G1 收集器
基礎知識
性能指標
在調優Java應用程式時,重點通常放在兩個主要目標上:響應性 或 吞吐量。
響應性Responsiveness 是指應用程式對請求的數據做出響應的速度:
- 桌面用戶介面對事件的響應速度
- 網站返回頁面的速度
- 資料庫查詢的返回速度
吞吐量Throughput 專註於最大程度地提高應用程式在特定時間段內的工作量:
- 在給定時間內完成的事務次數
- 批處理程式在一小時內可以完成的作業數
- 一小時內可以完成的資料庫查詢數
較長的暫停時間Pause Time對於注重響應性的應用程式是不可接受的,但對於注重吞吐量的應用程式來說可以接受的。前者重點是在短時間內做出響應,後者則側重與長時間運行的處理效率。
GC 基礎
GC Root

可達性分析是 Java GC 演算法的基礎,基本思路就是以一系列名為 GC Roots 對象作為起始點,通過引用關係遍歷對象圖,如果一個對象到 GC Roots 間沒有任何可達路徑相連時,則說明此對象可以被回收。

可以作為 GC Roots 的對象:
- 虛擬機棧(棧幀中的本地變數表)中引用的對象
- 本地方法棧中JNI(即一般說的native方法)中引用的對象
- 方法區中類靜態屬性引用的對象
- 方法區中常量引用的對象
三色標記
可達性分析中重要的一環就是遍歷整個堆,並標記其中的存活對象。一種常用的標記演算法是 三色標記法tri-color marking:

每個對象可能為以下 3 種顏色之一:
- white — 未被標記
- gray — 本身已標記,但部分引用的對象完成標記(動圖的黃色對象)
- black — 本身已標記,且所有引用的對象完成標記(動圖的藍色對象)
標記演算法從 GC Roots 出發遍歷堆,可達對象先標記 gray,然後再標記 為 black。
遍歷完成之後所有可達對象都是 black 的,此時所有標記為 white 的對象都是可以回收的。
當實現並發標記演算法時,必須防止 white 對象被漏標,否則可能導致不該回收的對象被回收。
分代收集
傳統垃圾收集器將堆分成三個部分:年輕代YoungGen = Eden + Survivor,老年代OldGen和永久代PermGen,每個區域記憶體連續且大小固定。
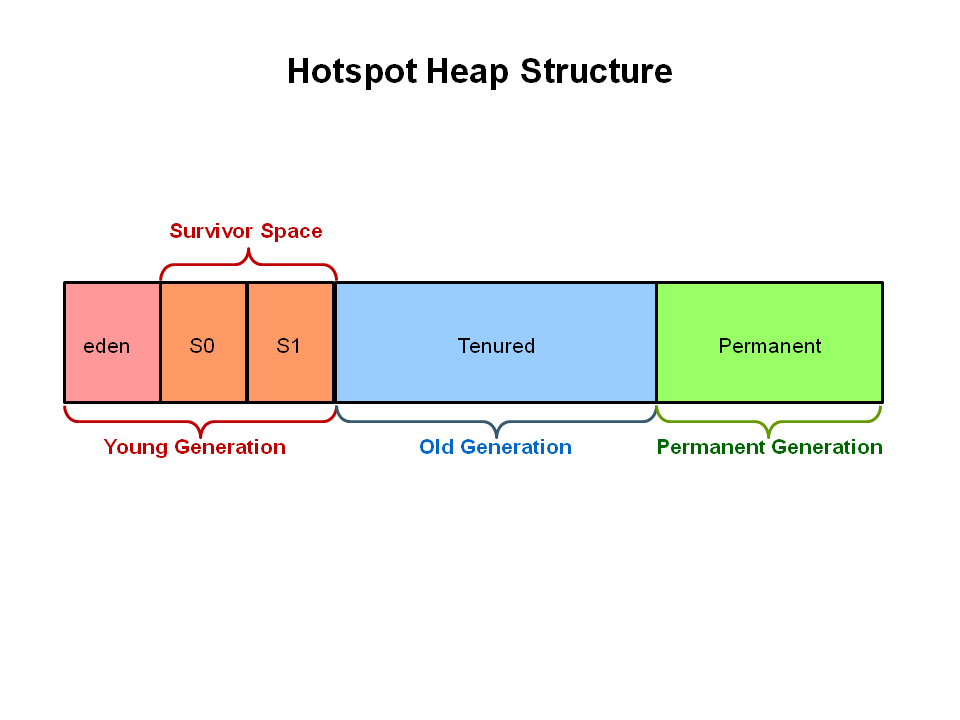
- 年輕代:一次性使用的臨時對象(例如:方法中構造的臨時對象)
- 老年代:被長期引用的常駐對象(例如:快取對象、單例對象)
- 永久代:JVM 運行過程中一直存在的對象(例如:字元串常量、類資訊)
將堆記憶體進行劃分後,可以按照對象生命周期長短,在不同區域使用不同的回收演算法,提高 GC 的效率。
演算法分類
Mark and Sweep標記-清除

