Java進階專題(二十) 消息中間件架構體系(2)– RabbitMQ研究
前言
接上文,這個繼續介紹RabbitMQ,並理解其底層原理。
介紹
RabbitMQ是由erlang語言開發,基於AMQP(Advanced Message Queue 高級消息隊列協議)協議實現的消息隊列。
為什麼使用RabbitMQ呢?
1、使得簡單,功能強大。
2、基於AMQP協議。
3、社區活躍,文檔完善。
4、高並發性能好,這主要得益於Erlang語言。
5、Spring Boot默認已集成RabbitMQ
AMQP協議
AMQP基本介紹
AMQP,即Advanced Message Queuing Protocol,一個提供統一消息服務的應用層標準高級消息隊列協議,是應用層協議的一個開放標準,為面向消息的中間件設計。基於此協議的客戶端與消息中間件可傳遞消息,並不受客戶端/中間件同產品、不同的開發語言等條件的限制。
AMQP的實現有:RabbitMQ、OpenAMQ、Apache Qpid、Redhat Enterprise MRG、AMQP Infrastructure、
ØMQ、Zyre等。
目前Rabbitmq最新的版本默認支援的是AMQP 0-9-1,該協議總共包含了3部分:
Module Layer: 位於協議的最高層,主要定義了一些供客戶端調用的命令,客戶端可以利用這些命令實現
自定義的業務邏輯。
例如,客戶端可以是使用Queue.Declare命令聲明一個隊列或者使用Basic.Consume訂閱消費一個隊列中的
消息。
Session Layer: 位於中間層,主要負責將客戶端的命令發送給服務端,在將服務端的應答返回給客戶端,
主要為客戶端與伺服器之間的通訊提供可靠性的同步機制和錯誤處理。
Transport Layer: 位於最底層,主要傳輸二進位數據流,提供幀的處理、信道的復用、錯誤檢查和數據表
示等。
AMQP生產者流轉過程
當客戶端與Broker建立連接的時候,客戶端會向Broker發送一個Protocol Header 0-9-1的報文頭,以此通知Broker本次交互才採用的是AMQP 0-9-1協議。
緊接著Broker返回Connection.Start來建立連接,在連接的過程中涉及Connection.Start/.Start-OK、Connection. Tune/. Tune-OK、Connection.Open/.Open-OK這6個命令的交互。
連接建立以後需要創建通道,會使用到Channel.Open , Channel.Open-OK命令,在進行交換機聲明的時候需要使用到Exchange.Declare以及Exchange.Declare-OK的命令。以此類推,在聲明隊列以及完成隊列和交換機的綁定的時候都會使用到指定的命令來完成。
在進行消息發送的時候會使用到Basic.Publish命令完成,這個命令還包含了Conetent-Header和Content-Body。Content Header裡面包含的是消息體的屬性,Content-Body包含了消息體本身。
AMQP消費者流轉過程
消費者消費消息的時候,所涉及到的命令和生成者大部分都是相同的。在原有的基礎之上,多個幾個命令:Basic.Qos/.Qos-OK以及Basic.Consume和Basic.Consume-OK。
其中Basic.Qos/.Qos-OK這兩個命令主要用來確認消費者最大能保持的未確認的消息數時使用。Basic.Consume和Basic.Consume-OK這兩個命令主要用來進行消息消費確認。
RabbitMQ的特性
RabbitMQ使用Erlang語言編寫,使用Mnesia資料庫存儲消息。
(1)可靠性(Reliability) RabbitMQ 使用一些機制來保證可靠性,如持久化、傳輸確認、發布確認。
(2)靈活的路由(Flexible Routing) 在消息進入隊列之前,通過Exchange 來路由消息的。對於典型的路由功
能,RabbitMQ 已經提供了一些內置的Exchange 來實現。針對更複雜的路由功能,可以將多個Exchange 綁定在
一起,也通過插件機制實現自己的Exchange 。
(3)消息集群(Clustering) 多個RabbitMQ 伺服器可以組成一個集群,形成一個邏輯Broker 。
(4)高可用(Highly Available Queues) 隊列可以在集群中的機器上進行鏡像,使得在部分節點出問題的情況下
隊列仍然可用。
(5)多種協議(Multi-protocol) RabbitMQ 支援多種消息隊列協議,比如AMQP、STOMP、MQTT 等等。
(6)多語言客戶端(Many Clients) RabbitMQ 幾乎支援所有常用語言,比如Java、.NET、Ruby、PHP、C#、
JavaScript 等等。
(7)管理介面(Management UI) RabbitMQ 提供了一個易用的用戶介面,使得用戶可以監控和管理消息、集群
中的節點。
(8)插件機制(Plugin System)
RabbitMQ提供了許多插件,以實現從多方面擴展,當然也可以編寫自己的插件。
工作模型

名詞解釋
Broker :即RabbitMQ的實體伺服器。提供一種傳輸服務,維護一條從生產者到消費者的傳輸線路,保證消息數據能按照指定的方式傳輸。
Exchange :消息交換機。指定消息按照什麼規則路由到哪個隊列Queue。
Queue :消息隊列。消息的載體,每條消息都會被投送到一個或多個隊列中。
Binding :綁定。作用就是將Exchange和Queue按照某種路由規則綁定起來。
Routing Key:路由關鍵字。Exchange根據Routing Key進行消息投遞。定義綁定時指定的關鍵字稱為Binding Key。
Vhost:虛擬主機。一個Broker可以有多個虛擬主機,用作不同用戶的許可權分離。一個虛擬主機持有一組Exchange、Queue和Binding。
Producer:消息生產者。主要將消息投遞到對應的Exchange上面。一般是獨立的程式。
Consumer:消息消費者。消息的接收者,一般是獨立的程式。
Connection:Producer 和Consumer 與Broker之間的TCP長連接。
Channel:消息通道,也稱信道。在客戶端的每個連接里可以建立多個Channel,每個Channel代表一個會話任務。在RabbitMQ Java Client API中,channel上定義了大量的編程介面。
交換機類型
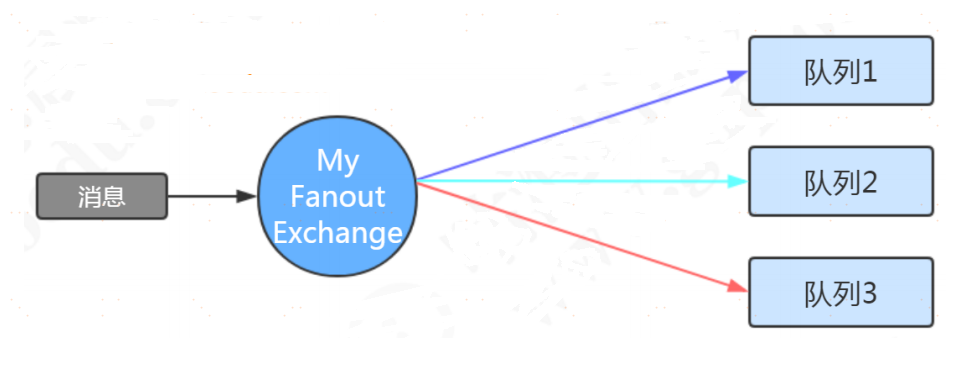
Direct Exchange 直連交換機
定義:直連類型的交換機與一個隊列綁定時,需要指定一個明確的binding key。
路由規則:發送消息到直連類型的交換機時,只有routing key跟binding key完全匹配時,綁定的隊列才能收到消息。
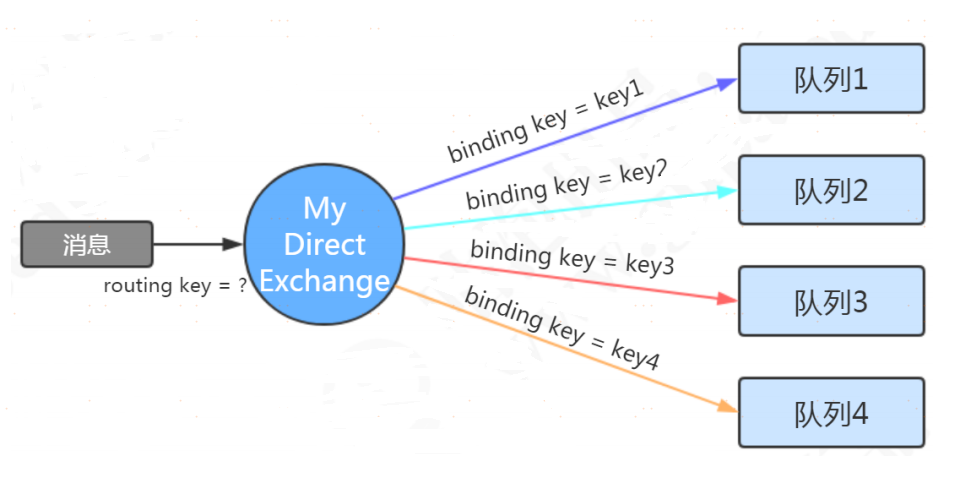
Topic Exchange 主題交換機
定義:主題類型的交換機與一個隊列綁定時,可以指定按模式匹配的routing key。
通配符有兩個,*代表匹配一個單詞。#代表匹配零個或者多個單詞。單詞與單詞之間用 . 隔開。
路由規則:發送消息到主題類型的交換機時,routing key符合binding key的模式時,綁定的隊列才能收到消息。
// 只有隊列1能收到消息
channel.basicPublish("MY_TOPIC_EXCHANGE", "sh.abc", null, msg.getBytes());
// 隊列2和隊列3能收到消息
channel.basicPublish("MY_TOPIC_EXCHANGE", "bj.book", null, msg.getBytes());
// 只有隊列4能收到消息
channel.basicPublish("MY_TOPIC_EXCHANGE", "abc.def.food", null, msg.getBytes());
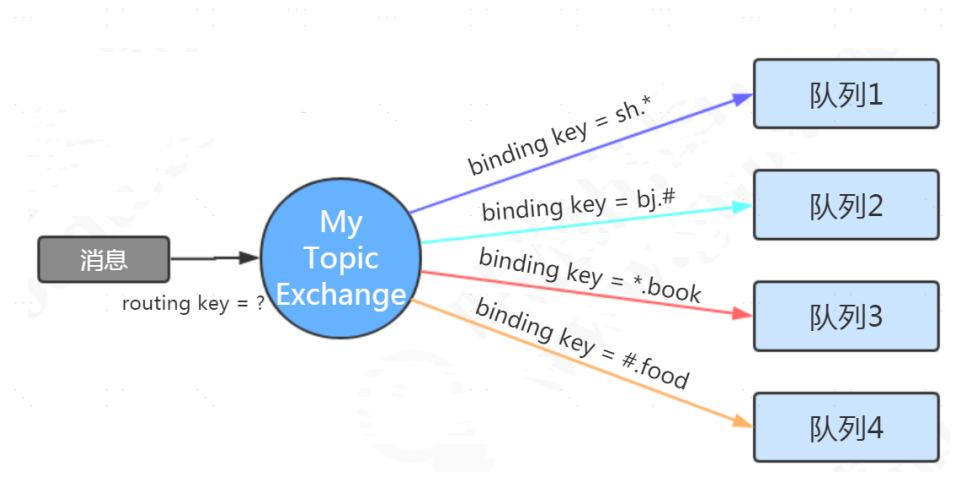
Fanout Exchange 廣播交換機
