關於c語言單項鏈表尾添加
- 2020 年 12 月 21 日
- 筆記
猶豫了幾天,看了很多大牛寫的關於c語言鏈表,感觸很多,終於下定決心,把自己對於鏈表的理解隨之附上,可用與否,自行裁奪。由於作者水平有限也是第一次寫,不足之處,竭誠希望得到各位大神的批評指正。製作不易,不喜勿噴,謝謝!!!
在正文開始之前,我先對數組和鏈表進行簡單的對比分析。
鏈表也是一種很常見的數據結構,不同於數組的是它是動態進行存儲分配的一種結構。數組存放數據時,必須要事先知道元素的個數。舉個例子,比如一個班有40個人,另一個班有100個人,如果要用同一個數組先後來存放這兩個班的學生數據,那麼必須得定義長度為100的數組。如果事先不確定一個班的人數,只能把數組定義的足夠大,以能存放任何班級的學生數據。這樣就很浪費記憶體,而且數組對於記憶體的要求必須是是連續的,數據小的話還好說,數據大的話記憶體分配就會失敗,數組定義當然也就失敗。還有數組對於插入以及刪除元素的效率也很低這就不一一介紹了。然而鏈表就相對於比較完美,它很好的解決了數組存在的那些問題。它儲存數據時就不需要分配連續的空間,對於元素的插入以及刪除效率就很高。可以說鏈表對於記憶體就是隨用隨拿,不像數組要事先申請。當然,有優點就必然有缺點,就比如說鏈表裡每一個元素裡面都多包含一個地址,或者說多包含一個存放地址的指針變數,所以記憶體開銷就很大。還有因為鏈表的記憶體空間不是連續的,所以想找到其中的某一個數據就沒有數組那麼方便,必須先得到該元素的上一個元素,根據上一個元素提供的下一元素地址去找到該元素。所以不提供「頭指針」(下文中「頭指針」為「PHead」),那麼整個鏈表將無法訪問。鏈表就相當於一條鐵鏈一環扣一環(這個稍後會詳細的說)。
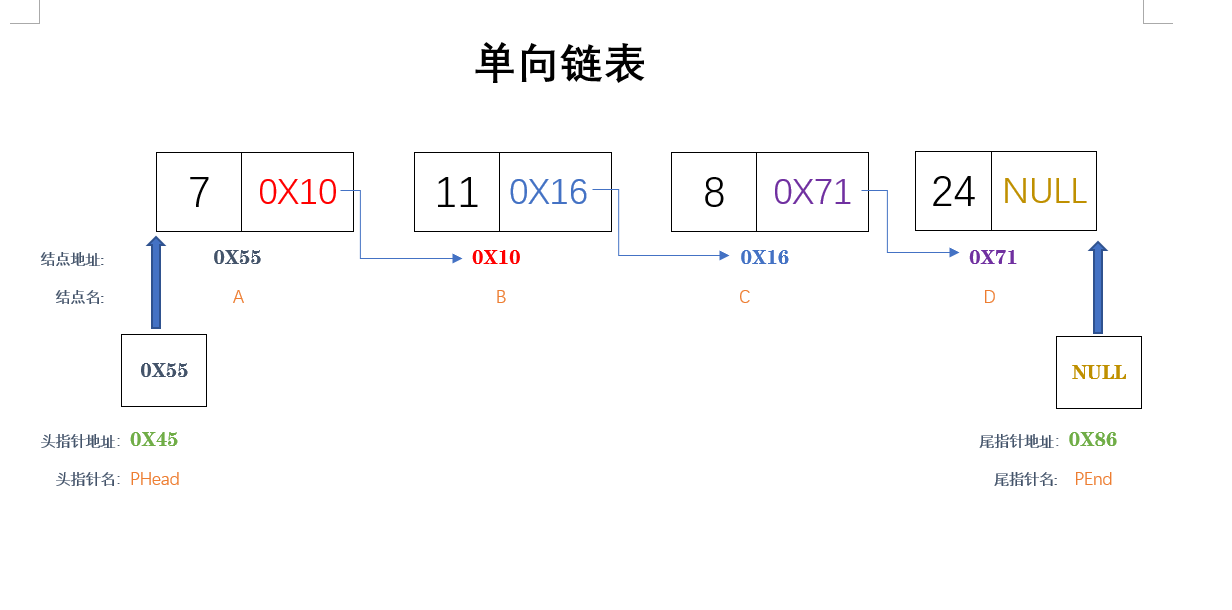
鏈表
上面我提到過鏈表是動態進行存儲分配的一種結構。鏈表中的每一個元素稱為「結點」,每個結點都包括兩部分:一部分為用戶需要的實際數據,另一部分為下一結點的地址。鏈表有一個「頭指針(PHead)」變數,存放著一個地址,該地址指向第一個結點,第一個結點裡面存放著第二個結點的地址,第二個結點又存放著第三個結點地址。就這樣頭指針指向第一個結點,第一個結點又指向第二個……直到最後一個結點。最後一個結點不再指向其他結點,地址部分存放一個「NULL」。 見下圖:(表中有一個尾指針(PEnd)其作用後面會解釋)
c語言單項鏈表尾添加整體程式碼如下:(詳解附後)
#include <stdio.h> #include <stdlib.h> #include <malloc.h> //函數聲明 //尾添加 void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int shu_ju); //尾添加(沒有尾指針) void wei_tian_jia_(struct NODE** PHEAD, int shu_ju); //釋放鏈表 void shi_fang_lian_biao(struct NODE* PHEAD); //釋放鏈表(並是頭指針(PHead)尾指針(PEnd)指向空) void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd); //輸出鏈表 void shu_chu(struct NODE* PHEAD); //定義一個鏈表結構體 struct NODE { int shu_ju; //用戶需要的實際數據 struct NODE* PNext; //下一結點的地址 }; int main(void) { //創建頭尾指針 struct NODE* PHead = NULL; struct NODE* PEnd = NULL; //尾添加 wei_tian_jia(&PHead, &PEnd, 