基於金融智慧風控的實時指標處理技術體系
- 2019 年 11 月 21 日
- 筆記
分享嘉賓:尹航
本次分享主要包含以下三個部分:
Part 01互聯網時代面臨的風控挑戰
1.1 數據泄露、欺詐泛濫
現在是大數據時代也是互聯網時代,這個時代最大的挑戰:
第一數據泄露,無論是你的密碼、銀行卡卡號、密碼相關的資訊都可以買到;
第二黑產分子也考慮性價比,所以數據泄露極其嚴重不可阻擋,如何在泄露的情況下做到風控?黑產已成體系化,非常嚴重,盜庫,撞庫,洗庫,驗證多個環節;
第三互金激勵了互聯網的應用給客戶帶來了大量的便利,便利的同時也帶來了相應的麻煩,銀行傳統的金融機構注重的是穩定,而互金注重的是速度。也就是說,一個年輕人需要借5000元,同時向幾家貸款機構發起申請,誰最先給,後幾家就不用了,所以特別注重速度,談到的秒貸什麼的,都出自於互金領域,銀行面臨著壓力、競爭,因此銀行也往這方面發展,互金從某種程度上在加大速度的同時,若風控等一些規則跟不上的話,就加速了安全的不穩定性;
第四各種各樣的應用,包含直銷銀行,網上銀行,各種先進的技術帶來了業務的創新,但這種創新和技術不匹配,帶來了滯後性。

1.2 現有的金融風控系統面臨的挑戰
風控反欺詐分為交易反欺詐和申請反欺詐。簡單規則,硬性規則:比如「出國在外,經常接到電話,您消費超過一萬元,這是您花的錢嗎?是則過,不是則打住」,這樣的規則是一視同仁,不需要平台,不需要經常改變,做到業務系統里即可,那現在的規則及其複雜;事後處理:對黑產分子、欺詐分子具有威懾作用,能夠掌握到痕迹,各位想想我們不是公安系統,不是破案的,我們要把他攔在防範事件未發生之前,比如做交易反欺詐,來一筆交易,事中就攔截了,要在100毫秒內就給個答覆,主動放行還是強驗證,而不是過去了之後再去追查各種線索,現在目前大多數都是事後處理;業務人員很難做到實時的調整參數,等等各種調參,反映整個系統的靈活性不夠;人工智慧,機器學習,關聯圖譜,設備指紋等這些技術如何和風控、實時系統相結合,是擺在我們面前迫切的話題;對黑產的了解是魔高一尺道高一丈,還是道高一尺魔高一丈,剛才也有人問這樣的問題,為什麼模型用用就有問題了,當然是有數據問題等諸多問題,但其中不可忽略一個問題,任何一個模型,任何一個規則是有時效性的,而且這個時間是越來越短,建模人員了解了黑產的特徵,建立模型或者說有相應的規則梳理出來了,那你就把黑產擋住了,能走過去,那說明他跳窗了,這個門就逐漸失效了,這是很正常的現象,所以說我們要對黑產的了解,基於業務不停的跟它鬥爭,就是說魔高一尺道高一丈;本身內部的數據,外部的數據如何獲取,大數據時代不是代表著你的數據獲取的越多越好,數據是有成本的,無論是金錢的成本還是人力的成本,這些成本需要考慮進來,要知道用什麼樣的數據合適,然後這些數據如何和系統結合,結合完後怎麼能發揮作用,那麼這就是個非常大的課題,所以說這是挑戰。

1.3 大數據時代的機遇與挑戰
到了真正的大數據時代,原來是以統計分析和BI平台為主,現在變成實時分析,原來都說歷史數據分析作為趨勢,然後再把分析出來相應的結果用於預測,這些分析一般都是以歷史數據(跑批數據)結合,最後形成個預測的模型,那麼現在我們要做到實時分析,實時決策,這個價值就非常大。

1.4 大數據處理:批式+流式
數據的價值從它產生開始就逐漸降低,而且一開始時會顯著降低;數據產生時叫熱數據,一般超過了瞬時(秒級/毫秒級)就已經進入了溫數據,溫數據一般是在一天左右,價值下降;在往後就是冷數據,冷數據也有一定價值,比較穩定。原來所談的大數據平台,或所利用的實時分析或各種分析模型,大部分利用冷數據來做的,那麼今天分享如何利用熱數據。