定義:廣播類型的交換機與一個隊列綁定時,不需要指定binding key。
路由規則:當消息發送到廣播類型的交換機時,不需要指定routing key,所有與之綁定的隊列都能收到消息。
RabbitMq安裝
下載鏡像
docker pull rabbitmq
創建並啟動容器
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq --hostname myRabbit -e RABBITMQ_DEFAULT_VHOST=my_vhost -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin rabbitmq
- -d 後台運行容器;
- –name 指定容器名;
- -p 指定服務運行的埠(5672:應用訪問埠;15672:控制台Web埠號);
- -v 映射目錄或文件;
- –hostname 主機名(RabbitMQ的一個重要注意事項是它根據所謂的 「節點名稱」 存儲數據,默認為主機名);
- -e 指定環境變數;(RABBITMQ_DEFAULT_VHOST:默認虛擬機名;RABBITMQ_DEFAULT_USER:默認的用戶名;RABBITMQ_DEFAULT_PASS:默認用戶名的密碼)
啟動rabbitmq後台管理服務
docker exec -it rabbitmq rabbitmq-plugins enable rabbitmq_management
訪問後台頁面:
//127.0.0.1:15672 初始密碼: admin admin

RabbitMQ快速入門
maven依賴
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
</dependencies>
rabbitmq配置類
/**
* @author 原
* @date 2020/12/22
* @since 1.0
**/
@Configuration
public class RabbitConfig {
public static final String EXCHANGE_TOPICS_INFORM = "exchange_topic_inform";
public static final String QUEUE_SMS = "queue_sms";
public static final String QUEUE_EMAIL = "queue_email";
@Bean
public Exchange getExchange() {
//durable(true)持久化,消息隊列重啟後交換機仍然存在
return ExchangeBuilder.topicExchange(EXCHANGE_TOPICS_INFORM).durable(true).build();
}
@Bean("queue_sms")
public Queue getQueueSms(){
return new Queue(QUEUE_SMS);
}
@Bean("queue_email")
public Queue getQueueEmail(){
return new Queue(QUEUE_EMAIL);
}
@Bean
public Binding bindingSms(@Qualifier("queue_sms") Queue queue, Exchange exchange){
return BindingBuilder.bind(queue).to(exchange).with("demo.#.sms").noargs();
}
@Bean
public Binding bindingEmail(@Qualifier("queue_email") Queue queue, Exchange exchange){
return BindingBuilder.bind(queue).to(exchange).with("demo.#.email").noargs();
}
}
生產者
@Service
public class RabbitmqProviderService {
@Autowired
RabbitTemplate rabbitTemplate;
public void sendMessageSms(String message) {
rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.sms",message);
}
public void sendMessageEmail(String message) {
rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.email",message);
}
}
消費者
@Component
public class RabbitMqConsumer {
@RabbitListener(queues = {RabbitConfig.QUEUE_EMAIL})
public void listenerEmail(String message, Message msg , Channel channel) {
System.out.println("EMAIL:"+message);
System.out.println(msg);
System.out.println(channel);
}
@RabbitListener(queues = {RabbitConfig.QUEUE_SMS})
public void listenerSms(String message) {
System.out.println("SMS:"+message);
}
}
啟動類
/**
* @author 原
* @date 2020/12/22
* @since 1.0
**/
@SpringBootApplication
@EnableRabbit
public class RabbitMqApplicaiton {
public static void main(String[] args) {
ResourceLoader resourceLoader = new DefaultResourceLoader(RabbitMqApplicaiton.class.getClassLoader());
try {
String path = resourceLoader.getResource("classpath:").getURL().getPath();
System.out.println(path);
} catch (IOException e) {
e.printStackTrace();
}
SpringApplication.run(RabbitMqApplicaiton.class, args);
}
}
web
@RestController
public class DemoController {
@Autowired
RabbitmqProviderService rabbitmqProviderService;
@RequestMapping("/sms")
public void sendMsgSms(String msg) {
rabbitmqProviderService.sendMessageSms(msg);
}
@RequestMapping("/eamil")
public void sendMsgEmail(String msg) {
rabbitmqProviderService.sendMessageEmail(msg);
}
}
通過頁面發送消息:
//localhost:44000/sms?msg=1111
//localhost:44000/email?msg=1111

RabbitMQ進階用法
TTL
消息設置過期時間
MessageProperties messageProperties = new MessageProperties();
messageProperties.setExpiration("30000");
Message msg = new Message("消息內容".getBytes(),messageProperties);
