Java之String重點解析
String s = new String("abc")這段程式碼創建了幾個對象呢?s=="abc"這個判斷的結果是什麼?s.substring(0,2).intern()=="ab"這個的結果是什麼呢?- s.charAt(index) 真的能表示出所有對應的字元嗎?
"abc"+"gbn"+s直接的字元串拼接是否真的比使用StringBuilder的性能低?
前言
很高興遇見你~
Java中的String對象特性,與c/c++語言是很不同的,重點在於其不可變性。那麼為了服務字元串不可變性的設計,則衍生出非常多的相關問題:為什麼要保持其不可變?底層如何存儲字元串?如何進行字元串操作才擁有更好的性能?等等。此外,字元編碼的相關知識也是非常重要;畢竟,現在使用emoij是再正常不過的事情了。
文章的內容圍繞著不可變 這個重點展開:
- 分析String對象的不可變性;
- 常量池的存儲原理以及intern方法的原理
- 字元串拼接的原理以及優化
- 程式碼單元與程式碼點的區別
- 總結
那麼,我們開始吧~
不可變性
理解String的不可變性,我們可以簡單看幾行程式碼:
String string = "abcd";
String string1 = string.replace("a","b");
System.out.println(string);
System.out.println(string1);
輸出:
abcd
bbcd
string.replace("a","b")這個方法把"abcd"中的a換成了b。通過輸出可以發現,原字元串string並沒有發生任何改變,replace方法構造了一個新的字元串"bbcd"並賦值給了string1變數。這就是String的不可變性。
再舉個栗子:把"abcd"的最後一個字元d改成a,在c/c++語言中,直接修改最後一個字元即可;而在java中,需要重新創建一個String對象:abca,因為"abcd"本身是不可變的,不能被修改。
String對象值是不可變的,一切操作都不會改變String的值,而是通過構造新的字元串來實現字元串操作。
很多時候很難理解,為什麼Java要如此設計,這樣不是會導致性能的下降嗎?回顧一下我們日常使用String的場景,更多的時候並沒有直接去修改一個string,而是使用一次,則被拋棄。但下次,很可能,又再一次使用到相同的String對象。例如日誌列印:
Log.d("MainActivity",string);
前面的"MainActivity"我們並不需要去更改他,但是卻會頻繁使用到這個字元串。Java把String設計為不可變,正是為了保持數據的一致性,使得相同字面量的String引用同個對象。例如:
String s1 = "hello";
String s2 = "hello";
s1與s2引用的是同個String對象。如果String可變,那麼就無法實現這個設計了。因此,我們可以重複利用我們創建過的String對象,而無需重新創建他。
基於重複使用String的情況比更改String的場景更多的前提下,Java把String設計為不可變,保持數據一致性,使得同個字面量的字元串可以引用同個String對象,重複利用已存在的String對象。
在《Java編程思想》一書中還提到另一個觀點。我們先看下面的程式碼:
public String allCase(String s){
return string.toUpperCase();
}
allCase方法把傳入的String對象全部變成大寫並返回修改後的字元串。而此時,調用者的期望是傳入的String對象僅僅作為提供資訊的作用,而不希望被修改,那麼String不可變的特性則非常符合這一點。
使用String對象作為參數時,我們希望不要改變String對象本身,而String的不可變性符合了這一點。
存儲原理
由於String對象的不可變特性,在存儲上也與普通的對象不一樣。我們都知道對象創建在 堆 上,而String對象其實也一樣,不一樣的是,同時也存儲在 常量池 中。處於堆區中的String對象,在GC時有極大可能被回收;而常量池中的String對象則不會輕易被回收,那麼則可以重複利用常量池中的String對象。也就是說, 常量池是String對象得以重複利用的根本原因 。
常量池不輕易垃圾回收的特性,使得常量池中的String對象可以一直存在,重複被利用。
往常量池中創建String對象的方式有兩種: 顯式使用雙引號構造字元串對象、使用String對象的intern()方法 。這兩個方法不一定會在常量池中創建對象,如果常量池中已存在相同的對象,則會直接返回該對象的引用,重複利用String對象。其他創建String對象的方法都是在堆區中創建String對象。舉個栗子吧。
當我們通過new String()的方法或者調用String對象的實例方法,如string.substring()方法,會在堆區中創建一個String對象。而當我們使用雙引號創建一個字元串對象,如String s = "abc",或調用String對象的intern()方法時,會在常量池中創建一個對象,如下圖所示:
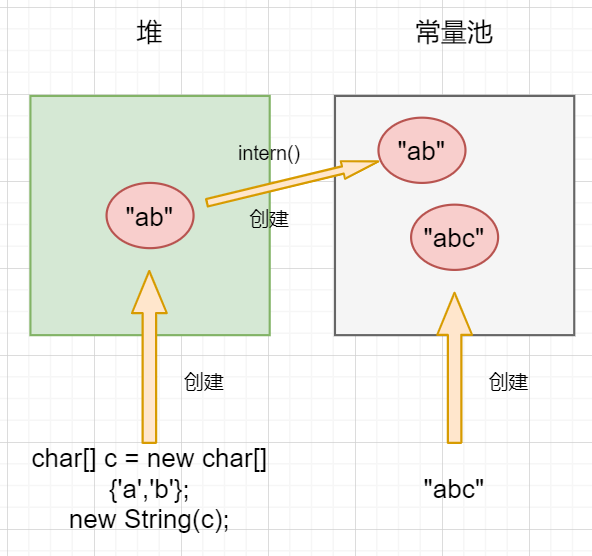
還記得我們文章開頭的問題嗎?
