JavaScript 數據結構與演算法之美 – 冒泡排序、插入排序、選擇排序
- 2019 年 10 月 3 日
- 筆記


1. 前言
演算法為王。
想學好前端,先練好內功,只有內功深厚者,前端之路才會走得更遠。
筆者寫的 JavaScript 數據結構與演算法之美 系列用的語言是 JavaScript ,旨在入門數據結構與演算法和方便以後複習。
之所以把冒泡排序、選擇排序、插入排序放在一起比較,是因為它們的平均時間複雜度都為 O(n2)。
請大家帶著問題:為什麼插入排序比冒泡排序更受歡迎 ?來閱讀下文。
2. 如何分析一個排序演算法
複雜度分析是整個演算法學習的精髓。
- 時間複雜度: 一個演算法執行所耗費的時間。
- 空間複雜度: 運行完一個程式所需記憶體的大小。
時間和空間複雜度的詳解,請看 JavaScript 數據結構與演算法之美 – 時間和空間複雜度。
學習排序演算法,我們除了學習它的演算法原理、程式碼實現之外,更重要的是要學會如何評價、分析一個排序演算法。
分析一個排序演算法,要從 執行效率、記憶體消耗、穩定性 三方面入手。
2.1 執行效率
1. 最好情況、最壞情況、平均情況時間複雜度
我們在分析排序演算法的時間複雜度時,要分別給出最好情況、最壞情況、平均情況下的時間複雜度。
除此之外,你還要說出最好、最壞時間複雜度對應的要排序的原始數據是什麼樣的。
2. 時間複雜度的係數、常數 、低階
我們知道,時間複雜度反應的是數據規模 n 很大的時候的一個增長趨勢,所以它表示的時候會忽略係數、常數、低階。
但是實際的軟體開發中,我們排序的可能是 10 個、100 個、1000 個這樣規模很小的數據,所以,在對同一階時間複雜度的排序演算法性能對比的時候,我們就要把係數、常數、低階也考慮進來。
3. 比較次數和交換(或移動)次數
這一節和下一節講的都是基於比較的排序演算法。基於比較的排序演算法的執行過程,會涉及兩種操作,一種是元素比較大小,另一種是元素交換或移動。
所以,如果我們在分析排序演算法的執行效率的時候,應該把比較次數和交換(或移動)次數也考慮進去。
2.2 記憶體消耗
也就是看空間複雜度。
還需要知道如下術語:
- 內排序:所有排序操作都在記憶體中完成;
- 外排序:由於數據太大,因此把數據放在磁碟中,而排序通過磁碟和記憶體的數據傳輸才能進行;
- 原地排序:原地排序演算法,就是特指空間複雜度是 O(1) 的排序演算法。
其中,冒泡排序就是原地排序演算法。
2.3 穩定性
- 穩定:如果待排序的序列中存在值
相等的元素,經過排序之後,相等元素之間原有的先後順序不變。
比如: a 原本在 b 前面,而 a = b,排序之後,a 仍然在 b 的前面; - 不穩定:如果待排序的序列中存在值
相等的元素,經過排序之後,相等元素之間原有的先後順序改變。
比如:a 原本在 b 的前面,而 a = b,排序之後, a 在 b 的後面;
3. 冒泡排序

思想
- 冒泡排序只會操作相鄰的兩個數據。
- 每次冒泡操作都會對相鄰的兩個元素進行比較,看是否滿足大小關係要求。如果不滿足就讓它倆互換。
- 一次冒泡會讓至少一個元素移動到它應該在的位置,重複 n 次,就完成了 n 個數據的排序工作。
特點
- 優點:排序演算法的基礎,簡單實用易於理解。
- 缺點:比較次數多,效率較低。
實現
// 冒泡排序(未優化) const bubbleSort = arr => { console.time('改進前冒泡排序耗時'); const length = arr.length; if (length <= 1) return; // i < length - 1 是因為外層只需要 length-1 次就排好了,第 length 次比較是多餘的。 for (let i = 0; i < length - 1; i++) { // j < length - i - 1 是因為內層的 length-i-1 到 length-1 的位置已經排好了,不需要再比較一次。 for (let j = 0; j < length - i - 1; j++) { if (arr[j] > arr[j + 1]) { const temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } console.log('改進前 arr :', arr); console.timeEnd('改進前冒泡排序耗時'); };優化:當某次冒泡操作已經沒有數據交換時,說明已經達到完全有序,不用再繼續執行後續的冒泡操作。
