大白話詳解大數據hive知識點,老劉真的很用心(2)
- 2020 年 12 月 11 日
- 筆記
- hive, 大數據, 大數據Hive知識點, 大數據開發

前言:老劉不敢說寫的有多好,但敢保證盡量用大白話把自己複習的內容詳細解釋出來,拒絕資料上的生搬硬套,做到有自己的了解!
1. hive知識點(2)
第12點:hive分桶表
hive知識點主要偏實踐,很多人會認為基本命令不用記,但是萬丈高樓平地起,基本命令無論多基礎,都要好好練習,多實踐。
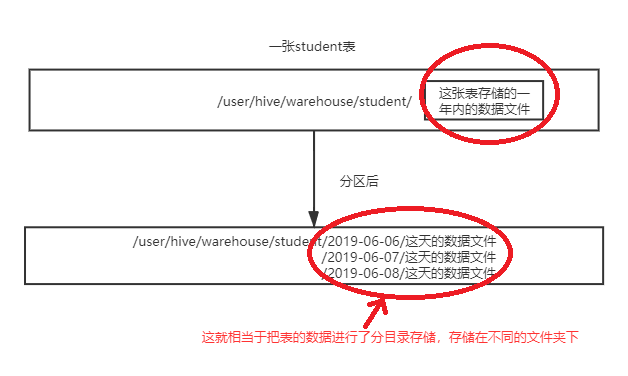
在hive中,分桶是相對分區進行更加細粒的劃分。其中分區針對的是數據的存儲路徑,而分桶針對的是數據文件,老劉用兩張相關的圖對比一下,就能明白剛剛說的區別了。
第一張是表進行分區後變化:
 第二張是表進行分桶後的變化:
第二張是表進行分桶後的變化:

根據這兩張圖,大致可以理解分區和分桶的區別。
那既然看了這兩張圖,分桶到底是什麼,也應該大致清楚了!
什麼是分桶?
分桶就是將整個數據內容按照某列屬性值取hash值進行區分,具有相同hash值的數據進入到同一個文件中。
舉例說明一下:比如按照name屬性分為3個桶,就是對name屬性值的hash值對3取模,按照取模結果對數據進行分桶。
取模結果為0的數據記錄存放到一個文件;
取模結果為1的數據記錄存放到一個文件;
取模結果為2的數據記錄存放到一個文件;取模結果為3的數據記錄存放到一個文件;
至於分桶表的案例太多了,大家自己可搜一個練練手。
第13點:hive修改表結構
這一點,其實沒有什麼好說的,資料上提到了,老劉也說一說,記住幾個命令就行。
修改表的名稱
alter table stu3 rename to stu4;
表的結構資訊
desc formatted stu4;
第14點:hive數據導入
這部分挺重要的,因為創建表後,要做的事就是把數據導入表中,如果連數據導入的基本命令都不會的話,那絕對是不合格的,這是非常重要的基礎!
1、通過load方式載入數據(必須記下來)
通過load方式載入數據
load data local inpath '/kkb/install/hivedatas/score.csv' overwrite into table score3 partition(month='201806');
2、通過查詢方式載入數據(必須記下來)
通過查詢方式載入數據
create table score5 like score;
insert overwrite table score5 partition(month = '201806') select s_id,c_id,s_score from score;
第15點:hive數據導出
1、insert導出
將查詢的結果導出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu' select * from stu;
將查詢的結果格式化導出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu2' row format delimited fields terminated by ',' select * from stu;
將查詢的結果導出到HDFS上(沒有local)
insert overwrite directory '/kkb/hivedatas/stu' row format delimited fields terminated by ',' select * from stu;
第16點:靜態分區和動態分區
Hive有兩種分區,一種是靜態分區,也就是普通的分區。另一種是動態分區。
靜態分區:在載入分區表的時候,往某個分區表通過查詢的方式載入數據,必須要指定分區欄位值。
這裡舉一個小例子,演示下兩者的區別。
1、創建分區表
use myhive;
create table order_partition(
order_number string,
order_price double,
order_time string
)
partitioned BY(month string)
row format delimited fields terminated by '\t';
2、準備數據
cd /kkb/install/hivedatas
vim order.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04
3、載入數據到分區表
load data local inpath '/kkb/install/hivedatas/order.txt' overwrite into table order_partition partition(month='2019-03');
4、查詢結果數據
select * from order_partition where month='2019-03';
結果為:
10001 100.0 2019-03-02 2019-03
10002 200.0 2019-03-02 2019-03
10003 300.0 2019-03-02 2019-03
10004 400.0 2019-03-03 2019-03
10005 500.0 2019-03-03 2019-03
10006 600.0 2019-03-03 2019-03
10007 700.0 2019-03-04 2019-03
10008 800.0 2019-03-04 2019-03
10009 900.0 2019-03-04 2019-03
動態分區:按照需求實現把數據自動導入到表的不同分區中,不需要手動指定。
如果需要一次性插入多個分區的數據,可以使用動態分區,不用指定分區欄位,系統自動查詢。
動態分區的個數是有限制的,它一定要從已經存在的表裡面來創建。
首先必須說的是,動態分區表一定是在已經創建的表裡來創建
1、創建普通標
create table t_order(
order_number string,
order_price double,
order_time string
)row format delimited fields terminated by '\t';
2、創建目標分區表
create table order_dynamic_partition(
order_number string,
order_price double
)partitioned BY(order_time string)
row format delimited fields terminated by '\t';
3、準備數據
cd /kkb/install/hivedatas
vim order_partition.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04
4、動態載入數據到分區表中
要想進行動態分區,需要設置參數
開啟動態分區功能
set hive.exec.dynamic.partition=true;
設置hive為非嚴格模式
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table order_dynamic_partition partition(order_time) select order_number,order_price,order_time from t_order;
5、查看分區
show partitions order_dynamic_partition;
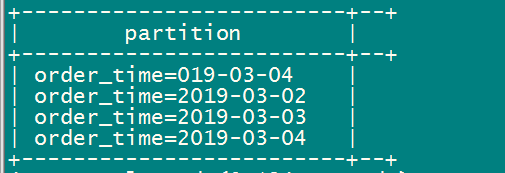
靜態分區和動態分區的例子講述的差不多了,大家好好體會下。
第17點:hive的基本查詢語法
老劉之前就說過,hive的基本查詢語法是非常重要的,很多人認為壓根不用記,需要的時候看看筆記就行,但是在老劉看來,這是非常錯誤的想法。
有句話說基礎不牢,地動山搖,我們最起碼要掌握常用的查詢語法。
1、基本語法查詢:
因為limit語句和where語句用的特別多,單獨拿出來,大家好好記記!
limit 語句
select * from score limit 5;
接下來是where語句,單獨拿出來,是想表達出where語句很重要。我們使用where語句,將不滿足條件的行過濾掉。
select * from score where s_score > 60;
2、分組語句
group by語句
group by語句通常和聚合函數一起使用,按照一個或者多個列結果進行分組,然後對每個組執行聚合操作。有個重點必須注意,select的欄位,必須在group by欄位後面挑選,除了聚合函數max,min,avg。
舉兩個小例子:
(1)計算每個學生的平均分數
select s_id,avg(s_score) from score group by s_id;
(2)計算每個學生最高的分數
select s_id,max(s_score) from score group by s_id;
having語句
先說說having語句和where不同點
① where是針對於表中的列,查詢數據;having針對於查詢結果中的列,刷選數據。
② where後面不能寫分組函數,而having後面可以使用分組函數。
③ having只用於group by分組統計語句。
舉兩個小例子:
求每個學生的平均分數
select s_id,avg(s_score) from score group by s_id;
求每個學生平均分數大於60的人
select s_id,avg(s_score) as avgScore from score group by s_id having avgScore > 60;
3、join語句

