基於時序數據,推動智慧運維發展
基於IT 健康分析的智慧運維新趨勢
隨著 IT 技術的發展與普及,各類資訊化系統正日趨成為工業製造領域不可或缺的基礎能力,推動著業務部門、工廠產線的高效運行,因此對資訊化系統的高品質運維,是工業製造企業保持高效生產的關鍵。傳統上,企業 IT 運維是通過系統指標的變化,例如處理器 / 記憶體使用率、磁碟吞吐量等,由人工判斷系統是否存在問題與隱患。隨著企業資訊化系統日趨多樣, 加之軟硬體平台不再緊密耦合,單一系統可能存在多個廠商的硬體與服務,因此資訊化系統的複雜程度正呈指數化增長,給工業製造企業的 IT 部門帶來了巨大的挑戰。
雖然許多企業已經部署了自動化的運維監控系統,並基於專家規則對異常指標進行告警,但這種藉助經驗構建的系統,無法讓運維人員通過告警資訊即時進行原因分析。而通過專家後期採集、分析整套系統的數據,又往往需要很長時間。同時,由於技術能力的差異,專家對監控指標的分析結論也會有差別, 為系統異常的及時甄別與處理埋下隱患。
在英特爾與南京基石數據技術有限責任公司(以下簡稱 「基石數據」)看來,要根本解決這一問題,需要從運維生態入手,
針對設備日誌、運行數據等時序數據建模,建立 「IT 健康分析」 系統來發現存在的系統隱患,進而推送給運維部門或者專門的優化部門進行優化改進,並能夠通過經驗積累實現自我優化。
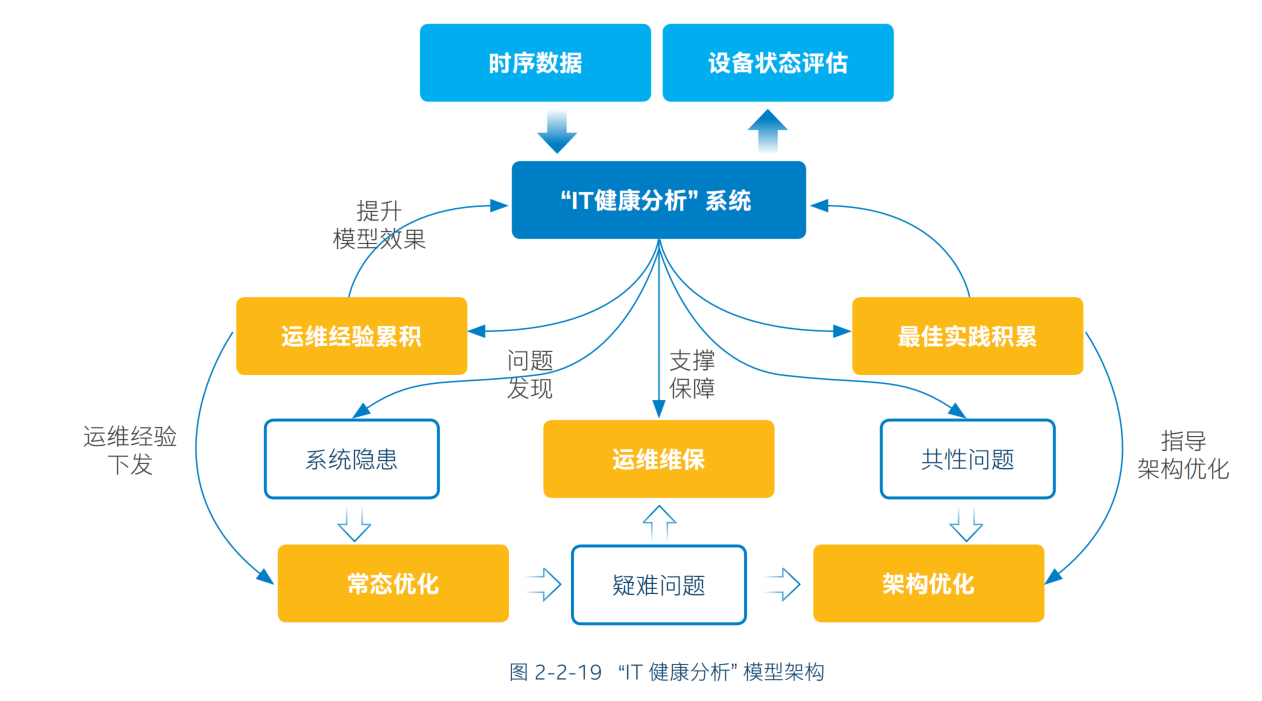
如圖 2-2-19 所示,藉助基於時序數據構建的 「IT 健康分析」系統,企業一方面可以及時發現系統隱患,並通過常態優化或架構優化來予以修復;另一方面,模型也可對資訊化系統的運維維保進行支撐,並通過運維經驗和最佳實踐的積累,來不斷自我完善和優化。而要構建這樣的系統,工業製造企業需要解決三個方面的問題。
- 引入高精度、高效率的智慧分析模型作為系統核心,減少運維繫統對人力,尤其是對專家的依賴;
- 為智慧分析模型提供強有力的硬體基礎設施,特別是高性能計算力的輸入;
- 以合理的系統架構設計,保證充分的計算、分析能力能 「 下放」 到運維一線。
基於以上分析,英特爾與基石數據首先引入 AI、大數據等技術, 通過機器學習、深度學習方法來建立智慧模型,對複雜的時序指標數據進行分析並判別系統的運行狀態。基於海量數據訓練出的智慧分析模型,不僅有著更勝於專家系統的準確率和效率, 更能大幅減少運維工作所需的人力,提高運維效率。一項統計數據表明,通過智慧模型來預測系統狀態變化,工作可以在秒級內完成,且分析準確率超過 98%。
為了使 「IT 健康分析」 系統和智慧分析模型發揮更大效能,英特爾為之提供了多種先進軟硬體產品與框架,為智慧分析模型的訓練推理過程提供強勁算力和工具。同時,新方案還引入了「雲邊協同」 的新架構,一方面,通過就近部署智慧分析模型, 提升運維能力的實時性;另一方面,利用雲端的專家知識庫, 對發現的問題進行閉環管理,展開問題溯源與優化方案編製, 並將優化方案回饋回現場。
現在,這一全新的系統方案正廣泛地在 「 資料庫健康狀態評估」、「網路安全風險預警」 等實際場景中開展實踐,並取得了良好的應用效果。
基石數據以機器健康模型,提升企業資料庫運維效率
■ 項目背景
作為 IT 系統的核心組件之一,資料庫的健康對於企業資訊化系統的高效運行至關重要。傳統上,運維工程師需要通過資料庫管理系統 (Database Management System,DBMS)等工具,以人工方式對資料庫進行統一的管理、控制和調配。但這種方式既繁瑣又缺乏效率,尤其當企業資訊化系統變得更為複雜,且與業務緊密關聯時,配置優化效果將直接影響企業生產的效率。以產線自動化監控系統為例,通過高清攝影機採集的產線影像需要在資料庫中暫存後再送至後端處理,在這種高吞吐量的場景中,如何設置資料庫的快取機制,如何在阻塞發生前啟動相關 Session 的處理等,都會直接影響該產線的生產效率和產品品質。

