[python學習手冊-筆記]004.動態類型
004.動態類型
❝
本系列文章是我個人學習《python學習手冊(第五版)》的學習筆記,其中大部分內容為該書的總結和個人理解,小部分內容為相關知識點的擴展。
非商業用途轉載請註明作者和出處;商業用途請聯繫本人([email protected])獲取許可。
❞
基礎概念的解釋
首先我們來解釋一些基礎概念,看不懂的可以跳過,這對於初學者不是很重要。
強類型語言和弱類型語言
首先,強弱類型語言的區分不是看變數聲明的時候是否顯式的定義數據類型。
強類型語言,定義是任何變數在使用的時候必須要指定這個變數的類型,而且在程式的運行過程中這個變數只能存儲這個類型的數據。因此,對於強類型語言,一個變數不經過強制轉換,它永遠是這個數據類型,不允許隱式的類型轉換。比如java,python都屬於強類型語言。
強類型語言在編譯的時候,就可以檢查出類型錯誤,避免一些不可預知的錯誤,使得程式更加安全。
與之對應的是弱類型語言,在變數使用的時候,不嚴格的檢查數據類型,比如vbScript,數字12和字元串3進行連接,可以直接得到123。再比如C語言中int i = 0.0是可以通過編譯的。
另外知乎上關於相關問題 rainoftime 大神也有相關解答,沒有查到權威解釋,對大神的解答存疑,但是可以參考,幫助我們理解。
動態類型語言和靜態類型語言
動態類型和靜態類型的區別主要在數據類型檢查的階段。
動態類型語言:運行期間才去做數據類型的檢查。在動態類型語言中,不需要給變數顯式的指明其數據類型,該語言會在第一次賦值的時候,將內部的數據類型記錄下來。
靜態類型語言,在編譯階段就進行數據類型檢查。也就是說靜態類型語言,在定義變數的時候,必須聲明數據類型。
這裡有個比較經典的圖:
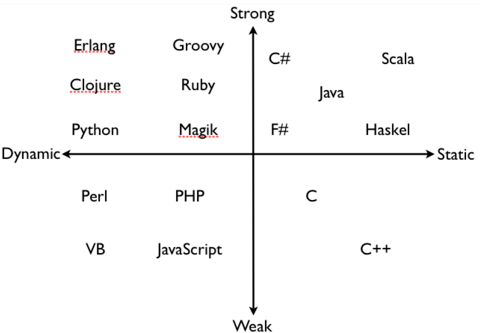
堆和棧
首先,堆兒(不好意思,這裡不應該帶兒化音…),堆(heap)和棧(stack)的概念在不同範疇是有不同含義的。
在數據結構中,堆指的是滿足父子節點滿足大小關係的一種完全二叉樹。棧指的是滿足後進先出(LIFO),支援pop和push兩種操作的一個「桶」(本來想說序列,但是不知道準不準確,所以說了個桶…)
在作業系統中,堆兒和棧指的是記憶體空間。
棧,和數據結構中的棧差不多,是一個LIFO隊列,由編譯器自動分配和釋放,主要用來存放函數的參數值,局部變數的值等內容。
堆,一般由程式設計師分配和釋放,當然,像java和python這類語言也有自動垃圾回收的機制。這個我們在後面會講到。
關於堆兒和棧的詳細解釋可以參考 Memory : Stack vs Heap
變數、對象和引用
python中的變數聲明是不需要顯式的指定類型的,但這並不表明python是一個弱類型語言。
比如,我們的一條簡單的賦值語句a=3,那麼接下來python編譯器會做哪些事情呢?
-
創建變數和字面量: -
創建一個字面量3(如果這個字面量還沒有被創建過的情況下) -
創建一個名稱叫a的變數。一般我們理解在這個變數a第一次被賦值的時候就創建了它。(實際python解釋器在運行程式碼之前就會檢測變數名)
-
-
檢查變數類型: -
python中類型是針對對象而言的,並不是針對變數名而言的。 對象會包含兩個重要的頭部資訊,一個是類型標誌符,一個是引用計數器。 -
變數名並不會限制變數的類型。也就是說這個 a它只是一個名字,具體「關聯」什麼類型的變數,這個是沒有限制的。
-
-
變數的使用 -
當變數出現在表達式中的時候,它就會被當前引用的對象所代替。 -
還是說這個例子,如果在之後的程式碼中使用了a,比如 a+1那麼這裡的a就會被指向3這個字面量
-
簡單總結,當我們執行a=3的時候,實際做了三件事:
-
創建一個對象實例,3 -
創建一個變數,a -
將變數名a引用到對象實例3上