Part 02實時指標處理技術體系
2.1 實時計算髮展歷程與目標
電腦進入實時處理時代,spark streaming、storm、flink 等流處理。最開始的時候用的簡單資料庫,延遲低,幾十毫秒非常快,但它是個小量數據,在這個數據量下做到實時,沒有問題;接著進入了數據倉庫時代,數據倉庫時代是大數據時代,大數據時代就面臨著問題,超高的延遲,有時候算個東西算幾天,幾十個小時很正常;接著進入了以Hadoop為主的大數據平台,不是解決延時問題,是降低了成本;現在有Flink,Spark Streaming等各種流處理,這些流處理是能夠降下來的,延遲能達到毫秒級,但它和業務結合是有一定問題的。在這裡定義無狀態和有狀態,無狀態是指拿到數據,還不知道怎麼去利用它;有狀態是指在拿數據時就知道怎麼做;實際上我們原來這部分統稱數據驅動,有數據了驅動相應的模型,而到這就稱做邏輯驅動,需要一個邏輯或規則或者需要點東西,再去準備數據,其實邦盛平台就是這樣做的,現在可以達到毫秒級微秒級。

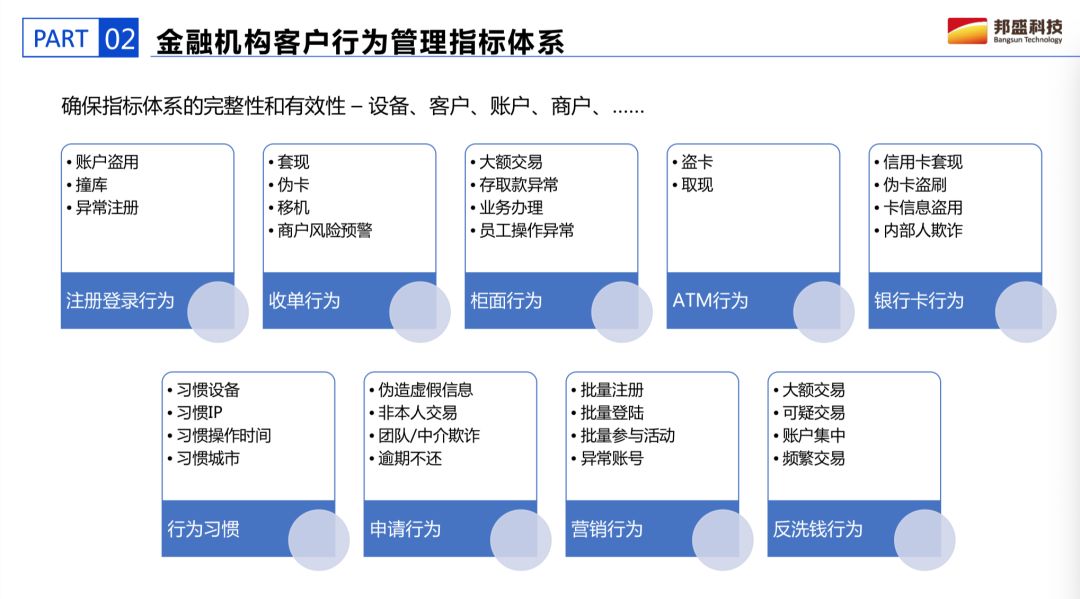
2.2 金融機構客戶行為管理指標體系
無論是人工智慧,機器學習,關聯圖譜還是規則都離不開指標;在信貸領域,無論是交易反欺詐,申請反欺詐,登陸、收單、櫃面還有行為等許多指標,但在這定義的指標既有價值也有權重;這些指標需要大量的梳理出來,下一步要知道什麼是實時指標。
2.3 實時指標處理需求的業務場景和技術挑戰
實時指標處理也就是熱數據,它會用在哪些領域裡?比如實時反欺詐,業界100毫秒的概念,夠判斷;一個交易過來,要100毫秒內進入風控系統里,給業務一個回饋,回饋主動放過還是強驗證,而這個叫無感知;超過100毫秒就叫有感知,對客戶體驗不好,所以說應用在實時反欺詐領域裡;另一個實時營銷,能夠快速的找到目標客戶;再有實時授信,目前所說的秒貸,原來是幾天或十幾天才能批,現在能達到一天之內或幾小時內或像那些優質客戶能達到秒級;但真正說的是,只要申請,只要進來,馬上就能審批到,這一定是個趨勢,所以說誰能搶先佔到了這個高點,公司的業務就能把別人甩出大截,業務會明顯的上升;另外這裡面還有些別的方式,比如說給證券行業,更是實時分析,它是基於微秒級的,為券商,散戶提供相應的分析;再一個實時網路機器人,判斷誰在跟我對話,是個真人還是台機器,一台機器會不斷的佔用頻寬來讀取,比如一些民航售票等等或者一些網站,頻寬基本上被吃住了,因為它不斷的查詢你的額度或票目前的狀態,佔了大量的頻寬,並不是說他是黑產份子,那麼要給它限制流量,限制流量前要知道他是否是人,有的不是人也會偽裝成人,他會用些隨機演算法,但是我會用標準差/方差方法仍然能找出他的痕迹,那就要給他適當的延遲或頻寬短點;另外實時的IT運維,怎麼能快速的反應;設備運行狀態可以應用到公共領域,因此說實時指標平台是有廣闊的應用場景。

