數倉架構發展史
主要內容
發展史
時代的變遷,生死的輪迴,歷史長河滔滔,沒有什麼是永恆的,只有變化才是不變的,技術亦是如此,當你選擇互聯網的那一刻,你就相當於乘坐了一個滾滾向前的時代列車,開往未知的方向,不論什麼樣的技術架構只有放在當前的時代背景下,才是有意義的,人生亦是如此。
時間就是一把尺子,它能衡量奮鬥者前進的進程;時間就是一架天平,它能衡量奮鬥者成果的重量;時間就是一架穿梭機,它能帶我們遨遊歷史長河,今天我們看一下數倉架構的發展,來感受一下歷史的變遷,回頭看一下那些曾經的遺迹。準備好了嗎 let’s go!,在此之前我們先看一下,數據倉庫在整個數據平台中的地位
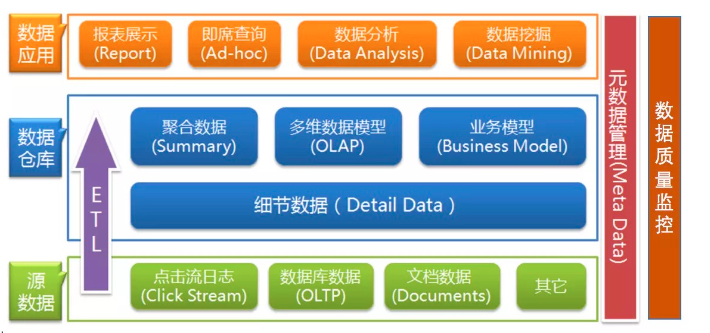
開始之前,我們先上一張大圖,先有一個大概的認知,從整體到局部從概括到具體,看一下導致機構變化的原因是什麼,探究一下時代背景下的意義,我們順便看一下什麼是數倉

那麼什麼是數倉,數據倉庫是一個面向主題的(Subject Oriented)、集成的(Integrate)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用於支援管理決策,數據倉庫在數據平台中的建設有兩個環節:一個是數據倉庫的構建,另外一個就是數據倉庫的應用。
數據倉庫是伴隨著企業資訊化發展起來的,在企業資訊化的過程中,隨著資訊化工具的升級和新工具的應用,數據量變的越來越大,數據格式越來越多,決策要求越來越苛刻,數據倉庫技術也在不停的發展 這就是架構升級的原因,其實就是外部環境變了,現有的體系不能滿足當前的需求,既然找到了原因,我們就來欣賞一下歷史長河中哪些閃亮的星

「我們正在從IT時代走向DT時代(數據時代)。IT和DT之間,不僅僅是技術的變革,更是思想意識的變革,IT主要是為自我服務,用來更好地自我控制和管理,DT則是激活生產力,讓別人活得比你好」
——阿里巴巴董事局主席馬雲。
經典數倉
在開始之前,我們先說一點,其實數據倉庫很早之前就有了,也就是說在離線數倉之前(基於大數據架構之前),有很多傳統的數倉技術,例如基於Teradata的數據倉庫,只不過是數據倉庫技術在大數據背景下發生了很多改變,也就是我們開始拋棄了傳統構建數倉的技術,轉而選擇了更能滿足當前時代需求的大數據技術而已,當然大數據技術並沒有完整的、徹底的取代傳統的技術實現,我們依然可以在很多地方看見它們的身影
經典數倉可以將數倉的數倉的不同分層放在不同的資料庫中,也可以將不同的分層放在不同的資料庫實例上,甚至是可以把不同的分層放在不同的機房
大數據技術改變了數倉的存儲和計算方式,當然也改變了數倉建模的理念,例如經典數倉數據存儲在mysql等關係型資料庫上,大數據數倉存儲在hadoop平台的hive中(實際上是HDFS中),當然也有其他的數倉產品比如TD、greenplum等。
離線數倉(離線大數據架構)
隨著互聯網時代來臨,數據量暴增,開始使用大數據工具來替代經典數倉中的傳統工具。此時僅僅是工具的取代,架構上並沒有根本的區別,可以把這個架構叫做離線大數據架構。
隨著數據量逐漸增大,事實表條數達到千萬級,kettle等傳統ETL工具逐漸變得不穩定,資料庫等存儲技術也面臨著存儲緊張,每天都陷入和磁碟的爭鬥中單表做拉鏈的任務的執行時間也指數級增加,這個時候存儲我們開始使用HDFS而不是資料庫;計算開始使用HIVE(MR)而不是傳統數倉技術架構使用的kettle、Informatica 等ETL工具;
公司開始考慮重新設計數倉的架構,使用hadoop平台的hive做數據倉庫,報表層數據保存在mysql中,使用tableau做報表系統,這樣不用擔心存儲問題、計算速度也大大加快了。在此基礎上,公司開放了hue給各個部門使用,這樣簡單的提數工作可以由運營自己來操作。使用presto可以做mysql、hive的跨庫查詢,使用時要注意presto的數據類型非常嚴格。