// 冒泡排序(已優化) const bubbleSort2 = arr => { console.time('改進後冒泡排序耗時'); const length = arr.length; if (length <= 1) return; // i < length - 1 是因為外層只需要 length-1 次就排好了,第 length 次比較是多餘的。 for (let i = 0; i < length - 1; i++) { let hasChange = false; // 提前退出冒泡循環的標誌位 // j < length - i - 1 是因為內層的 length-i-1 到 length-1 的位置已經排好了,不需要再比較一次。 for (let j = 0; j < length - i - 1; j++) { if (arr[j] > arr[j + 1]) { const temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; hasChange = true; // 表示有數據交換 } } if (!hasChange) break; // 如果 false 說明所有元素已經到位,沒有數據交換,提前退出 } console.log('改進後 arr :', arr); console.timeEnd('改進後冒泡排序耗時'); };測試
// 測試 const arr = [7, 8, 4, 5, 6, 3, 2, 1]; bubbleSort(arr); // 改進前 arr : [1, 2, 3, 4, 5, 6, 7, 8] // 改進前冒泡排序耗時: 0.43798828125ms const arr2 = [7, 8, 4, 5, 6, 3, 2, 1]; bubbleSort2(arr2); // 改進後 arr : [1, 2, 3, 4, 5, 6, 7, 8] // 改進後冒泡排序耗時: 0.318115234375ms分析
- 第一,冒泡排序是原地排序演算法嗎 ?
冒泡的過程只涉及相鄰數據的交換操作,只需要常量級的臨時空間,所以它的空間複雜度為 O(1),是一個原地排序演算法。 - 第二,冒泡排序是穩定的排序演算法嗎 ?
在冒泡排序中,只有交換才可以改變兩個元素的前後順序。
為了保證冒泡排序演算法的穩定性,當有相鄰的兩個元素大小相等的時候,我們不做交換,相同大小的數據在排序前後不會改變順序。
所以冒泡排序是穩定的排序演算法。 - 第三,冒泡排序的時間複雜度是多少 ?
最佳情況:T(n) = O(n),當數據已經是正序時。
最差情況:T(n) = O(n2),當數據是反序時。
平均情況:T(n) = O(n2)。
動畫
4. 插入排序
插入排序又為分為 直接插入排序 和優化後的 拆半插入排序 與 希爾排序,我們通常說的插入排序是指直接插入排序。
一、直接插入
思想
一般人打撲克牌,整理牌的時候,都是按牌的大小(從小到大或者從大到小)整理牌的,那每摸一張新牌,就掃描自己的牌,把新牌插入到相應的位置。
插入排序的工作原理:通過構建有序序列,對於未排序數據,在已排序序列中從後向前掃描,找到相應位置並插入。
步驟
- 從第一個元素開始,該元素可以認為已經被排序;
- 取出下一個元素,在已經排序的元素序列中從後向前掃描;
- 如果該元素(已排序)大於新元素,將該元素移到下一位置;
- 重複步驟 3,直到找到已排序的元素小於或者等於新元素的位置;
- 將新元素插入到該位置後;
- 重複步驟 2~5。
實現
// 插入排序 const insertionSort = array => { const len = array.length; if (len <= 1) return let preIndex, current; for (let i = 1; i < len; i++) { preIndex = i - 1; //待比較元素的下標 current = array[i]; //當前元素 while (preIndex >= 0 && array[preIndex] > current) { //前置條件之一: 待比較元素比當前元素大 array[preIndex + 1] = array[preIndex]; //將待比較元素後移一位 preIndex--; //游標前移一位 } if (preIndex + 1 != i) { //避免同一個元素賦值給自身 array[preIndex + 1] = current; //將當前元素插入預留空位 console.log('array :', array); } } return array; };測試
// 測試 const array = [5, 4, 3, 2, 1]; console.log("原始 array :", array); insertionSort(array); // 原始 array: [5, 4, 3, 2, 1] // array: [4, 5, 3, 2, 1] // array: [3, 4, 5, 2, 1] // array: [2, 3, 4, 5, 1] // array: [1, 2, 3, 4, 5]分析
- 第一,插入排序是原地排序演算法嗎 ?