2.4 實時指標計算的計算特點
實時指標計算的特點:長周期、多維度、大數據量。長周期:指標里含有半年,一年這樣的參數;原來說一個小時,幾分鐘這叫短周期;一個銀行卡號/一個身份證號,這叫小維度,海淀區或北京市所有Android手機的用戶這叫多維度;模型或規則里用到了這樣的數據,那麼它就是個典型的多維度數據;計算模式也是非常複雜的,比如說一個規則,如果一個銀行卡號過來買東西,這個銀行卡號關聯的最近一個月(30天之內)所購買的商品排名前3位,你的這次購買在不在這前3位之內,先從數倉里把和他相關聯的所有的一個月內的數據取出來排序,而且是動態實時排序,排完序之後找出前3名再去比對,大數據做這麼個決策如何在毫秒級完成?

2.5 實時指標體系的計算模式

2.6 AI模型迫切需要實時落地
一般來講,AI模型要落地的話,有三種基本模式,一用規則教,是個形式化的方法;二用數據學,這是典型機器學習應用,是種統計的方法;三用問題引導,在實踐中提升,是控制論的方法;無論是哪種方法,到我這來,一定是說是用規則集或評分卡或知識圖譜等等,這裡用到隨機森林,GBDT,神經網路等等來支撐著AI模型。

2.7 大數據實時智慧處理技術
要想實現快速決策,實時採集、實時加工、實時分析、實時決策這四步都不能少,每步都需要快速,哪個環節慢了,整個系統都會慢下來,會使得實時風控或熱數據根本沒辦法好好的應用,那麼我們是怎麼做的?採集後要快速實時的進行清洗加工,加工之後,要按照一定的特色進行提取,最後返到決策系統,和傳統的加工有什麼不同;比如,做一道宮保雞丁,現在有菜譜,只要一來胡蘿蔔就按照宮保雞丁那樣切好,放到冰箱里,一來雞肉,也洗好切好,放在那,需要用的時候弄下就好,炒菜和數據不同的在哪,數據不一樣可以複製成多套,按照多個菜單來,來個胡蘿蔔,要丁就切成丁,要條切成條,數據需要什麼樣的就洗成什麼樣的,等到決策的時候就像菜單炒菜特別快,這就是原理;還有一部分,是把源數據給到T數據處理平台,給機器學慣用,機器學習一般分兩個平台,一個是學習平台,一個是決策平台,學習平台也稱是訓練平台,訓練平台大部分是以跑批的,大量數據為主,所以我們的數據要和跑批的數據結合,然後讓它不斷的訓練,同時我的數據還能進到圖資料庫中,圖資料庫後由場景化就能進到複雜網路里,給這些關聯圖譜用,這些圖譜最終匯合到決策平台,在決策平台里有個決策引擎,這個決策引擎光有規則就叫做單引擎,規則加上機器學習,叫做雙核,按百分比決策,可調整;加上圖的話,叫三核決策,所以說這兩者並不矛盾而是相互補充的。

2.8 機器學習模型快速上線
機器學習如何快速上線,把決策前置,分成倆部分,一部分只要來了數據就存在流立方里,等到決策的時候,進行加工匯總就行;有了機器學習決策引擎,就需要特徵,而這個特徵一定要是實時的,如果做的不好就不能做到實時決策,這塊就需要用流立方/PipeACE解決。