Lambda架構
後來隨著網路技術、通訊技術的發展,使得終端數據的實時上報傳輸成為可能,從而業務實系統發生變化,進而導致了我們對需求的時性要求的不斷提高開始之前我們先看一下,網路技術和通訊技術到底對我們的生活有什麼樣的影響

為了應對這種變化,開始在離線大數據架構基礎上加了一個加速層,使用流處理技術直接完成那些實時性要求較高的指標計算,然後和離線計算進整合從而給用戶一個完整的實時計算結果,這便是Lambda架構。

為了計算一些實時指標,就在原來離線數倉的基礎上增加了一個實時計算的鏈路,並對數據源做流式改造(即把數據發送到消息隊列),實時計算去訂閱消息隊列,直接完成指標增量的計算,推送到下游的數據服務中去,由數據服務層完成離線&實時結果的合併。
需要注意的是流處理計算的指標批處理依然計算,最終以批處理為準,即每次批處理計算後會覆蓋流處理的結果(這僅僅是流處理引擎不完善做的折中),Lambda架構是由Storm的作者Nathan Marz提出的一個實時大數據處理框架。Marz在Twitter工作期間開發了著名的實時大數據處理框架Storm,Lambda架構是其根據多年進行分散式大數據系統的經驗總結提煉而成。Lambda架構的目標是設計出一個能滿足實時大數據系統關鍵特性的架構,包括有:高容錯、低延時和可擴展等。Lambda架構整合離線計算和實時計算,融合不可變性(Immunability),讀寫分離和複雜性隔離等一系列架構原則,可集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數據組件。
如果拋開上面的Merge 操作,那麼Lambda架構就是兩條完全不同處理流程,就像下面所示

存在的問題
同樣的需求需要開發兩套一樣的程式碼,這是Lambda架構最大的問題,兩套程式碼不僅僅意味著開發困難(同樣的需求,一個在批處理引擎上實現,一個在流處理引擎上實現,還要分別構造數據測試保證兩者結果一致),後期維護更加困難,比如需求變更後需要分別更改兩套程式碼,獨立測試結果,且兩個作業需要同步上線。
資源佔用增多:同樣的邏輯計算兩次,整體資源佔用會增多(多出實時計算這部分)·
實時鏈路和離線鏈路計算結果容易讓人誤解,昨天看到的數據和今天看到的數據不一致**
下游處理複雜,需要整合實時和離線處理結果,這一部分往往是我們在呈現給用戶之前就完成了的
Kappa架構
再後來,實時的業務越來越多,事件化的數據源也越來越多,實時處理從次要部分變成了主要部分,架構也做了相應調整,出現了以實時事件處理為核心的Kappa架構。當然這不要實現這一變化,還需要技術本身的革新——Flink,Flink 的出現使得Exactly-Once 和狀態計算成為可能,這個時候實時計算的結果保證最終結果的準確性
Lambda架構雖然滿足了實時的需求,但帶來了更多的開發與運維工作,其架構背景是流處理引擎還不完善,流處理的結果只作為臨時的、近似的值提供參考。後來隨著Flink等流處理引擎的出現,流處理技術很成熟了,這時為了解決兩套程式碼的問題,LickedIn 的Jay Kreps提出了Kappa架構
Kappa架構可以認為是Lambda架構的簡化版(只要移除lambda架構中的批處理部分即可)。在Kappa架構中,需求修改或歷史數據重新處理都通過上游重放完成。

Kappa架構的重新處理過程

選擇一個具有重放功能的、能夠保存歷史數據並支援多消費者的消息隊列,根據需求設置歷史數據保存的時長,比如Kafka,可以保存全部歷史數據,當然還有後面出現的Pulsar,以及專門解決實時輸出存儲的Pravega
當某個或某些指標有重新處理的需求時,按照新邏輯寫一個新作業,然後從上游消息隊列的最開始重新消費,把結果寫到一個新的下游表中。
當新作業趕上進度後,應用切換數據源,使用新產生的新結果表。停止老的作業,刪除老的結果表。
存在的問題
Kappa架構最大的問題是流式重新處理歷史的吞吐能力會低於批處理,但這個可以通過增加計算資源來彌補
Pravega(流式存儲)
想要統一流批處理的大數據處理架構,其實對存儲有混合的要求
對於來自序列舊部分的歷史數據,需要提供高吞吐的讀性能,即catch-up read對於來自序列新部分的實時數據,需要提供低延遲的 append-only 尾寫 tailing write 以及尾讀 tailing read

存儲架構最底層是基於可擴展分散式雲存儲,中間層表示日誌數據存儲為 Stream 來作為共享的存儲原語,然後基於 Stream 可以向上提供不同功能的操作:如消息隊列,NoSQL,流式數據的全文搜索以及結合 Flink 來做實時和批分析。換句話說,Pravega 提供的 Stream 原語可以避免現有大數據架構中原始數據在多個開源存儲搜索產品中移動而產生的數據冗餘現象,其在存儲層就完成了統一的數據湖。

提出的大數據架構,以 Apache Flink 作為計算引擎,通過統一的模型/API來統一批處理和流處理。以 Pavega 作為存儲引擎,為流式數據存儲提供統一的抽象,使得對歷史和實時數據有一致的訪問方式。兩者統一形成了從存儲到計算的閉環,能夠同時應對高吞吐的歷史數據和低延時的實時數據。同時 Pravega 團隊還開發了 Flink-Pravega Connector,為計算和存儲的整套流水線提供 Exactly-Once 的語義。
混合架構
前面介紹了Lambda架構與Kappa架構的含義及優缺點,在真實的場景中,很多時候並不是完全規範的Lambda架構或Kappa架構,可以是兩者的混合,比如大部分實時指標使用Kappa架構完成計算,少量關鍵指標(比如金額相關)使用Lambda架構用批處理重新計算,增加一次校對過程。
Kappa架構並不是中間結果完全不落地,現在很多大數據系統都需要支援機器學習(離線訓練),所以實時中間結果需要落地對應的存儲引擎供機器學習使用,另外有時候還需要對明細數據查詢,這種場景也需要把實時明細層寫出到對應的引擎中。
還有就是Kappa這種以實時為主的架構設計,除了增加了計算難度,對資源提出了更改的要求之外,還增加了開發的難度,所以才有了下面的混合架構,可以看出這個架構的出現,完全是處於需求和處於現狀考慮的

實時數倉
實時數倉不應該成為一種架構,只能說是是Kappa架構的一種實現方式,或者說是實時數倉是它的一種在工業界落地的實現,在Kappa架構的理論支援下,實時數倉主要解決數倉對數據實時化的需求,例如數據的實時攝取、實時處理、實時計算等
其實實時數倉主主要解決三個問題 1. 數據實時性 2. 緩解集群壓力 3. 緩解業務庫壓力。