插入排序演算法的運行並不需要額外的存儲空間,所以空間複雜度是 O(1),所以,這是一個原地排序演算法。 - 第二,插入排序是穩定的排序演算法嗎 ?
在插入排序中,對於值相同的元素,我們可以選擇將後面出現的元素,插入到前面出現元素的後面,這樣就可以保持原有的前後順序不變,所以插入排序是穩定的排序演算法。 - 第三,插入排序的時間複雜度是多少 ?
最佳情況:T(n) = O(n),當數據已經是正序時。
最差情況:T(n) = O(n2),當數據是反序時。
平均情況:T(n) = O(n2)。
動畫
二、拆半插入
插入排序也有一種優化演算法,叫做拆半插入。
思想
折半插入排序是直接插入排序的升級版,鑒於插入排序第一部分為已排好序的數組, 我們不必按順序依次尋找插入點, 只需比較它們的中間值與待插入元素的大小即可。
步驟
- 取 0 ~ i-1 的中間點 ( m = (i-1)>>1 ),array[i] 與 array[m] 進行比較,若 array[i] < array[m],則說明待插入的元素 array[i] 應該處於數組的 0 ~ m 索引之間;反之,則說明它應該處於數組的 m ~ i-1 索引之間。
- 重複步驟 1,每次縮小一半的查找範圍,直至找到插入的位置。
- 將數組中插入位置之後的元素全部後移一位。
- 在指定位置插入第 i 個元素。
註:x>>1 是位運算中的右移運算,表示右移一位,等同於 x 除以 2 再取整,即 x>>1 == Math.floor(x/2) 。