2.9 全棧式機器學習平台-智慧學習平台
機器學習平台,邦盛也有採集,訓練及應用為一體的機器學習平台,對於項目來說,用多種演算法來算,用生存對抗的方式來看哪種方法或哪種演算法或哪種模型最優,目前用GBDT,隨機森林較多,一般都會做至少3個以上。

2.10 全棧式知識圖譜平台
知識圖譜,如何定義邊,定義節點,找出關係,而且要做到實時。

Part 03邦盛實時指標處理產品的技術特點
3.1 邦盛提供的產品和方案
邦盛產品特點,產品非常單一,只做金融反欺詐及互聯網授信,以技術為主,從戰略、諮詢、策略、模型、數據、到平台一個完整的系列。

3.2 邦盛對金融風險控制系統建設的理解與實踐
邦盛有設備指紋,黑手機號等等相關的數據,重點來談,流立方、PipeACE,關聯圖譜,機器學習,如何建模,無論是諮詢到產品落地,以及到相應的服務都提供。

3.3 實時指標處理平台在整個系統架構中的位置
實時指標處理平台在整個的風控體系或金融體系里處於什麼樣的位置,雖然是很小一塊,數據來了,實時的存在指標平台里,與菜單相關聯,再與實時指標處理引擎相配合。

3.4 指標系統與相關係統的交互
存儲存什麼,把各種各樣的指標拿過來,而且這些指標存的是中間結果,且是增量,然後用實時引擎來處理。

3.5 複雜業務場景中實時指標計算
基於複雜業務場景的指標計算,包括採集多源,比如說對接多種數據源,不是一個個的對接,而是從某種程度上說,找到通用的介面,接著要實時的加工,ETL處理有PipeACE ,然後實時計算由流立方處理,計算有多種方式,基本上涵蓋了目前規則所用到的各種各樣計算,按時序處理:比如有條規則銀行卡在過去10天內的交易1萬元的次數大於20次,過去10天而不是傳統意義上的10天,而是從現在這個時刻起,過去24小時算一天,在1月1日,來了筆交易,交易額1萬8,在流立方系統里存的1,等到下午再來筆交易,1萬2,也大於1萬,系統里記為2,1月1日存的是2,1月3日存的是1,1月4日存的5等,把過去10天的數據累加即可;比如現在達到19次了,來了筆2萬4的交易,就20次了,給他過,過了5秒中又來了次,當天就差5秒下一次就阻斷了,超過20次了,只有邦盛系統才能實時處理,不然解決不了這個問題,這就是基於時序;剛說的是10天,可以靈活的改成15天或20天,不需要動任何的指標平台,只要從指標里取數就好,去決策引擎里修改即可。

3.6邦盛的實時指標處理方法-以流立方為核心的實時指標平台
流立方存的是立方塊,立方塊是針對某一個規則所準備的材料,放在這個立方塊里,有3個維度,時間,計算,指標維度缺一不可,不用擔心量大,存的是增量數據且是計算完的結果數據;數據綜合前置,ETL 加上流立方這就是構成指標平台的整個體系。

3.7 流立方的核心技術特點
流立方的特點,一分散式快取,當性能不夠的時候,加節點即可;二專利時序處理,按照時間的概念存放;三大數據模型管理,有大量的數據計算及處理,同時解決低延遲,高並發,邦盛這套系統平均延遲13-17毫秒,遠低於業界標準,實測非常之快。

3.8 數據實時加工能力
數據實時加工能力:線性擴展,分散式系統,低延遲,高並發,而且保證高可用性,可以做到種種模式,橫向擴展,廣泛適配,可以對接多個數據源,可以對接不同的決策引擎,可以說是松耦合的各種模組,多執行緒的流處理技術。

3.9 實時指標平台的整體架構
實時採集是採用代理機制,微探針在不同的系統里,把數據實時採集過來加工處理。

3.10 實時指標平台功能架構

3.11 應用案例分享
最後講下交易反欺詐例子,有風控系統和無風控系統的區別。



3.12 總結
邦盛實時指標平台的特點包含,超快的速度、豐富的內置演算法、強大的數據加工能力、滿足業務的高可靠性要求。



