Sophon :Hulu智慧OLAP快取層技術實踐
- 2019 年 11 月 21 日
- 筆記
分享嘉賓:羅安寧 Hulu 高級技術專家 編輯整理:董亮亮 內容來源:《Sophon :Intelligent OLAP Cache Layer》
首先介紹下Hulu,Hulu是美國本土的互聯網專業影片服務平台,主要以電影電視劇數字提供商提供的影片為主,同時有自製電視劇,還有實時的電視直播,Hulu在2018年的訂閱用戶數達到了2500萬,增長48%。
本次演講內容主要分為四部分:第一部分介紹Hulu的大數據架構;第二部分介紹Sophon,Sophon是一個輕量的OLAP中間快取管理層,它的下層主要依賴於OLAP計算引擎—Impala;第三部分介紹 Impala在Hulu的一些應用實踐;最後是一個全文的總結。
1. Hulu的大數據架構

Hulu大數據架構分成4部分,架構最底層有兩個自建的數據中心,它主要用於公司內部的大數據平台,包括大數據的存儲,離線和實時計算,以及OLAP查詢引擎等。同時也有一部分的data和data mart存儲在AWS的S3上,使用一些Cloud Native的查詢引擎,例如snowflake等;基礎設施層的上層是一些數據團隊,包括廣告,Metrics團隊等,最上層提供一些廣告售賣和一些報表服務等。

Hulu大數據的基礎技術架構如上圖,整體上是比較擁抱開源的,數據採集使用的是Flume、Kafka,數據存儲用的是HDFS和HBase,資源調度用的是yarn,離線計算用的是Spark、MapReduce、Hive等,在線計算主要用Impala、Presto以及一些自建的引擎,Presto是一個FaceBook 開源的MPP架構OLAP查詢引擎,在Hulu主要用於Ad Hoc的查詢,Impala是Cloudera開源的MPP架構OLAP查詢引擎,主要服務於一些自建的數據倉庫,我們自研的主要是Nesto和Sophon,Nesto是一個能夠查詢嵌套數據結構,基於MPP架構的查詢引擎,Sophon是一個OLAP快取的管理引擎,同時提供查詢和路由的功能,再往上就是統一的客戶端管理,包含統一的配置管理,自動更新等。我們的監控,除了採用Cloudera的自帶監控外,還有自研的監控組件Hawkeye,主要是對Cloudera監控的補充,它可以用來統計整個HDFS和各種計算引擎的指標。
2. Sophon

在介紹了整個Hulu的大數據平台架構以後,我們來具體看一下今天要演講的Sophon。首先介紹下Sophon的研發背景,Hulu廣告的數據集市比較複雜。Hulu主要以一些品質比較高的電視劇為主,所以它的廣告是受到很大限制的,主要以展示類廣告為主,這種廣告一般是提前售賣的方式,它不是一種實時競價的方式,提前售賣意味著今年10月份可能去談明年一年廣告售賣的單,這個單會非常非常大,在明年一年的投放中會細分成小的訂單,它會整合到廣告售賣訂單系統中,售賣周期會很長,預先售賣的方式不可能把廣告售賣的十分完整,總會有一部分廣告位或多或少,是通過實時競價的方式售賣出去的。因此整個系統會產生很多的事實表,包括廣告的投放,廣告的交易等。這些事件都會形成很多fact事實表,以及非常多的dimension,包括訂單的具體資訊,用戶的具體資訊,年齡,所在的州等,這樣就會形成很多的事實表和維度表在你的數據集市Data Market中,如果用一個傳統的方式對上層提供服務的話,那麼你是需要一個很長的pipeline來處理這些數據。


同時對於不同的事實表和不同的領域,需要建立不同的數據集市,有時比如你關心廣告的售賣情況和具體的投放的關係時,就需要用相關的事實表和維度表來形成特定的數據集市,不同的數據集市之間可能復用了部分相同的表,導致它們之間存在一定程度的耦合關係,這樣當維度表的關係一旦發生修改的話,就意味著你上層的在不同pipeline的邏輯都需要修改,整個處理流程非常長。還有就是需要由不同領域技術背景的人去服務你的各個層次,因此我們希望這個過程可以更加一致,更加統一,更加靈活。再有就是來自bussiness的需求,比如當數據分析師用到一些新的維度組合時,你原有的數據集市可能滿足不了,那麼當你去重新建立一些pipeline去滿足這個新的需求時,時間周期可能會非常久。所以我們考慮能不能把這些東西統一起來,把所有的數據關係集中到一起,當你有新的需求出現時,我能利用現有的模型和數據,在一個適當的響應時間內返回結果,然後系統能自動的優化cache,加速查詢。在這個方面我們嘗試做了改進,把由下到上的過程統一到一起,把它結合到一個過程,就省掉中間各種流程。因為本質上那些數據之間的關係不隨數據集市的不同而改變,既然不變的話,就能夠構建一套系統在知道這套關係以後能自動的根據上層的需要去生成對應的數據集市需要的數據,直接去服務於用戶,因此這就是我們嘗試做Sophon的初衷。