基石數據推出的機器健康模型能有效應對以上挑戰。這一模型利用資料庫豐富的時序化監控數據,例如連接狀態、處理器 / 記憶體使用率、磁碟讀寫時延、快取大小、等待時間等,通過機器學習或深度學習的方法進行訓練,並得到合理的資料庫健康預測得分,進而幫助運維人員制定相應策略。
同時,這一健康預測方法,也是英特爾與基石數據合作開展的 「IT 健康分析」 系統在資料庫智慧運維領域的重要落地,部署在邊緣的資料庫健康預測系統所得到的預測結果,可以與雲端的 D-Smart 運維知識自動化系統形成交互,對方案實施迭代優化。
■ 基石數據機器健康模型方案描述
基石數據機器健康模型方案基本架構如圖 2-2-20 所示,貼近電網管線、電力生產等一線部署的機器健康模型,由數據預處理、模型訓練 & 驗證以及預測系統幾部分組成,可以使用訓練數據,通過特定演算法訓練模型,並利用測試數據對模型效果進行驗證,迭代優化模型。最終的預測結果將傳送到位於雲端的 D-Smart 運維知識庫,並可以對接內外部專家系統、廠商支撐、系統優化團隊以及專門的 IT 系統健康管理團隊,根據預測結果對資料庫狀況進行分析,開展進一步優化。
機器健康模型會對資料庫當前的健康狀態進行評價打分,並預測未來一段時間內的健康得分。因此如圖2-2-21所示,模型的輸入數據X包括了會話連接狀態、處理器/記憶體使用率、磁碟讀寫時延、快取大小等具有時序特徵的資料庫監控數據,輸出Y則是資料庫的健康得分,包括當前分數和未來時間的預測分。分數為百分制,如96分。模型需要通過健康得分(標籤)來調整優化模型的參數,因此模型採用的是監督學習的方法。

