Boost.JSON Boost的JSON解析庫(1.75首發)
目錄
Boost的1.75版本新庫
12月11日,Boost社區發布了1.75版本,相比較於原定的12月9日,推遲了兩天。這次更新帶來了三個新庫:JSON,LEAF,PFR。
其中JSON自然是json格式的解析庫,來自Vinnie Falco和Krystian Stasiowski。
LEAF是一個輕量的異常處理庫,來自Emil Dotchevski。
PFR是一個基礎的反射庫,不需要用戶使用宏和樣版程式碼(由於還未仔細閱讀此庫,可能翻譯有一些不準確),來自Antony Polukhin。
JSON庫簡介
其實在之前,Boost就已經有能夠解析JSON的庫了,名字叫做Boost.PropertyTree。Boost.PropertyTree不僅僅能夠解析JSON,還能解析XML,INI和INFO格式的文件。但是由於成文較早及需要兼容其他的數據格式,相比較於其他的C++解析庫,其顯得比較笨重,使用的時候有很多的不方便。
Boost.JSON相對於Boost.PropertyTree來所,其只能支援JSON格式的解析,但是其使用方法更為簡便,直接。華麗胡哨的東西也更多了。
JSON的簡單使用
有兩種方法使用Boost.JSON,一種是動態鏈接庫,此時引入頭文件boost/json.hpp,同時鏈接對應的動態庫;第二種是使用header only模式,此時只需要引入頭文件boost/json/src.hpp即可。兩種方法各有優缺點,酌情使用。
編碼
最通用的方法
我們要構造的json如下,包含了各種類型。
{
"a_string" : "test_string",
"a_number" : 123,
"a_null" : null,
"a_array" : [1, "2", {"123" : "123"}],
"a_object" : {
"a_name": "a_data"
},
"a_bool" : true
}
構造的方法也很簡單:
boost::json::object val;
val["a_string"] = "test_string";
val["a_number"] = 123;
val["a_null"] = nullptr;
val["a_array"] = {
1, "2", boost::json::object({{"123", "123"}})
};
val["a_object"].emplace_object()["a_name"] = "a_data";
val["a_bool"] = true;
首先定義一個object,然後往裡面塞東西就好。其中有一個emplace_object這個比較重要,後面會提到。
結果:

使用std::initializer_list
Boost.JSON支援使用std::initializer_list來構造自己的對象。所以也可以這樣使用:
boost::json::value val2 = {
{"a_string", "test_string"},
{"a_number", 123},
{"a_null", nullptr},
{"a_array", {1, "2", {{"123", "123"}}}},
{"a_object", {{"a_name", "a_data"}}},
{"a_bool", true}
};
結果如下:

json對象的輸出
生成了json對象以後,就可以使用serialize對對象進行序列化了。
std::cout << boost::json::serialize(val2) << std::endl;
結果如前兩圖。
除了直接把整個對象直接輸出,Boost.JSON還支援分部分進行流輸出,這種方法在數據量較大時,可以有效降低記憶體佔用。
boost::json::serializer ser;
ser.reset(&val);
char temp_buff[6];
while (!ser.done()) {
std::memset(temp_buff, 0, sizeof(char) * 6);
ser.read(temp_buff, 5);
std::cout << temp_buff << std::endl;
}
結果:
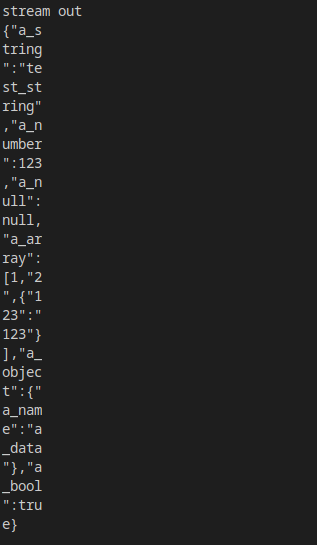
如果快取變數是數組,還可以直接使用ser.read(temp_buff)。
需要注意的是,ser.read並不會默認在字元串末尾加\0,所以如果需要直接輸出,在輸入時對快取置0,同時為\0空餘一個字元。
也可以直接使用輸出的boost::string_view。
兩種對比
這兩種方法對比的話,各有各的優點。前一種方法比較時候邊運行邊生成,後者適合一開始就需要直接生成的情形,而且相對來說,後者顯得比較的直觀。
但是第二種方法有一個容易出現問題的地方。比如以下兩個json對象:
// json1
[["data", "value"]]
//json2
{"data": "value"}
如果使用第二種方法進行構建,如果一不小心的話,就有可能寫出一樣的程式碼:
boost::json::value confused_json1 = {{"data", "value"}};
boost::json::value confused_json2 = {{"data", "value"}};
std::cout << "confused_json1: " << boost::json::serialize(confused_json1) << std::endl;
std::cout << "confused_json2: " << boost::json::serialize(confused_json2) << std::endl;
而得到的結果,自然也是一樣的:
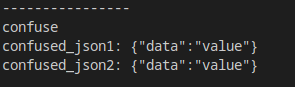
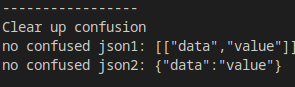
如果需要消除這一歧義,可以直接使用Boost.JSON提供的對象構建有可能產生歧義的地方:
boost::json::value no_confused_json1 = {boost::json::array({"data", "value"})};
boost::json::value no_confused_json2 = boost::json::object({{"data", "value"}});
結果為:
解碼
JSON的解碼也比較簡單。
簡單的解碼
auto decode_val = boost::json::parse("{\"123\": [1, 2, 3]}");