這裡提到了一個概念,引用。 引用其實就是一種關係,是通過記憶體中的指針所實現的。
好嘞,這裡又出現了一個新的概念,指針。 指針這個東西,簡單來說可以理解為記憶體地址的一個指向。就是對初學者不好解釋(主要是我懶得解釋,就是屬於那種懂的不需要講,不懂的一時半會講了也是不懂,但是隨著學習的深入,慢慢就理解了的東西。。。)
變數的類型
首先,python是一個強類型語言,這是毫無疑問的。 但是python不需要顯式的聲明變數類型。 這是因為python的類型是記錄在對象實例中的。
在前面我們講到過,python中的對象會包含兩個重要的頭部資訊:
-
類型標誌符(type designator):用來標識這個對象的類型 -
引用計數器(reference counter): 表明有多少個變數引用到了這個對象上,用於跟蹤改對象應該何時被回收
因為對象的這個機制,python中的變數聲明的時候,就不需要再指定類型了。 也就是說變數名與變數類型是無關的。
a=1
a='spam'
a=1.123
而且如上所示,同一個變數名可以賦值給不同類型的對象實例。
共享引用
這裡提出一個問題,如下程式碼:
In [6]: a=3
In [7]: b=a
In [8]: a='spam'
那麼在經過這一系列操作之後,a和b的值分別是啥?
In [9]: a
Out[9]: 'spam'
In [10]: b
Out[10]: 3
首先我們來看,在執行a=3和b=a之後,發生了什麼

a=3根據之前的介紹,比較好理解了。b=a實際上變數名b只是複製了a的引用,然後b也引用到了對象實例3上。那在之後這一句a='spam'又發生了什麼?

這個圖就說的很清楚了,在我們執行了a='spam'之後,a被指向了另外一個對象。
搞清楚了這個之後,我們再來看下一個例子:
a=3
b=a
a=a+3
這個前兩句就不需要解釋了,第三句a=a+3 其實一眼就可以看出來,此時a是6。這個就涉及到前面說的,當a出現在表達式中的時候,它就會「變成」它所引用的對象實例。a=a+3也就是會變成3+3 計算後得出新的對象實例6,然後變數a引用到6這個對象上。
「在原位置修改」
關於共享引用,這裡看一個特殊的例子:
In [16]: L1=[1,2,3]
In [17]: L2=L1
In [18]: L1[0]=1111
In [19]: L1
Out[19]: [1111, 2, 3]
In [20]: L2
Out[20]: [1111, 2, 3]
按照之前的劇本,L2和L1都是指向列表[1,2,3]這個對象的,那為什麼在我們修改L1[0] 這個元素之後,為什麼L2也跟著發生變化了呢?
我自己畫了圖,從這個圖可以看出來,實際上對於L1和L2的共享引用來看,並沒有違反我們上面說的共享引用的原則。只是對於序列中元素的修改,L1[0]會在原位置覆蓋列表對象中的某部分值。
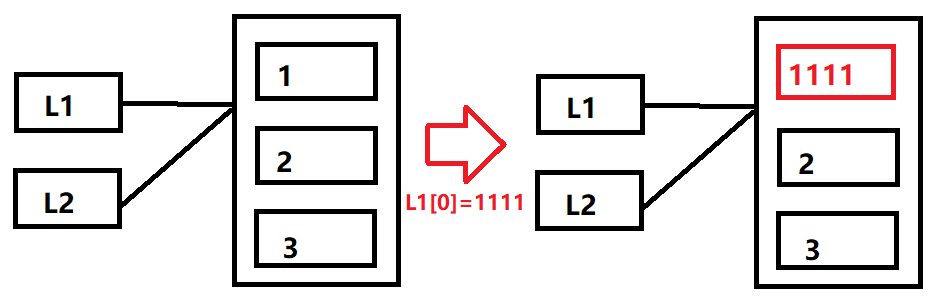
那麼問題來了如果在修改L1[0]之後,並不想L2的值受到影響,那該怎麼辦?
簡單
把列表原原本本的複製一份就好了。 複製的辦法有三種:
第一種針對列表而言,可以直接創建一個完整的切片,本質上是一種淺拷貝。
In [32]: L1=[[1,2,3],4,5,6]
In [33]: L2=L1[:]
In [34]: L2
Out[34]: [[1, 2, 3], 4, 5, 6]
In [37]: L1[2]='aaa'
In [38]: L2
Out[38]: [[1111, 2, 3], 4, 5, 6]
In [39]: L1
Out[39]: [[1111, 2, 3], 4, 'aaa', 6]
第二種,淺拷貝,如下面這個例子中的D1.copy()
In [26]: D1={a:[1,2,3],b:3}
In [27]: import copy
In [28]: D2=D1.copy()
In [29]: D2
Out[29]: {6: [1, 2, 3], 3: 3}
In [30]: D1[a][0]=1111
In [31]: D2
Out[31]: {6: [1111, 2, 3], 3: 3}
第三種,深拷貝,如下D2=copy.deepcopy(D1)
In [41]: import copy
In [45]: D1={'A':[1,2,3],'B':'spam'}
In [46]: D1
Out[46]: {'A': [1, 2, 3], 'B': 'spam'}
In [47]: D2=copy.deepcopy(D1)
In [48]: D2
Out[48]: {'A': [1, 2, 3], 'B': 'spam'}
In [49]: D1['A'][0]=1111
In [50]: D1
Out[50]: {'A': [1111, 2, 3], 'B': 'spam'}
In [51]: D2
Out[51]: {'A': [1, 2, 3], 'B': 'spam'}
我相信,看到這裡,對於深拷貝和淺拷貝有些讀者已經明白了,但是有些讀者還是迷糊的。 這裡簡單說一下,
-
淺拷貝:只拷貝父對象,不會拷貝對象內部的子對象。
-
深拷貝:完全拷貝父對象和子對象。