模型首先從一線數據中獲得供訓練和測試使用的數據集,這些數據已經預先打好標籤,並按照 80%:20% 的訓練與測試比例進行劃分。如圖2-2-22所示,方案中針對資料庫運維的健康模型使用了7類68個維度的指標,並預先設定了各個指標的健康度得分。由此,系統可以得到一組以時間序列排列的資料庫健康得分數據。

在獲取數據集之後,系統首先進行缺失值處理。數據集中的缺失值會帶來雜訊,從而對最後的預測結果造成偏差,因此方案採用了平均值填充或上下值填充的方式來予以處理。前者是將均值填入缺失值,後者是將前一個值或後一個值填入缺失值, 不同缺失值填充方法會對預測結果造成差異,一般建議每行數據如果缺失率小於0.6則填充平均值。示例程式碼如下:

特徵選擇是數據預處理環節中的重要步驟,進行合理的特徵選擇可以降低維度,查找和選擇最有用的特徵,提高模型的可解釋性。另外,特徵選擇還能減少不必要的計算量,加快訓練速度,同時降低模型方差,提高泛化效果。
在特徵選擇過程中,首先需要查找高度相關的特徵,在機器學習方法中,這類特徵可能會導致模型在測試集上的泛化能力下降。其次是計算特徵的重要性。示例程式碼如下:

在使用梯度下降一類的機器演算法中,如果能保證不同特徵的取值在相同或相近的範圍內,比如都處於 0-1 之間,那麼梯度下降演算法會收斂的很快。因此在數據預處理的最後,方案對數據進行了特徵縮放處理。
經過預處理的數據集需要選擇合適的演算法進行訓練,方案根據資料庫時序數據的特點選擇多種演算法進行了比較,包括支援向量回歸(Support Vactor Regression,SVR)演算法、RNN- LSTM 演算法,GBDT 演算法、XGBoost 演算法以及隨機森林演算法等。通過驗證比較表明,在時序化的資料庫健康預測環境中, XGBoost 以及隨機森林演算法的預測準確度和效率較高。
在上述過程中,機器健康模型選擇了英特爾® 至強® 可擴展處理器來為整個訓練推理過程提供強勁算力。這一系列的處理器不僅集成了更多的內核和執行緒,對微架構也進行了全面升級優化,並配備了更快、效率更高的高速快取來提升處理效能。同時,其集成的英特爾® DL Boost 技術,對 INT8 數值類型數據有著更好的支援,可大幅提升方案的模型推理速度。
■ 方案成效
通過在多個電力系統生產環境中的實際部署,驗證了採用XGBoost 或隨機森林演算法的機器健康模型可對資料庫健康狀況進行有效預測。如圖 2-2-23 所示,上圖是模型預測結果, 下圖是實際情況,兩者的均方誤差(Mean Squared Error, MSE)為 0.28,而在採用 XGBoost 演算法的情況下,均方誤差可進一步縮減到 0.218。同時,得益於基於英特爾 ® 架構的處理器的強大算力,兩種演算法的訓練時間均在數秒內,滿足了工業製造企業預測實時性的要求。

利用機器健康模型,及以其為核心的 「IT 健康分析」 系統,基石數據針對某電力企業省級公司的 20 多套系統進行了IT 健康分析巡檢,僅在一個多月時間裡,就發現問題 143 個,並全部完成溯源工作。同時,利用預測結果,用戶還通過系統配置 調整、SQL 調整、參數調整等方法,提升了系統性能,使一體化電量與線損系統、數據管理服務、結構化數據中心等與業 務息息相關的核心資訊化系統的健康分,由不足 80 分上升至90 分以上,獲得了從管理層到生產一線的一致好評。

