EMNLP 2019 | 大規模利用單語數據提升神經機器翻譯
- 2019 年 11 月 22 日
- 筆記
作者 | 吳酈軍、夏應策
來源 | 微軟研究院AI頭條(ID:MSRAsia)
編者按:目前,目標語言端的無標註單語數據已被廣泛應用於在機器翻譯任務中。然而,目標語言端的無標註數據一旦使用不當,反而會給模型結果帶來負面影響。為了有效利用大規模源語言端和目標語言端的單語數據,微軟亞洲研究院在 EMNLP 2019 上發表的論文中,提出一種簡單的語料數據使用流程,只需要四個步驟就能極大地提高模型翻譯結果。
在機器翻譯任務中,如何利用好大規模的單語語料數據來輔助翻譯模型的訓練是非常重要的研究方向。目前,目標語言端的無標註單語數據已經被證實能夠極大的提升模型的翻譯品質,並被廣泛利用,最著名的就是反向翻譯技術 BT(back-translation)。相比之下,源語言端的無標註單語數據則並沒有被很好地利用。為此,我們在這個工作中進行了系統的研究,來闡明如何能夠同時利用好源語言端和目標語言端的無標註單語數據,並且我們提出了一種非常有效的數據使用流程,只包括簡單的四個步驟就能極大地提高模型翻譯結果。通過在 WMT 英德互譯和 WMT 德法互譯任務上的實驗,我們驗證了所提出演算法的有效性,同時取得了非常優越的性能。
無標註單語數據的有效性
我們首先嘗試驗證對於兩個方向(源語言端 X、目標語言端 Y)無標註單語數據在大規模語料下的有效性,對於兩種單語數據,常見的方法為:
1) 對於目標語言端的單語數據 y,常用的方法為反向翻譯技術 BT(back-translation),即我們會使用一個 Y->X 的反向翻譯模型來翻譯 y 得到對應的結果 x',然後將(x', y)作為偽雙語數據參與訓練 X->Y 模型;
2) 而對於源語言端的單語數據 x,常用的方法為正向翻譯技術 FT(forward-translation),即我們使用正向的翻譯模型 X->Y 來翻譯 x 得到對應的結果 y',然後將(x, y')作為偽雙語數據參與訓練 X->Y 模型。
我們在不同的大規模數據量(20M、60M、120M單語數據)下進行實驗,發現了如下實驗現象:

圖1:單語數據量的增加導致翻譯模型性能的變化
1) 當只有目標語言端單語數據的時候,隨著單語數據的量越來越多,BT 所帶來的模型性能呈現出先上升後下降的趨勢,並且下降速度非常快(如圖(a)所示)。
2) 當只有源語言端的單語數據的時候,隨著單語數據的量越來越多,FT 所帶來的模型性能呈現緩慢下降的趨勢,不過下降速度比 BT 略小(如圖(b)所示)。
這樣的實驗結果說明單獨使用大量的某一端單語數據並不是一個好的策略,相反這樣的方式反而會給模型結果帶來負面影響。我們也分析了其中的部分原因,比如目標端單語數據產生的偽雙語數據是來源於另一個方向的翻譯模型,數據品質並不可控,所以大量的偽單語數據則會使得模型訓練產生了偏差。因此,我們需要找到一種合適有效的方式來利用大規模的單語數據。
演算法與流程
假設我們關注的是 X 和 Y 語言之間的互譯,給定的有標雙語數據集為 B,我們希望得到的是 X->Y 和 Y->X 兩個翻譯模型,分別記做 f 和 g。同時,我們需要準備兩份無標註單語數據 Mx 和 My,分別對應 X 和 Y 兩種語言。我們提出了一個清晰的數據使用和訓練流程,將兩端的無標註單語數據都進行了利用。我們提出的演算法包括如下的四步:

圖2:數據使用和訓練流程
(1)有標雙語模型預訓練:我們首先在雙語數據 B 上訓練得到 X->Y 方向的翻譯模型 f,和 Y->X 方向的翻譯模型 g。同時我們會用不同的隨機種子再次訓練得到兩個新模型 f' 和 g'(為了在第四步中使用)。
(2)無標註數據翻譯:我們將 Mx 中的每一個句子 x 用模型 f 翻譯到 Y 語言,對 My 中的句子 y 用模型 g 翻譯到 X 語言,得到兩個新的偽標註數據集合 Bs={(x, f(x))|x∈Mx}, Bt={(g(y),y)|y∈My}。
(3)有雜訊訓練:我們在數據集 B、Bs 和 Bt 的源語言端都加上雜訊,加雜訊的方式包括:a)隨機將單詞替換為<UNK>;b)隨機丟棄句子中的某些詞語;c)隨機打亂句子中連續的 k 個單詞順序。在新的有雜訊的數據集上,我們訓練對應的模型 f1:X->Y 和 g1:Y->X。在此階段,我們建議使用大規模的無標註數據。
(4)微調:最後,在得到 f1 和 g1 之後,我們用第一步中訓練得到的新的雙語模型 f' 和 g' 來重新翻譯 Mx 和 My 中的部分無標註數據,得到新的 Bs' 和 Bt' 數據集,然後在這份數據上再將 f1 和 g1 微調成最終所需要的模型。
實驗及結果
我們在 WMT 英語和德語的雙向翻譯,以及 WMT 德語和法語之間的互相翻譯任務上進行了實驗驗證。我們採用的模型是 Transformer Big 模型,在第三階段,我們選用了120M(兩邊分別60M)的無標註單語數據,第四階段,使用40M(兩邊分別20M)無標註的單語數據進行微調。評測所採用的指標為 SacreBLEU score。我們得到的實驗結果如表1和表2所示,具體結果如下:
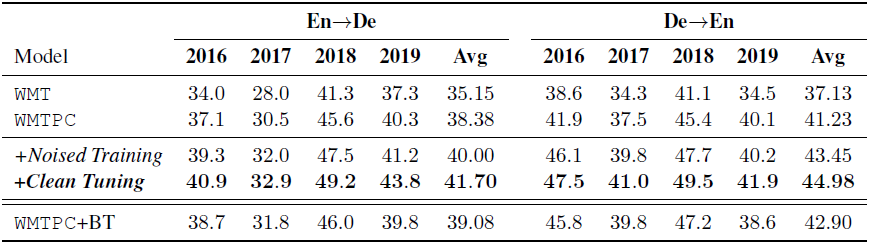
表1:WMT 英德互譯上的 SacreBLEU 結果

表2:WMT 德法互譯上的 SacreBLEU 結果
可以看出,我們的模型在每一步訓練階段,結果都會有一定提高,如第三步有雜訊訓練階段取得了2個點的 BLEU 提升,而在第四階段微調階段又取得了至少1.5個點的 BLEU 提升。
同時我們和目前已經存在的最好方案進行了對比,我們的模型取得了當下最好的翻譯結果(表3和表4所示)。

表3:WMT 英德上方案比較

表4:WMT 德英上方案比較
最後我們對流程中的每一部分也進行了一定的分析,比如不同的語料使用的結果(圖3(a)),有雜訊數據和隨機 sample 的數據上的訓練結果(圖3(b)),以及不同的數據微調方式的結果(圖3(c)),得到的結論證明我們的使用方法確為最優方案。

圖3:WMT 英德上針對不同流程的實驗結果
總結
在這篇文章中,我們提出了一種簡單高效的無標註單語語料的數據使用和模型訓練流程,只包含了簡單的四個步驟,並且對不同的無標註單語語料的使用方案進行了詳細的討論和對比。另外我們還驗證了如下結論:(1)只使用源語言端或者目標語言端無標註單語數據,效果不會隨著數據量的增加而增加;(2)源語言端和目標語言端的無標註單語數據組合在一起使用時作用是最大的,實驗效果會隨著數據的增多而得到提升;(3)有雜訊訓練這一階段對提升最終性能有明顯的幫助。