// 折半插入排序 const binaryInsertionSort = array => { const len = array.length; if (len <= 1) return; let current, i, j, low, high, m; for (i = 1; i < len; i++) { low = 0; high = i - 1; current = array[i]; while (low <= high) { //步驟 1 & 2 : 折半查找 m = (low + high) >> 1; // 注: x>>1 是位運算中的右移運算, 表示右移一位, 等同於 x 除以 2 再取整, 即 x>>1 == Math.floor(x/2) . if (array[i] >= array[m]) { //值相同時, 切換到高半區,保證穩定性 low = m + 1; //插入點在高半區 } else { high = m - 1; //插入點在低半區 } } for (j = i; j > low; j--) { //步驟 3: 插入位置之後的元素全部後移一位 array[j] = array[j - 1]; console.log('array2 :', JSON.parse(JSON.stringify(array))); } array[low] = current; //步驟 4: 插入該元素 } console.log('array2 :', JSON.parse(JSON.stringify(array))); return array; };測試
const array2 = [5, 4, 3, 2, 1]; console.log('原始 array2:', array2); binaryInsertionSort(array2); // 原始 array2: [5, 4, 3, 2, 1] // array2 : [5, 5, 3, 2, 1] // array2 : [4, 5, 5, 2, 1] // array2 : [4, 4, 5, 2, 1] // array2 : [3, 4, 5, 5, 1] // array2 : [3, 4, 4, 5, 1] // array2 : [3, 3, 4, 5, 1] // array2 : [2, 3, 4, 5, 5] // array2 : [2, 3, 4, 4, 5] // array2 : [2, 3, 3, 4, 5] // array2 : [2, 2, 3, 4, 5] // array2 : [1, 2, 3, 4, 5]注意:和直接插入排序類似,折半插入排序每次交換的是相鄰的且值為不同的元素,它並不會改變值相同的元素之間的順序,因此它是穩定的。
三、希爾排序
希爾排序是一個平均時間複雜度為 O(nlogn) 的演算法,會在下一個章節和 歸併排序、快速排序、堆排序 一起講,本文就不展開了。
5. 選擇排序
思路
選擇排序演算法的實現思路有點類似插入排序,也分已排序區間和未排序區間。但是選擇排序每次會從未排序區間中找到最小的元素,將其放到已排序區間的末尾。
步驟