//如果消息沒有及時消費,那麼經過30秒以後,消息變成死信,Rabbitmq會將這個消息直接丟棄。
rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_TOPICS_INFORM,"demo.one.sms",msg);
隊列設置過期時間
Queue queue = QueueBuilder.durable(QUEUE_SMS).ttl(30000).build();
死信隊列
當一個消息變成死信了以後,默認情況下這個消息會被mq刪除。如果我們給隊列指定了”死信交換機”(DLX:
Dead-Letter-Exchange),那麼此時這個消息就會轉發到死信交換機,進而被與死信交換機綁定的隊列(死信隊列)進行消費。從而實現了延遲消息發送的效果。有三種情況消息會進入DLX(Dead Letter Exchange)死信交換機。
1、(NACK || Reject ) && requeue == false
2、消息過期
3、隊列達到最大長度,可以通過x-max-length參數來指定隊列的長度,如果不指定,可以認為是無限長(先入隊的消息會被發送到DLX)
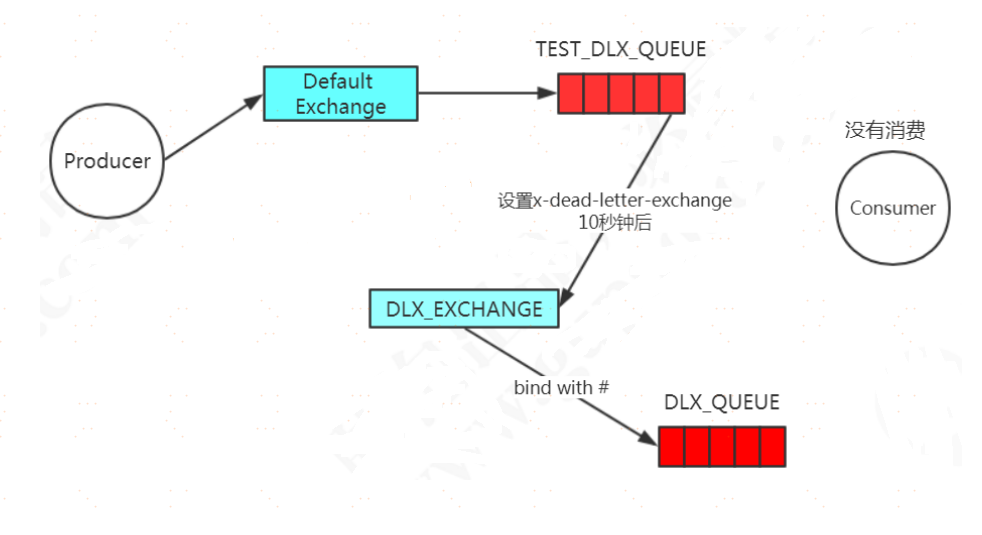
1、聲明死信交換機、死信隊列、死信交換機和死信隊列的綁定
// 聲明死信交換機
@Bean(name = "dlx.exchange")
public Exchange dlxExchange() {
return
ExchangeBuilder.directExchange("dlx.exchange").durable(true).build() ;
}
// 聲明死信隊列
@Bean(name = "dlx.queue")
public Queue dlxQueue() {
return QueueBuilder.durable("dlx.queue").build() ;
}
// 完成死信隊列和死信交換機的綁定
@Bean
public Binding dlxQueueBindToDlxExchange(@Qualifier(value =
"dlx.exchange") Exchange exchange, @Qualifier(value = "dlx.queue")
Queue queue) {
return
BindingBuilder.bind(queue).to(exchange).with("delete").noargs() ;
}
2、將死信隊列作為普通隊列的屬性設置過去
// 聲明隊列
@Bean(name = "direct.queue_02")
public Queue commonQueue02() {
QueueBuilder queueBuilder =
QueueBuilder.durable("direct.queue_02");
queueBuilder.deadLetterExchange("dlx.exchange") ; // 將死信交換機作
為普通隊列的屬性設置過去
queueBuilder.deadLetterRoutingKey("delete") ; // 設置消息的
routingKey
// queueBuilder.ttl(30000) ; // 設置隊列消息的過期時間,為30秒
// queueBuilder.maxLength(2) ; // 設置隊列的最大長度
return queueBuilder.build() ;
}
3、消費端進行同樣的設置,並且指定消費死信隊列
@Component
public class RabbitmqDlxQueueConsumer{
// 創建日誌記錄器
private static final Logger LOGGER =
LoggerFactory.getLogger(RabbitmqDlxQueueConsumer.class) ;
@RabbitListener(queues = "dlx.queue")
public void dlxQueueConsumer(String msg) {
LOGGER.info("dlx queue msg is : {} ", msg);
}
}
優先隊列
優先順序高的消息可以優先被消費,但是:只有消息堆積(消息的發送速度大於消費者的消費速度)的情況下優先順序
才有意義。
Map<String, Object> argss = new HashMap<String, Object>();
argss.put("x-max-priority",10); // 隊列最大優先順序
channel.queueDeclare("ORIGIN_QUEUE", false, false, false, argss);
延遲隊列
RabbitMQ本身不支援延遲隊列。可以使用TTL結合DLX的方式來實現消息的延遲投遞,即把DLX跟某個隊列綁定,
到了指定時間,消息過期後,就會從DLX路由到這個隊列,消費者可以從這個隊列取走消息。
另一種方式是使用rabbitmq-delayed-message-exchange插件。
當然,將需要發送的資訊保存在資料庫,使用任務調度系統掃描然後發送也是可以實現的。
服務端限流
在AutoACK為false的情況下,如果一定數目的消息(通過基於consumer或者channel設置Qos的值)未被確認
前,不進行消費新的消息。
channel.basicQos(2); // 如果超過2條消息沒有發送ACK,當前消費者不再接受隊列消息
channel.basicConsume(QUEUE_NAME, false, consumer);
RabbitMQ如何保證可靠性
首先需要明確,效率與可靠性是無法兼得的,如果要保證每一個環節都成功,勢必會對消息的收發效率造成影響。如果是一些業務實時一致性要求不是特別高的場合,可以犧牲一些可靠性來換取效率。
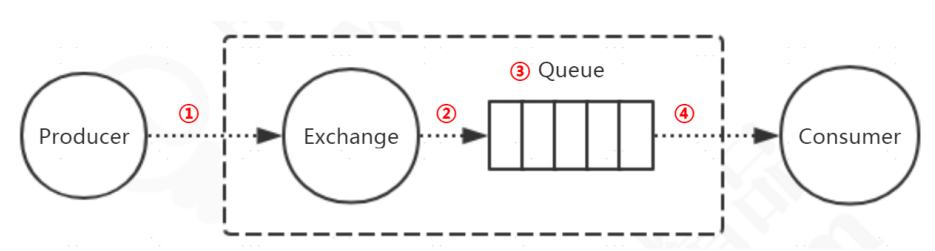
① 代表消息從生產者發送到Exchange;
② 代表消息從Exchange路由到Queue;
③ 代表消息在Queue中存儲;
④ 代表消費者訂閱Queue並消費消息。
1、確保消息發送到RabbitMQ伺服器
可能因為網路或者Broker的問題導致①失敗,而生產者是無法知道消息是否正確發送到Broker的。
有兩種解決方案,第一種是Transaction(事務)模式,第二種Confirm(確認)模式。
在通過channel. txSelect方法開啟事務之後,我們便可以發布消息給RabbitMQ了,如果事務提交成功,則消息定到達了RabbitMQ中,如果在事務提交執行之前由於RabbitMQ異常崩潰或者其他原因拋出異常,這個時候我們便可以將其捕獲,進而通過執行channel. txRollback方法來實現事務回滾。使用事務機制的話會「吸干」RabbitMQ性能,一般不建議使用。
生產者通過調用channel. confirmSelect方法(即Confirm. Select命令)將信道設置為confirm模式。一旦消息投遞到所有匹配的隊列之後,RabbitMQ就會發送一個確認(Basic. Ack)給生產者(包含消息的唯一ID),這就使得生產者知曉消息已經正確到達了目的地了。
2、確保消息路由到正確的隊列
可能因為路由關鍵字錯誤,或者隊列不存在,或者隊列名稱錯誤導致②失敗。
使用mandatory參數和ReturnListener,可以實現消息無法路由的時候返回給生產者。
另一種方式就是使用備份交換機(alternate-exchange),無法路由的消息會發送到這個交換機上。
3、確保消息在隊列正確地存儲
可能因為系統宕機、重啟、關閉等等情況導致存儲在隊列的消息丟失,即③出現問題。
1、做隊列、交換機、消息的持久化。
2、做集群,鏡像隊列。
如果想更改這個默認的配置,我們可以在/etc/rabbitmq/目錄下創建一個rabbitmq.config文件,配置資訊可以按照指定的json規則進行指定。如下所示:
[{
rabbit,
[
{
queue_index_embed_msgs_below,
4097
}
]
}].
