「回顧」愛奇藝大數據分析平台的演進之路
- 2019 年 11 月 23 日
- 筆記

首先講一下愛奇藝大數據平台業務背景,目前日均DAU接近三億,愛奇藝在業務初期主要關注於長影片,隨後發展業務有PPC、UPC,同時還發展了遊戲、直播、小說等業務。目前業務線達到20多條,存量的設備資訊達到30億,每天處理的用戶行為日誌超過300T。這種業務數據量對數據運維、開發人員提出了很高的要求。
1. 起始時代

愛奇藝剛剛起步時平台架構很簡單,數據流從日誌通過RSYNC流入到Hive,然後通過腳驅動Hive SQL語句統計分析,結果導入到MySQL,最後形成報表展示。整個流程的驅動基於Shell腳本完成,報表系統和數據處理是利用Java實現。然後進入第二階段,原先所有業務需求都是手工處理,所有報表都要寫Java程式碼開發,這個給開發人員造成了很大的工作量,並且用戶獲取數據周期長,速度慢。
2. 魔鏡時代

因此開發了一個魔鏡系統。在魔鏡系統中進行投遞管理、投遞驗證,通過自研的日誌收集器Accio Log將日誌從Pingback伺服器上傳到HDFS;再通過Transfiguration解析框架做日誌格式轉化和分拆入庫。然後分析人員可以再魔鏡系統上通過配置進行自助取數,不再需要等待開發排期
但是隨著業務不斷發展,數據需求不斷增多,很快遇到了新的問題。開發魔鏡系統是由於需求較多開發人員處理不過來,現在是取數計算太多,Hadoop集群處理不過來。因為在魔鏡系統中消費的大多都是日誌數據,數據量非常大,任務又多,導致集群計算壓力非常大。而且數據開發人員仍然是主要進行腳本開發,調度方式也不成體系。所以我們基於魔鏡系統的思路進行進一步設計,研發了大數據平台「通天塔」系統。
3. 通天塔時代

通天塔集合了整個愛奇藝技術部門所有數據、所有計算資源和服務框架,重新構建形成一個大數據平台框架。底層是大數據平台所用的計算資源,離線計算主要是Hive、Spark,流式計算主要是Spark Streaming和Flink;OLAP主要是Impala和Kylin。數據方面Pingback是用戶行為日誌,機器日誌就是程式產生的相關日誌。線上資料庫主要是MySQL、MongoDB等,大數據存儲主要是HDFS、HBase、Kudu,Kudu主要是支援實時,分散式存儲主要是HBase、HDFS。再往上層是開發平台層,主要負責工作流開發。流計算通過專門的開發工具進行管理,就是將任務開發進行重新構建。數據開發針對於系統數據進行血緣管理,提供數據集成管理,實現數據在不同集群、引擎間的同步。如機房中有很多機器分成3-4個集群,相互之間要進行數據同步,先前主要是手寫程式完成,現在可以通過數據集成來進行跨DC的數據同步。數倉管理主要是埋點投遞管理、指標維度管理、數倉模型管理。最上層就是直接面向用戶的分析報表平台,自助分析工具有漏斗分析、畫像分析、路徑分析,還有自助查詢工具、BI報表工具,接下來會詳細講解。
4. 工作流管理與開發方式的演變

接下來講一下工作流管理與開發方式的演變,剛開始的時候在這方面投入量不是很大,使用Crontab直接驅動數據處理腳本運行。隨著任務量逐漸增多,crontab會變得不可維護,就利用Shell寫了一個框架,可以自動批量維護很多計算。隨著業務發展又無法滿足需求,引入Linkedin公司的開源工作流調度器Azkaban。由於當時Azkaban只能單機,可維護性也不是很高,自研發了一個工作流管理系統Gear,但是Gear的管理基於配置文件,開發調試起來麻煩又自研了通天塔數據開發Babel BD。

Slytherin完全是一個Shell腳本,有一個驅動腳本和一個執行腳本。驅動腳本主要是調動執行腳本運行,並關注其運行生命周期,感知整個並發量,避免對集群造成過大的壓力。執行腳本保證自己的唯一性,處理完成後打好標誌文件,保證唯一性的方式就是記錄自己的process ID作為ID鎖,如果檢測自己有ID鎖存在,就不再重複執行。隨著後續發展發現其可視化程度不高,維護成本大,於是引入了Azkaban,其優點是使用簡單、開源、可視化程度很高,缺點是當年只能單機,在使用Azkaban時愛奇藝集群有3-4個,涉及的集群機器有上百台,每個集群都會有很多台入口Client機器,只能一台機器一台機器去維護,整體大局性控制不高。