String s = new String("abc"),這句程式碼創建了幾個對象?"abc"在常量池中構造了一個對象,new String()方法在堆區中又創建了一個對象,所以一共是兩個。s=="abc"的結果是false。兩個不同的對象,一個位於堆中,一個位於常量池中。s.substring(0,2).intern()=="ab"intern方法在常量池中構建了一個值為「ab”的String對象,”ab”語句不會再去構建一個新的String對象,而是返回已經存在的String對象。所以結果是true。
只有顯式使用雙引號構造字元串對象、使用String對象的
intern()方法 這兩種方法會在常量池中創建String對象,其他方法都是在堆區創建對象。每次在常量池創建String對象前都會檢查是否存在相同的String對象,如果是則會直接返回該對象的引用,而不會重新創建一個對象。
關於intern方法還有一個問題需要講一下,在不同jdk版本所執行的具體邏輯是不同的。在jdk6以前,方法區是存放在永生代記憶體區域中,與堆區是分割開的,那麼當往常量池中創建對象時,就需要進行深拷貝,也就是把一個對象完整地複製一遍並創建新的對象,如下圖:
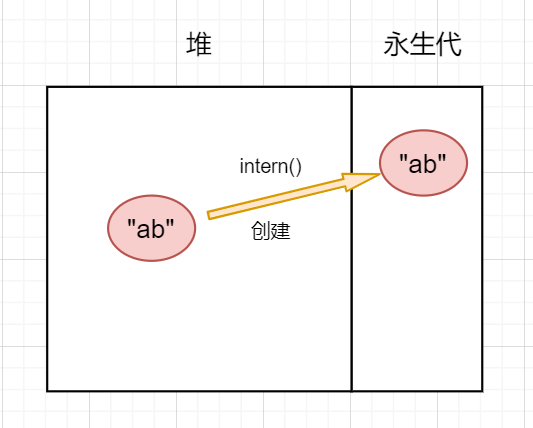
永生代有一個很嚴重的缺點:容易發生OOM 。永生代是有記憶體上限的,且很小,當程式大量調用intern方法時很容易就發生OOM。在JDK7時將常量池遷移出了永生代,改在堆區中實現,jdk8以後使用了本地空間實現。jdk7以後常量池的實現使得在常量池中創建對象可以進行淺拷貝,也就是不需要把整個對象複製過去,而只需要複製對象的引用即可,避免重複創建對象,如下圖:
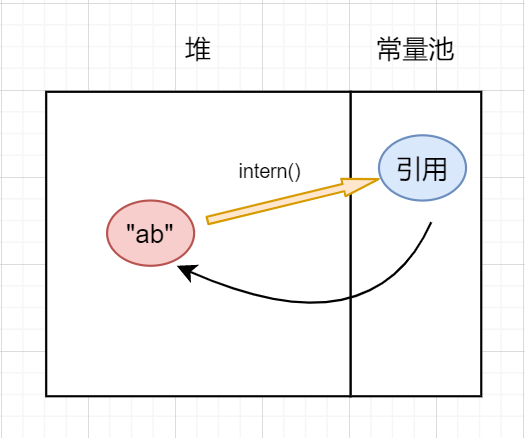
觀察這個程式碼:
String s = new String(new char[]{'a'});
s.intern();
System.out.println(s=="a");
在jdk6以前創建的是兩個不同的對象,輸出為false;而jdk7以後常量池中並不會創建新的對象,引用的是同個對象,所以輸出是true。
jdk6之前使用intern創建對象使用的深拷貝,而在jdk7之後使用的是淺拷貝,得以重複利用堆區中的String對象。
通過上面的分析,String真正重複利用字元串是在使用雙引號直接創建字元串時。使用intern方法雖然可以返回常量池中的字元串引用,但是本身已經需要堆區中的一個String對象。因而我們可以得出結論:
盡量使用雙引號顯式構建字元串;如果一個字元串需要頻繁被重複利用,可以調用intern方法將他存放到常量池中。
字元串拼接
字元串操作最多的莫過於字元串拼接了,由於String對象的不可變性,如果每次拼接都需要創建新的字元串對象就太影響性能了。因此,官方推出了兩個類: StringBuffer、StringBuilder 。這兩個類可以在不創建新的String對象的前提下拼裝字元串、修改字元串。如下程式碼:
StringBuilder stringBuilder = new StringBuilder("abc");
stringBuilder.append("p")
.append(new char[]{'q'})
.deleteCharAt(2)
.insert(2,"abc");
String s = stringBuilder.toString();
拼接、插入、刪除都可以很快速地完成。因此,使用StringBuilder進行修改、拼接等操作來初始化字元串是更加高效率的做法。StringBuffer和StringBuilder的介面一致,但StringBuffer對操作方法都加上了synchronize關鍵字,保證執行緒安全的同時,也付出了對應的性能代價。單執行緒環境下更加建議使用StringBuilder。
拼接、修改等操作來初始化字元串時使用StringBuilder和StringBuffer可以提高性能;單執行緒環境下使用StringBuilder更加合適。
一般情況下,我們會使用+來連接字元串。+在java經過了運算符重載,可以用來拼接字元串。編譯器也對+進行了一系列的優化。觀察下面的程式碼:
String s1 = "ab"+"cd"+"fg";
String s2 = "hello"+s1;
Object object = new Object();