等值join
hive中支援通常的SQL JOIN語句,但是只支援等值連接,不支援非等值連接。
使用join的時候,可以給表起別名,也可以不用起。起別名的好處就是可以簡化查詢,方便。
根據學生和成績表,查詢學生姓名對應的成績
select * from stu left join score on stu.id = score.s_id;
合併老師與課程表
select * from teacher t join course c on t.t_id = c.t_id;
內連接inner join
當兩個表進行內連接的時候,只有兩個表中都存在與連接條件相匹配的數據的時候,數據才會保留下來,並且join默認就是inner join。
select * from teacher t inner join course c on t.t_id = c.t_id;
左外連接left outer join
進行左外連接的時候,join左邊表中符合where子句的所有記錄將會返回。
查詢老師對應的課程
select * from teacher t left outer join course c on t.t_id = c.t_id;
右外連接right outer join
進行右外連接的時候,join右邊表中符合where子句的所有記錄將會返回。
查詢老師對應的課程
select * from teacher t right outer join course c on t.t_id = c.t_id;
4、排序
order by全局排序
使用order by進行排序時候,asc表示升序,這是默認的;desc表示降序。
查詢學生的成績,並按照分數降序排列
select * from score s order by s_score desc ;
2. hive總結
hive知識點(2)就分享的差不多了,這部分偏於實踐,需要好好練習。在老劉看來分桶表以及靜態分區和動態分區的概念需要好好記住,剩下的就是hive的基本查詢操作,由於命令實在太多了,老劉只分享出了一些常用的命令,limit語句,where語句,分組語句,join語句等要熟記於心。
最後,如果覺得有哪裡寫的不好或者有錯誤的地方,可以聯繫公眾號:努力的老劉,進行交流。希望能夠對大數據開發感興趣的同學有幫助,希望能夠得到同學們的指導。
如果覺得寫的不錯,給老劉點個贊!