然後重啟rabbitmq服務(rabbitmqctl stop—-> rabbitmq-server -detached)。
那麼我們是不是把queue_index_embed_msgs_below參數的值調節的越大越好呢?肯定不是的rabbit_queue_index中以順序(文件名從0開始累加)的段文件來進行存儲,後綴為”.idx”,每個段文件中包含固定的SEGMENT_ENTRY_COUNT條記錄,SEGMENT_ENTRY_COUNT默認值為16384。每個rabbit_queue_index從磁碟中讀取消息的時候至少在記憶體中維護一個段文件,所以設置queue_index_embed_msgs_below值的時候需要格外謹慎,一點點增大也可能會引起記憶體爆炸式增長。
相關知識:消息存儲機制
不管是持久化的消息還是非持久化的消息都可以被寫入到磁碟。
1、持久化的消息在到達隊列時就被寫入到磁碟,並且如果可以,持久化的消息也會在記憶體中保存一份備份,這樣可以提高一定的性能,當記憶體吃緊的時候會從記憶體中清除。
2、非持久化的消息一般只保存在記憶體中,在記憶體吃緊的時候會被寫入到磁碟中,以節省記憶體空間。這兩種類型的消息的落盤處理都在RabbitmqMQ的”持久層”中完成。持久層的組成如下所示:
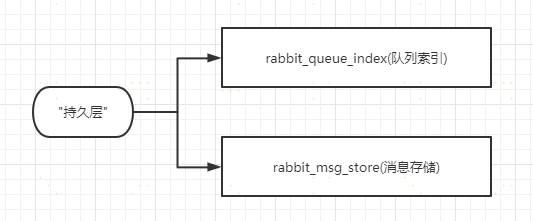
rabbit_queue_index:負責維護隊列中的落盤消息的資訊,包括消息的存儲地點、是否已被交付給消費者、
是否已被消費者ack。每一個隊列都有與之對應的一個rabbitmq_queue_index。
rabbit_msg_store: 負責消息的存儲,它被所有的隊列共享,在每個節點中有且只有一個。
rabbit_msg_store可以在進行細分:
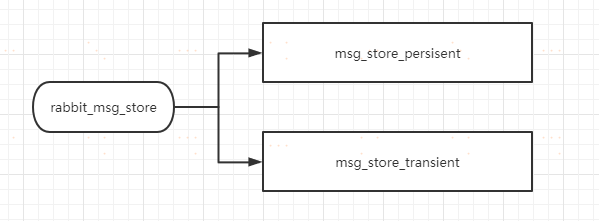
msg_store_persisent :負責持久化消息的持久化,重啟不會丟失
msg_store_transient :負責非持久化消息的持久化,重啟會丟失
消息可以存儲在rabbit_queue_index中也可以存儲在rabbit_msg_store中。最佳的配置是較小的消息存儲在rabbit_queue_index中而較大的消息存儲在rabbit_msg_store中。這個消息的界定可以通過queue_index_embed_msgs_below來配置,默認大小為4096,單位為B。注意這裡的消息大小是指消息體、屬性以及headers整體的大小。當一個消息小於設定的大小閾值時就可以存儲在rabbit_queue_index中,這樣可以得到性能上的優化。這種存儲機制是在Rabbitmq3.5 版本以後引入的,該優化提高了系統性能10%左右。
相關知識: 隊列的結構
Rabbitmq中隊列的是由兩部分組成:rabbit_amqpqueue_process和backing_queue組成:

rabbit_amqpqueue_process: 負責協議相關的消息處理,即接收生產者發布的消息、向消費者交付消息、處理消息的確認(包括生產端的confirm和消費端的ack)等。
backing_queue: 是消息存儲的具體形式和引擎,並向rabbit_amqpqueue_process提供相關的介面以供調用。
如果消息發送的隊列是空的且隊列有消費者,該消息不會經過該隊列而是直接發往消費者,如果無法直接被消費,則需要將消息暫存入隊列,以便重新投遞。
消息在存入隊列後,主要有以下幾種狀態:
alpha:消息內容(包括消息體、屬性和headers)和消息索引都存在記憶體中(消耗記憶體最多,CPU消耗最少)
beta:消息內容保存在磁碟中,消息索引都存在記憶體中(只需要一次IO操作就可以讀取到消息)
gamma:消息內容保存在磁碟中,消息索引在磁碟和記憶體中都存在(只需要一次IO操作就可以讀取到消息)
delta:消息內容和消息索引都在磁碟中(消耗記憶體最小,但是會消耗更多的CPU和磁碟的IO操作)持久化的消息,消息內容和消息索引必須先保存在磁碟中,才會處於上面狀態中的一種,gamma狀態只有持久化的消息才有這種狀態。Rabbitmq在運行時會根據統計的消息傳送速度定期計算一個當前記憶體中能夠保存的最大消息數量(target_ram_count), 如果alpha狀態的消息數量大於此值時,就會引起消息的狀態轉換,多餘的消息可能會轉換到beta狀態、gamma狀態或者delta狀態。區分這4種狀態的主要作用是滿足不同的記憶體和CPU 的需求。
對於普通隊列而言,backing_queue內部的實現是通過5個子隊列來體現消息的狀態的:
Q1:只包含alpha狀態的消息
Q2:包含beta和gamma的消息
Delta:包含delta的消息
Q3:包含beta和gamma的消息
Q4:只包含alpha狀態的消息
一般情況下,消息按照Q1->Q2->Delta->Q3->Q4這樣的順序進行流動,但並不是每一條消息都會經歷所有狀態,這取決於當前系統的負載情況(比如非持久化的消息在記憶體負載不高時,就不會經歷delta)。如此設計的好處:可以在隊列負載很高的情況下,能夠通過將一部分消息由磁碟保存來節省記憶體空間,而在負載降低的時候,這部分消息又漸漸回到記憶體被消費者獲取,使得整個隊列具有良好的彈性。
相關知識: 消費消息時的狀態轉換
消費者消費消息也會引起消息狀態的轉換,狀態轉換的過程如下所示:
-
消費者消費時先從Q4獲取消息,如果獲取成功則返回。
-
如果Q4為空,則從Q3中獲取消息,首先判斷Q3是否為空,如果為空返回隊列為空,即此時隊列中無消
息 -
如果Q3不為空,取出Q3的消息,然後判斷Q3和Delta中的長度,如果都為空,那麼Q2、Delta、Q3、
Q4都為空,直接將Q1中的消息轉移至Q4,下次直接從Q4中讀取消息 -
如果Q3為空,Delta不為空,則將Delta中的消息轉移至Q3中,下次直接從Q3中讀取。
-
在將消息從Delta轉移至Q3的過程中,是按照索引分段讀取,首先讀取某一段,然後判斷讀取的消息個數和Delta消息的個數,如果相等,判定Delta已無消息,直接將讀取Q2和讀取到消息一併放入Q3,如果不相等,僅將此次讀取的消息轉移到Q3。
通常在負載正常時,如果消息被消費的速度不小於接收新消息的速度,對於不需要保證可靠性的消息來說,極有可能只會處於alpha狀態。對於durable屬性設置為true的消息,它一定會進入gamma狀態,並且在開啟publisher confirm機制時,只有到了gamma狀態時才會確認該消息己被接收,若消息消費速度足夠快、記憶體也充足,這些消息也不會繼續走到下一個狀態。
在系統負載較高中,已經收到的消息若不能很快被消費掉,就是這些消息就是在隊列中”堆積”, 那麼此時Rabbitmq就需要花更多的時間和資源處理”堆積”的消息,如此用來處理新流入的消息的能力就會降低,使得流入的消息又被”堆積”繼續增大處理每個消息的平均開銷,繼而情況變得越來越惡化,使得系統的處理能力大大降低。
減少消息堆積的常見解決方案:
1、增加prefetch_count的值,設置消費者存儲未確認的消息的最大值
2、消費者進行multiple ack,降低ack帶來的開銷
相關知識: 惰性隊列
