Apple的Core ML3簡介——為iPhone構建深度學習模型(附程式碼)
- 2019 年 11 月 22 日
- 筆記
編譯 | VK
來源 | Analytics Vidhya
概述
- Apple的Core ML 3是一個為開發人員和程式設計師設計的工具,幫助程式設計師進入人工智慧生態
- 你可以使用Core ML 3為iPhone構建機器學習和深度學習模型
- 在本文中,我們將為iPhone構建一個全新的應用程式!
介紹
想像一下,在不需要深入了解機器學習的情況下,使用最先進的機器學習模型來構建應用程式。這就是Apple的Core ML 3!
你是Apple的狂熱粉絲嗎?你用iPhone嗎?有沒有想過Apple是如何利用機器學習和深度學習來驅動其應用和軟體的?
如果你對以上任何一個問題的回答是肯定的,那麼你將會得到一場盛宴!因為在本文中,我們將使用深度學習和Apple的Core ML 3為iPhone構建一個應用程式。下面是這款應用的快速瀏覽:

軟體開發人員、程式設計師甚至數據科學家都喜歡Apple的人工智慧生態。近年來,他們取得了一些驚人的進展,包括Core ML和我個人最喜歡的Swift程式語言。
Core ML 3是一個框架,支援iPhone的一些功能,比如FaceID、Animoji和增強現實AR。自從Core ML在2017年發布以來,它已經走過了很長的路,現在它支援大量的工具,可以幫助我們快速構建基於機器學習的應用程式。
在這篇文章中,我們將探索Apple應用程式的整個人工智慧生態,以及如何使用Core ML 3豐富的生態,包括前沿的預訓練深度模型。
目錄
- Apple的人工智慧生態
- Core ML 3
- Core ML 3有什麼新特性?
- 使用ResNet50為iPhone構建一個影像分類應用
- 分析Vidhya對Core ML的看法
Apple的人工智慧生態
Apple在構建利用機器學習的工具和框架方面做得很好。構建人工智慧應用程式有多種選擇,每種選擇都有其優缺點。

讓我們了解一下每個工具或框架。
1)Turi Create
這應該是你的首選框架,如果你想添加推薦,對象檢測,影像分類,影像相似性或活動分類等任務到你的應用程式。
使用這個工具你不需要成為機器學習專家因為它已經為每個任務定義了模型。
我喜歡Turi Create的一點是,我們可以在Python中使用它,就像我們的常規工作流程一樣。當我們對我們的模型感到滿意時,只需將它導入到Core ML中,就可以在iOS、macOS、watchOS和tvOS應用程式中使用!
以下是Turi Create的支援的一些任務:

2)CreateML
Create ML使我們能夠構建機器學習模型,而不需要編寫太多程式碼。
我喜歡這個工具的地方是,你可以拖放你的訓練數據,選擇你想要的模型類型(語音識別,對象檢測等),它會自動開始訓練模型!
下面是一個訓練貓狗影像分類器的例子:

請注意,我只編寫了兩行程式碼並拖拽訓練數據到目標文件夾,其餘部分都由CreateML負責!
Turi Create可以在Python中工作,而我們可以使用CreateML在Mac上構建程式。並且它支援在GPU上進行訓練
3)用於TensorFlow的Swift
Swift for TensorFlow有一個靈活、高性能的類似於TensorFlow/PyTorch的API來構建複雜的神經網路架構。
這個框架最吸引人的地方是它的程式碼和Python的程式碼一樣易讀。以下是相同的模型在Swift和Python的不同表達(注意相似性):

當你需要模型的高性能並希望有效地部署它們時,可以選擇Swift來使用TensorFlow。
4)語言和視覺框架
這些是Apple針對Python的spaCy和OpenCV框架創建的副本,但是增加了功能。這些框架允許我們創建端到端管道來執行影像處理和文本處理等。
如果你想執行影像分析任務,如人臉或地標檢測、文本檢測、條形碼識別、影像配准和一般特徵跟蹤,那麼視覺就是你的選擇。

