SQL精華總結索引類型優化SQL優化事務大表優化思維導圖❤️
- 2020 年 12 月 19 日
- 筆記
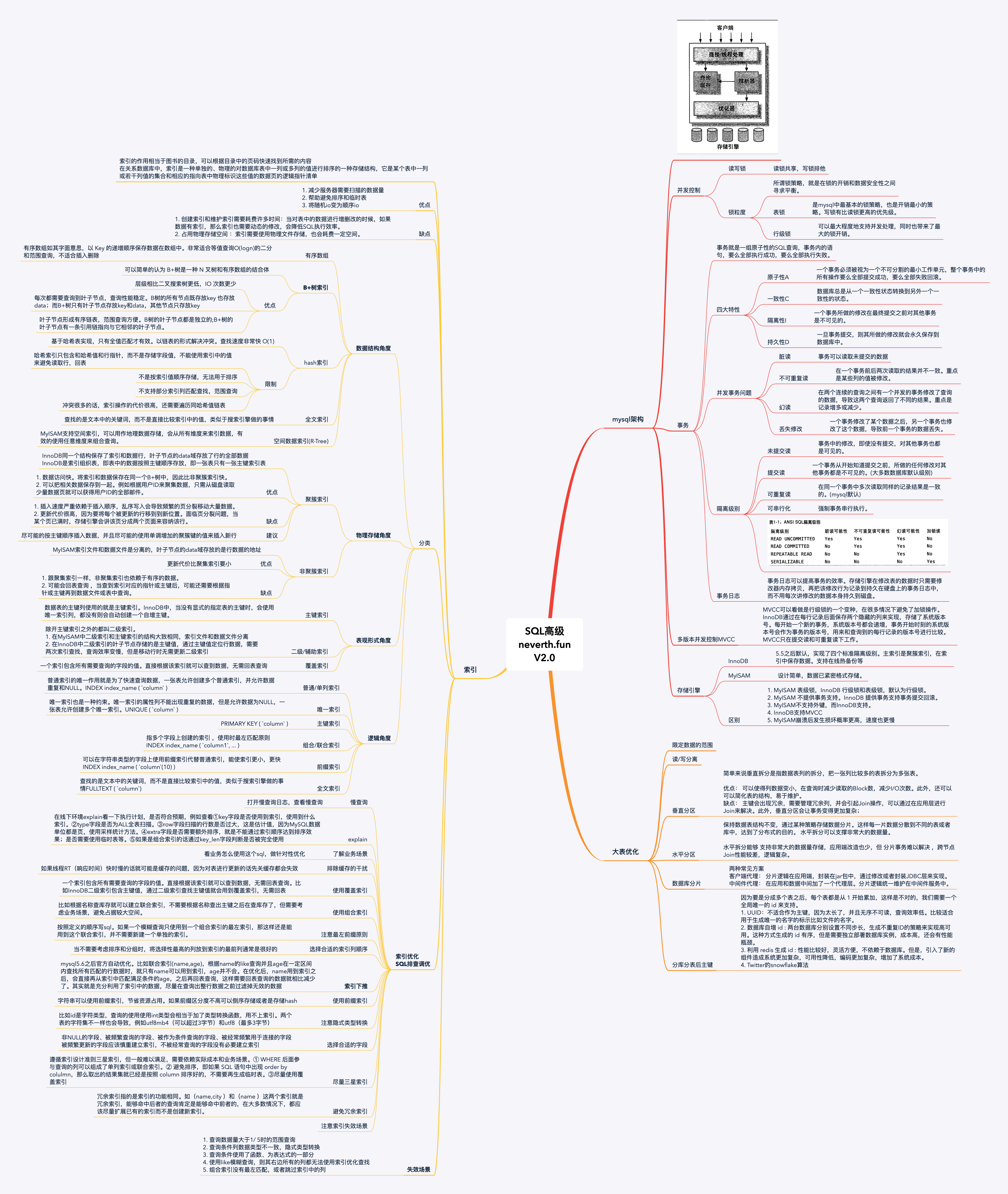
索引類型
從數據結構角度:
- B+樹索引,
- hash索引,基於哈希表實現,只有全值匹配才有效。以鏈表的形式解決衝突。查找速度非常快 O(1)
- 全文索引,查找的是文本中的關鍵詞,而不是直接比較索引中的值,類似於搜索引擎做的事情。
- 空間數據索引(R-Tree),MyISAM支援空間索引,可以用作地理數據存儲,會從所有維度來索引數據,有效的使用任意維度來組合查詢。
從物理存儲角度:
-
聚簇索引,InnoDB同一個結構保存了索引和數據行,葉子節點的data域存放了行的全部數據。
優點:數據訪問快。將索引和數據保存在同一個B+樹種,因此比非聚簇索引快。可以把相關數據保存到一起。例如根據用戶ID來聚集數據,只需從磁碟讀取少量數據頁就可以獲得用戶ID的全部郵件。
缺點:插入速度驗證依賴於插入順序,亂序寫入會導致頻繁的頁分裂移動大量數據。更新代價很高,因為要將每個被更新的行移到到新位置。面臨頁分裂問題,當某個頁已滿時,存儲引擎會講該頁分成兩個頁面來容納該行。
儘可能的按主鍵順序插入數據,並且儘可能的使用單調增加的聚簇鍵的值來插入新行。
-
非聚簇索引,MyISAM索引文件和數據文件是分離的,葉子節點的data域存放的是行數據的地址
優點: 更新代價比聚集索引要小 。
缺點:跟聚集索引一樣,非聚集索引也依賴於有序的數據。可能會二次查詢(回表) ,當查到索引對應的指針或主鍵後,可能還需要根據指針或主鍵再到數據文件或表中查詢。
從邏輯角度:
- 普通 /單列索引,普通索引的唯一作用就是為了快速查詢數據,一張表允許創建多個普通索引,並允許數據重複和NULL。
INDEX index_name ( column )。 - 唯一索引,唯一索引也是一種約束。唯一索引的屬性列不能出現重複的數據,但是允許數據為NULL,一張表允許創建多個唯一索引。
UNIQUE ( column ) - 主鍵索引,數據表的主鍵列使用的就是主鍵索引
PRIMARY KEY ( column) - 聯合索引,指多個欄位上創建的索引
INDEX index_name ( column1, ... ),使用時最左匹配原則 - 前綴索引,索引字元串的一部分
INDEX index_name ( column(10) ) - 全文索引,查找的是文本中的關鍵詞,而不是直接比較索引中的值,類似於搜索引擎做的事情。
FULLTEXT ( column)
從表現形式角度:
- 主鍵索引,數據表的主鍵列使用的就是主鍵索引。InnoDB中,當沒有顯式的指定表的主鍵時,InnoDB會自動先檢查表中是否有唯一索引的欄位,如果有,則選擇該欄位為默認的主鍵,否則InnoDB將會自動創建一個6Byte的自增主鍵。
- 二級 / 輔助索引,除開主鍵索引之外的都叫二級索引。在MyISAM中二級索引和主鍵索引的結構大致相同。在InnoDB中二級索引的葉子節點存儲的是主鍵值,通過主鍵值定位行數據,需要兩次索引查找。使用主鍵值當做指針會讓二級索引占更多的空間,但是移動行時無需更新二級索引。