基於上述缺點,雲服務部門的同事著手開發Gear工作流管理。 這是一個基於appache的Oozie在上層進行二次開發的工具,沒有直接使用Oozie是由於其配置過於繁瑣,可視化不是很好。因此在Oozie基礎上進行配置簡化,並且提供更友好的介面和開發方式,主要是使用GitLab-CI和SDK的方式提交。上圖是一個並行的工作流,配置文件通過GitLab提交,Gitlab-CI會自動提交發布,然後實例化,同時會調用相應的API將計算過程進行監控。


在開發過程中還是感覺配置Gear過程比較複雜,配置文件編寫容易出錯,平均需要提交三次調試三次才能成功執行。因此在通天塔系統中進行進一步封裝,形成BabelBD開發IDE。BabelBD可以直接拖拽節點的方式開發工作流,這樣開發人員只需要關注核心SQL語句編寫和整個基礎流程,其他都交給IDE完成,上圖是實際開發效果和執行效果。


報表製作最開始是開發人員寫程式碼開發報表,後來是配置系統去配置報表,然後是讓用戶從自助系統和工具去自助發布報表,最後是生成一些個性化報告。最開始的報表系統是龍源報表系統,就是一個報表系統,幾乎沒有管理後台,僅有用戶許可權管理。其架構是最基礎的MVC模式,開發的每一張報表都是一個小的JavaWeb項目。需要為每一張報表編寫JSP頁面,隨著業務量增加,開發人員任務加重,因此將報表配置抽象化。形成一個報表配置平台-龍源2.0,配置流程最核心的就是寫SQL,定義相關圖表資訊、條件資訊,將其配置成一張報表。最後利用bootstrap的一個可視化配置管理工具,通過拖拽方式搭建報表。由於業務線發展,愛奇藝發展成為一個多元平台,各種業務層出不窮,先前一體化的報表模式不能滿足需求,大BI系統應運而生。

5. 愛奇藝BI

愛奇藝BI平台是一個很大的平台系統,報表只是其中的一部分,最核心的部分就是對不同業務線進行拆分。在前期的基礎上,配置方式進一步抽象,思路也進行了變更。之前從SQL語句開始配置是基於開發的思路,現在是從報表構建的思路去配置,先配置報表的雛形,然後詳細配置報表的各個組件,這種方式更加符合數據分析者的思路。
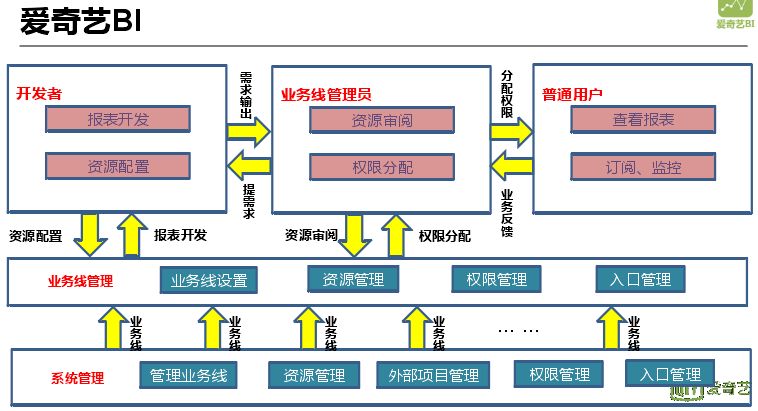
愛奇藝BI核心不在報表開發,核心在於業務線劃分以及許可權的劃分。數據安全越來越重要,在業務線和許可權方面做了很多工作。除了開發人員開發報表外,還可以讓用戶通過一些自助分析的系統發布自己的報表到BI進行展示。
在消費數據時有個很重要的一點就是要保證數據是可用的,有時我們會去猜測數據在某一時刻是完整的,但是如果某一集群發生延遲,就會消費掉一個空數據。因此設置了Done文件機制。將Done文件放到HDFS上,每生成一個表都有相應的Done文件,每當消費某張數據表都會先檢測其Done文件是否存在。HDFS很怕小文件,但是每個表每天都會有若干done文件產生,而且表非常多,就會有海量空文件產生。所以為了避免HDFS壓力過大,我們就製作了Done服務,這樣直接在做依賴判斷的時候,直接使用Done服務,不再在HDFS上查找,依賴管理最終採用的方案是數據管理。