用一個空閑列表free-list記錄失效對象佔用的記憶體區域,方便後續重新分配給新對象。
- 回收原理簡單,GC 停頓時間短
- 維護空閑列表需要一定的空間開銷
- 記憶體碎片較多,可能導致記憶體分配失敗
Mark-Sweep-Compact標記-整理

將所有存活對象移動到記憶體區域的開頭,剩餘的連續記憶體區域都是可用的空閑空間。
- 通過指針碰撞查找空閑空間,分配速度快
- 記憶體碎片少,記憶體分配失敗概率低
- 複製對象會導致較長時間的 GC 停頓
Mark and Copy標記-複製

將記憶體劃分為活動區間與空閑區間,前者用於動態分配對象,後者用於容納 GC 存活對象。
GC 時只需將存活對象從前者複製到後者,然後交換兩者的角色即可。
- 標記和複製在同一階段同時進行,當存活對象少時回收效率極高
- 需要預留一個空閑空間用於容納存活對象,造成記憶體浪費
CMS 回顧
CMS Concurrent Mark-Sweep 是一個採用 標記-清除 演算法的老年代收集器。
它通過與應用程式執行緒並發執行大多數垃圾回收工作,來最大程度地減少由於 GC 導致的暫停。
通常情況下,CMS 收集器不會複製或壓縮活動對象,這意味著無需移動活動對象即可完成垃圾回收。
然而過多的記憶體碎片可能造成分配失敗,最終導致 FullGC。可以通過分配更大的堆來規避這一問題。
CMS 對老年代的回收可以分為以下幾個步驟:
-
Initial Mark (STW)
初始標記
- 標記 GC Roots 直接可達的老年代對象
- 遍歷新生代存活對象,標記直接可達的老年代對象
-
Concurrent Mark
並發標記GC 執行緒遍歷 Initial Mark 階段標記出來存活的老年代對象,然後遞歸標記這些可達的對象。

該階段與應用執行緒並發運行,期間會發生新生代對象晉陞、老年代對象引用關係更新,需要對這些對象進行重新標記,避免發生遺漏。

CMS 用一個
card-table管理老年代,並發標記過程中,某個對象的引用關係發生了變化,則將對象所在的記憶體塊標記為 Dirty Card。CMS 使用增量更新
incremental update解決並發修改導致的漏標問題:把 black 對象重新標記為 grey,下次重新掃描其引用。 -
Preclean
預清理這一階段主要是處理 Concurrent Mark 階段中引用關係改變,導致沒有標記到的存活對象的。通過並發地重新掃描這些對象,預清理階段可以減少 Remark 階段的 STW。