從Sophon整個的框架可以看到,它上層對接的是Bussiness UI工具,比如MSTR和Tableau,而對於數據建模人員來說,它提供一個介面去編輯和配置數據之間的關係是什麼。它只去管理和重寫SQL,不會真正去做任何的查詢,這樣可以保證它是一個非常輕量的引擎。真正的查詢工作它會下推給Impala或者其它一些數據引擎去實現。那麼有一個問題,當我的數據表很原始的時候,我把很大的fact表接過來,查詢速度會很慢,需要對整個過程進行加速,因此我們做了許多預聚合運算,存儲了許多預聚合表,Sophon並不會把這些預聚合的錶快取到內部,而是直接存儲為Hive表,且記錄所有表之間的join關係。這一點和Kylin不同,Kylin將預聚合記過存儲在HBase中,本身並不記錄預聚合表與其他維度表之間是否能夠join。雖然Kylin能夠配置維度之間的函數關係,但是只能適用於有限的幾種情況。另外,Kylin只支援Snowflake這種單fact的模型,在這種情況下,它可以把速度提升到很快毫秒級別,但犧牲了它的靈活性。因此,Kylin和Druid更傾向於把我的查詢提升到非常快的程度,達到毫秒級別,一旦沒有命中的話,就會發送給後端的Hive引擎,這個速度就會有很明顯的下降。對於Sophon來說,如果沒有命中聚合表,但是select的維度和聚合表存在join關係,Sophon會把兩者join在一起做聯合查詢。一般來說,聚合表的規模遠遠小於Fact表,當這個join下推到一個MPP架構的查詢,它的優化還是很可觀的,即使我們沒有在完全命中快取的情況下,一個十幾分鐘的查詢在這種情況下會縮減到幾秒到十幾毫秒,也可以非常明顯的被上層感知到,所以它的適用範圍會比這些查詢引擎廣一點,但是它的缺點就是會比Kylin這些引擎慢一點,到不了毫秒級的查詢,因此使用場景會有一些區別。