第一層DWD公共實時明細層 實時計算訂閱業務數據消息隊列,然後通過數據清洗、多數據源join、流式數據與離線維度資訊等的組合,將一些相同粒度的業務系統、維表中的維度屬性全部關聯到一起,增加數據易用性和復用性,得到最終的實時明細數據。這部分數據有兩個分支,一部分直接落地到ADS,供實時明細查詢使用,一部分再發送到消息隊列中,供下層計算使用
第二層DWS公共實時匯總層 以數據域+業務域的理念建設公共匯總層,與離線數倉不同的是,這裡匯總層分為輕度匯總層和高度匯總層,並同時產出,輕度匯總層寫入ADS,用於前端產品複雜的olap查詢場景,滿足自助分析;高度匯總層寫入Hbase,用於前端比較簡單的kv查詢場景,提升查詢性能,比如產出報表等
實時數倉的的實施關鍵點
- 端到端數據延遲、數據流量量的監控
- 故障的快速恢復能⼒力力 數據的回溯處理理,系統⽀支援消費指定時間端內的數據
- 實時數據從實時數倉中查詢,T+1數據藉助離線通道修正
- 數據地圖、數據⾎血緣關係的梳理理
- 業務數據品質量的實時監控,初期可以根據規則的⽅方式來識別品質量狀況
數據保障
- 集團每年都有雙十一等大促,大促期間流量與數據量都會暴增。實時系統要保證實時性,相對離線系統對數據量要更敏感,對穩定性要求更高
- 所以為了應對這種場景,還需要在這種場景下做兩種準備: 1.大促前的系統壓測; 2.大促中的主備鏈路保障


數據湖
最開始的時候,每個應用程式會產生、存儲大量數據,而這些數據並不能被其他應用程式使用,這種狀況導致數據孤島的產生。隨後數據集市應運而生,應用程式產生的數據存儲在一個集中式的數據倉庫中,可根據需要導出相關數據傳輸給企業內需要該數據的部門或個人,然而數據集市只解決了部分問題。剩餘問題,包括數據管理、數據所有權與訪問控制等都亟須解決,因為企業尋求獲得更高的使用有效數據的能力。
為了解決前面提及的各種問題,企業有很強烈的訴求搭建自己的數據湖,數據湖不但能存儲傳統類型數據,也能存儲任意其他類型數據(文本、影像、影片、音頻),並且能在它們之上做進一步的處理與分析,產生最終輸出供各類程式消費。而且隨著數據多樣性的發展,數據倉庫這種提前規定schema的模式顯得越來難以支援靈活的探索&分析需求,這時候便出現了一種數據湖技術,即把原始數據全部快取到某個大數據存儲上,後續分析時再根據需求去解析原始數據。簡單的說,數據倉庫模式是schema on write,數據湖模式是schema on read
總結
Kappa對比Lambda架構

在真實的場景中,很多時候並不是完全規範的Lambda架構或Kappa架構,可以是兩者的混合,比如大部分實時指標使用Kappa架構完成計算,少量關鍵指標(比如金額相關)使用Lambda架構用批處理重新計算,增加一次校對過程。
這兩個架構都是實時架構,都是對離線架構的擴展
實時數倉與離線數倉的對比
離線數據倉庫主要基於sqoop、hive等技術來構建T+1的離線數據,通過定時任務每天拉取增量量數據導⼊到hive表中,然後創建各個業務相關的主題維度數據,對外提供T+1的數據查詢介面
實時數倉當前主要是基於實時數據採集工具,如canal等將原始數據寫⼊入到Kafka這樣的數據通道中,最後⼀一般都是寫 入到類似於HBase這樣存儲系統中,對外提供分鐘級別、甚⾄至秒級別的查詢⽅方案。