數據管理會將數據的整個生命周期管理起來,對數據進行可用性管理並提供服務給其他業務調用,用來替代Done服務。它通過元數據抓取、手動錄入、投遞註冊管理、外部系統註冊管理,通過數據血緣分析、數據標註、數據生命周期分析等對各種元數據進行系統性管理。
接下來講一下我們的數據倉庫演變,最開始的時候我們的分析統計都是直接消費日誌表,所有報表結果都是從日誌表中計算產生,產生的結果是造成資源浪費,並且定義不清楚,缺乏周知性。接著就針對影片播放設計了播放數倉模型,製作了中間大寬表,方便使用。但是對於有些簡單表或者其他一些條件不適用,目前採用分層建模的方式。


直接消費日誌表優點是最底層、簡單,數據原始,無任何聚合處理,可以探查細節,缺點就是數據量大,消耗計算資源大,未進行反刷量。中間大寬表就是按照一定的主題進行聚合,盡量使用最全面的欄位盡量方便使用;同時也進行了反刷量過濾,只有少量數據會用到日誌,大寬表有個缺點就是數據量不適合在Impala等OLAP引擎使用。分層建模有日誌層、明細層、聚合層、應用層,不同主題都在聚合層,根據不同的應用場景會上升到應用層構建。明細層和日誌層利用魔鏡和SQL語句進行管理查詢,應用層針對BI報表和莫奈系統,日誌層默認不開放,業務簡單時會開放查詢。

基於上述需求使用了一些數倉工具,主要負責數倉模型管理,其核心是指標維度管理,基於指標維度進行數據開發,然後進行一些分析,尤其是莫奈系統中利用指標維度統一的標準資訊製作場景和場景間關聯,在BI報表直接引用指標維度資訊製作報表。
OLAP在數倉的上一層,最開始只使用MySQL,通過分庫分表來解決大數據量問題;之後就藉助MySQL+HBase,將一部分數據提前計算好存入HBase,根據不同的查詢進行提取。接著就引入Kylin/Impala作為查詢引擎,目前考慮的是不同框架綜合使用,不局限於一個查詢,根據分析目標數據源不同,智慧選擇不同的引擎。

一個典型的例子就是劇集統計,愛奇藝有海量影片數據,剛開始是幾十萬,現在是一億+的影片資源。原先按可加項不可加項分表,分表維度也有很多(來源、提供商),隨著影片量增加這種方式無法滿足需求,查詢速度很慢。接著採用冷熱數據分表,保證日常最常用數據的查詢速度,數據按天、月、年進行分表。後來考慮將一部分數據存入HBase中,每天會進行播放數據排行計算,最難的也是計算排行,將不同組合的排行數據預先組合計算存入HBase中。接著將所有數據都存入HBase中,這種思想就是Kylin思想,將不同維度組合提前算好存入HBase,這樣就可以提供給自助查詢系統使用。
6. 魔鏡與庖丁刃

前面主要講報表,接下來講一下分析人員和運維人員取數分析方式的變化。最開始是運營人員提出數據需求,首先看報表是否滿足,滿足直接查報表,不滿足作為臨時報表讓開發人員完成報表取數。這種方式工作量大、周期長,後來用戶通過魔鏡看結果或者運行SQL,如果魔鏡不滿足再去看報表或者開發。目前和未來思想就是先看報表是不是滿足,不滿足提供專門的分析工具,如漏斗分析、畫像分析去訂製化分析需求,再不滿足通過OLAP分析進行拖拽式分析,或者通過魔鏡去寫SQL,生成結果後看是否滿足,是否需要進一步分析,如果需要就回到OLAP系統進行分析。
整體的思路是最開始靠人工,分析師通過人工導數、Excel分析等工具進行分析。後來發展為主要依據魔鏡進行報表導數,後續分析主要還是Excel等其他分析工具。現在是將用戶往莫奈分析系統上引導,後續是希望去掉像Excel等其他分析工具,所有分析都在莫奈系統中完成。魔鏡是通過勾選配置的方式寫SQL達到取數的目的,通過定義指標、選取維度、定義詳細的條件、排序方式,通過勾選方式生成SQL,最後落在SQL執行的引擎上。庖丁刃就是提供給用戶一個SQL編輯的工具,同時還提供一些數據源的管理。魔鏡和庖丁刃是一個相相成的工具,庖丁刃的SQL不一定能轉化為魔鏡的訂製計算,但是魔鏡的訂製計算一定能轉化為庖丁刃的SQL。