這個階段會處理前一個階段被標記為 Dirty Card 的部分,將其中變化了的對象作為 GC Root 再進行掃描並重新標記。
-
Abortable Preclean
可終止的預清理這個階段作用與 Preclean 類似,但可以通過設置 掃描時長(默認5秒)或 Eden 區使用佔比(默認50%)控制本階段的結束時機。
增加這一階段的原因,是期待這期間能發生一次 YoungGC 清理無效的年輕代對象,減少 Remark 階段掃描年輕代的時間。
-
Remark (STW)
重新標記:這個階段同時掃描 YoungGen 與 OldGen,重新標記整個老年代中所有存活對象。
由於之前的 Concurrent Mark 與 Preclean 階段是與用戶執行緒並發執行的,年輕代對老年代的引用可能已經發生了改變,Remark 要花很多時間處理這些改變,會導致長時間的 STW。
此外,即使新生代的對象已經不可達了,CMS 也會使用這些不可達的對象當做的 GC Roots 來掃描老年代,導致部分失效的老年代對象無法被及時回收。
可以加入參數 -XX:+CMSScavengeBeforeRemark,在重新標記之前,先執行一次 YoungGC,回收掉年輕代的對象無用的對象。這樣進行年輕代掃描時,只需要掃描 Survivor 區的對象即可,一般 Survivor 區非常小,這大大減少了掃描時間。
-
Concurrent Sweep
並發清理
至此,老年代所有存活的對象已經被標記完成。這個階段主要是清除那些沒有標記的對象並且回收空間。
被回收的空間會被添加到 空閑列表中,以供以後分配。這一過程可能會對空閑空間進行合併,但是不會移動存活對象。
由於該階段是與應用執行緒並發運行的,自然就還會有新的垃圾不斷產生,這一部分垃圾出現在標記過程之後,無法在當次收集中處理掉它們。只好留待下一次GC時再清理掉。這一部分垃圾就稱為 浮動垃圾。
-
Resetting
重置清除數據結構,並重置定時器,為下一輪 GC 做準備。





G1 演算法
設計目的
G1 Garbage-First 是一種伺服器端的垃圾收集器:
- 可以與應用程式執行緒並行運行,減少 STW
- 整理空閑空間減少記憶體碎片,但不引入較長的 GC 暫停時間
- 提供可預測的GC暫停時間,無需犧牲很多吞吐量
G1 能夠在大記憶體的多處理器電腦上,保證 GC 暫停時間可控,並實現高吞吐量。
其最終目的是取代 CMS 成為服務端 GC 更好的解決方案:
- 採用 標記-整理 演算法,可以避免使用細粒度的空閑列表進行分配。簡化了收集器設計並消除了潛在的碎片問題。
- 使用 增量回收
incremental collecting演算法,其 GC 暫停時間比 CMS 更具可預測性,並允許用戶指定期望的暫停時間。
基本概念
G1 將堆劃分為一組大小相等的且連續的堆區域Region:

G1 中新生代與老年代不再連續,每個區域可以在 Eden、Survivor 與 Old 之間切換角色。此外,還有一類被稱為 Humongous 的巨型區域,用於容納體積 ≥ 標準區域大小的50%的對象。JVM 通常會將記憶體劃分為 2000個區域,每個大小從 1 到 32Mb 不等,由 JVM 在啟動時通過 -XX:G1HeapRegionSize 指定。
每個區域會被進一步細分成多個卡片Card,每個大小為 512Kb,用於實現細粒度的引用統計。
分區設計可以避免一次收集整個堆,每次 GC 只收集區域的一個子集 CSetcollection set,其中必然包含所有 Young 區域,同時可能包括部分 Old 區域:

根據回收區域的不同,可以將 GC 分為:
- YoungGC:CSet 只包含 Young 區域
- MixedGC: CSet 同時包含 Young 與 Old 區域
- FullGC: 回收整個堆(可用空間耗盡時觸發,單執行緒執行)
G1 根據存活對象的位元組數統計每個區域的 活躍度liveness,然後根據期望停頓時間來確定該 CSet 的大小,並保證那些垃圾多(活躍度低)的區域會被優先回收,故此得名 垃圾優先。
G1 的執行過程可以表示為由 3 個階段組成的循環:
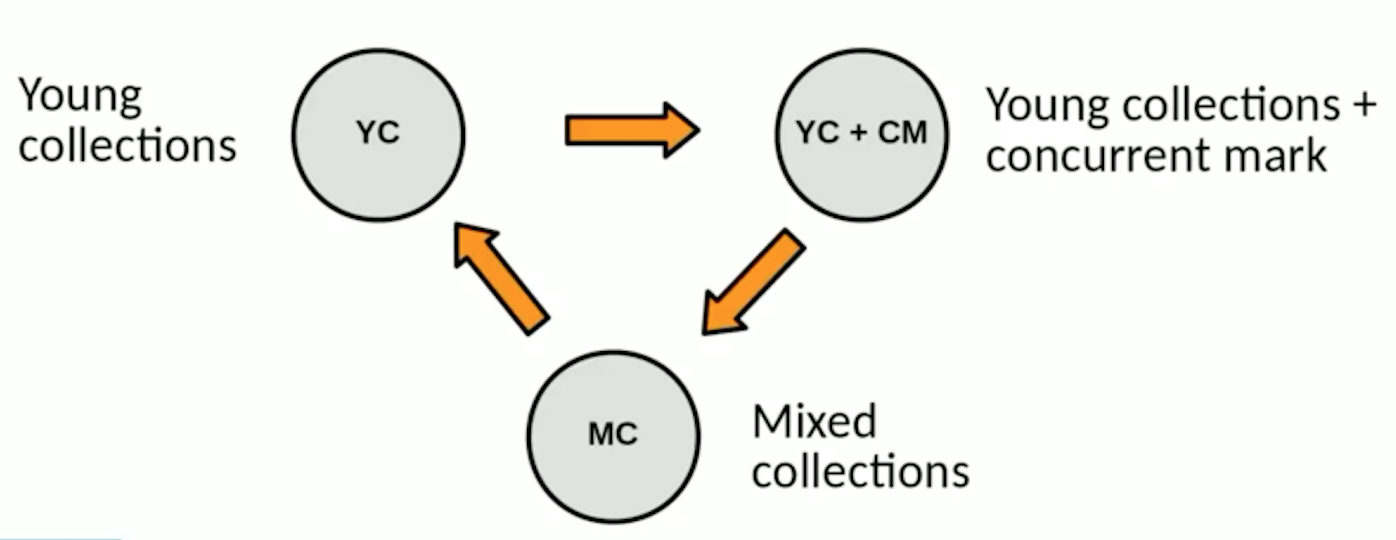
Young GC
堆中一開始只有 YoungGen,因此只會觸發 YoungGC,將 Eden 與 Survivor 區域中的活動對象複製到另一個空閑的 Survivor 區域。