默認情況下,當生產者將消息發送到Rabbitmq的時候,隊列中的消息會儘可能地存儲在記憶體中,這樣可以更快地將消息發送給消費者。即使是持久化的消息,在被寫入磁碟的同時也會在記憶體中駐留一份備份。這樣的機制無形會佔用更多系統資源,畢竟記憶體應該留給更多有需要的地方。如果發送端過快或消費端宕機,導致消息大量積壓,此時消息還是在記憶體和磁碟各存儲一份,在消息大爆發的時候,MQ伺服器會撐不住,影響其他隊列的消息收發,能不能有效的處理這種情況呢。答案 惰性隊列。
RabbitMQ從3.6.0版本開始引入了惰性隊列(Lazy Queue)的概念。惰性隊列會將接收到的消息直接存入文件系統中,而不管是持久化的或者是非持久化的,這樣可以減少了記憶體的消耗,但是會增加I/0的使用,如果消息是持久化的,那麼這樣的I/0操作不可避免,惰性隊列和持久化的消息可謂是”最佳拍檔”。注意如果惰性隊列中存儲的是非持久化的消息,記憶體的使用率會一直很穩定,但是重啟之後消息一樣會丟失。
把一個隊列設置成惰性隊列的方式:
// 聲明隊列
@Bean(name = "direct.queue_03")
public Queue commonQueue03() {
QueueBuilder queueBuilder = QueueBuilder.durable("direct.queue_03");
queueBuilder.lazy(); // 把隊列設置成惰性隊列
return queueBuilder.build();
}
4、確保消息從隊列正確地投遞到消費者
如果消費者收到消息後未來得及處理即發生異常,或者處理過程中發生異常,會導致④失敗。
為了保證消息從隊列可靠地達到消費者,RabbitMQ提供了消息確認機制(message acknowledgement)。消費者在訂閱隊列時,可以指定autoAck參數,當autoAck等於false時,RabbitMQ會等待消費者顯式地回復確認訊號後才從隊列中移去消息。
如果消息消費失敗,也可以調用Basic. Reject或者Basic. Nack來拒絕當前消息而不是確認。如果r equeue參數設置為true,可以把這條消息重新存入隊列,以便發給下一個消費者(當然,只有一個消費者的時候,這種方式可能會出現無限循環重複消費的情況,可以投遞到新的隊列中,或者只列印異常日誌)。
5、補償機制
對於一定時間沒有得到響應的消息,可以設置一個定時重發的機制,但要控制次數,比如最多重發3次,否則會造
成消息堆積。
6、消息冪等性
服務端是沒有這種控制的,只能在消費端控制。
如何避免消息的重複消費?
消息重複可能會有兩個原因:
1、生產者的問題,環節①重複發送消息,比如在開啟了Confirm模式但未收到確認。
2、環節④出了問題,由於消費者未發送ACK或者其他原因,消息重複投遞。
對於重複發送的消息,可以對每一條消息生成一個唯一的業務ID,通過日誌或者建表來做重複控制。
7、消息的順序性
消息的順序性指的是消費者消費的順序跟生產者產生消息的順序是一致的。
在RabbitMQ中,一個隊列有多個消費者時,由於不同的消費者消費消息的速度是不一樣的,順序無法保證。
RabbitMQ如何保證高可用
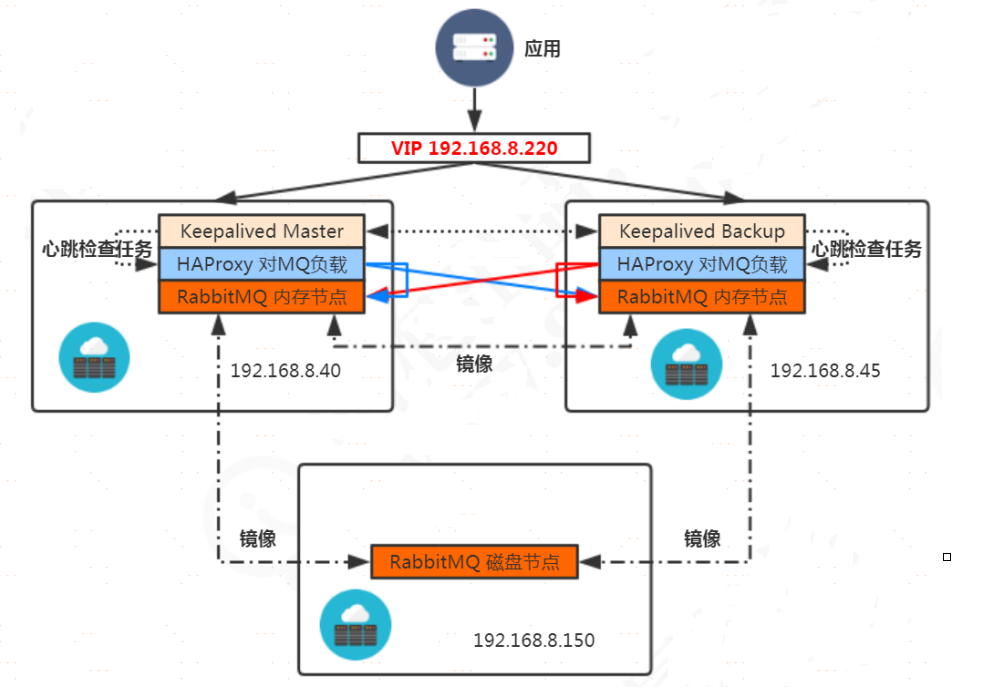
RabbittMQ集群
集群主要用於實現高可用與負載均衡。
RabbitMQ通過/var/lib/r abbitmq/. erlang. cookie來驗證身份,需要在所有節點上保持一致。
集群有兩種節點類型,一種是磁碟節點,一種是記憶體節點。集群中至少需要一個磁碟節點以實現元數據的持久化,
未指定類型的情況下,默認為磁碟節點。
集群通過25672埠兩兩通訊,需要開放防火牆的埠。
需要注意的是,RabbitMQ集群無法搭建在廣域網上,除非使用feder ation或者shovel等插件。
集群的配置步驟:
1、配置hosts
2、同步erlang. cookie
3、加入集群
集群搭建
docker pull rabbitmq:3.6.10-management
docker run -di --network=docker-network --ip=172.19.0.50 --hostname=rabbitmq-node01 --name=rabbitmq_01 -p 15673:15672 -p 5673:5672
--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'
rabbitmq:3.6.10-management /bin/bash
docker run -di --network=docker-network --ip=172.19.0.51 --hostname=rabbitmq-node02 --name=rabbitmq_02 -p 15674:15672 -p 5674:5672
--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'
rabbitmq:3.6.10-management /bin/bash
docker run -di --network=docker-network --ip=172.19.0.52 --hostname=rabbitmq-node03 --name=rabbitmq_03 -p 15675:15672 -p 5675:5672
--privileged=true -e RABBITMQ_ERLANG_COOKIE='rabbitcookie'
rabbitmq:3.6.10-management /bin/bash
參數說明:Erlang Cookie值必須相同,也就是RABBITMQ_ERLANG_COOKIE參數的值必須相同。因為
RabbitMQ是用Erlang實現的,Erlang Cookie相當於不同節點之間相互通訊的秘鑰,Erlang節點通過交換Erlang Cookie獲得認證。
docker exec -itrabbitmq_01 /bin/bash
配置hosts文件,讓各個節點都能互相識別對方的存在。在系統中編輯/etc/hosts文件,添加ip地址和節點名稱的映射資訊(apt-get update , apt-get install vim):
172.19.0.50 rabbitmq-node01
172.19.0.51 rabbitmq-node02
172.19.0.52 rabbitmq-node03
啟動rabbitmq,並且查看狀態
root@014faa4cba72:/# rabbitmq-server -detached # 啟動
rabbitmq服務,該命令可以啟動erlang虛擬機和rabbitmq服務
root@014faa4cba72:/# rabbitmqctl status # 查看節點
資訊
Status of noderabbit@014faa4cba72
[{pid,270},
{running_applications,
[{rabbitmq_management,"RabbitMQ Management Console","3.6.10"},
{rabbitmq_management_agent,"RabbitMQ Management Agent","3.6.10"},
{rabbitmq_web_dispatch,"RabbitMQ Web Dispatcher","3.6.10"},
.............