直接使用boost::json::parse,輸入相應的字元串就行了。
增加錯誤處理
boost::json::error_code ec;
boost::json::parse("{\"123\": [1, 2, 3]}", ec);
std::cout << ec.message() << std::endl;
boost::json::parse("{\"123\": [1, 2, 3}", ec);
std::cout << ec.message() << std::endl;
結果:
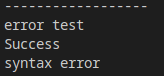
非嚴格模式
在這個模式下,Boost.JSON可以選擇性的對一些不那麼嚴重的錯誤進行忽略。
unsigned char buf[4096];
boost::json::static_resource mr(buf);
boost::json::parse_options opt;
opt.allow_comments = true; // 允許注釋
opt.allow_trailing_commas = true; // 允許最後的逗號
boost::json::parse("[1, 2, 3, ] // comment test", ec, &mr, opt);
std::cout << ec.message() << std::endl;
boost::json::parse("[1, 2, 3, ] // comment test", ec, &mr);
std::cout << ec.message() << std::endl;
結果如下:
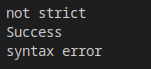
可以看到,增加了選項的解釋器成功的解析了結果。
流輸入
和輸出一樣,輸入也有流模式。
boost::json::stream_parser p;
p.reset();
p.write("[1, 2,");
p.write("3]");
p.finish();
std::cout << boost::json::serialize(p.release()) << std::endl;
結果:
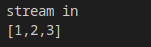
進階應用
對象序列化
有時候我們需要將對象轉換為JSON,對對象進行序列化然後保存。Boost.JSON提供了一個非常簡單的方法,能夠使我們非常簡單的將一個我們自己定義的對象轉化為JSON對象。
我們只需要在需要序列化的類的命名空間中,定義一個重載函數tag_invoke。注意,是類所在的命名空間,而不是在類裡面定義。
使用示例:
namespace MyNameSpace {
class MyClass {
public:
int a;
int b;
MyClass (int a = 0, int b = 1):
a(a), b(b) {}
};
void tag_invoke(boost::json::value_from_tag, boost::json::value &jv, MyClass const &c) {
auto & jo = jv.emplace_object();
jo["a"] = c.a;
jo["b"] = c.b;
}
}
其中,boost::json::value_from_tag是作為標籤存在的,方便Boost.JSON分辨序列化函數的。jv是輸出的JSON對象,c是輸入的對象。
boost::json::value_from(MyObj)
使用的話,直接調用value_from函數即可。
結果:
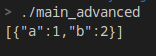
序列化還有一個好處就是,可以在使用std::initializer_list初始化JSON對象時,直接使用自定義對象。譬如:
boost::json::value val = {MyObj};
注意,這裡的val是一個數組,裡面包含了一個對象MyObj。
反序列化
有序列化,自然就會有反序列化。操作和序列化的方法差不多,也是定義一個tag_invoke函數,不過其參數並不一致。
MyClass tag_invoke(boost::json::value_to_tag<MyClass>, boost::json::value const &jv) {
auto &jo = jv.as_object();
return MyClass(jo.at("a").as_int64(), jo.at("b").as_int64());
}
需要注意的是,由於傳入的jv是被const修飾的,所以不能類似於jv["a"]使用。
使用也和上面的類似,提供了一個value_to<>模板函數。
auto MyObj = boost::json::value_to<MyNameSpace::MyClass>(vj);
無論是序列化還是反序列化,對於標準庫中的容器,Boost.JSON都可以直接使用。
Boost.JSON的類型
array
數組類型,用於儲存JSON中的數組。實際使用的時候類似於std::vector<boost::json::value>,差異極小。
object
對象類型,用於儲存JSON中的對象。實際使用時類似於std::map<std::string, boost::json::value>,但是相對來說,它們之間的差異較大。
string
字元串類型,用於儲存JSON中的字元串。實際使用時和std::basic_string類似,不過其只支援UTF-8編碼,如果需要支援其他編碼,在解碼時候需要修改option中相應的選項。
value
可以儲存任意類型,也可以變換為各種類型。其中有一些特色的函數比如as_object,get_array,emplace_int64之類的。它們的工作都類似,將boost::json::value對象轉化為對應的類型。但是他們之間也有一定的區別。
as_xxx返回一個引用,如果類型不符合,會拋出異常get_xxx返回一個引用,不檢查類型,如果類型不符合,可能導致未定義行為is_xxx判斷是否為xxx類型if_xxx返回指針,如果類型不匹配則返回nullptremplace_xxx返回一個引用,可以直接改變其類型和內容。
總結
大致的使用方法就這些了。如果還要更進一步的話,就是涉及到其記憶體管理了。
縱觀整個庫的話,感覺其對於模板的使用相當克制,能不使用就不使用,這在一定程度上也提高了編譯的速度。
引用
部落格原文://www.cnblogs.com/ink19/p/Boost_JSON.html