G1 中將 將存活對象複製到其他區域 的過程稱為 疏散Evacuation。為了減少停頓時間,疏散工作由多個 GC 執行緒並行完成。
YoungGC 過程中會根據預期目標停頓時間 -XX:MaxGCPauseMillis 動態調整新生代的大小,通過 -XX:G1NewSizePercent 參數可以人為干預這一過程,但會讓預期停頓時間參數失效。
當堆的整體佔用空間足夠大時(超過45%),就會進入 Concurrent Marking 階段。通過 -XX:InitiatingHeapOccupancyPercent 選項可以配置這一行為。
Concurrent Marking
與 CMS 類似,G1 中的並發標記包括多個階段,其中一些階段是並發的,另一些階段則會 STW。
-
Initial Mark (STW)
初始標記掃描並標記 GC Root 對象直接可達的老年代存活對象。
Initial Mark 並沒有獨立的執行階段,而是嵌入 YoungGC 中執行的,其停頓時間會被分攤,因此實際的開銷非常低。
-
Root Region Scan
掃描根區域掃描 Root Region 並標記所有可達的老年代存活對象。
此處的 Root Region 就是先前 YoungGC 中生成的 Survivor 區域,其包含的對象都會被視為 GC Root。
為了避免移動對象對標記產生影響,該過程必須在下次 YongGC 啟動前完成。
-
Concurrent Mark
並發標記啟動並發標記執行緒,掃描並標記整個堆中的存活對象(執行緒數可以通過 -XX:ConcGCThread 進行配置)。
為了避免重複標記,G1 使用 SATB
snapshot-at-the-beginning演算法解決漏標問題:應用執行緒對在 Concurrent Mark 執行期間進行的所有並發更新,都應保留先前的已知標記資訊。該約束是通過預寫屏障
pre-write barrier實現:Concurrent Mark 掃描過程中,當應用執行緒修改某個欄位時,會將先前的引用對象存儲在日誌緩衝區log buffers中,然後交由並發標記執行緒處理。為了避免移動對象對標記產生影響,該過程必須在下次 YoungGC 啟動前完成。所有的標記任務必須在堆滿前完成,如果堆滿前沒有完成標記任務,則會觸發擔保機制,經歷一次長時間的串列 FullGC。
-
Remark (STW)
重新標記啟動並行標記執行緒,完成對整個堆中存活對象的標記(執行緒數可以通過 -XX:ParallelGCThread 進行配置)。
該階段會暫停所有應用執行緒,避免發生引用更新,並完成對SATB 日誌緩衝區中剩餘對象的標記,找出所有未被訪問的存活對象。
該階段還執行一些額外的清理操作,例如:
- 卸載不可達的類(通過 -XX:+ClassUnloadingWithConcurrentMark 開啟)
- 處理引用對象(弱引用、軟引用、虛引用、最終引用)
-
Cleanup
清理垃圾整理統計資訊並識別出高收益的老年代分區,為 MixedGC 做準備。
主要工作有:
- RSet 梳理(後續說明)
- 識別回收收益高的老年代分區 (基於釋放空間和暫停目標)
- 直接回收的沒有活躍對象的空閑分區
此外還會執行一些清理工作,為下一次 Concurrent Marking 做好準備。
Mixed GC
MixedGC 主要流程與 YoungGC 類似,不同的地方在於 CSet 中包含了 Old 區域。
需要注意的是,Concurrent Marking 結束後,並不一定會立即觸發 MixedGC,中間可能會穿插多次的 YoungGC。
當收集某個區域時,我們必須知道是否有來自非收集區域引用,來確定它們的活動性:
- 從非收集區域到收集區域的 incoming reference 是重要的(被非收集區引用的對象必須存活)
- 從收集區域到非收集區域的 outgoing reference 是可忽略的(非收集區域不參與GC)
但查找整個堆非常耗時,同時也失去了增量收集的優勢。為了解決這一問題,G1 為每個區域維護了一個 RSetremembered set,用於記憶從其他區域指向自己的引用。
收集過程
在執行收集時,RSet 中引用資訊會扮演局部 GC Roots 的角色,避免耗時的引用查找,保證每個區域的 GC 能夠獨立進行:

注意,象如果 Old 區域中對在 Concurrent Marking 階段被確定為垃圾,即使有外部引用,該對象也會被作為垃圾回收。
接下來發生的事情與其他收集器所做的相同:多個並行GC執行緒找出哪些對象是活動的,哪些對象是垃圾:

最後,釋放空閑區域,將活動對象移到 Survivor 區域,並在必要時創建新對象:

RSet 維護
為了維護 RSet,在應用執行緒對欄位執行寫操作時,會觸發寫後屏障post-write barrier:
為了減少寫屏障帶來的開銷,該過程是非同步的:
Dirty Card Queue,然後由 Refine 執行緒將其拾取並將資訊傳播到被引用區域的 RSet。如果應用執行緒插入速度過快,會導致 Refine 執行緒來不及處理,那麼應用執行緒將接管 RSet 更新的任務,從而導致性能下降。
總結
並發標記 與 增量收集 是 G1 實現高性能與可預測回收的關鍵。
對於 CPU 資源充足且對延遲敏感的服務端應用來說,G1 演算法能夠在大堆上提供良好的響應速度。
作為代價,額外的寫屏障與更活躍GC執行緒,會對應用的吞吐量產生負面影響。
參考資料
- //www.oracle.com/technetwork/tutorials/tutorials-1876574.html
- //plumbr.io/handbook/garbage-collection-algorithms
- //medium.com/@hansrajchoudhary_88463/evolution-of-garbage-collection-on-java-garbage-first-garbage-collection-a3f39b1a9ae0
- //juejin.cn/post/6844903960550047757#heading-10
- //segmentfault.com/a/1190000021761004