更詳細的內容見: Python 直接賦值、淺拷貝和深度拷貝解析
「關於相等」
先看一個例子
In [59]: L1=[1,2,3]
In [60]: L2=L1
In [61]: L1==L2
Out[61]: True
In [62]: L1 is L2
Out[62]: True
In [66]: L1=[1,2,3]
In [67]: L2=[1,2,3]
In [68]: L1==L2
Out[68]: True
In [69]: L1 is L2
Out[69]: False
從上面這個例子就可以看出來,==比較的是值,is 實際比較的是實現引用的指針。
對象的垃圾收集和弱引用
垃圾回收機制也是一件很複雜的事情,但是python編譯器可以自己去處理這玩意兒。 所以在初級階段,我們不需要過多關注這玩意兒。 知道有這麼個東西就夠了。
這裡簡單的介紹下,python中的垃圾回收就是我們所謂的GC,靠的是對象的引用計數器。引用計數器為0的時候,這個對象實例就會被釋放。對象的引用計數器可以通過sys.getrefcount(istance)來查看。
In [70]: import sys
In [72]: sys.getrefcount(1)
Out[72]: 2719
引用計數器的引入可以很好的跟蹤對象的使用情況,但是在某些情況下,也可能會帶來問題。 比如循環引用的問題。
如下程式碼:
In [73]: L =[1,2,3]
In [74]: L.append(L)
當然,正常人肯定不會寫出這種智障程式碼,但是在一些複雜的數據結構中,子對象互相引用,就可能會造成死鎖。比如:
In [1]: class Node:
...: def __init__(self):
...: self.parent=None
...: self.child=None
...: def add_child(self,child):
...: self.child=child
...: child.parent=self
...: def __del__(self):
...: print('deleted')
...:
這裡我們定義了一個簡單的類。這時,如果我們創建一個節點,然後刪除它,可以看到,對象被回收,並且準確的列印出了deleted。
In [2]: a=Node()
In [3]: del a
deleted
那麼,像下面這個例子,在刪除a節點之後,貌似沒有觸發垃圾回收,只有手動的gc之後,這兩個對象實例才被刪除。
在刪除a之後,沒有觸發垃圾回收,是因為它倆互相引用,實例的引用計數器並沒有置0 。
那在手動gc之後,由於python的gc會檢測這種循環引用,並刪除它。
In [4]: a=Node()
In [5]: a.add_child(Node())
In [6]: del a
In [7]: import gc
In [8]: gc.collect()
deleted
deleted
Out[8]: 356

那麼如果使用弱引用的話,效果就不一樣了
In [9]: import weakref
...:
...: class Node:
...: def __init__(self):
...: self.parent=None
...: self.child=None
...: def add_child(self,child):
...: self.child=child
...: child.parent=weakref.ref(self)
...: def __del__(self):
...: print('deleted')
...:
In [10]: a=Node()
In [11]: a.add_child(Node())
In [12]: del a
deleted
deleted
所以這裡就可以看出來,所謂弱引用,其實並沒有增加對象的引用計數器,即使弱引用存在,垃圾回收器也會當做沒看見。
弱引用一般可以拿來做快取使用,對象存在時可用,對象不存在的時候返回None。這正符合快取有則使用,無則重新獲取的性質。