root@014faa4cba72:/# rabbitmqctl cluster_status # 查看集群
節點狀態
Cluster status of noderabbit@014faa4cba72
[{nodes,[{disc,[rabbit@014faa4cba72]}]},
{running_nodes,[rabbit@014faa4cba72]}, # 正在運行
的只有一個節點
{cluster_name,<<"rabbit@014faa4cba72">>},
{partitions,[]},
{alarms,[{rabbit@014faa4cba72,[]}]}]
注意:此時我們可以通過瀏覽器訪問rabbitmq的後端管理系統,但是rabbitmq默認提供的guest用戶不支援遠程訪問。因此我們需要創建用戶,並且對其進行授權
root@014faa4cba72:/# rabbitmqctl add_user admin admin # 添加用戶,用戶名
為admin,密碼為admin
root@014faa4cba72:/# rabbitmqctl list_users # 查看rabbitmq的
用戶列表
Listing users
admin [] # admin用戶已經添
加成功,但是沒有角色
guest [administrator]
root@014faa4cba72:/# rabbitmqctl set_user_tags admin administrator #
給admin用戶設置管理員許可權
# rabbitmqctl delete_user admin # 刪除admin用戶
# rabbitmqctl stop_app # 停止rabbitmq服務
# rabbitmqctl stop # 會將rabbitmq的服務和erlang虛擬機一同關閉
再次使用admin用戶就可以登錄web管理系統了。在其他的rabbitmq中也創建用戶,以便後期可以訪問後端管理系統。
配置集群
1、同步cookie
集群中的Rabbitmq節點需要通過交換密鑰令牌以獲得相互認證,如果節點的密鑰令牌不一致,那麼在配置節點時就會報錯。
獲取某一個節點上的/var/lib/rabbitmq/.erlang.cookie文件,然後將其複製到其他的節點上。我們以node01節點為基準,進行此操作。
docker cprabbitmq_01:/var/lib/rabbitmq/.erlang.cookie .
docker cp.erlang.cookie rabbitmq_02:/var/lib/rabbitmq
docker cp.erlang.cookie rabbitmq_03:/var/lib/rabbitmq
2、建立集群關係
目前3個節點都是獨立的運行,之間並沒有任何的關聯關係。接下來我們就來建立3者之間的關聯關係,我們以rabbitmq-node01為基準,將其他的兩個節點加入進來。
把rabbitmq-node02加入到節點1中
# 進入到rabbitmq-node02中
rabbitmqctl stop_app # 關閉rabbitmq服務
rabbitmqctl reset # 進行重置
rabbitmqctl join_cluster rabbit@rabbitmq-node01 # rabbitmq-node01為
節點1的主機名稱
rabbitmqctl start_app # 啟動rabbitmq節點
把rabbitmq-node03加入到節點1中
# 進入到rabbitmq-node03中
rabbitmqctl stop_app # 關閉rabbitmq服務
rabbitmqctl reset # 清空節點的狀態,並將其恢復都空白狀態,當設置的節點時集群
中的一部分,該命令也會和集群中的磁碟節點進行通訊,告訴他們該節點正在離開集群。不然集群
會認為該節點處理故障,並期望其最終能夠恢復過來
rabbitmqctl join_cluster rabbit@rabbitmq-node01 # rabbitmq-node01為
節點1的主機名稱
rabbitmqctl start_app # 啟動rabbitmq節點
進入後台管理系統查看集群概述。
節點類型
節點類型介紹
在使用rabbitmqctl cluster_status命令來查看集群狀態時會有[{nodes,[{disc[‘rabbit@rabbitmqnode01′,’rabbit@rabbitmq-node02′,’rabbit@rabbitmq-node03’]}這一項資訊,其中的disc標註了Rabbitmq節點類型。Rabbitmq中的每一個節點,不管是單一節點系統或者是集群中的一部分要麼是記憶體節點,要麼是磁碟節點。記憶體節點將所有的隊列,交換機,綁定關係、用戶、許可權和vhost的元數據定義都存儲在記憶體中,而磁碟節點則將這些資訊存儲到磁碟中。單節點的集群中必然只有磁碟類型的節點,否則當重啟Rabbitmq之後,所有關於系統配置資訊都會丟失。不過在集群中,可以選擇配置部分節點為記憶體節點,這樣可以獲得更高的性能。
節點類型變更
如果我們沒有指定節點類型,那麼默認就是磁碟節點。我們在添加節點的時候,可以使用如下的命令來指定節點的類型為記憶體節點:
rabbitmqctl join_cluster rabbit@rabbitmq-node01 --ram
我們也可以使用如下的命令將某一個磁碟節點設置為記憶體節點:
rabbitmqctl change_cluster_node_type {disc , ram}
如下所示
root@rabbitmq-node02:/# rabbitmqctl stop_app
# 關閉rabbitmq服務
Stopping rabbit application on node 'rabbit@rabbitmq-node02'
root@rabbitmq-node02:/# rabbitmqctl change_cluster_node_type ram
# 將root@rabbitmq-node02節點類型切換為記憶體節點
Turning 'rabbit@rabbitmq-node02'into a ram node
root@rabbitmq-node02:/# rabbitmqctl start_app
# 啟動rabbitmq服務
Starting node 'rabbit@rabbitmq-node02'
root@rabbitmq-node02:/# rabbitmqctl cluster_status
# 查看集群狀態
Cluster status of node 'rabbit@rabbitmq-node02'
[{nodes,[{disc,['rabbit@rabbitmq-node03','rabbit@rabbitmq-node01']},
{ram,['rabbit@rabbitmq-node02']}]},
{running_nodes,['rabbit@rabbitmq-node01','rabbit@rabbitmq-node03',
'rabbit@rabbitmq-node02']},
{cluster_name,<<"rabbit@rabbitmq-node01">>},
{partitions,[]},
{alarms,[{'rabbit@rabbitmq-node01',[]},
{'rabbit@rabbitmq-node03',[]},
{'rabbit@rabbitmq-node02',[]}]}]
root@rabbitmq-node02:/#
節點選擇
Rabbitmq只要求在集群中至少有一個磁碟節點,其他所有的節點可以是記憶體節點。當節點加入或者離開集群時,它們必須將變更通知到至少一個磁碟節點。如果只有一個磁碟節點,而且不湊巧它剛好崩潰了,那麼集群可以繼續接收和發送消息。
但是不能執行創建隊列,交換機,綁定關係、用戶已經更改許可權、添加和刪除集群節點操作了。也就是說、如果集群中唯一的磁碟節點崩潰了,集群仍然可以保持運行,但是知道將該節點恢復到集群前,你無法更改任何東西,所以在創建集群的時候應該保證至少有兩個或者多個磁碟節點。
當記憶體節點重啟後,它會連接到預先配置的磁碟節點,下載當前集群元數據的副本。當在集群中添加記憶體節點的時候,確保告知所有的磁碟節點(記憶體節點唯一存儲到磁碟中的元數據資訊是磁碟節點的地址)。只要記憶體節點可以找到集群中至少一個磁碟節點,那麼它就能在重啟後重新加入集群中。
集群優化:HAproxy負載+Keepalived高可用
之前搭建的集群存在的問題:不具有負載均衡能力
本次我們所選擇的負載均衡層的軟體是HAProxy。為了保證負載均衡層的高可用,我們需要使用使用到keepalived軟體,使用vrrp協議產生虛擬ip實現動態的ip飄逸。
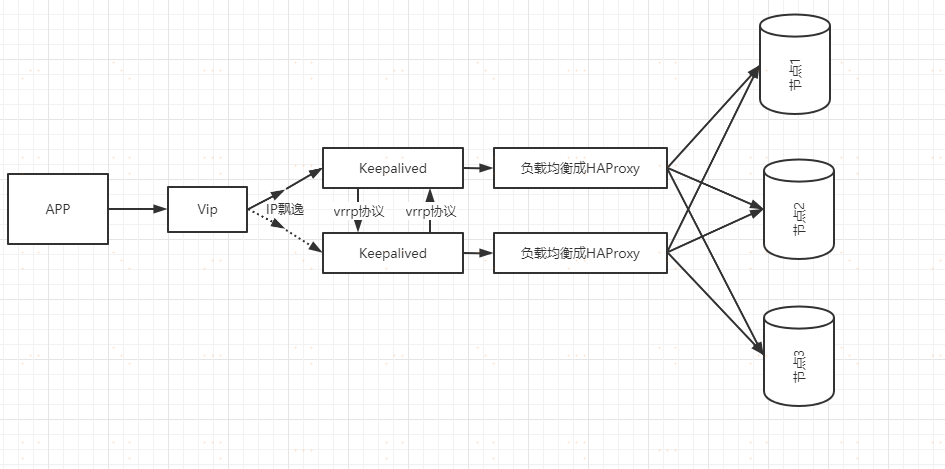
keepalived是以VRRP協議為實現基礎的,VRRP全稱Virtual Router Redundancy Protocol,即虛擬路由冗餘協議。虛擬路由冗餘協議,可以認為是實現路由器高可用的協議,即將N台提供相同功能的路由器組成一個路由器組,這個組裡面有一個master和多個backup,master上面有一個對外提供服務的vip(該路由器所在區域網內其他機器的默認路由為該vip),master會定義向backup發送vrrp協議數據包,當backup收不到vrrp包時就認為master宕掉了,這時就需要根據VRRP的優先順序來選舉一個backup當master。這樣的話就可以保證路由器的高可用了。
優化實現
在兩個記憶體節點上安裝HAProxy
yum install haproxy
編輯配置文件
vim /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option dontlognull
option redispatch
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
maxconn 3000
listen http_front
mode http
bind 0.0.0.0:1080 #監聽埠
stats refresh 30s #統計頁面自動刷新時間
stats uri /haproxy?stats #統計頁面url
stats realm Haproxy Manager #統計頁面密碼框上提示文本
stats auth admin:123456 #統計頁面用戶名和密碼設置
listen rabbitmq_admin
bind 0.0.0.0:15673
server node1 192.168.8.40:15672
server node2 192.168.8.45:15672
listen rabbitmq_cluster 0.0.0.0:5673
mode tcp
balance roundrobin
timeout client 3h
timeout server 3h
timeout connect 3h
server node1 192.168.8.40:5672 check inter 5s rise 2 fall 3
server node2 192.168.8.45:5672 check inter 5s rise 2 fall 3
啟動HAproxy
haproxy -f /etc/haproxy/haproxy.cfg
安裝keepalived
yum -y install keepalived
修改配置文件
vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict # 注釋掉,不然訪問不到VIP
vrrp_garp_interval 0
vrrp_gna_interval 0
}
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
# vrrp_strict # 注釋掉,不然訪問不到VIP
vrrp_garp_interval 0
vrrp_gna_interval 0
}
# 檢測任務
vrrp_script check_haproxy {
# 檢測HAProxy監本
script "/etc/keepalived/script/check_haproxy.sh"
# 每隔兩秒檢測
interval 2
# 權重
weight 2
}
# 虛擬組
vrrp_instance haproxy {
state MASTER # 此處為`主`,備機是 `BACKUP`
interface ens33 # 物理網卡,根據情況而定
mcast_src_ip 192.168.8.40 # 當前主機ip
virtual_router_id 51 # 虛擬路由id,同一個組內需要相同
priority 100 # 主機的優先權要比備機高
advert_int 1 # 心跳檢查頻率,單位:秒
authentication { # 認證,組內的要相同
auth_type PASS
auth_pass 1111
}
# 調用腳本
track_script {
check_haproxy
}
# 虛擬ip,多個換行
virtual_ipaddress {
192.168.8.201
}
}
啟動
keepalived -D
RabbitMQ鏡像隊列
1、為什麼要存在鏡像隊列
為了保證隊列和消息的高可用
2、什麼是鏡像隊列,鏡像隊列是如何進行選取主節點的?
引入鏡像隊列的機制,可以將隊列鏡像到集群中的其他的Broker節點之上,如果集群中的一個節點失效了,隊列能自動的切換到鏡像中的另一個節點之上以保證服務的可用性。在通常的用法中,針對每一個配置鏡像的隊列(一下稱之為鏡像隊列)都包含一個主節點(master)和若干個從節點(slave),如下圖所示:
集群方式下,隊列和消息是無法在節點之間同步的,因此需要使用RabbitMQ的鏡像隊列機制進行同步。
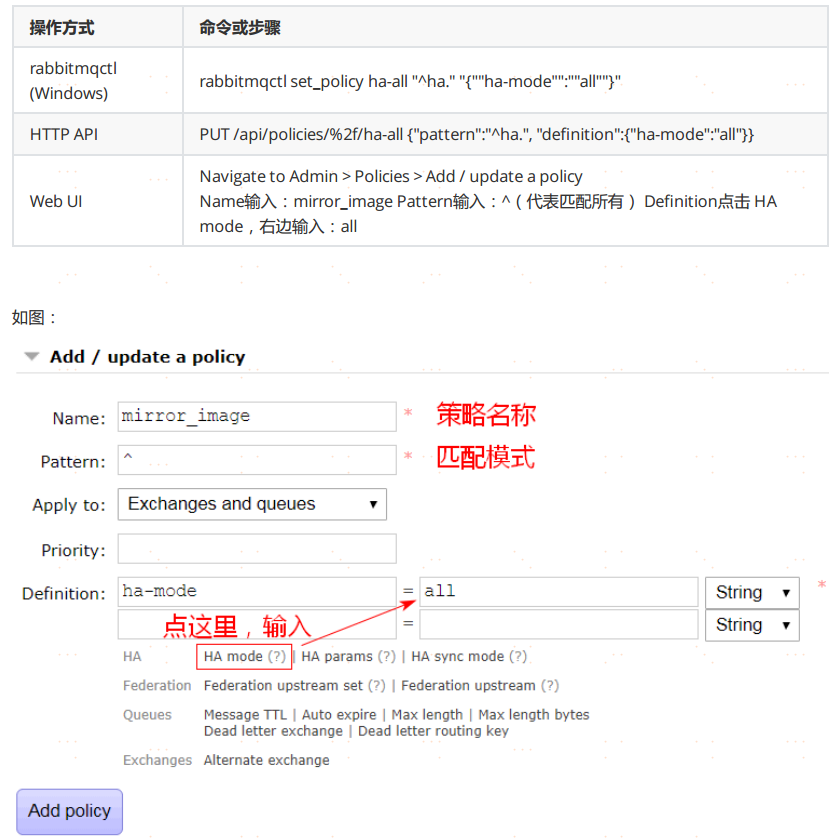
深入了解參考文章://blog.csdn.net/u013256816/article/details/71097186
RabbitMQ的應用
筆者就職於電商公司,就以電商秒殺場景為背景,闡述下RabbitMQ的實踐。
場景:訂單未支付庫存回退
當用戶秒殺成功以後,就需要引導用戶去訂單頁面進行支付。如果用戶在規定的時間之內(30分鐘),沒有完成訂單的支付,此時我們就需要進行庫存的回退操作。
架構圖
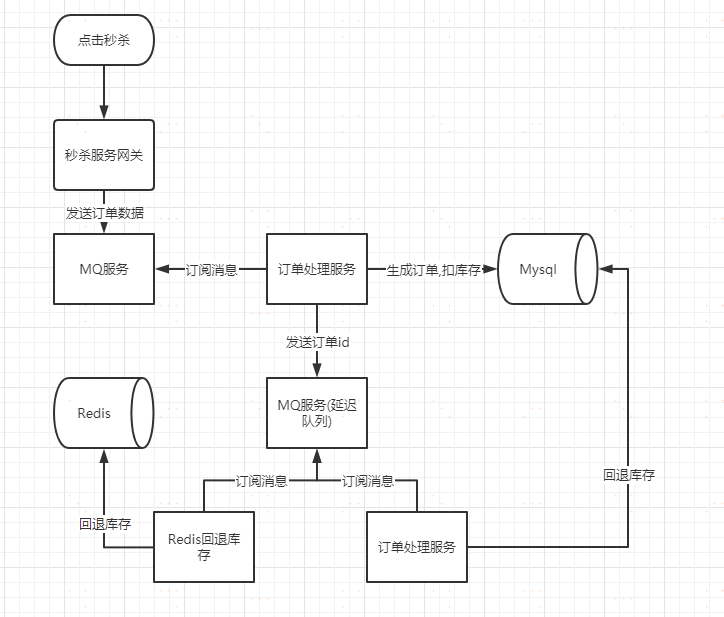
具體實現就是使用的死信隊列,可以參考上面的程式碼。
場景:RabbitMQ秒殺公平性保證
消息的可靠性傳輸可以保證秒殺業務的公平性。關於秒殺業務的公平性,我們還需要考慮一點:消息的順序性(先進入隊列的消息先進行處理)
RabbitMQ消息順序性說明
順序性:消息的順序性是指消費者消費到的消息和發送者發布的消息的順序是一致的。
舉個例子,不考慮消息重複的情況,如果生產者發布的消息分別為msgl、msg2、msg3,那麼消費者必然也是按照msgl、msg2、msg3的順序進行消費的。
目前很多資料顯示RabbitMQ的消息能夠保障順序性,這是不正確的,或者說這個觀點有很大的局限性。在不使用任何RabbitMQ的高級特性,也沒有消息丟失、網路故障之類異常的情況發生,並且只有一個消費者的情況下,也只有一個生產者的情況下可以保證消息的順序性。如果有多個生產者同時發送消息,無法確定消息到達Broker 的前後順序,也就無法驗證消息的順序性,因為每一次消息的發送都是在各自的執行緒中進行的。
RabbitMQ消息順序錯亂演示
生產者發送消息:
1、不使用生產者確認機制,單生產者單消費者可以保證消息的順序性
2、使用了生產者確認機制,那麼就無法保證消息到達Broker的前後順序,因為消息的發送是非同步發送的,每一個執行緒的執行時間不同
3、生產端使用事務機制,保證消息的順序性
消費端消費消息:
1、單消費者可以保證消息的順序性
2、多消費者不能保證消息的順序,因為每一個消息的消費都是在各自的執行緒中進行,每一個執行緒的執行時間不同
RabbitMQ消息順序性保障
生產端啟用事務機制,單生產者單消費者。如果我們不考慮消息到達MQ的順序,只是考慮對已經到達到MQ中的消息順序消費,那麼需要保證消費者是單消費者即可。
場景:RabbitMQ秒殺不超賣保證
要保證秒殺不超賣,我們需要在很多的環節進行考慮。比如:在進行預扣庫存的時候,我們需要考慮不能超賣,在進行資料庫真實庫存扣減的時候也需要考慮不能超賣。而對我們的mq這個環節而言,要保證不超賣我們只需要保證消息不被重複消費。
首先我們可以確認的是,觸發消息重複執行的條件會是很苛刻的! 也就說 在大多數場景下不會觸發該條件!!! 一般出在任務超時,或者沒有及時返回狀態,引起任務重新入隊列,由於服務端沒有收到消費端的ack應答,因此該條消息還會重新進行投遞。
冪等性保障方案
重複消費不可怕,可怕的是你沒考慮到重複消費之後,怎麼保證冪等性。
所謂冪等性,就是對介面的多次調用所產生的結果和調用一次是一致的。通俗點說,就一個數據,或者一個請求,給你重複來多次,你得確保對應的數據是不會改變的,不能出錯。
舉個例子:
假設你有個系統,消費一條消息就往資料庫里插入一條數據,要是你一個消息重複消費兩次,你不就插入了兩條,這數據不就錯了?但是你要是消費到第二次的時候,自己判斷一下是否已經消費過了,若是就直接扔了,這樣不就保留了一條數據,從而保證了數據的正確性。一條數據重複消費兩次,資料庫里就只有一條數據,這就保證了系統的冪等性。
怎麼保證消息隊列消費的冪等性?這一點需要結合的實際的業務來進行處理:
1、比如我們消費的數據需要寫資料庫,你先根據主鍵查一下,如果這數據都有了,你就別插入了,執行以下update操作
2、比如我們消費的數據需要寫Redis,那沒問題了,反正每次都是set,天然冪等性。
3、比如你不是上面兩個場景,那做的稍微複雜一點,你需要讓生產者發送每條數據的時候,裡面加一個全局唯一的id,類似訂單id 之類的東西,然後你這裡消費到了之後,先根據這個id 去比如Redis 里查一下,之前消費過嗎?如果沒有消費過,你就處理,然後這個id 寫Redis。如果消費過了,那你就別處理了,保證別重複處理相同的消息即可。
4、比如基於資料庫的唯一鍵來保證重複數據不會重複插入多條。因為有唯一鍵約束了,重複數據插入只會報錯,不會導致資料庫中出現臟數據。
面試題
1、消息隊列的作用與使用場景?
2、創建隊列和交換機的方法?
3、多個消費者監聽一個生產者時,消息如何分發?
4、無法被路由的消息,去了哪裡?
5、消息在什麼時候會變成Dead Letter(死信)?
6、RabbitMQ如何實現延遲隊列?
7、如何保證消息的可靠性投遞?
8、如何在服務端和消費端做限流?
9、如何保證消息的順序性?
10、RabbitMQ的節點類型?