- 覆蓋索引,如果一個索引包含(或者說覆蓋)所有需要查詢的欄位的值,我們就稱之為「覆蓋索引」。覆蓋索引即需要查詢的欄位正好是索引的欄位,那麼直接根據該索引,就可以查到數據了, 而無需回表查詢。
索引優化SQL排查調優
- 打開慢查詢日誌,查看慢查詢
- 首先在線下環境explain看一下執行計劃,是否符合預期,例如查看①key欄位是否使用到索引,使用到什麼索引。②type欄位是否為ALL全表掃描。③row欄位掃描的行數是否過大,估計值。MySQL數據單位都是頁,使用取樣統計方法。④extra欄位是否需要額外排序,就是不能通過索引順序達到排序效果;是否需要使用臨時表等。⑤如果是組合索引的話通過key_len欄位判斷是否被完全使用。
- 了解業務場景。看業務怎麼使用這個sql,做針對性優化。
- 排除快取的干擾。如果執行緒RT(響應時間)快時慢的話就可能是快取的問題,因為對錶進行更新的話先關快取都會失效
- 使用覆蓋索引。一個索引包含所有需要查詢的欄位的值。直接根據該索引就可以查到數據,無需回表查詢。比如InnoDB二級索引包含主鍵值,通過二級索引查找主鍵值就會用到覆蓋索引,無需回表
- 使用組合索引。比如根據名稱查庫存就可以建立聯合索引,不需要根據名稱查出主鍵之後在查庫存了,但需要考慮業務場景,避免佔據較大空間。
- 注意最左前綴原則,按照定義的順序寫sql。如果一個模糊查詢只使用到一個組合索引的最左索引,那這樣還是能用到這個聯合索引,並不需要新建一個單獨的索引。
- 選擇合適的索引列順序。當不需要考慮排序和分組時,將選擇性最高的列放到索引的最前列通常是很好的。
- 索引下推,mysql5.6之後官方自動優化。比如聯合索引(name,age),根據name的like查詢並且age在一定區間內查找所有匹配的行數據時,就只有name可以用到索引,age並不會。在優化後,name用到索引之後,會直接再從索引中匹配滿足條件的age,之後再回表查詢,這樣需要回表查詢的數據就相比減少了。其實就是充分利用了索引中的數據,盡量在查詢出整行數據之前過濾掉無效的數據。
- 使用前綴索引。當要給字元串加索引時,可以使用前綴索引,節省資源佔用。如果前綴區分度不高可以倒序存儲或者是存儲hash。
- 注意隱式類型轉換。比如id是字元類型,查詢的使用使用int類型會相當於加了類型轉換函數,用不上索引。兩個表的字符集不一樣也會導致,例如utf8mb4(可以超過3位元組)和utf8(最多3位元組)
- 被頻繁更新的欄位應該慎重建立索引,不被經常查詢的欄位沒有必要建立索引。
- 遵循索引設計準則三星索引,但一般難以滿足,需要依賴實際成本和業務場景。① WHERE 後面參與查詢的列可以組成了單列索引或聯合索引。② 避免排序,即如果 SQL 語句中出現 order by colulmn,那麼取出的結果集就已經是按照 column 排序好的,不需要再生成臨時表。③盡量使用覆蓋索引
- 注意索引失效場景。
思維導圖