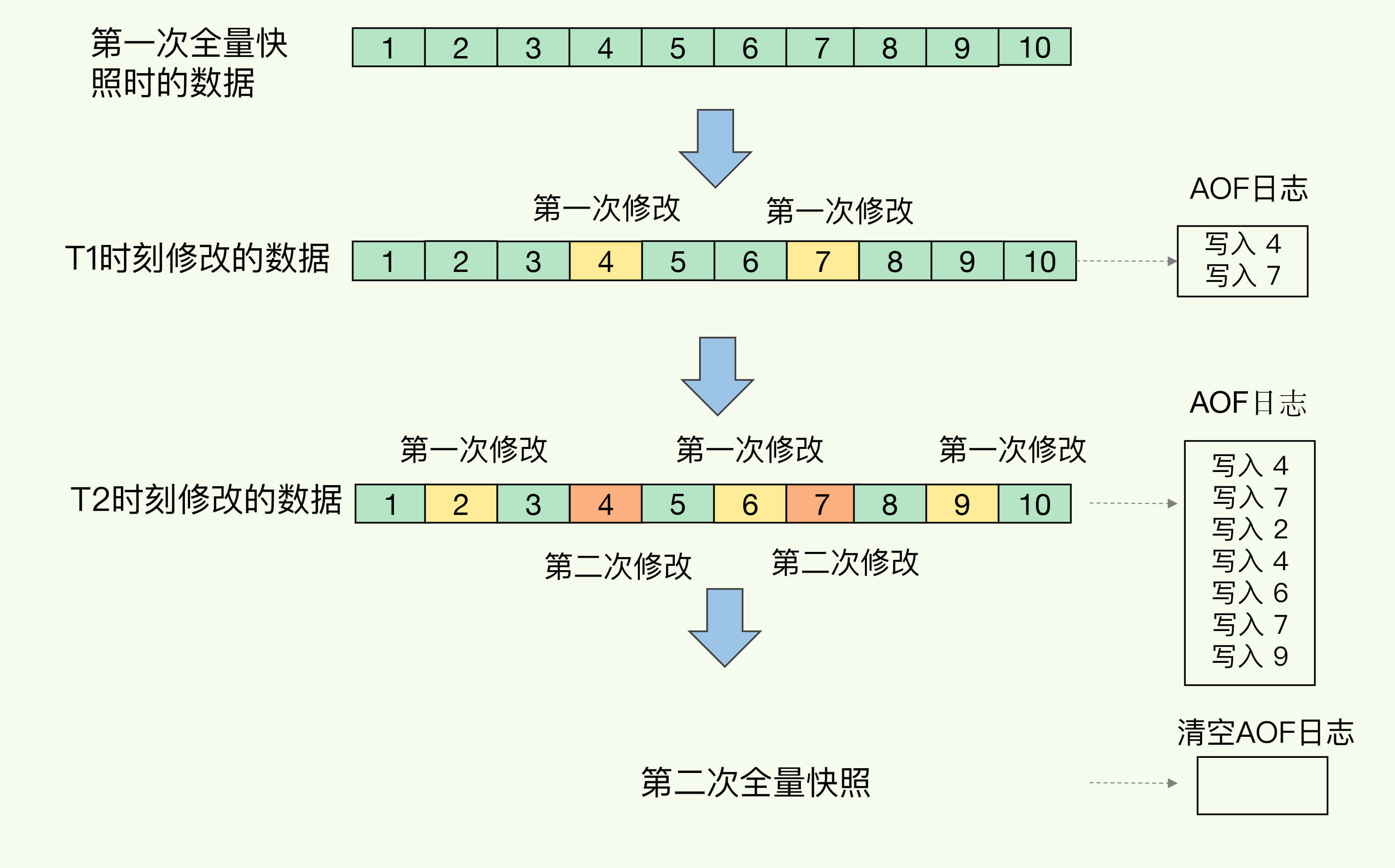
第二個方法是Redis 4.0提出一個混合使用AOF日誌和RDB快照的方法:RDB快照以一定的頻率執行,在兩次快照之間,使用AOF日誌記錄這期間的所有命令操作。
T1和T2時刻的修改,用AOF日誌記錄,等到第二次做全量快照時,就可以清空AOF日誌,因為此時的修改都已經記錄到快照中了。如下圖所示:
拓展
使用一個2核CPU、4GB記憶體、500GB磁碟的雲主機運行Redis,Redis資料庫的數據量大小差不多是2GB,使用了RDB做持久化保證。當時Redis的運行負載以修改操作為主,寫讀比例差不多在8:2左右,也就是說,如果有100個請求,80個請求執行的是修改操作。在這個場景下,用RDB做持久化有什麼風險嗎?
主要有兩方面風險:記憶體資源風險和CPU資源風險。
記憶體資源風險
Redis fork子進程做RDB持久化,由於寫的比例為80%,那麼在持久化過程中,「寫時複製」會重新分配整個實例80%的記憶體副本,大約需要重新分配1.6GB記憶體空間,這樣整個系統的記憶體使用接近飽和。
如果此時父進程又有大量新key寫入,很快機器記憶體就會被吃光,如果機器開啟了Swap機制,那麼Redis會有一部分數據被換到磁碟上。
當Redis訪問這部分在磁碟上的數據時,性能會急劇下降,已經達不到高性能的標準。
如果沒有開啟Swap,會直接觸發OOM,父子進程會面臨被系統kill掉的風險。
CPU資源風險
雖然子進程在做RDB持久化,但生成RDB快照過程會消耗大量的CPU資源。
雖然Redis處理請求是單執行緒的,但Redis Server還有其他執行緒在後台工作,例如AOF每秒刷盤、非同步關閉文件描述符這些操作。
由於機器只有2核CPU,這也就是意味著父進程佔用了超過一半的CPU資源。
此時子進程做RDB持久化,可能會產生CPU競爭,導致的結果是父進程處理請求延遲增大,子進程生成RDB快照的時間也會變長,整個Redis Server性能下降。
如果Redis進程綁定了CPU,那麼子進程會繼續父進程的CPU親和性屬性,子進程必然會與父進程爭奪同一個CPU資源,整個Redis Server的性能必然會受到影響。
因此如果Redis需要開啟定時RDB和AOF重寫,進程一定不要綁定CPU。
參考資料
- Redis設計與實現
- 10分鐘徹底理解Redis的持久化機制:RDB和AOF
- Redis兩種持久化機制RDB和AOF詳解(面試常問,工作常用)
- Redis持久化機制:RDB和AOF
- 05 | 記憶體快照:宕機後,Redis如何實現快速恢復?