庖丁刃的技術架構,上層網頁層是SQL編輯器以及魔鏡訂製計算的介面。伺服器會根據不同的數據源路由到不同的執行引擎上執行,同時會進行許可權的驗證。最下層是實際SQL執行引擎,可以依據不同數據特點智慧選擇不同的引擎,並且根據執行情況進行智慧下沉。如Impala滿足不了會直接下沉到Spark,分為兩種一種是Impala沒有數據,另一種是Impala執行失敗。整個架構構建在企業雲計算架構上,全部微服務化,這樣易於監控和維護不容易掛掉。

孔明計算引擎是提供數據查詢的統一介面,實施智慧選擇執行引擎的一個工具。在執行的時候實現智慧下沉,確保計算的可靠性。在SQL解析開始後進行許可權驗證,依據SQL解析後數據源的結果進行引擎路由。目前如果不同數據源數據存在關聯會出現報錯,未來會開發底層觸發自動同步維護。
7. 莫奈系統

莫奈系統目標是只需滑鼠如作畫般划過螢幕,即可進行大數據分析,將抽象數據變成畫作。上圖是莫奈系統介面,給出的是事先製作好的報表進行的展示,可以直接將其發布到BI系統。將相應維度拖到工作區,支援不同行列的維度;同時還支援不同的圖形可視化方式;支援下載Excel數據,後續將其去掉採用生成報告的方式。後台是場景分析配置,每一個場景是根據數倉應用層進行的進一步抽象,將維度和指標全部抽象成場景配置到系統中去。

在普通場景基礎上支援多分析場景的自動組合,將已經定義好的場景合併到一起,同樣的欄位進行合併形成一個新的大場景。組合場景會根據用戶的勾選和當前場景維護情況自動生成查詢,並判斷當前條件維度選擇是否滿足需求。

莫奈系統架構,最上層的展現層是基於定義去開發的前後端系統,網關層網關相關配置,接下來的許可權控制、DSL邏輯、SQL層等都是微服務。最底層的查詢引擎用的最多就是Kylin,MySQL和IMPALA在系統中也可用,實現MySQL和Kylin並行使用。如果用戶需要對BI報表進行進一步分析,可以將報表數據直接拉到莫奈系統中進行進一步分析,當數據量過大時可以將MySQL下沉到IMPALA中執行。
8. 愛奇藝大數據分析體系
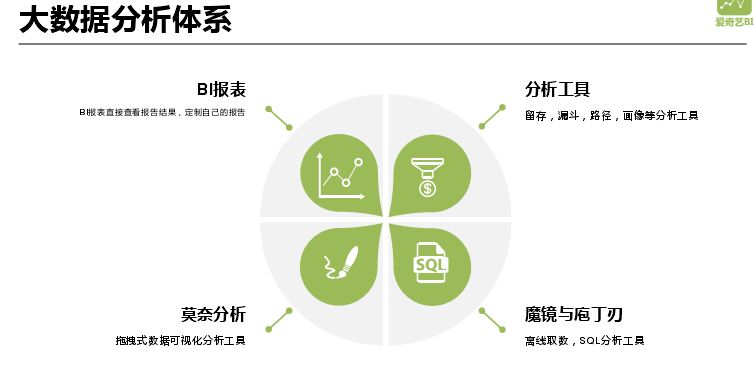
上圖中的任務構成愛奇藝大數據分析體系,上層是BI報表、莫奈分析、魔鏡與庖丁刃、分析工具。
BI報表:BI報表直接查看報告結果,訂製自己的報告;
莫奈分析:拖拽式數據可視化分析工具;
魔鏡與庖丁刃:離線取數,SQL分析工具;
分析工具:留存,漏斗,路徑,畫像等分析工具。
——END——
分享嘉賓:杜益凡 愛奇藝 高級技術經理
內容來源:DataFun Talk《愛奇藝大數據分析平台的演進之路》
出品社區:DataFun