17); wei_tian_jia(&PHead, &PEnd, 21); wei_tian_jia(&PHead, &PEnd, 34); wei_tian_jia(&PHead, &PEnd, 8); wei_tian_jia(&PHead, &PEnd, 24); //尾添加(沒有尾指針) //wei_tian_jia_(&PHead, 23); //wei_tian_jia_(&PHead, 17); //wei_tian_jia_(&PHead, 11); //輸出鏈表 shu_chu(PHead); //釋放鏈表 //shi_fang_lian_biao(PHead); //釋放鏈表(並是頭指針(PHead)尾指針(PEnd)指向空) shi_fang_lian_biao_free(&PHead, &PEnd); system("pause"); return 0; }
//尾添加 void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU) { //創建結點 struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL) { //節點賦值 PTEMP->shu_ju = SHU_JU; PTEMP->PNext = NULL; //把結點連起來 if (NULL == *PHEAD) // 因為PHEAD如果是NULL的話 PEND也就是NULL 所以條件裡面不必要寫 { *PHEAD = PTEMP; *PEND = PTEMP; } else { (*PEND)->PNext = PTEMP; *PEND = PTEMP; } } } //尾添加(沒有尾指針) void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU) { //創建結點 struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL) { //結點成員賦值 PTEMP->shu_ju = SHU_JU; PTEMP->PNext = NULL; //把結點連一起 if (NULL == *PHEAD1) { *PHEAD1 = PTEMP; } else { struct NODE* PTEMP2 = *PHEAD1; while (PTEMP2->PNext != NULL) { PTEMP2 = PTEMP2->PNext; } PTEMP2->PNext = PTEMP; } } } //輸出鏈表 void shu_chu(struct NODE* PHEAD) { while (PHEAD != NULL) { printf("%d\n", PHEAD->shu_ju); PHEAD = PHEAD->PNext; } } //釋放鏈表 void shi_fang_lian_biao(struct NODE* PHEAD) { struct NODE* P = PHEAD; while (PHEAD != NULL) { struct NODE* PTEMP = P; P = P->PNext; free(PTEMP); } free(PHEAD); } //釋放鏈表(並是頭指針(PHead)尾指針(PEnd)指向空) void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd) { while (*PHEAD != NULL) { struct NODE* PTEMP = *PHEAD; *PHEAD = (*PHEAD)->PNext; free(PTEMP); } *PHEAD = NULL; *PHEAD = NULL; }
部分程式碼詳解:
(再次申明:由於作者水平有限,所以有的變數名用的拼音。見笑,莫怪!!!為了簡單明了,方便起見,我定義了一個實際數據。)

「頭指針」(PHead)以及「尾指針」(PEnd):

頭指針很好理解指向首結點用於遍歷整個數組,而尾指針呢?我們先看下面兩段程式碼一段是有尾指針的一段是沒有尾指針的:
顯然這是一段有尾指針的程式碼。這裡的思想就是當寫入第一個成員進鏈表的時候,此時鏈表就一個成員,即是頭(PHEAD),也是尾(PEND),當寫入第二個成員的時候,鏈表頭(PHEALD)不動鏈表尾(PEND)向後移,指向最後一個結點。
//尾添加 void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU) { //創建一個結點 struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL) { //節點成員賦值(一定要每個成員都要賦值) PTEMP->shu_ju = SHU_JU; PTEMP->PNext = NULL; //把結點連起來 if (NULL == *PHEAD) // 因為PHEAD如果是NULL的話 PEND也就是NULL 所以條件裡面不必要寫 { *PHEAD = PTEMP; *PEND = PTEMP; } else { //把尾指針向後移 (*PEND)->PNext = PTEMP; *PEND = PTEMP; } } }
那麼下面這段程式碼是沒有尾指針的。它的思想就是頭指針一直指向第一個結點,然後通過遍歷來找到最後一個結點,從而使最後一個結點裡面的指針指向所要插入的元素。
//尾添加(沒有尾指針) void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU) { //創建結點 struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE)); if (PTEMP != NULL) { //結點成員賦值 PTEMP->shu_ju = SHU_JU; PTEMP->PNext = NULL; //把結點連一起 if (NULL == *PHEAD1) { *PHEAD1 = PTEMP; } else { struct NODE* PTEMP2 = *PHEAD1; while (PTEMP2->PNext != NULL) { PTEMP2 = PTEMP2->PNext; } PTEMP2->PNext = PTEMP; } } }
我把上面程式碼裡面的一段摘出來說明一下。
這段程式碼裡面可以看到我又定義了一個PTEMP2指針變數,為什麼呢?前面我提到過沒有尾指針的時候添加結點的思想就是要遍曆數組,從而找到最後一個結點然後讓它指向我們要插入的結點,如果沒有這個PHEAD2,我們遍歷完鏈表以後我們的頭指針PHEAD1就已經指向了最後一個結點了,單項鏈表如果頭指針移動了,數據就會找不到了。所以我定義了一個中間變數裝著頭指針然後去遍歷鏈表,讓頭指針永遠指向鏈表的頭。
else { struct NODE* PTEMP2 = *PHEAD1; while (PTEMP2->PNext != NULL) { PTEMP2 = PTEMP2->PNext; } PTEMP2->PNext = PTEMP; }
可以看到有尾指針的程式碼和沒有尾指針的程式碼裡面,有尾指針的鏈表裡面我每次添加完數據都讓尾指針指向最後一個結點,然後通過尾指針來添加數據。而沒有尾指針的鏈表裡面每次添加數據都要通過循環來遍歷鏈表找到最後一個結點然後指向所添加的結點。如果一個鏈表裡面有幾萬個結點,每次都通過循環遍歷鏈表來添加數據,那麼速度就相對於有尾指針的鏈錶慢很多。總而言之,還是看個人愛好吧。不管黑貓還是白貓能抓到耗子都是好貓。