類似地,如果你想執行諸如語言和腳本識別、分詞、lemmatization、詞性分析和命名實體識別等任務,那麼語言模組將會很有用。

除了這兩個,Apple還支援處理語音數據的框架(並且它們很容易與CoreML一起工作)。我將在以後的文章中介紹這些工具。現在,讓我們來看看最精彩的框架——ML 3!
Core ML 3
我喜歡Apple的Core ML 3框架。它不僅支援我們在上面看到的工具,而且還支援它自己的一些功能。
首先,CoreML3允許我們導入主流的Python框架中訓練過的機器學習或深度學習模型:

我們在前面的一篇文章中已經介紹了Core ML 3的這個功能。在這裡,我們將看到CoreML3的另一個有趣的功能,我們如何利用CoreML3使用大量前沿的預訓練模型!
下面是Core ML 3支援的模型列表。注意其中的一些(比如Squeezenet, DeeplabV3, YOLOv3)是最近幾個月才出現的:

所有這些模型實際上都經過了優化,以便在移動設備、平板電腦和電腦上提供最佳性能。這就是Apple的偉大之處。
這意味著,即使其中許多是複雜的基於深度學習的模型,我們也不必在部署和在應用程式中使用它們時過多地擔心性能——這有多酷?
Core ML 3有什麼新特性?
你看了今年的WWDC大會了嗎?關於Apple設備對這個框架的支援,有一些有趣的公告。這裡有一個簡短的總結,以防你錯過。
1)設備內置的訓練
這是Core ML 3目前為止最突出的功能。之前,我們只支援「設備上的推理」。這基本上意味著我們在其他機器上訓練我們的模型,然後利用訓練好的模型對設備本身進行實時預測。新功能導致了更好的用戶體驗,因為我們不依賴互聯網來獲得預測。
Core ML 3現在也支援設備上的訓練!你可以使用iPhone的CPU、GPU和神經引擎來訓練你的機器學習和深度學習模型。
你可以將Core ML 3訓練視為一種遷移學習或在線學習的形式,在這種形式中,你只需要調整現有的模型。
以Face ID為例。當用戶的臉隨著時間變化(長鬍子、化妝、變老等)時,它需要保持模型的更新。基本思想是,首先擁有一個通用模型,它為每個人提供平均性能,然後為每個用戶訂製一個副本。
隨著時間的推移,這個模型會變得非常適合特定的用戶:
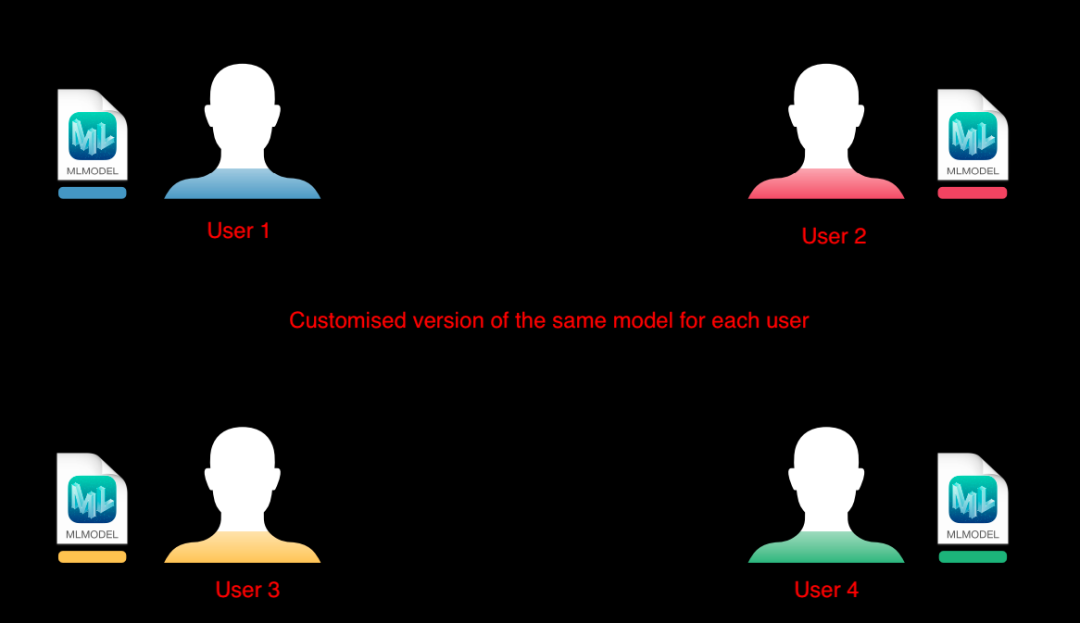
這樣做有很多好處:
- 訓練將在用戶的個人設備上進行,這對用戶來說意味著很高的數據隱私
- 我們不需要設置龐大的伺服器來幫助數百萬應用程式用戶進行模型訓練
- 因為不涉及互聯網,這些模型預測時一直可用!
2)在Core ML 3中加入了新型的神經網路層