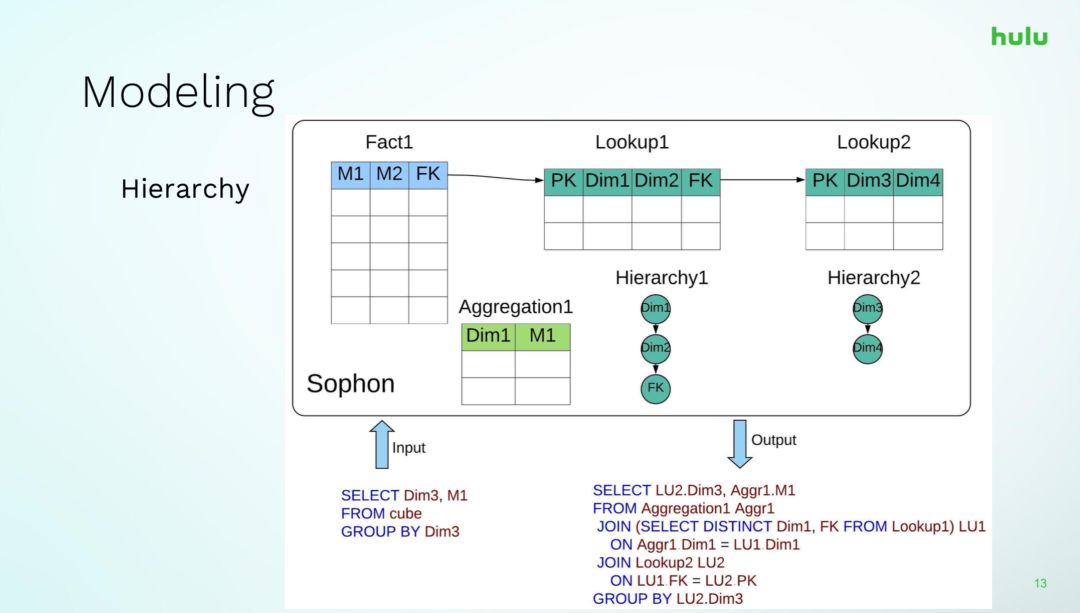
上面介紹了Sophon是做什麼的,下面我們來介紹一下Sophon建模的一些細節。Sophon最主要的功能就是表與表之間的Join,下面針對Join給出一個例子,如上圖所示,我們有一個Fact表和幾個Lookup表join到一起,在lookup表中,我們配置了維度與維度之間的層次結構關係,類似傳統資料庫的函數依賴,比如Dim1是一個hour,Dim2是一個Month,你的FK可能是一個year,同時系統中預構建了一個聚合表,它只命中了維度Dim1和度量M1,然而,查詢語句並沒有完全命中聚合表,那麼在一個Kylin或者其它的系統中就直接放到後端的查詢引擎計算了,但是對於Sophon來說,可以把Lookup1和Lookup2結合起來,把這兩個表join到一起,這樣聚合表就可以在這種情況下使用,這樣的另一個好處是,當Lookup2的Schema結構發生了變化,預聚合Aggregation1同樣是完完全全可以用的,不需要去做任何的重建工作。當然Kylin也支援Derived Column的特性,但是有很多的限制,像這樣的例子無法適用,由於Sophon所記錄的原始表之間的關係中,join鏈往往比較長,很多情況都無法通過Derived Column這種方式來優化。
另外一個功能是,我們希望聚合可以自動構建。聚合本身就是一個計算Cube的過程,在Kylin裡面,決定聚合哪些維度組合,需要人工探索,尤其是當Dimension維度規模比較大的時候,Cube膨脹的規模會變得非常大,但是Sophon所遇到的場景本身維度就非常多,當你想通過人工去找出裡面的規律,會非常困難。在Sophon裡面,我們通過使用一個貪心演算法去決定去建哪些聚合,具體來說就是每當我們選擇一個節點物化一個維度組合生成快取的時候,它對查詢Sophon的所有query都會產生一定程度的優化(沒有被優化的認為優化程度為0),總體的查詢代價就會減少,因此只要我們建立一個模型來計算查詢的代價降低了多少,並且每一步選擇一個代價減少最多的節點計算,就可以逐步通過這種貪心的方式得到一個比較優的結果。這種方法已經被證明與最優解之間的差距在一個有限範圍內。綜上可以看出,如何選擇代價是一個關鍵的問題,直觀上講,代價應該和join的規模成正相關,當你join的兩張表越大,代價就越大; 如果聚合表的規模很大,那麼就會耗費更多的存儲空間,查詢優化的效果也不經濟,這種情況需要引入額外的懲罰。最後的問題是,這個演算法本身的複雜度跟cube的複雜度是成線性關係的,假如說有n個維度,那麼複雜度將是O(2^n)。為了減少這個規模,我們一般需要去做一個聚類,來確定線上哪些維度是經常在一起查詢的,然後再根據這樣一個貪心的演算法,去進一步的找出我們物化哪些節點,使得最終的代價最小,收益會最大。

最後是如何將Sophon和後端引擎融合到一起,這方面最重要的是將如何根據預先定義的模型選擇聚合表和join路徑與如何對輸入的查詢進行改寫和優化分離開來。可以從下圖看到,首先系統將輸入的原始SQL翻譯成邏輯執行計劃,然後從邏輯執行計劃中提取具體是要查詢哪個Cube,哪些dimension和Measure資訊。然後將這些資訊傳遞到右側的優化系統中,這一部分與SQL採用什麼樣的語法沒有任何關係。之後,系統根據這個資訊去判斷應該怎麼去展開去命中需要的快取,是否能命中聚合表,根據不同的選擇去決定怎麼把這個表展開,展開之後再去決定在這種場景下有哪些優化規則可以用的上,然後通過一個適配器生成改寫SQL的規則,之所以這樣做是希望Sophon可以不僅支援單一查詢引擎,尤其是在當前背景下,希望以後可以支援一些Cloud native的引擎,比如S3上的Snowflake引擎,目前的趨勢就是,以後的一個查詢,一部分1年以內的數據可能在In-house的集群里,一年以前的數據在雲上,我希望可以自動將這兩部分數據的查詢結果結合起來,這個時候可以由Sophon對這兩部分數據進行管理和Merge結合起來,希望上層看到的是一個統一的視圖,具體的底層細節數據是在雲上還是在雲下對於上層用戶是無感知的。