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。
- 重複第二步,直到所有元素均排序完畢。
實現
const selectionSort = array => { const len = array.length; let minIndex, temp; for (let i = 0; i < len - 1; i++) { minIndex = i; for (let j = i + 1; j < len; j++) { if (array[j] < array[minIndex]) { // 尋找最小的數 minIndex = j; // 將最小數的索引保存 } } temp = array[i]; array[i] = array[minIndex]; array[minIndex] = temp; console.log('array: ', array); } return array; };測試
// 測試 const array = [5, 4, 3, 2, 1]; console.log('原始array:', array); selectionSort(array); // 原始 array: [5, 4, 3, 2, 1] // array: [1, 4, 3, 2, 5] // array: [1, 2, 3, 4, 5] // array: [1, 2, 3, 4, 5] // array: [1, 2, 3, 4, 5]分析
- 第一,選擇排序是原地排序演算法嗎 ?
選擇排序空間複雜度為 O(1),是一種原地排序演算法。 - 第二,選擇排序是穩定的排序演算法嗎 ?
選擇排序每次都要找剩餘未排序元素中的最小值,並和前面的元素交換位置,這樣破壞了穩定性。所以,選擇排序是一種不穩定的排序演算法。 - 第三,選擇排序的時間複雜度是多少 ?
無論是正序還是逆序,選擇排序都會遍歷 n2 / 2 次來排序,所以,最佳、最差和平均的複雜度是一樣的。
最佳情況:T(n) = O(n2)。
最差情況:T(n) = O(n2)。
平均情況:T(n) = O(n2)。
動畫
6. 解答開篇
為什麼插入排序比冒泡排序更受歡迎 ?
冒泡排序和插入排序的時間複雜度都是 O(n2),都是原地排序演算法,為什麼插入排序要比冒泡排序更受歡迎呢 ?
這裡關乎到 逆序度、滿有序度、有序度。
- 有序度:是數組中具有有序關係的元素對的個數。
有序元素對用數學表達式表示就是這樣:
有序元素對:a[i] <= a[j], 如果 i < j。-
滿有序度:把完全有序的數組的有序度叫作 滿有序度。
- 逆序度:正好跟有序度相反(默認從小到大為有序)。
逆序元素對:a[i] > a[j], 如果 i < j。
同理,對於一個倒序排列的數組,比如 6,5,4,3,2,1,有序度是 0;
對於一個完全有序的數組,比如 1,2,3,4,5,6,有序度就是 **n*(n-1)/2** ,也就是滿有序度為 15。
原因
- 冒泡排序不管怎麼優化,元素交換的次數是一個固定值,是原始數據的逆序度。