除了為不同的模型類型提供層外,Core ML 3還為中間操作提供了100多個層,比如掩蔽、張量操作、布爾邏輯、控制流等等。
這些層類型中的一些已經被用在最先進的神經網路架構中,Core ML 3已經為我們提供了支援。
這僅僅意味著我們可以很容易地為我們的應用程式立即構建這樣的模型。
如果你對整個包感興趣,可以免費觀看整個WWDC影片。出於本文的目的,我們介紹了core ML 3的核心基礎知識。現在是時候構建一個iPhone應用程式了!影片鏈接:https://developer.apple.com/videos/play/wwdc2019/704/
為iPhone建立一個影像分類應用
在我們開始構建應用程式之前,我們需要安裝一些東西。
系統設置
- macOS:我用的是macOS Catalina (10.15.1)
- Xcode:這是為Apple設備開發應用的默認軟體。你可以從Apple電腦上的App Store下載。我用的是11.2版
- Project:你可以在你的終端使用下面的命令從GitHub下載項目的基本程式碼:
git clone https://github.com/mohdsanadzakirizvi/CoreML3-Resnet50.git
注意:
- 對於本文,你需要一台macOS機器,否則無法實現該項目
- 任何為Apple設備開發的應用程式都是用Swift編寫的
建立我們的深度學習模型
一旦你下載項目,你會看到有兩個文件夾:

圖片上的完整版是應用程式的全功能版本,你可以通過導入ResNet50模型來運行。練習版缺少一些程式碼。
在Xcode中運行以下命令打開項目:
open ImageClassifier.xcodeproj

我在Xcode窗口中突出顯示了三個主要區域:
- 左上角的play按鈕用於在模擬器上start the app
- 如果你看下面的play按鈕,有文件和文件夾的項目。這稱為項目導航器。它幫助我們在項目的文件和文件夾之間導航
- 在播放按鈕旁邊寫著iPhone 11 Pro Max。這表示要測試模擬器的目標設備
讓我們先運行我們的應用程式,看看會發生什麼。點擊左上角的播放按鈕,模擬器就會運行。 你看到了什麼?

目前,我們的應用程式還做不了什麼。它只顯示一個影像和一個按鈕來選擇其他影像-讓我們做得更好!
如果你打開Pratice版本,你會發現以下文件夾結構:

在項目導航窗格中,選擇ViewController.swift。這個文件包含了很多控制我們應用程式功能的程式碼。
import CoreML import Vision import UIKit class ViewController: UIViewController { @IBOutlet weak var scene: UIImageView! @IBOutlet weak var answerLabel: UILabel! override func viewDidLoad() { super.viewDidLoad() guard let image = UIImage(named: "scenery") else { fatalError("no starting image") } scene.image = image } } extension ViewController { @IBAction func pickImage(_ sender: Any) { let pickerController = UIImagePickerController() pickerController.delegate = self pickerController.sourceType = .savedPhotosAlbum present(pickerController, animated: true) } } // UIImagePickerControllerDelegate extension ViewController: UIImagePickerControllerDelegate { func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) { dismiss(animated: true) guard let image = info[UIImagePickerControllerOriginalImage] as? UIImage else { fatalError("couldn't load image from Photos") } scene.image = image } } //UINavigationControllerDelegate extension ViewController: UINavigationControllerDelegate { }
現在你已經熟悉了Xcode和項目程式碼文件,讓我們進入下一個階段。
在我們的應用程式中添加一個預訓練模型
前往官方Core ML 3網站直接下載預訓練的模型:
https://developer.apple.com/machine-learning/models/
在image部分,你可以找到ResNet50:

你可以下載任何你想要的版本。尺寸越大,模型就越精確。同樣,尺寸越小,模型運行的速度越快。
- 拖拽Resnet50.mlmodel文件放入項目導航窗格中的文件夾
- 將彈出一個帶有一些選項的窗口。選擇默認選項,然後點擊「Finish」
- 當我們將這樣的文件拖放到Xcode中時,它會自動創建對該文件的引用。通過這種方式,我們可以輕鬆地在程式碼中訪問該文件
以下是整個流程供參考:

做出第一個預測
為了進行第一次預測,我們需要載入剛剛下載的ResNet50模型。然後,取一幅影像,將它轉換成模型期望的格式並進行預測。
在ViewController.swift文件的IBActions(第33行)下面編寫以下程式碼:
extension ViewController { func imageClassify(image: CIImage) { answerLabel.text = "detecting..." // 通過生成的類載入ML模型 guard let model = try? VNCoreMLModel(for: Resnet50().model) else { fatalError("can't load Places ML model") } // 創建帶有處理程式的視覺請求 let request = VNCoreMLRequest(model: model) { [weak self] request, error in let results = request.results as? [VNClassificationObservation] var outputText = "" for res in results!{ outputText += "(Int(res.confidence * 100))% it's (res.identifier)n" } DispatchQueue.main.async { [weak self] in self?.answerLabel.text! = outputText } } // 在全局調度隊列上運行CoreML3 Resnet50分類器 let handler = VNImageRequestHandler(ciImage: image) DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) } } } }
上面的程式碼接收一個新影像,根據ResNet50期望的格式對其進行預處理,然後將其傳遞到網路中進行預測。
最重要的程式碼行是:
// 通過生成的類載入ML模型 guard let model = try? VNCoreMLModel(for: Resnet50().model) else { fatalError("can't load Places ML model") }
我們在這裡設置模型名稱。如果你想使用像BERT或YOLO這樣的框架,你只需要修改模型名,你的應用程式的其他部分就可以順利運行了。
現在,我們需要調用這個函數imageClassify()來獲得對影像的預測。將下面這段程式碼添加到viewDidLoad()的末尾(第19行):
guard let ciImage = CIImage(image: image) else { fatalError("couldn't convert UIImage to CIImage") } classifyImage(image: ciImage)
現在,如果你運行這個應用程式,你會看到它已經開始預測當應用程式啟動時顯示的風景圖片:

在imagePickerController()中複製相同的程式碼(第87行),然後應用程式將能夠對你選擇的任何影像做出相同的預測。
這是應用程式的最終版本:
恭喜你——你剛剛為iPhone開發了第一款人工智慧應用!
Vidhya對Core ML 3的分析
Apple公司利用最新的人工智慧影像、語音和文本研究,開發出令人印象深刻的應用程式。你可以立即開始,而不必對這些模型有太多的了解,並在此過程中學習和探索。
我喜歡這個行業認真對待人工智慧的方式,這讓更廣泛的受眾能夠接觸到它。
我鼓勵你進一步探索和嘗試最新的模型,如BERT,並創建更有趣的應用程式。如果想選擇其他模型的話,你可以嘗試在我們這裡開發的同一個應用程式上使用SqueezeNet和MobileNet,看看不同的模型是如何在相同的影像上運行的。
本文中使用的所有程式碼都可以在Github上找到:https://github.com/mohdsanadzakirizvi/CoreML3-Resnet50