下面介紹下Sophon在廣告數據集市的數據規模,有5張事實表,50+維度表,超過500個維度,數據量壓縮以後有50TB的數據,大概是10倍的壓縮比例,壓縮格式是ORC,這個是一個數據集市的量,目前我們要解決的場景就是這個,大部分的查詢在秒級或者十幾秒內。

簡單總結下Sophon的特點:首先,它很輕量,結構簡單。其次,它比較智慧,它會自動的幫你完成很多事情,數據工程師只需要去關注建模,之後它便能夠根據用戶的查詢需求來選擇應該計算哪些中間結構去加速查詢,並自動快取數據。再次,它比較靈活,它不僅可以直接命中快取表,還可以將快取表與其它的表進行關聯,由於快取表的規模一般比較小,這樣的場景下,它的速度也可以有明顯的提升。最後,它易於集成,由於分離了優化模組和SQL改寫模組,未來可以集成更多查詢引擎。
3. Impala在Hulu的應用
除了Sophon以外,Sophon的底層非常依賴Impala,下面我們介紹下Impala在Hulu的應用,首先介紹下Impala的選型背景,Impala是一種MPP查詢引擎,它的查詢速度相對Hive、Spark要快很多。其次它對Hive SQL的兼容性非常好,數據集市的遷移會非常方便。再有它是C++編寫的,OLAP在很多情況下Worker節點之間的Shuffle數據量會非常大,對於java-based的OLAP查詢引擎的話,GC垃圾回收的壓力非常大,很容易導致Full GC,所以Impala在記憶體管理這方面會友好一些。再有就是它向上提供的JDBC或者ODBC的操作,由於這些特性,我們選擇了Impala作為我們的後端。

Impala在Hulu有70多台機器節點,主要有兩個集群,廣告的是一個單獨的集群,Hadoop的機器節點有1千多台,存儲了Hive中的1萬多張表,支援的文件格式有parquet、orc、text、json、sequence file。Impala默認是不支援ORC格式的數據查詢的,這也是很多時候用Impala查詢hive 表的痛點,而Presto支援的數據格式就會豐富一點,因此我們在這方面做了單獨的支援,再有Impala有一個問題就是它的元數據是會被Cache快取的,被Cache的話,它不能及時的知道Hive層的數據變動,而我們的數據導入 pipeline入庫的過程一般來說還是通過Hive或者Spark這些工具導入進去的,那麼怎麼在數據導入以後,讓數據有及時的感知,這是個很重要的問題。

由於ORC在hive表中應用廣泛,Hive中90%的表都是ORC格式的。因此如果要使用Impala,我們有很強的需求使它能夠查詢ORC表,Hulu在17年開發了這個Feature,在C++這一層實現了Impala的scanner,目前它能夠支援查詢主要的數據類型,包括一些比較簡單的數據格式的下推,這些工作由另外一個同事完成,目前已經回饋給社區,這個Feature會在2.13和3.1的版本中會被Release出來,現在正在開發複雜類型的支援和條件下推,還在和社區討論過程中。


另外一個問題是關於元數據的,當你有新的數據進來,或者表的Schema發生了改變時,Impala無法自動更新這些變化,查詢在執行過程中出錯。這種情況下,簡單的辦法是根據Impala提供的指令手動更新元數據。但是我們希望這個過程能夠更加的自動化,來減少人工的參與。
對於這個問題,我們在Impala外部構建一個Pipeline直接拿到HDFS和Hive的audit日誌形成一條事件流,通過Kafka灌入Spark Streaming中,來監控數據和表schema的變化,當變化發生時,會自動觸發Impala的刷新,這是一個獨立的外部組件,同時也有一個報表系統,會具體記錄用戶對集群做了哪些操作,如果這個時候有人誤刪了一些表或者一些有害性的操作,報表系統會檢測出來,並觸發報警。
4. 總結
今天我們主要分享了Sophon的設計方案和Impala在Hulu的應用。Sophon作為Hulu在OLAP快取層的嘗試,更加註重靈活性,更注重智慧,來減少開發人員的工作,同時也希望它能夠處理更複雜的數據模型。在設計這些特性的同時,我們也儘可能的使它成為一個輕量且易於集成的系統。