String s3 = s2 + object;
-
對於s1字元串而言,編譯器會把
"ab"+"cd"+"fg"直接優化成"abcdefg",與String s1 = "abcdefg";是等價的。這種優化也就減少了拼接時產生的消耗。甚至比使用StringBuilder更加高效。 -
s2的拼接編譯器會自動創建一個StringBuilder來構建字元串。也就相當於以下程式碼:
StringBuilder sb = new StringBuilder(); sb.append("hello"); sb.append(s1); String s2 = sb.toString();那麼這是不是意味著我們可以不需要顯式使用StringBuilder了,反正編譯器都會幫助我們優化?當然不是,觀察下邊的程式碼:
String s = "a"; for(int i=0;i<=100;i++){ s+=i; }這裡有100次循環,則會創建100個StringBuilder對象,這顯然是一個非常錯誤的做法。這時候就需要我們來顯示創建StringBuilder對象了:
StringBuilder sb = new StringBuilder("a"); for(int i=0;i<=100;i++){ sb.append(i); } String s = sb.toString();只需要構建一個StringBuilder對象,性能就極大地提高了。
-
String s3 = s2 + object;字元串拼接也是支援直接拼接一個普通的對象,這個時候會調用該對象的toString方法返回一個字元串來進行拼接。toString方法是Object類的方法,若子類沒有重寫,則會調用Object類的toString方法,該方法默認輸出類名+引用地址。這看起來沒有什麼問題,但是有一個大坑:切記不要在toString方法中直接使用+拼接自身 。如下程式碼@Override public String toString() { return this+"abc"; }這裡直接拼接this會調用this的toString方法,從而造成了無限遞歸。
Java對+拼接字元串進行了優化:
- 可以直接拼接普通對象
- 字面量直接拼接會合成一個字面量
- 普通拼接會使用StringBuilder來進行優化
但同時也有注意這些優化是有限度的,我們需要在合適的場景選擇合適的拼接方式來提高性能。
編碼問題
在Java中,一般情況下,一個char對象可以存儲一個字元,一個char的大小是16位。但隨著電腦的發展,字符集也在不斷地發展,16位的存儲大小已經不夠用了,因此拓展了使用兩個char,也就是32位來存儲一些特殊的字元,如emoij。一個16位稱為一個 程式碼單元 ,一個字元稱為 程式碼點 ,一個程式碼點可能佔用一個程式碼單元,也可能是兩個。
在一個字元串中,當我們調用String.length() 方法時,返回的是程式碼單元的數目, String.charAt() 返回也是對應下標的程式碼單元。這在正常情況下並沒有什麼問題。而如果允許輸入特殊字元時,這就有大問題了。要獲得真正的程式碼點數目,可以調用 String .codePointCount 方法;要獲得對應的程式碼點,可調用 String.codePointAt 方法。以此來兼容拓展的字符集。
一個字元為一個程式碼點,一個char稱為一個程式碼單元。一個程式碼點可能佔據一個或兩個程式碼單元。若允許輸入特殊字元,則必須使用程式碼點為單位來操作字元串。
總結
到此,關於String的一些重點問題就分析完畢了,文章開頭的問題讀者應該也都知道答案了。這些是面試常考題,也是String的重點。除此之外,關於正則表達式、輸入與輸出、常用api等等也是String相關很重要的內容,有興趣的讀者可自行學習。
希望文章對你有幫助。
參考資料
- 《Java編程思想》 java工程師皆知的神書,詳細講解了如何更好運用java來編程,感受編程思想。
- 《Java核心技術卷一》 入門書籍,主要講解如何使用String的api以及一些注意的點。
- 《深入理解JVM》對於理解方法區以及常量池有非常大的幫助。
- 深入解析String#intern美團技術團隊的一篇分析String.intern方法的文章。
- 感謝網路其他部落格的貢獻。
全文到此,原創不易,覺得有幫助可以點贊收藏評論轉發。
筆者才疏學淺,有任何想法歡迎評論區交流指正。
如需轉載請評論區或私信交流。另外歡迎光臨筆者的個人部落格:傳送門


