NeurIPS 2019 | 一種對噪音標註魯棒的基於資訊理論的損失函數
- 2019 年 11 月 22 日
- 筆記
來源:北京大學前沿計算研究中心
本文是第三十三屆神經資訊處理系統大會(NeurIPS 2019)入選論文《L_DMI:一種對噪音標註魯棒的基於資訊理論的損失函數(L_DMI: A Novel Information-theoretic Loss Function for Training Deep Nets Robust to Label Noise)》的解讀。該論文由北京大學前沿計算研究中心助理教授孔雨晴博士和北京大學數字影片編解碼技術國家工程實驗室教授、前沿計算研究中心副主任王亦洲共同指導,由 2016 級圖靈班本科生許逸倫、曹芃(共同一作)合作完成。

- 論文鏈接:https://arxiv.org/abs/1909.03388
- 程式碼鏈接:https://github.com/Newbeeer/L_DMI
簡介
噪音標註(noisy label)是機器學習領域的一個熱門話題,這是因為標註大規模的數據集往往費時費力,儘管在眾包平台上獲取數據更加快捷,但是獲得的標註往往是有噪音的,直接在這樣的數據集上訓練會損害模型的性能。許多之前處理噪音標註的工作僅僅對特定的噪音模式(noise pattern)魯棒,或者需要額外的先驗資訊,比如需要事先對噪音轉移矩陣(noise transition matrix)有較好的估計。我們提出了一種新的損失函數,

,它是基於一種新的互資訊,DMI(Determinant based Mutual Information)設計的。DMI 是一種對香農互資訊(Shannon Mutual Information)的推廣,它不僅像香農互資訊一樣滿足資訊單調性(information-monotone),還滿足相對不變性(relatively-invariant)等性質。
是首個不僅對噪音模式沒有限制,並且能夠無需先驗資訊而直接應用到任何現存的用於分類的神經網路中的損失函數。實際上,當噪音滿足條件獨立(conditional independence)假設時,即噪音標籤和具體數據條件獨立時,我們有下列等式成立:


這意味著,理論上,用
作為損失函數在噪音標註上訓練分類器和在正確標註(clean label)上訓練分類器沒有區別。
之前,人們使用的損失函數僅僅對特定的噪音模式魯棒。原因之一,是它們往往都是基於距離的(distance-based),比如 cross entropy loss,0-1 loss,MAE loss 等等,也就是說,這些損失函數定義的是分類器的輸出和標籤之間的一種距離。因此,如果標註者對某一分類具有很強的傾向,比如一個能力較低的標註者在標註醫療數據時,因為他知道大部分數據是良性的,所以他把所有良性的數據都標成了良性的,並且把 90% 的惡性的數據也標成了良性的。這樣,我們收集到的標籤就極其傾斜於良性這個分類,也就是有了對角線不主導(diagonally non-dominant)的噪音模式。在這種情況下,如果使用基於距離的損失函數,那麼一個把所有數據都分類到良性的分類器就會比一個把所有數據都分類到真實標籤的分類器有更小的損失函數值。
而不同於那些基於距離的損失函數,我們使用的是基於資訊理論的損失函數(information-theoretic loss function),即我們希望輸出和標籤之間有最高的互資訊的分類器具有最低的損失函數值。這樣,那個把所有數據都分類到良性的分類器由於和標籤的互資訊為零,就會有很高的損失函數值而被淘汰。但僅這一點是不夠的,實際上我們希望的是找到一個資訊測度 I,滿足下列性質:

也就是說,這個資訊測度在噪音標註(noisy label)上對分類器的序應該與其在正確標註(clean label)上對分類器的序相同。然而,香農的互資訊不滿足以上性質。
本文方法
我們使用了基於兩個離散隨機變數的聯合分布矩陣的行列式的互資訊 DMI[1]。它不僅保留有香農互資訊的一些性質,還能夠滿足我們需要的上述性質。它的正式定義為:


之間的 -log-DMI。在實際中,DMI 可以通過矩陣乘積快速計算,如下圖所示:


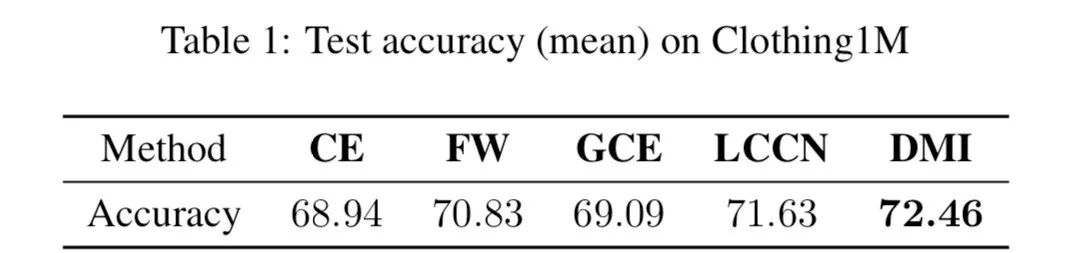
實驗結果
我們的方法在人工合成的數據集上和真實的數據集(Clothing 1M)上都取得了 state-of-the-art 的結果,並且在對角線不主導(diagonally non-dominant)的雜訊模式(noise pattern)中優勢明顯。


參考文獻:[1] Y. Kong, "Dominantly Truthful Multi-task Peer Prediction with a Constant Number of Tasks," to appear in SODA, 2020.