- 插入排序是同樣的,不管怎麼優化,元素移動的次數也等於原始數據的逆序度。
- 但是,冒泡排序的數據交換要比插入排序的數據移動要複雜,冒泡排序需要 3 個賦值操作,而插入排序只需要 1 個,數據量一旦大了,這差別就非常明顯了。
7. 複雜性對比
複雜性對比
| 名稱 | 平均 | 最好 | 最壞 | 空間 | 穩定性 | 排序方式 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) | O(1) | Yes | In-place |
| 插入排序 | O(n2) | O(n) | O(n2) | O(1) | Yes | In-place |
| 選擇排序 | O(n2) | O(n2) | O(n2) | O(1) | No | In-place |
演算法可視化工具
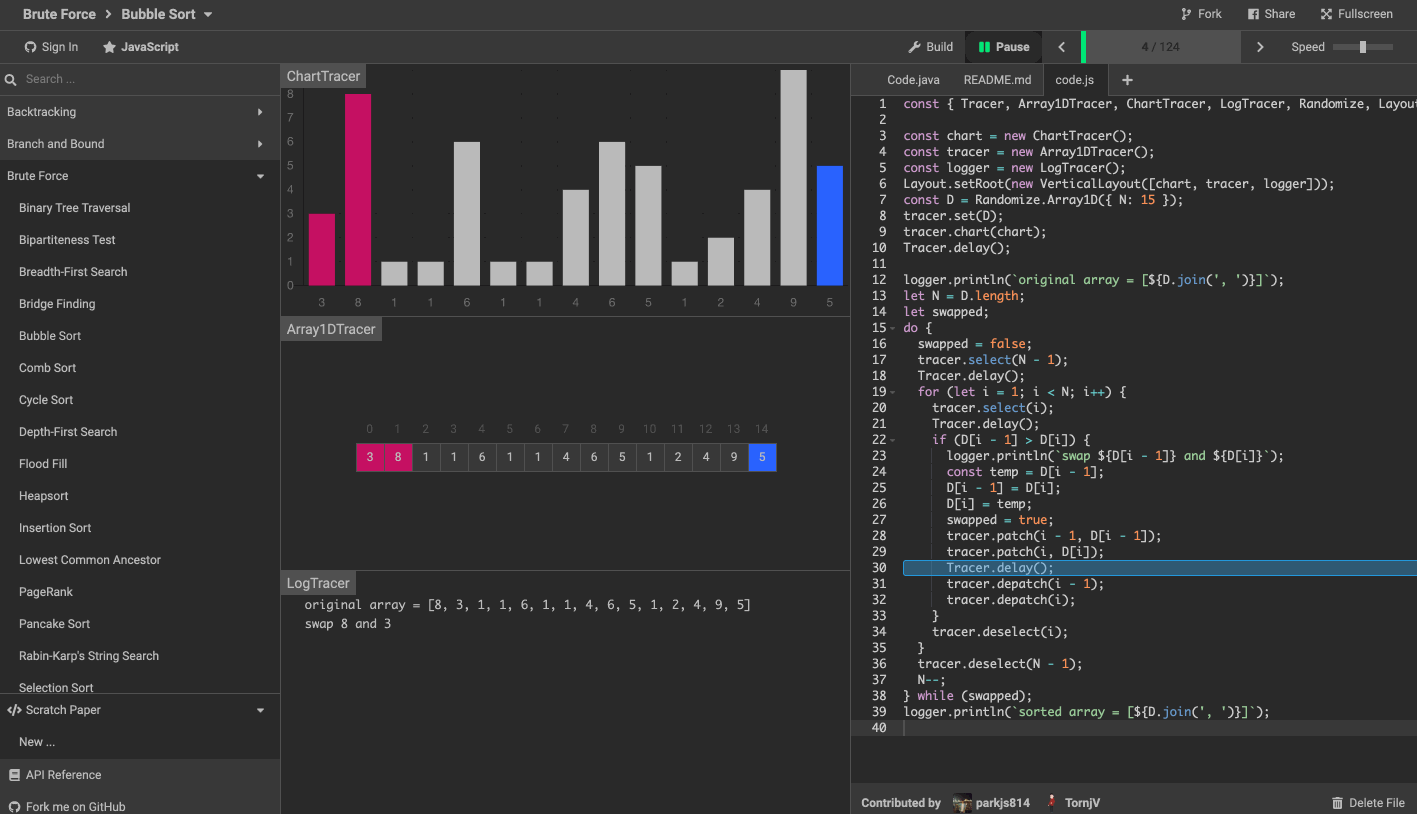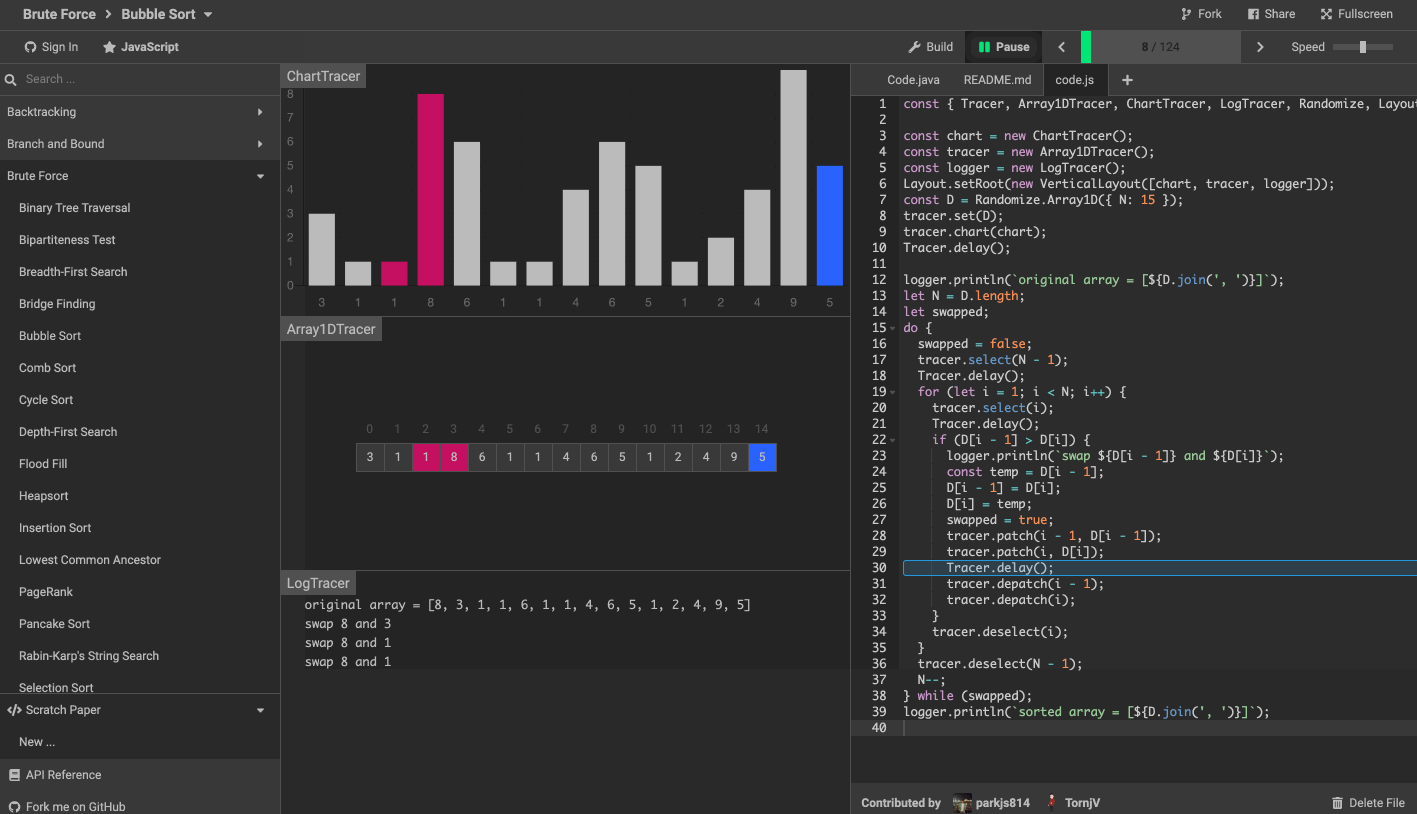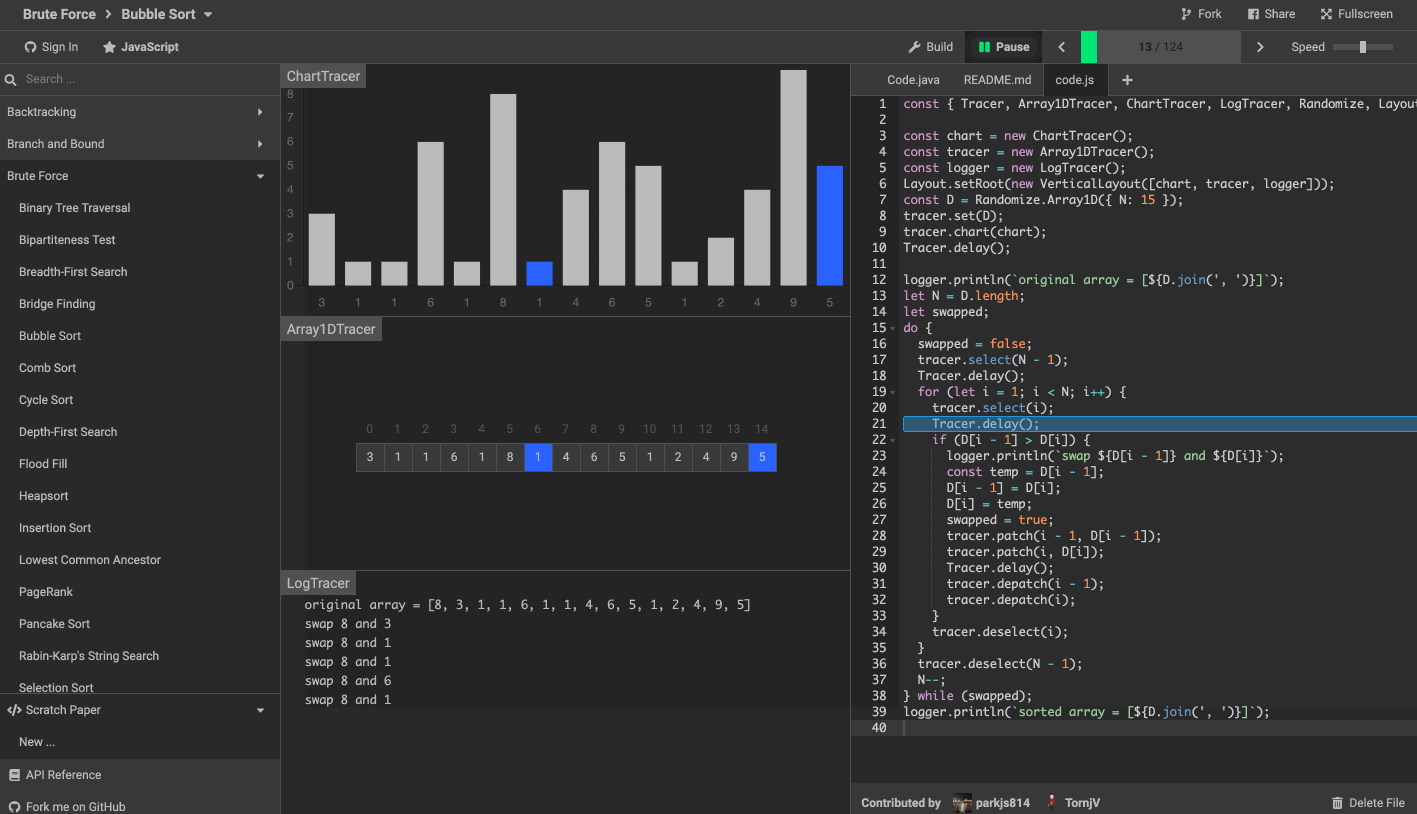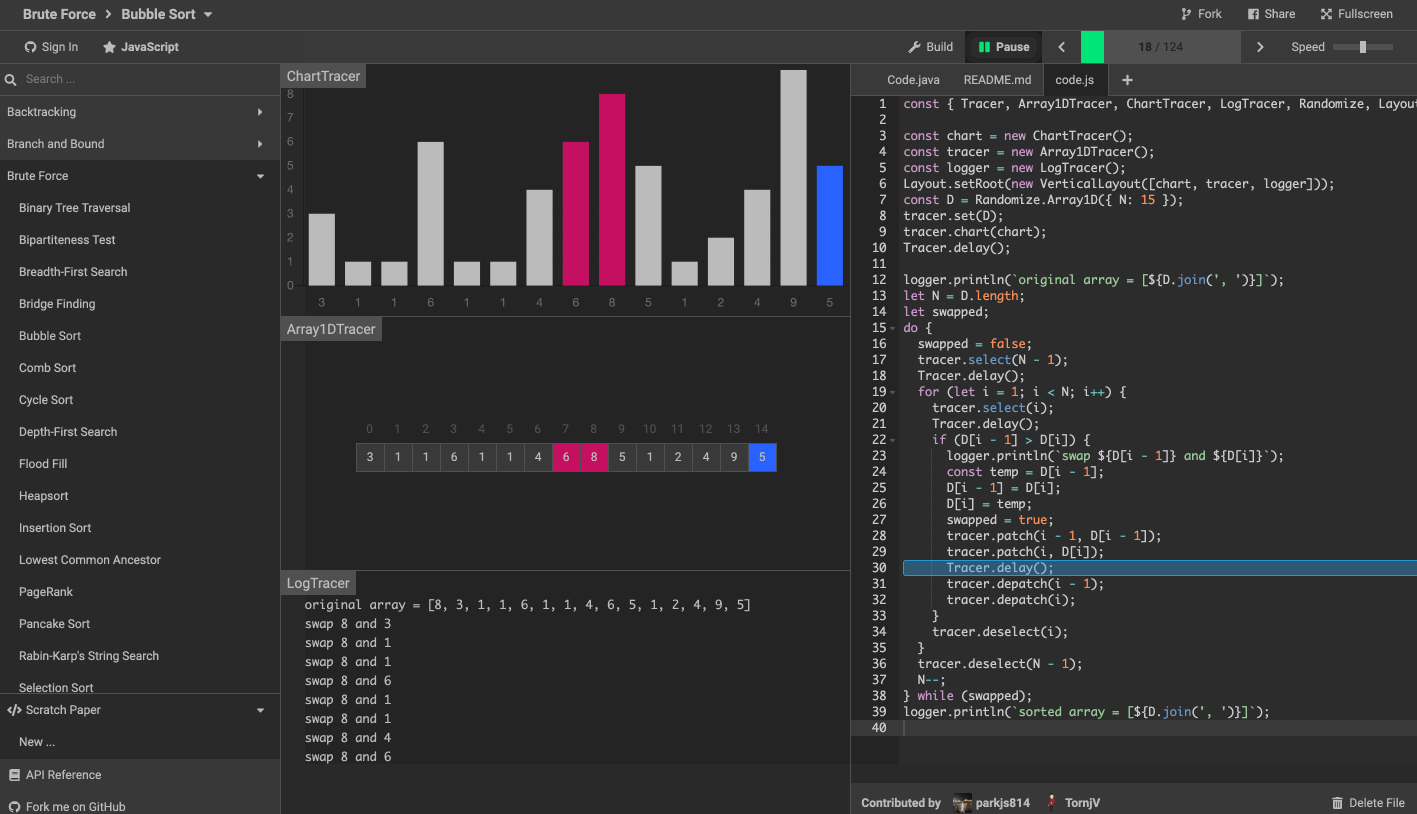
這裡推薦一個演算法可視化工具。
演算法可視化工具 algorithm-visualizer 是一個互動式的在線平台,可以從程式碼中可視化演算法,還可以看到程式碼執行的過程。
效果如下圖。
8. 最後
喜歡就點個小星星吧。
文中所有的程式碼及測試事例都已經放到我的 GitHub 上了。
參考文章:
