kafka rebalance解決方案 -incremental cooperative協議和static membership功能
apache kafka的重平衡(rebalance),一直以來都為人詬病。因為重平衡過程會觸發stop-the-world(STW),此時對應topic的資源都會處於不可用的狀態。小規模的集群還好,如果是大規模的集群,比如幾百個節點的consumer或kafka connect等,那麼重平衡就是一場災難。所以我們要儘可能避免重平衡,在之前的文章中也有介紹過這點,有關重平衡的基礎內容可以參閱:
在kafka2.4的時候,社區推出兩個新feature來解決重平衡過程中STW的問題。
- Incremental Rebalance Protocol(以下簡稱cooperative協議):改進了eager協議(即舊重平衡協議)的問題,避免STW的發生,具體怎麼避免,後面介紹
- static membership:避免重起或暫時離開的消費者觸發重平衡
本篇接下來主要介紹這兩點,另外注意,這兩個功能都是kafka2.4推出的,如果想嘗鮮建議升級到kafka2.4,升級方案參見官網:Upgrading to 2.4.0 from any version 0.8.x through 2.3.x。
apache kafak2.4 incremental cooperative rebalancing協議
背景
負載均衡,基本是分散式系統中必不可少一個功能,apache kafka也不例外。為了讓消費數據這個過程在kafka集群中儘可能地均衡,kafka推出了重平衡的功能,重平衡能夠幫助kafka客戶端(consumer client,kafka connect,kafka stream)儘可能實現負載均衡。
但是在kafka2.3之前,重平衡各種分配策略基本都是基於eager協議的(包括RangeAssignor,RoundRobinAssignor等,這部分內容最前面給出的文章有介紹),也就是我們以前熟知的kafka重平衡。eager協議重平衡的細節,推薦看極客時間胡夕大佬的文章,講得很詳細,具體的鏈接就不放了,也可以直接搜kafak重平衡流程解析。
值得一提的是,此前kafka就有推出一個重平衡的新分配策略,StickyAssignor粘性分配策略,主要作用是保證客戶端,比如consumer消費者在重平衡後能夠維持原本的分配方案,可惜的是這個分配策略依舊是在eager協議的框架之下,重平衡仍然需要每個consumer都先放棄當前持有的資源(分區)。
在2.x的時候,社區就意識到需要對現有的rebalance作出改變。所以在kafka2.3版本首先在kafka connect應用cooperative協議,然後在kafka2.4的時候也在consumer client添加了該協議的支援。
incremental cooperative rebalancing協議解析
接下來我們介紹cooperative協議和eager協議的具體區別。一句話介紹,cooperative協議將一次全局重平衡,改成每次小規模重平衡,直至最終收斂平衡的過程。
這裡我們主要針對一種場景舉個例子,來對比兩種協議的區別。
假設有這樣一種場景,一個topic有三個分區,分別是p1,p2,p3。有兩個消費者c1,c2在消費這三個分區,{c1 -> p1, p2},{c2 -> p3}。
當然這樣說不平衡的,所以加入一個消費者c3,此時觸發重平衡。我們先列出在eager協議的框架下會執行的大致步驟,然後再列出cooperative發生的步驟,以做比對。
eager 協議版本
先說下各個名詞:
- group coordinator:重平衡協調器,負責處理重平衡生命周期中的各種事件
- hearbeat:consumer和broker的心跳,重平衡時會通過這個心跳通知資訊
- join group request:consumer客戶端加入組的請求
- sync group request:重平衡後期,group coordinator向consumer客戶端發送的分配方案
如果在 eager 版本中,會發生如下事情。
- 最開始的時候,c1 c2 各自發送hearbeat心跳資訊給到group coordinator(負責重平衡的協調器)
- 這時候group coordinator收到一個join group的request請求,group coordinator知道有新成員加入組了
- 在下一個心跳中group coordinator 通知 c1 和 c2 ,準備rebalance
- c1 和 c2 放棄(revoke)各自的partition,然後發送joingroup的request給group coordinator
- group coordinator處理好分配方案(交給leader consumer分配的),發送sync group request給 c1 c2 c3,附帶新的分配方案
- c1 c2 c3接收到分配方案後,重新開始消費
用一張圖表示如下:
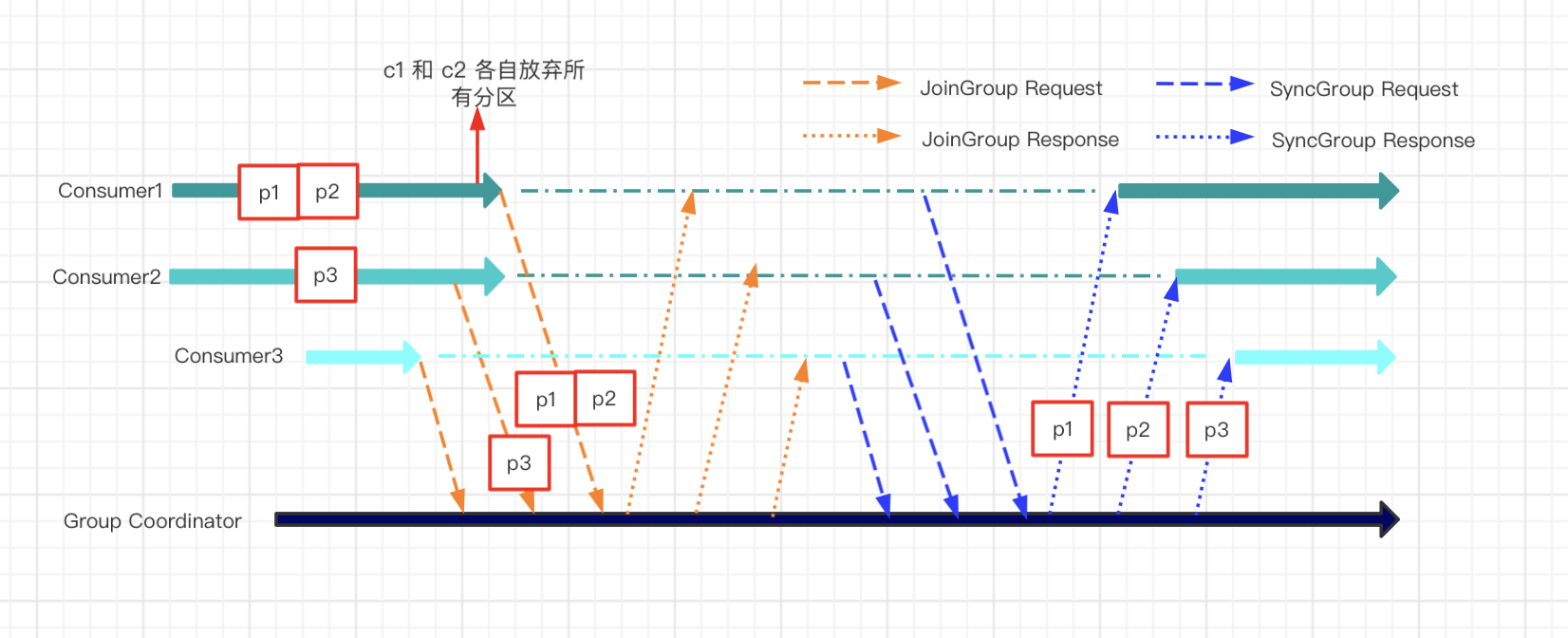
這裡省略了一些細節,不過整體上應該會更方便理解這個過程。接下來再看看cooperative協議會怎麼處理。
到了cooperative協議就會變成這樣:
cooperative rebalancing protocol 版本
如果在cooperative版本中,會發生如下事情。
- 最開始的時候c1 c2各自發送hearbeat心跳資訊給到group coordinator
- 這時候group coordinator收到一個join group的request請求,group coordinator知道有新成員加入組了
- 在下一個心跳中 group coordinator 通知 c1 和 c2 ,準備 rebalance,前面幾部分是一樣的
- c1 和 c2發送joingroup的request給group coordinator,但不需要revoke其所擁有的partition,而是將其擁有的分區編碼後一併發送給group coordinator,即 {c1->p1, p2},{c2->p3}
- group coordinator 從元數據中獲取當前的分區資訊(這個稱為assigned-partitions),再從c1 c2 的joingroup request中獲取分配的分區(這個稱為 owned-partitions),通過assigned-partitions和owned-partitions知曉當前分配情況,決定取消c1一個分區p2的消費權,然後發送sync group request({c1->p1},{c2->p3})給c1 c2,讓它們繼續消費p1 p2
- c1 c2 接收到分配方案後,重新開始消費,一次 rebalance 完成,當然這時候p2處於無人消費狀態
- 再次觸發rebalance,重複上述流程,不過這次的目的是把p2分配給c3(通過assigned-partitions和owned-partitions獲取分區分配狀態)
同樣用一張圖表示如下:
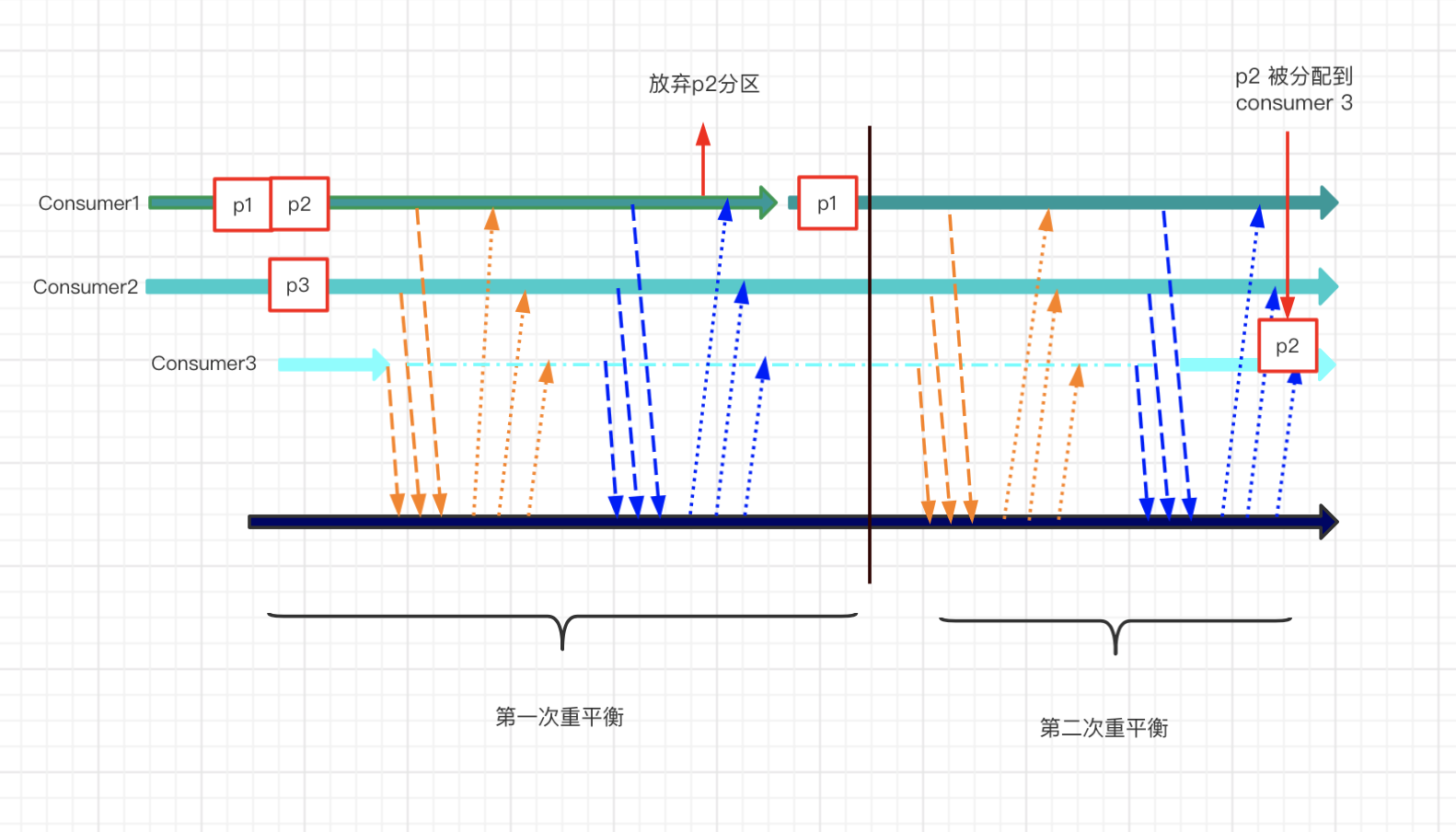
cooperative協議版重平衡的一個核心,是assigned-partitions和owned-partitions,group coordinator通過這兩者,可以保存和獲取分區的消費狀態,以便進行多次重平衡並達到最終的均衡狀態。
除了消費者崩潰離場的場景,其他場景也是類似的思路。具體重平衡演算法相對比較複雜,這裡留給感興趣的同學自行探索:KIP-429: Kafka Consumer Incremental Rebalance Protocol。
apache kafka2.4 static membership功能
我們知道,當前重平衡發生的條件有三個:
- 成員數量發生變化,即有新成員加入或現有成員離組(包括主動離組和崩潰被動離組)
- 訂閱主題數量發生變化
- 訂閱主題分區數量發生變化
其中成員加入或成員離組是最常見的觸發重平衡的情況。新成員加入這個場景必然發生重平衡,沒辦法優化(針對初始化多個消費者的情況有其他優化,即延遲進行重平衡),但消費者崩潰離組卻可以優化。因為一個消費者崩潰離組通常不會影響到其他{partition – consumer}的分配情況。
因此在 kafka 2.3~2.4 推出一項優化,即此次介紹的Static Membership功能和一個consumer端的配置參數 group.instance.id。一旦配置了該參數,成員將自動成為靜態成員,否則的話和以前一樣依然被視為是動態成員。
靜態成員的好處在於,其靜態成員ID值是不變的,因此之前分配給該成員的所有分區也是不變的。即假設一個成員掛掉,在沒有超時前靜態成員重啟回來是不會觸發 Rebalance 的(超時時間為session.timeout.ms,默認10 sec)。在靜態成員掛掉這段時間,broker會一直為該消費者保存狀態(offset),直到超時或靜態成員重新連接。
如果使用了 static membership 功能後,觸發 rebalance 的條件如下:
- 新成員加入組:這個條件依然不變。當有新成員加入時肯定會觸發 Rebalance 重新分配分區
- Leader 成員重新加入組:比如主題分配方案發生變更
- 現有成員離組時間超過了
session.timeout.ms超時時間:即使它是靜態成員,Coordinator 也不會無限期地等待它。一旦超過了 session 超時時間依然會觸發 Rebalance - Coordinator 接收到 LeaveGroup 請求:成員主動通知 Coordinator 永久離組。
所以使用static membership的兩個條件是:
- consumer客戶端添加配置:props.put(“group.instance.id”, “con1”);
- 設置
session.timeout.ms為一個合理的時間,這個參數受限於group.min.session.timeout.ms(6 sec)和group.max.session.timeout.ms(30 min),即大小不能超過這個上下限。但是調的過大也可能造成broker不斷等待掛掉的消費者客戶端的情況,個人建議根據使用場景,設置合理的參數。
以上~
參考:
Apache Kafka Rebalance Protocol, or the magic behind your streams applications
Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
From Eager to Smarter in Apache Kafka Consumer Rebalances
KIP-429: Kafka Consumer Incremental Rebalance Protocol
Incremental Cooperative Rebalancing: Support and Policies
KIP-345: Introduce static membership protocol to reduce consumer rebalances


